資訊專欄INFORMATION COLUMN

摘要:為了探索多種訓練方案,何愷明等人嘗試了在不同的迭代周期降低學習率。實驗中,何愷明等人還用預訓練了同樣的模型,再進行微調,成績沒有任何提升。何愷明在論文中用來形容這個結果。

何愷明,RBG,Piotr Dollár。
三位從Mask R-CNN就開始合作的大神搭檔,剛剛再次聯手,一文“終結”了ImageNet預訓練時代。
他們所針對的是當前計算機視覺研究中的一種常規操作:管它什么任務,拿來ImageNet預訓練模型,遷移學習一下。
但是,預訓練真的是必須的嗎?
這篇重新思考ImageNet預訓練(Rethinking ImageNet Pre-training)就給出了他們的答案。
FAIR(Facebook AI Research)的三位研究員從隨機初始狀態開始訓練神經網絡,然后用COCO數據集目標檢測和實例分割任務進行了測試。結果,絲毫不遜于經過ImageNet預訓練的對手。
甚至能在沒有預訓練、不借助外部數據的情況下,和COCO 2017冠軍平起平坐。
結果
訓練效果有圖有真相。
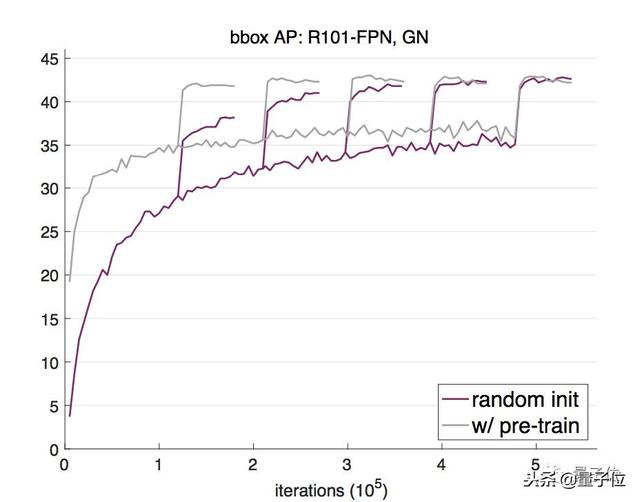
他們用2017版的COCO訓練集訓練了一個Mask R-CNN模型,基干網絡是用了群組歸一化(GroupNorm)的ResNet-50 FPN。

隨后,用相應的驗證集評估隨機權重初始化(紫色線)和用ImageNet預訓練后再微調(灰色線)兩種方法的邊界框平均檢測率(AP)。
可以看出,隨機權重初始化法開始不及預訓練方法效果好,但隨著迭代次數的增加,逐漸達到了和預訓練法相當的結果。
為了探索多種訓練方案,何愷明等人嘗試了在不同的迭代周期降低學習率。
結果顯示,隨機初始化方法訓練出來的模型需要更多迭代才能收斂,但最終收斂效果不比預訓練再微調的模型差。
主干網絡換成ResNet-101 FPN,這種從零開始訓練的方法依然呈現出一樣的趨勢:從零開始先是AP不及預訓練法,多次迭代后兩者終趨于不分上下。
效果究竟能有多好?答案前面也說過了,和COCO 2017冠軍選手平起平坐。
從零開始模型的效果,由COCO目標檢測任務來證明。在2017版驗證集上,模型的bbox(邊界框)和mask(實例分割)AP分別為50.9和43.2;
他們還在2018年競賽中提交了這個模型,bbox和mask AP分別為51.3和43.6。

這個成績,在沒有經過ImageNet預訓練的單模型中是較好的。
這是一個非常龐大的模型,使用了ResNeXt-152 8×32d基干,GN歸一化方法。從這個成績我們也能看出,這個大模型沒有明顯過擬合,非常健壯(robust)。
實驗中,何愷明等人還用ImageNet預訓練了同樣的模型,再進行微調,成績沒有任何提升。
這種健壯性還有其他體現。
比如說,用更少的數據進行訓練,效果還是能和預訓練再微調方法持平。何愷明在論文中用“Even more surprising”來形容這個結果。
當他們把訓練圖像數量縮減到整個COCO數據集的1/3(35000張圖)、甚至1/10(10000張圖)時,經過多次迭代,隨機初始化看起來還略優于預訓練法的效果。
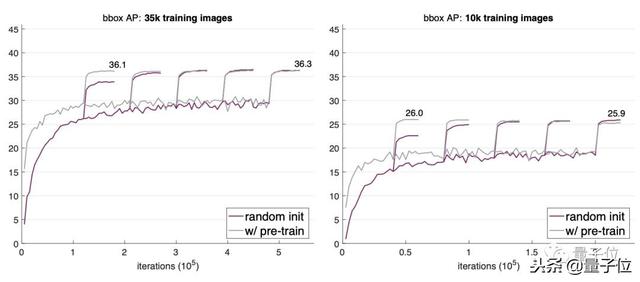
不過,10000張圖已經是極限,繼續降低數據量就不行了。當他們把訓練數據縮減到1000張圖片,出現了明顯的過擬合。
怎樣訓練?
想拋棄ImageNet預訓練,用不著大動干戈提出個新架構。不過,兩點小改動在所難免。
第一點是模型的歸一化方法,第二點是訓練長度。
我們先說模型歸一化(Normalization)。
因為目標檢測任務的輸入數據通常分辨率比較高,導致批次大小不能設置得太大,所以,批歸一化(Batch Normalization,BN)不太適合從零開始訓練目標檢測模型。
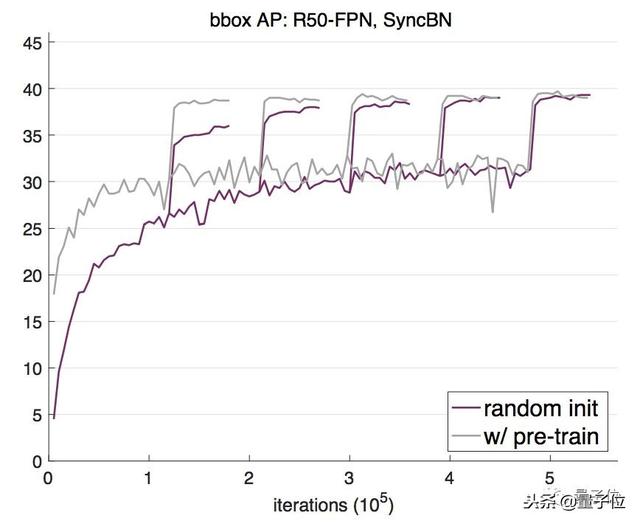
于是,何愷明等人從最近的研究中找了兩種可行的方法:群組歸一化(Group Normalization,GN)和同步批歸一化(Synchronized Batch Normalization,SyncBN)。
GN是吳育昕和何愷明合作提出的,發表在ECCV 2018上,還獲得了較佳論文榮譽提名。這種歸一化方法把通道分成組,然后計算每一組之內的均值和方差。它的計算獨立于批次維度,準確率也不受批次大小影響。
SyncBN則來自曠視的MegDet,和香港中文大學Shu Liu等人的CVPR 2018論文Path Aggregation Network for Instance Segmentation。這是一種跨GPU計算批次統計數據來實現BN的方法,在使用多個GPU時增大了有效批次大小。
歸一化方法選定了,還要注意收斂問題,簡單說是要多訓練幾個周期。
道理很簡單:你總不能指望一個模型從隨機初始化狀態開始訓練,還收斂得跟預訓練模型一樣快吧。
所以,要有耐心,多訓練一會兒。

上圖就是這兩種方法的對比。假設微調的模型已經預訓練了100個周期,那么,從零開始訓練的模型要迭代的周期數是微調模型的3倍,見到的像素數量才能差不多,實例級、圖片級的樣本數量依然差距很大。
也就是說,要想從隨機初始化狀態開始訓練,要有大量樣本。
到底要不要用ImageNet預訓練?
這篇論文還貼心地放出了從實驗中總結的幾條結論:
不改變架構,針對特定任務從零開始訓練是可行的。
從零開始訓練需要更多迭代周期,才能充分收斂。
在很多情況下,甚至包括只用10000張COCO圖片,從零開始訓練的效果不遜于用ImageNet預訓練模型微調。
用ImageNet預訓練能加速在目標任務上的收斂。
ImageNet預訓練未必能減輕過擬合,除非數據量極小。
如果目標任務對定位比識別更敏感,ImageNet預訓練的作用較小。
所以,關于ImageNet預訓練的幾個關鍵問題也就有了答案:
它是必需的嗎?并不是,只要目標數據集和計算力足夠,直接訓練就行。這也說明,要提升模型在目標任務上的表現,收集目標數據和標注更有用,不要增加預訓練數據了。
它有幫助嗎?當然有,它能在目標任務上數據不足的時候帶來大幅提升,還能規避一些目標數據的優化問題,還縮短了研究周期。
我們還需要大數據嗎?需要,但一般性大規模分類級的預訓練數據集就不用了,在目標領域收集數據更有效。
我們還要追求通用表示嗎?依然需要,這還是個值得贊賞的目標。
想更深入地理解這個問題,請讀論文:
論文:
Rethinking ImageNet Pre-training
Kaiming He,Ross Girshick,PiotrDollár
https://arxiv.org/abs/1811.08883
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4841.html
摘要:何愷明和兩位大神最近提出非局部操作為解決視頻處理中時空域的長距離依賴打開了新的方向。何愷明等人提出新的非局部通用網絡結構,超越。殘差連接是何愷明在他的年較佳論文中提出的。 Facebook何愷明和RGB兩位大神最近提出非局部操作non-local operations為解決視頻處理中時空域的長距離依賴打開了新的方向。文章采用圖像去噪中常用的非局部平均的思想處理局部特征與全圖特征點的關系。這種...
摘要:大神何愷明受到了質疑。今天,上一位用戶對何愷明的提出質疑,他認為何愷明年的原始殘差網絡的結果沒有被復現,甚至何愷明本人也沒有。我認為,的可復現性經受住了時間的考驗。 大神何愷明受到了質疑。今天,Reddit 上一位用戶對何愷明的ResNet提出質疑,他認為:何愷明 2015 年的原始殘差網絡的結果沒有被復現,甚至何愷明本人也沒有。網友稱,他沒有發現任何一篇論文復現了原始 ResNet 網絡的...
摘要:從標題上可以看出,這是一篇在實例分割問題中研究擴展分割物體類別數量的論文。試驗結果表明,這個擴展可以改進基準和權重傳遞方法。 今年10月,何愷明的論文Mask R-CNN摘下ICCV 2017的較佳論文獎(Best Paper Award),如今,何愷明團隊在Mask R-CNN的基礎上更近一步,推出了(以下稱Mask^X R-CNN)。這篇論文的第一作者是伯克利大學的在讀博士生胡戎航(清華...
摘要:但是其仍然存在一些問題,而新提出的解決了式歸一化對依賴的影響。上面三節分別介紹了的問題,以及的工作方式,本節將介紹的原因。作者基于此,提出了組歸一化的方式,且效果表明,顯著優于等。 前言Face book AI research(FAIR)吳育昕-何愷明聯合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度學習里程碑式的工作B...
摘要:現在,官方版開源代碼終于來了。同時發布的,是這項研究背后的一個基礎平臺。是的物體檢測平臺,今天宣布開源,它基于,用寫成,這次開放的代碼中就包含了的實現。說,將平臺開源出來,是想要加速世界各地實驗室的研究,推動物體檢測的進展。 等代碼吧。從Mask R-CNN論文亮相至今的10個月里,關于它的討論幾乎都會以這句話收尾。現在,官方版開源代碼終于來了。同時發布的,是這項研究背后的一個基礎平臺:De...

閱讀 1048·2021-11-18 10:02
閱讀 1304·2021-09-23 11:22
閱讀 2606·2021-08-21 14:08
閱讀 1636·2019-08-30 15:55
閱讀 1720·2019-08-30 13:45
閱讀 3139·2019-08-29 16:52
閱讀 3091·2019-08-29 12:18
閱讀 1636·2019-08-26 13:36






