資訊專(zhuān)欄INFORMATION COLUMN

摘要:但是其仍然存在一些問(wèn)題,而新提出的解決了式歸一化對(duì)依賴(lài)的影響。上面三節(jié)分別介紹了的問(wèn)題,以及的工作方式,本節(jié)將介紹的原因。作者基于此,提出了組歸一化的方式,且效果表明,顯著優(yōu)于等。
前言
Face book AI research(FAIR)吳育昕-何愷明聯(lián)合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度學(xué)習(xí)里程碑式的工作Batch normalization,本文將從以下三個(gè)方面為讀者詳細(xì)解讀此篇文章:
What"s wrong with BN ?
How GN work ?
Why GN work ?
Group Normalizition是什么
一句話(huà)概括,Group Normalization(GN)是一種新的深度學(xué)習(xí)歸一化方式,可以替代BN。眾所周知,BN是深度學(xué)習(xí)中常使用的歸一化方法,在提升訓(xùn)練以及收斂速度上發(fā)揮了重大的作用,是深度學(xué)習(xí)上里程碑式的工作。
但是其仍然存在一些問(wèn)題,而新提出的GN解決了BN式歸一化對(duì)batch size依賴(lài)的影響。詳細(xì)的介紹可以參考我另一篇博客:
https://blog.csdn.net/qq_25737169/article/details/...
So, BN到底出了什么問(wèn)題, GN又厲害在哪里?
What"s wrong with BN
BN全名是Batch Normalization,見(jiàn)名知意,其是一種歸一化方式,而且是以batch的維度做歸一化,那么問(wèn)題就來(lái)了,此歸一化方式對(duì)batch是independent的,過(guò)小的batch size會(huì)導(dǎo)致其性能下降,一般來(lái)說(shuō)每GPU上batch設(shè)為32最合適;
但是對(duì)于一些其他深度學(xué)習(xí)任務(wù)batch size往往只有1-2,比如目標(biāo)檢測(cè),圖像分割,視頻分類(lèi)上,輸入的圖像數(shù)據(jù)很大,較大的batchsize顯存吃不消。那么,對(duì)于較小的batch size,其performance是什么樣的呢?如下圖:
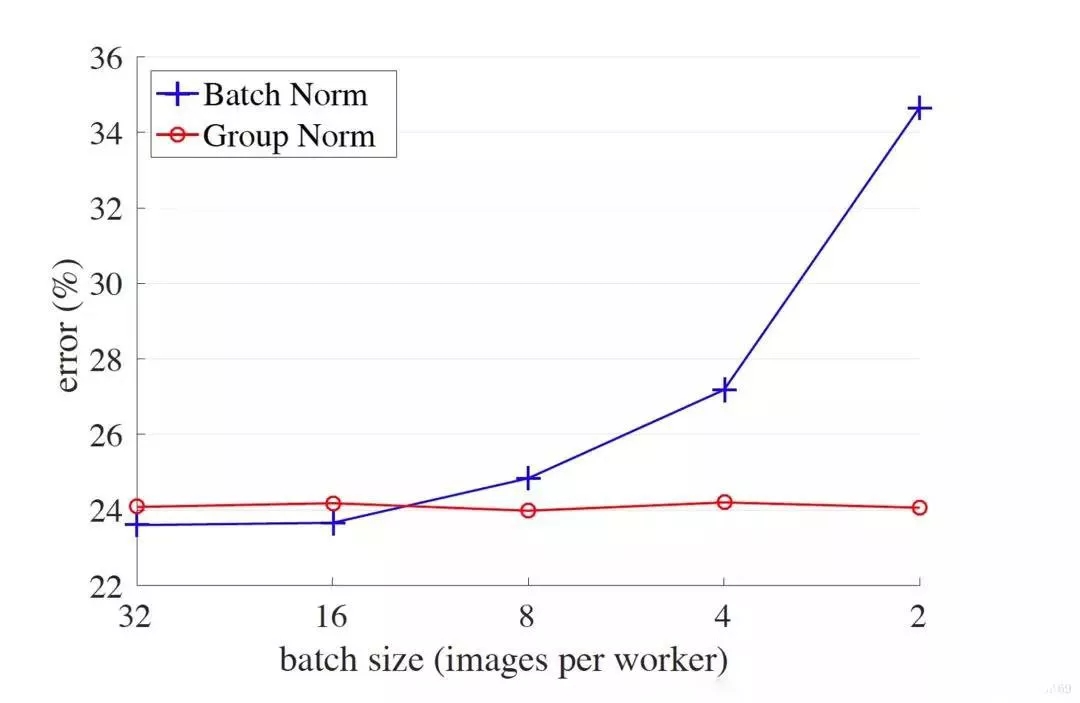
橫軸表示每個(gè)GPU上的batch size大小,從左到右一次遞減,縱軸是誤差率,可見(jiàn),在batch較小的時(shí)候,GN較BN有少于10%的誤差率。
另外,Batch Normalization是在batch這個(gè)維度上Normalization,但是這個(gè)維度并不是固定不變的,比如訓(xùn)練和測(cè)試時(shí)一般不一樣,一般都是訓(xùn)練的時(shí)候在訓(xùn)練集上通過(guò)滑動(dòng)平均預(yù)先計(jì)算好平均-mean,和方差-variance參數(shù)。
在測(cè)試的時(shí)候,不再計(jì)算這些值,而是直接調(diào)用這些預(yù)計(jì)算好的來(lái)用,但是,當(dāng)訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)分布有差別是時(shí),訓(xùn)練機(jī)上預(yù)計(jì)算好的數(shù)據(jù)并不能代表測(cè)試數(shù)據(jù),這就導(dǎo)致在訓(xùn)練,驗(yàn)證,測(cè)試這三個(gè)階段存在inconsistency。
既然明確了問(wèn)題,解決起來(lái)就簡(jiǎn)單了,歸一化的時(shí)候避開(kāi)batch這個(gè)維度是不是可行呢,于是就出現(xiàn)了layer normalization和instance normalization等工作,但是仍比不上本篇介紹的工作GN。
How GN work
GN本質(zhì)上仍是歸一化,但是它靈活的避開(kāi)了BN的問(wèn)題,同時(shí)又不同于Layer Norm,Instance Norm ,四者的工作方式從下圖可窺一斑:

從左到右依次是BN,LN,IN,GN
眾所周知,深度網(wǎng)絡(luò)中的數(shù)據(jù)維度一般是[N, C, H, W]或者[N, H, W,C]格式,N是batch size,H/W是feature的高/寬,C是feature的channel,壓縮H/W至一個(gè)維度,其三維的表示如上圖,假設(shè)單個(gè)方格的長(zhǎng)度是1,那么其表示的是[6, 6,*, * ]
上圖形象的表示了四種norm的工作方式:
BN在batch的維度上norm,歸一化維度為[N,H,W],對(duì)batch中對(duì)應(yīng)的channel歸一化;
LN避開(kāi)了batch維度,歸一化的維度為[C,H,W];
IN 歸一化的維度為[H,W];
而GN介于LN和IN之間,其首先將channel分為許多組(group),對(duì)每一組做歸一化,及先將feature的維度由[N, C, H, W]reshape為[N, G,C//G , H, W],歸一化的維度為[C//G , H, W]
事實(shí)上,GN的極端情況就是LN和I N,分別對(duì)應(yīng)G等于C和G等于1,作者在論文中給出G設(shè)為32較好
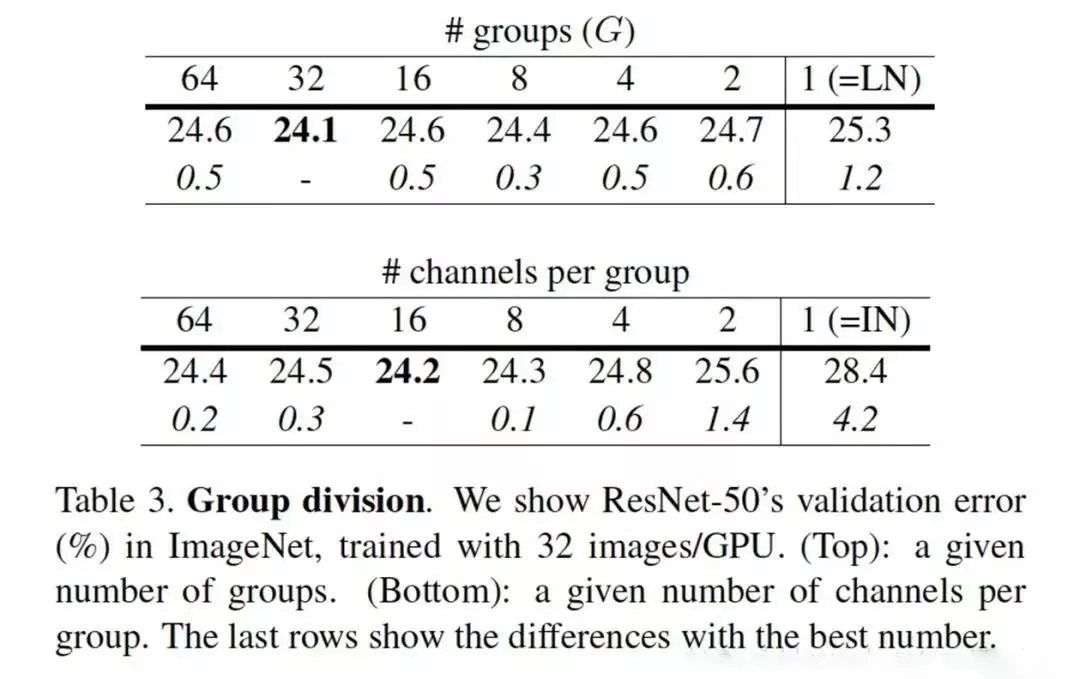
由此可以看出,GN和BN是有很多相似之處的,代碼相比較BN改動(dòng)只有一兩行而已,論文給出的代碼實(shí)現(xiàn)如下:
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x: input features with shape [N,C,H,W]
# gamma, beta: scale and offset, with shape [1,C,1,1]
# G: number of groups for GN
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C // G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
其中beta 和gama參數(shù)是norm中可訓(xùn)練參數(shù),表示平移和縮放因子,具體介紹見(jiàn)博客,從上述norm的對(duì)比來(lái)看,不得不佩服作者四兩撥千斤的功力,僅僅是稍微的改動(dòng)就能擁有舉重若輕的效果。
Why GN work
上面三節(jié)分別介紹了BN的問(wèn)題,以及GN的工作方式,本節(jié)將介紹GN work的原因。
傳統(tǒng)角度來(lái)講,在深度學(xué)習(xí)沒(méi)有火起來(lái)之前,提取特征通常是使用SIFT,HOG和GIST特征,這些特征有一個(gè)共性,都具有按group表示的特性,每一個(gè)group由相同種類(lèi)直方圖的構(gòu)建而成,這些特征通常是對(duì)在每個(gè)直方圖(histogram)或每個(gè)方向(orientation)上進(jìn)行組歸一化(group-wise norm)而得到。
而更高維的特征比如VLAD和Fisher Vectors(FV)也可以看作是group-wise feature,此處的group可以被認(rèn)為是每個(gè)聚類(lèi)(cluster)下的子向量sub-vector。
從深度學(xué)習(xí)上來(lái)講,完全可以認(rèn)為卷積提取的特征是一種非結(jié)構(gòu)化的特征或者向量,拿網(wǎng)絡(luò)的第一層卷積為例,卷積層中的的卷積核filter1和此卷積核的其他經(jīng)過(guò)transform過(guò)的版本filter2(transform可以是horizontal flipping等),在同一張圖像上學(xué)習(xí)到的特征應(yīng)該是具有相同的分布,那么,具有相同的特征可以被分到同一個(gè)group中,按照個(gè)人理解,每一層有很多的卷積核,這些核學(xué)習(xí)到的特征并不完全是獨(dú)立的,某些特征具有相同的分布,因此可以被group。
導(dǎo)致分組(group)的因素有很多,比如頻率、形狀、亮度和紋理等,HOG特征根據(jù)orientation分組,而對(duì)神經(jīng)網(wǎng)絡(luò)來(lái)講,其提取特征的機(jī)制更加復(fù)雜,也更加難以描述,變得不那么直觀。
另在神經(jīng)科學(xué)領(lǐng)域,一種被廣泛接受的計(jì)算模型是對(duì)cell的響應(yīng)做歸一化,此現(xiàn)象存在于淺層視覺(jué)皮層和整個(gè)視覺(jué)系統(tǒng)。
作者基于此,提出了組歸一化(Group Normalization)的方式,且效果表明,顯著優(yōu)于BN、LN、IN等。GN的歸一化方式避開(kāi)了batch size對(duì)模型的影響,特征的group歸一化同樣可以解決$Internal$ $Covariate$ $Shift$的問(wèn)題,并取得較好的效果。
效果展示
showtime!
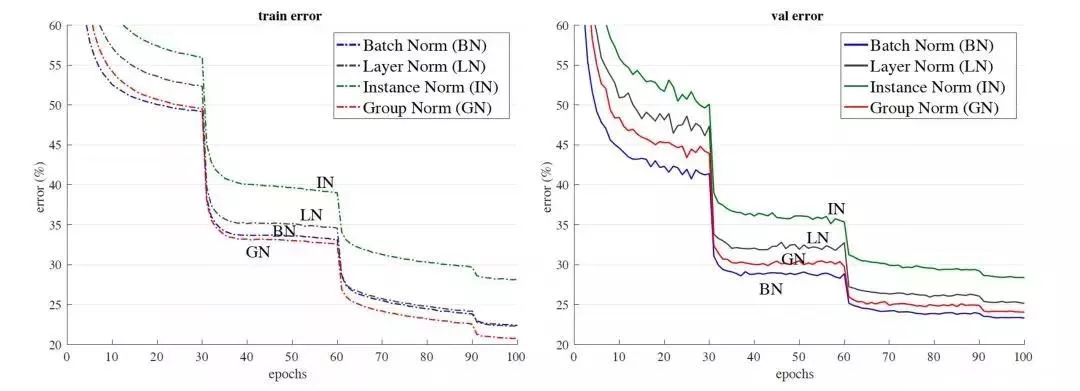
以resnet50為base model,batchsize設(shè)置為32在imagenet數(shù)據(jù)集上的訓(xùn)練誤差(左)和測(cè)試誤差(右)。GN沒(méi)有表現(xiàn)出很大的優(yōu)勢(shì),在測(cè)試誤差上稍大于使用BN的結(jié)果。
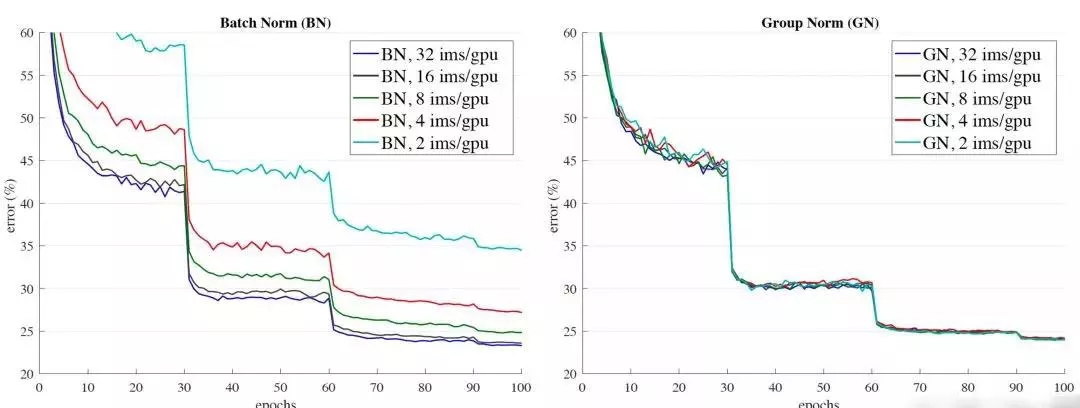
可以很容易的看出,GN對(duì)batch size的魯棒性更強(qiáng)
同時(shí),作者以VGG16為例,分析了某一層卷積后的特征分布學(xué)習(xí)情況,分別根據(jù)不使用Norm 和使用BN,GN做了實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如下:
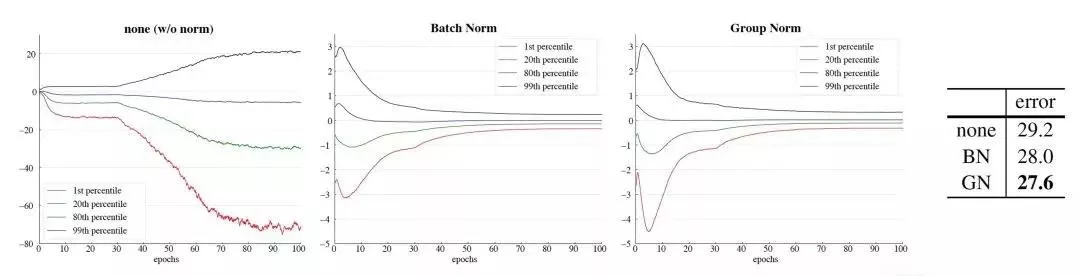
統(tǒng)一batch size設(shè)置的是32,最左圖是不使用norm的conv5的特征學(xué)習(xí)情況,中間是使用了BN結(jié)果,最右是使用了GN的學(xué)習(xí)情況,相比較不使用norm,使用norm的學(xué)習(xí)效果顯著,而后兩者學(xué)習(xí)情況相似,不過(guò)更改小的batch size后,BN是比不上GN的。
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4748.html
摘要:為了探索多種訓(xùn)練方案,何愷明等人嘗試了在不同的迭代周期降低學(xué)習(xí)率。實(shí)驗(yàn)中,何愷明等人還用預(yù)訓(xùn)練了同樣的模型,再進(jìn)行微調(diào),成績(jī)沒(méi)有任何提升。何愷明在論文中用來(lái)形容這個(gè)結(jié)果。 何愷明,RBG,Piotr Dollár。三位從Mask R-CNN就開(kāi)始合作的大神搭檔,剛剛再次聯(lián)手,一文終結(jié)了ImageNet預(yù)訓(xùn)練時(shí)代。他們所針對(duì)的是當(dāng)前計(jì)算機(jī)視覺(jué)研究中的一種常規(guī)操作:管它什么任務(wù),拿來(lái)ImageN...
摘要:大神何愷明受到了質(zhì)疑。今天,上一位用戶(hù)對(duì)何愷明的提出質(zhì)疑,他認(rèn)為何愷明年的原始?xì)埐罹W(wǎng)絡(luò)的結(jié)果沒(méi)有被復(fù)現(xiàn),甚至何愷明本人也沒(méi)有。我認(rèn)為,的可復(fù)現(xiàn)性經(jīng)受住了時(shí)間的考驗(yàn)。 大神何愷明受到了質(zhì)疑。今天,Reddit 上一位用戶(hù)對(duì)何愷明的ResNet提出質(zhì)疑,他認(rèn)為:何愷明 2015 年的原始?xì)埐罹W(wǎng)絡(luò)的結(jié)果沒(méi)有被復(fù)現(xiàn),甚至何愷明本人也沒(méi)有。網(wǎng)友稱(chēng),他沒(méi)有發(fā)現(xiàn)任何一篇論文復(fù)現(xiàn)了原始 ResNet 網(wǎng)絡(luò)的...
摘要:何愷明和兩位大神最近提出非局部操作為解決視頻處理中時(shí)空域的長(zhǎng)距離依賴(lài)打開(kāi)了新的方向。何愷明等人提出新的非局部通用網(wǎng)絡(luò)結(jié)構(gòu),超越。殘差連接是何愷明在他的年較佳論文中提出的。 Facebook何愷明和RGB兩位大神最近提出非局部操作non-local operations為解決視頻處理中時(shí)空域的長(zhǎng)距離依賴(lài)打開(kāi)了新的方向。文章采用圖像去噪中常用的非局部平均的思想處理局部特征與全圖特征點(diǎn)的關(guān)系。這種...
摘要:從標(biāo)題上可以看出,這是一篇在實(shí)例分割問(wèn)題中研究擴(kuò)展分割物體類(lèi)別數(shù)量的論文。試驗(yàn)結(jié)果表明,這個(gè)擴(kuò)展可以改進(jìn)基準(zhǔn)和權(quán)重傳遞方法。 今年10月,何愷明的論文Mask R-CNN摘下ICCV 2017的較佳論文獎(jiǎng)(Best Paper Award),如今,何愷明團(tuán)隊(duì)在Mask R-CNN的基礎(chǔ)上更近一步,推出了(以下稱(chēng)Mask^X R-CNN)。這篇論文的第一作者是伯克利大學(xué)的在讀博士生胡戎航(清華...
摘要:目前目標(biāo)檢測(cè)領(lǐng)域的深度學(xué)習(xí)方法主要分為兩類(lèi)的目標(biāo)檢測(cè)算法的目標(biāo)檢測(cè)算法。原來(lái)多數(shù)的目標(biāo)檢測(cè)算法都是只采用深層特征做預(yù)測(cè),低層的特征語(yǔ)義信息比較少,但是目標(biāo)位置準(zhǔn)確高層的特征語(yǔ)義信息比較豐富,但是目標(biāo)位置比較粗略。 目前目標(biāo)檢測(cè)領(lǐng)域的深度學(xué)習(xí)方法主要分為兩類(lèi):two stage的目標(biāo)檢測(cè)算法;one stage的目標(biāo)檢測(cè)算法。前者是先由算法生成一系列作為樣本的候選框,再通過(guò)卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行樣本...

閱讀 2461·2023-04-26 02:18
閱讀 1262·2021-10-14 09:43
閱讀 3822·2021-09-26 10:00
閱讀 6945·2021-09-22 15:28
閱讀 2535·2019-08-30 15:54
閱讀 2600·2019-08-30 15:52
閱讀 474·2019-08-29 11:30
閱讀 3465·2019-08-29 11:05






