資訊專欄INFORMATION COLUMN

摘要:何愷明和兩位大神最近提出非局部操作為解決視頻處理中時空域的長距離依賴打開了新的方向。何愷明等人提出新的非局部通用網絡結構,超越。殘差連接是何愷明在他的年較佳論文中提出的。
Facebook何愷明和RGB兩位大神最近提出非局部操作non-local operations為解決視頻處理中時空域的長距離依賴打開了新的方向。文章采用圖像去噪中常用的非局部平均的思想處理局部特征與全圖特征點的關系。這種非局部操作可以很方便的嵌入已有模型,在視頻分類任務中取得的很好的結果,并在在靜態圖像識別的任務中超過了何愷明本人ICCV較佳論文的Mask R-CNN。何愷明等人提出新的非局部通用網絡結構,超越CNN。
何愷明博士,2007年清華大學畢業之后開始在微軟亞洲研究院(MSRA)實習,2011年香港中文大學博士畢業后正式加入MSRA,目前在Facebook AI Research (FAIR)實驗室擔任研究科學家。曾以第一作者身份拿過兩次CVPR較佳論文獎(2009和2016),一次ICCV較佳論文。
Ross Girshick,在讀博士的時候就因為dpm獲得過pascal voc 的終身成就獎。同時也是RCNN,fast RCNN ,faster RCNN,YOLO一系列重要的目標檢測算法的作者。現在同樣就職于FAIR。
背景
文章主要受到NL-Means在圖像去噪應用中的啟發,在處理序列化的任務是考慮所有的特征點來進行加權計算,克服了CNN網絡過于關注局部特征的缺點。
圖像去噪是非常基礎也是非常必要的研究,去噪常常在更高級的圖像處理之前進行,是圖像處理的基礎。圖像中的噪聲常常用高斯噪聲N(μ,σ^2)來近似表示。 一個有效的去除高斯噪聲的方式是圖像求平均,對N幅相同的圖像求平均的結果將使得高斯噪聲的方差降低到原來的N分之一,現在效果比較好的去噪算法都是基于這一思想來進行算法設計。
NL-Means的全稱是:Non-Local Means,直譯過來是非局部平均,在2005年由Baudes提出,該算法使用自然圖像中普遍存在的冗余信息來去噪聲。與常用的雙線性濾波、中值濾波等利用圖像局部信息來濾波不同的是,它利用了整幅圖像來進行去噪,以圖像塊為單位在圖像中尋找相似區域,再對這些區域求平均,能夠比較好地去掉圖像中存在的高斯噪聲。
通常的CNN網絡模擬人的認知過程,在網絡的相鄰兩層之間使用局部連接來獲取圖像的局部特性,一般認為人對外界的認知是從局部到全局的,而圖像的空間聯系也是局部的像素聯系較為緊密,而距離較遠的像素相關性則較弱。因而,每個神經元其實沒有必要對全局圖像進行感知,只需要對局部進行感知,然后在更高層將局部的信息綜合起來就得到了全局的信息。網絡部分連通的思想,也是受啟發于生物學里面的視覺系統結構,底層的去捕捉輪廓信息,中層的組合輪廓信息,高層的組合全局信息,最終不同的全局信息最終被綜合,但由于采樣以及信息逐層傳遞損失了大量信息,所以傳統cnn在全局信息捕捉上存在局限性。

圖3是指在res3上一個非局部模塊的行為的示例,其在Kinetics數據集上基于5-block的非局部模型訓練得到的。這些例子來自于驗證集視頻。
而在處理視頻等序列化數據時,傳統cnn的這種局限性就顯得尤為嚴重了。比如在記錄一場網球比賽的視頻中,每一幀都能很容易的檢測到他的手握拍在哪,一個卷積核就能覆蓋位置也就是手腕周圍的區域。
但是為了識別揮拍這個動作,僅僅關注手腕周圍的信息是不夠的,我們需要了解到人的手腕跟他的胳膊、肩膀、膝蓋以及腳發生了哪些一系列的相對位移才能判斷出揮拍動作。這些信息是將網球區別于其他運動的重要信息,因為靜止來看運動員都拿著拍子站在那而已。而這些重要的全局位移信息很難被關注局部的卷積核收集到。
非局部神經網絡(Non-local Neural Networks)
非局部操作(Non-local operation)
為了處理這些全局動作信息,文章借鑒NL-Means中利用整幅圖去噪的思想。前面講到 NL-Means利用了整幅圖像來進行去噪,以圖像塊為單位在圖像中尋找相似區域,再對這些區域求平均,它的濾波過程可以用下面公式來表示:
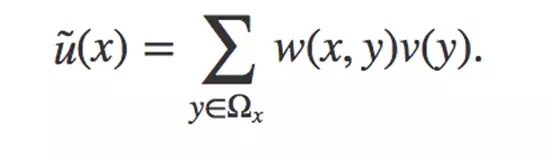
在這個公式中,w(x,y)是一個權重,表示在原始圖像中,像素 x和像素 y 的相似度。這個權重要大于0,同時,權重的和為1。
類似的,該文章定義了一個用于處理當前動作點與全局所有信息關系的函數
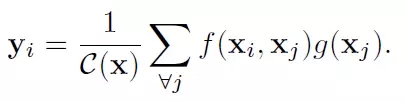
這里x是輸入信號,也是和x尺寸一樣的輸出信號,i代表時間空間上的輸出位置索引,j代表全圖中所有可能位置的枚舉索引。函數f(x_i, x_j)計算位置i和j的權重。函數g用來計算j位置輸入信號的一個表示。文章中的Non-Local操作就是考慮了圖像中的所有可能位置j。
文中還給出了具體的幾種f(x_i,x_j)函數的實現形式
1. ? ? Gaussian
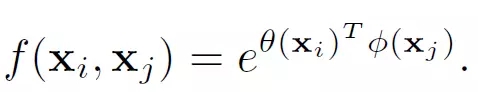
2. ? ? Embedded Gaussian
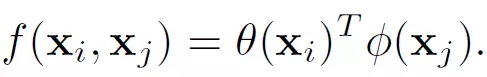
3. ? ? Dot product
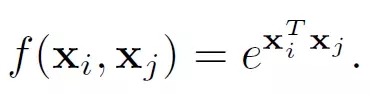
4. ? ? Concatenation
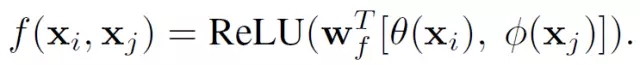
非局部模塊(Non-local Block)
文章中還定義了Non-local Block,也就是把前面的這種Non-local操作封裝起來作為一個模塊可以很方便的用在現有的框架中。
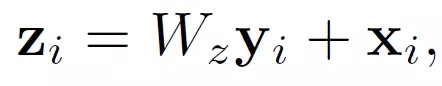
這里y_i就是公式(1)中的輸出結果。“+x_i”表示殘差連接。殘差連接是何愷明在他的2016年CVPR較佳論文中提出的。這個殘差連接使得我們可以將這個Non-local Block很方便的插入已有的預訓練模型中,而不會破壞模型原有的操作。
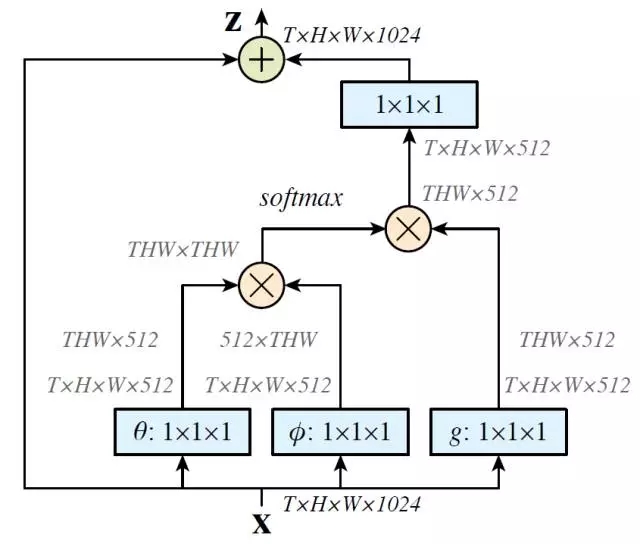
上圖是一個Non-local Block的例子。特征圖尺寸為T×H×W×1024 也就是有 1024 個通道。 f函數采用的是公式3中的Embedded Gaussian。藍色框表示1×1×1 的卷積操作,這種結構為512通道的“瓶頸”(bottleneck)結構。
實驗
視頻分類
文章在Kinetics 和Charades兩個視頻數據集上進行實驗,baseline選的是帶殘差結構的cnn網絡。

表3是在Kinetics上的比較結果。標記"+"是指在測試集上的結果,其余沒有標記的是在驗證集的結果。我們包含了2017年包括Kinetics競爭冠軍的結果,但是他們較好的結果利用了音頻信號(標記為灰色),不是一個僅僅基于視覺的解決方法。
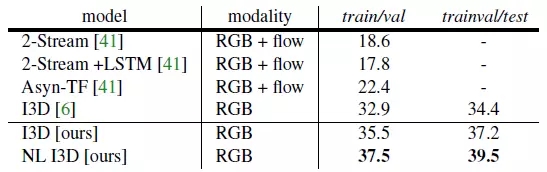
表4是在Charades數據集上的分類結果,數據集被劃分成訓練集/驗證集,訓練驗證/測試集兩種方式。我們的結果是基于ResNet-101, 我們提出的的NL I3D使用了5個non-local blocks.
COCO數據
文章還在靜態圖像數據識別進行實驗。用在物體識別分割以及姿態識別任務上的Baseline是何愷明剛在ICCV上取得較佳論文的Mask R-CNN.
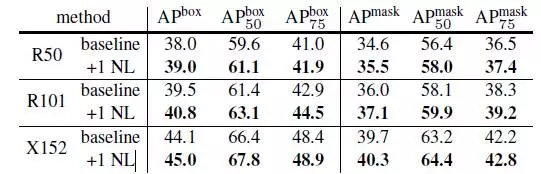
表5是在COCO物體檢測和示例分割任務中增加一個non-local block到Mask R-CNN的結果。
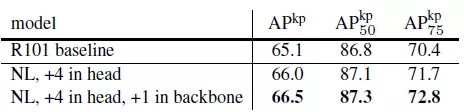
表6是在COCO關鍵點檢測任務中增加non-local blocks到Mask R-CNN的結果。
在未來,我們也希望在未來網絡結構設計中非局部層能成為一個不可或缺模塊。
論文:Non-local Neural Networks
鏈接:https://arxiv.org/abs/1711.07971

(附上專知內容組翻譯的摘要和引言,有錯誤和不完善的地方,請大家提建議和指正)
摘要
卷積和循環網絡操作都是常用的處理局部領域的基礎模塊。在本文中,我們提出將非局部操作(non-local operations)作為捕獲長距離依賴的通用模塊。受計算機視覺中的經典非局部均值方法的啟發,我們的非局部運算將位置處的響應計算為所有位置處的特征的加權和。這個構建模塊可以應用到許多計算機視覺體系結構中。
在視頻分類的任務上,即使沒有用任何花里胡哨的技巧,我們的非局部模型也可以在Kinetics和Charades數據集上超過對手的效果。在靜態圖像識別中,我們的非局部模型在COCO比賽中的三個任務,對象檢測/分割和姿態估計中都效果都有提升。代碼將隨后提供。
引言
在深層神經網絡中,捕獲長期依賴關系是至關重要的。對于連續的數據(例如演講中語言),循環操作是時間域上長期依賴問題的主要解決方案。對于圖像數據,長距離依賴關系是對大量的卷積操作形成的大的感受野進行建模的。
卷積操作或循環操作都是處理空間或者時間上的局部鄰域的。這樣,只有當這些操作被反復應用的時候,長距離依賴關系才能被捕獲,信號才能通過數據不斷地傳播。重復的局部操作有一些限制:首先,計算效率很低;其次,增加優化難度;最后,這些挑戰導致多跳依賴建模,例如,當消息需要在遠距離之間來回傳遞時,是非常困難的。
本文中,我們提出將非局部操作作為一個高效的、簡單的、通用的組件,并用深度神經網絡捕捉長距離依賴關系。我們提出的非局部操作受啟發于計算機視覺中經典非局部操作的一般含義。直觀地說,非局部操作在一個位置的計算響應是輸入特性圖中所有位置的特征的加權總和(如圖1)。一組位置可以在空間、時間或時空上,暗示我們的操作可以適用于圖像、序列和視頻問題。

圖1是一個在視頻分類應用中訓練的網絡包含的時空非局部操作示例。
非局部操作有以下優勢:(a)與循環操作的反復性行為形成對比,非局部操作直接通過計算任意兩個位置之間的相互作用來捕捉長距離依賴關系,而不需受兩位置的位置距離約束。(b)正如我們在實驗中展示的,非局部操作的效率高,而且在只有幾層的情況下也能達到較好的結果。(c)最后,我們的非局部操作保持輸入變量的大小,并且容易與其他操作進行結合(如卷積操作)。
我們將展示非局部操作在視頻分類應用中的有效性。在視頻中,遠距離的相互作用發生在空間或時間中的長距離像素之間。一個非局部塊是我們的基本單位,可以直接通過前饋方式捕捉這種時空依賴關系。在一些非局部塊中,我們的網絡結構被稱為非局部神經網絡,比2D或3D卷積網絡(包括其變體)有更準確的視頻分類效果。另外,非局部神經網絡有比3D卷積網絡有更低的計算開銷。我們在Kinetics和Charades數據集上進行了詳細的研究(分別進行了光流、多尺度測試)。我們的方法在所有數據集上都能獲得比方法更好的結果。
為了證明非局部操作的通用性,我們進一步在COCO數據集上進行了目標檢測/分割和姿勢估計的實驗。在MaskR-CNNbaseline的基礎之上,我們的非局部塊僅需要很小的額外計算開銷,就可以提升在三個任務中的準確度。在視頻和圖像中的實驗證明,非局部操作可以作為設計深度神經網絡的一個通用的部件。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4694.html
摘要:大神何愷明受到了質疑。今天,上一位用戶對何愷明的提出質疑,他認為何愷明年的原始殘差網絡的結果沒有被復現,甚至何愷明本人也沒有。我認為,的可復現性經受住了時間的考驗。 大神何愷明受到了質疑。今天,Reddit 上一位用戶對何愷明的ResNet提出質疑,他認為:何愷明 2015 年的原始殘差網絡的結果沒有被復現,甚至何愷明本人也沒有。網友稱,他沒有發現任何一篇論文復現了原始 ResNet 網絡的...
摘要:為了探索多種訓練方案,何愷明等人嘗試了在不同的迭代周期降低學習率。實驗中,何愷明等人還用預訓練了同樣的模型,再進行微調,成績沒有任何提升。何愷明在論文中用來形容這個結果。 何愷明,RBG,Piotr Dollár。三位從Mask R-CNN就開始合作的大神搭檔,剛剛再次聯手,一文終結了ImageNet預訓練時代。他們所針對的是當前計算機視覺研究中的一種常規操作:管它什么任務,拿來ImageN...
摘要:目前目標檢測領域的深度學習方法主要分為兩類的目標檢測算法的目標檢測算法。原來多數的目標檢測算法都是只采用深層特征做預測,低層的特征語義信息比較少,但是目標位置準確高層的特征語義信息比較豐富,但是目標位置比較粗略。 目前目標檢測領域的深度學習方法主要分為兩類:two stage的目標檢測算法;one stage的目標檢測算法。前者是先由算法生成一系列作為樣本的候選框,再通過卷積神經網絡進行樣本...
摘要:但是其仍然存在一些問題,而新提出的解決了式歸一化對依賴的影響。上面三節分別介紹了的問題,以及的工作方式,本節將介紹的原因。作者基于此,提出了組歸一化的方式,且效果表明,顯著優于等。 前言Face book AI research(FAIR)吳育昕-何愷明聯合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度學習里程碑式的工作B...
摘要:從標題上可以看出,這是一篇在實例分割問題中研究擴展分割物體類別數量的論文。試驗結果表明,這個擴展可以改進基準和權重傳遞方法。 今年10月,何愷明的論文Mask R-CNN摘下ICCV 2017的較佳論文獎(Best Paper Award),如今,何愷明團隊在Mask R-CNN的基礎上更近一步,推出了(以下稱Mask^X R-CNN)。這篇論文的第一作者是伯克利大學的在讀博士生胡戎航(清華...

閱讀 3563·2023-04-26 00:05
閱讀 953·2021-11-11 16:55
閱讀 3522·2021-09-26 09:46
閱讀 3517·2019-08-30 15:56
閱讀 908·2019-08-30 15:55
閱讀 2933·2019-08-30 15:53
閱讀 1939·2019-08-29 17:11
閱讀 814·2019-08-29 16:52






