資訊專欄INFORMATION COLUMN

摘要:大神何愷明受到了質(zhì)疑。今天,上一位用戶對何愷明的提出質(zhì)疑,他認(rèn)為何愷明年的原始?xì)埐罹W(wǎng)絡(luò)的結(jié)果沒有被復(fù)現(xiàn),甚至何愷明本人也沒有。我認(rèn)為,的可復(fù)現(xiàn)性經(jīng)受住了時間的考驗。
大神何愷明受到了質(zhì)疑。
今天,Reddit 上一位用戶對何愷明的ResNet提出質(zhì)疑,他認(rèn)為:
何愷明 2015 年的原始?xì)埐罹W(wǎng)絡(luò)的結(jié)果沒有被復(fù)現(xiàn),甚至何愷明本人也沒有。

網(wǎng)友稱,他沒有發(fā)現(xiàn)任何一篇論文復(fù)現(xiàn)了原始 ResNet 網(wǎng)絡(luò)的結(jié)果,或與原始?xì)埐罹W(wǎng)絡(luò)論文的結(jié)果進(jìn)行比較,并且所有的論文報告的數(shù)字都比原始論文的更差。
論文中報告的 top1 錯誤率的結(jié)果如下:
ResNet-50 @ 20.74
resnet - 101 @ 19.87
resnet - 152 @ 19.38
何愷明等人在2015年提出ResNet之后,ResNet很快成為計算機(jī)視覺最流行的架構(gòu)之一,這篇論文已經(jīng)被引用了超過20000次。

不過,網(wǎng)友稱,DenseNet (https://arxiv.org/abs/1608.06993, 3000 + 引用) 和 Wide ResNets (https://arxiv.org/abs/1605.07146, ~1000 引用) 都沒有使用這個結(jié)果。甚至在何愷明最近的一篇論文中,也沒有使用這個結(jié)果。
按理說,何愷明這篇論文應(yīng)該是這個領(lǐng)域被引用最多的論文之一,原始 ResNet 的結(jié)果真的沒有被復(fù)現(xiàn)出來嗎?在繼續(xù)討論之前,讓我們先來回顧一下ResNet的思想,以及它之所以強(qiáng)大的原因。
重新審視 ResNet:計算機(jī)視覺最流行的架構(gòu)之一
2015 年,ResNet 大大吸引了人們的眼球。實際上,早在 ILSVRC2012 分類競賽中,AlexNet 取得勝利,深度殘差網(wǎng)絡(luò)(deep Residual Network)就成為過去幾年中計算機(jī)視覺和深度學(xué)習(xí)領(lǐng)域最具突破性的工作。ResNet 使得訓(xùn)練深達(dá)數(shù)百甚至數(shù)千層的網(wǎng)絡(luò)成為可能,而且性能仍然優(yōu)異。
由于其表征能力強(qiáng),ResNet 在圖像分類任務(wù)之外的許多計算機(jī)視覺應(yīng)用上也取得了巨大的性能提升,例如對象檢測和人臉識別。?
自 2015 年以來,許多研究對 ResNet 架構(gòu)進(jìn)行了調(diào)整和改進(jìn)。其中最著名的一些 ResNet 變體包括:
何愷明等人提出的 ResNeXt
康奈爾大學(xué)、清華大學(xué)和 Facebook 聯(lián)合提出的 DenseNet
谷歌 MobileNet
孫劍團(tuán)隊 ShuffleNet
顏水成團(tuán)隊的雙通道網(wǎng)絡(luò) DPN
最近南開大學(xué)、牛津大學(xué)等提出的 Res2Net
……
那么 ResNet 的核心思想是什么呢?
根據(jù)泛逼近定理(universal approximation theorem),如果給定足夠的容量,一個單層的前饋網(wǎng)絡(luò)就足以表示任何函數(shù)。但是,這個層可能是非常大的,而且網(wǎng)絡(luò)容易過擬合數(shù)據(jù)。因此,研究界有一個共同的趨勢,就是網(wǎng)絡(luò)架構(gòu)需要更深。
從 AlexNet 的提出以來,state-of-the art 的 CNN 架構(gòu)都是越來越深。雖然 AlexNet 只有 5 層卷積層,但后來的 VGG 網(wǎng)絡(luò)和 GoogLeNet 分別有 19 層和 22 層。
但是,如果只是簡單地將層堆疊在一起,增加網(wǎng)絡(luò)的深度并不會起太大作用。這是由于難搞的梯度消失(vanishing gradient)問題,深層的網(wǎng)絡(luò)很難訓(xùn)練。因為梯度反向傳播到前一層,重復(fù)相乘可能使梯度無窮小。結(jié)果就是,隨著網(wǎng)絡(luò)的層數(shù)更深,其性能趨于飽和,甚至開始迅速下降。
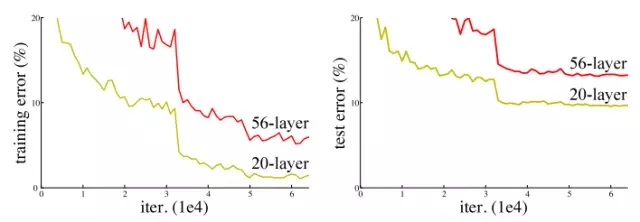
網(wǎng)絡(luò)深度增加導(dǎo)致性能下降
在 ResNet 之前,已經(jīng)出現(xiàn)好幾種處理梯度消失問題的方法,例如,2015 年 C. Szegedy 等人提出的 GoogLeNet 在中間層增加一個輔助損失(auxiliary loss)作為額外的監(jiān)督,但遺憾的是,沒有一個方法能夠真正解決這個問題。
ResNet 的核心思想是引入一個 “恒等捷徑連接”(identity shortcut connection),直接跳過一層或多層,如下圖所示:

一個殘差塊
何愷明等人于 2015 年發(fā)表的論文《用于圖像識別的深度殘差學(xué)習(xí)》(Deep Residual Learning for Image Recognition)中,認(rèn)為堆疊的層不應(yīng)該降低網(wǎng)絡(luò)的性能,因為我們可以簡單地在當(dāng)前網(wǎng)絡(luò)上堆疊identity映射(層不處理任何事情),并且所得到的架構(gòu)性能不變。這表明,較深的模型所產(chǎn)生的訓(xùn)練誤差不應(yīng)比較淺的模型的誤差更高。作者假設(shè)讓堆疊的層擬合一個殘差映射(residual mapping)要比讓它們直接擬合所需的底層映射更容易。上面的殘差塊(residual block)顯然仍讓它做到這點。
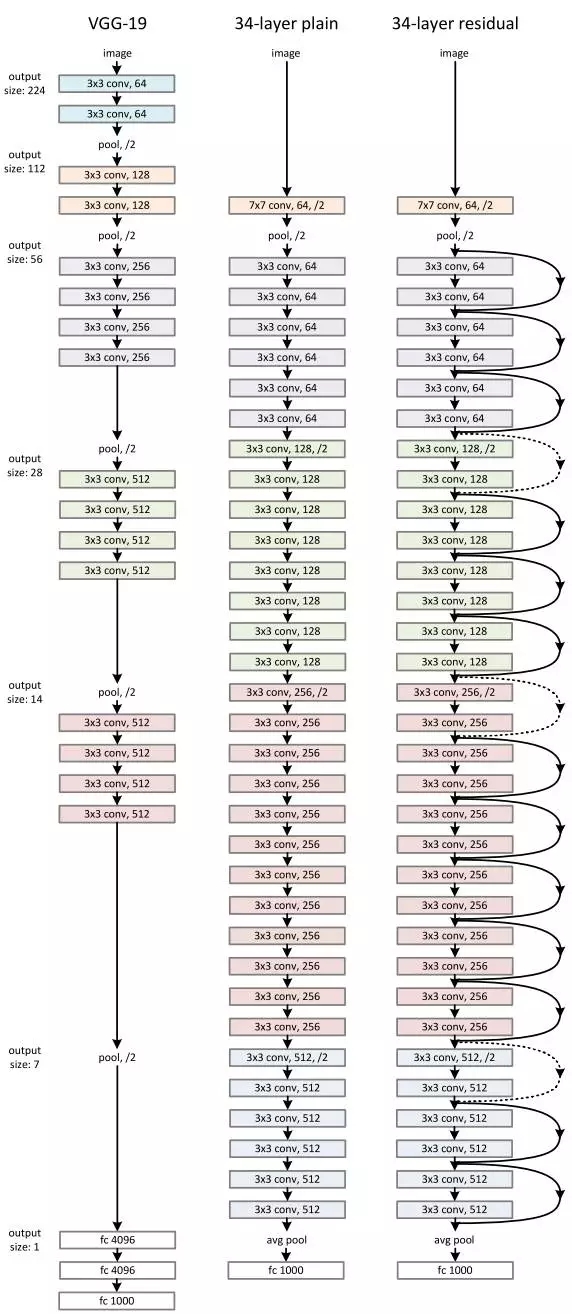
ResNet 的架構(gòu)
那么這次質(zhì)疑“不能復(fù)現(xiàn)”的結(jié)果是什么呢?討論點集中在原始論文中的表3和表4:
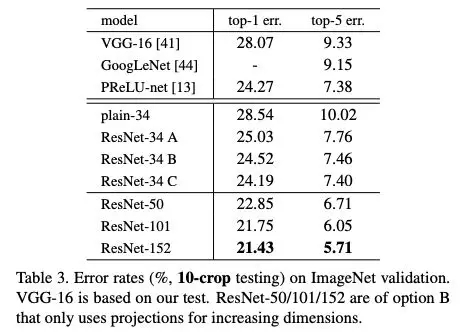
表3:ImageNet驗證集上10-crop測試的錯誤率
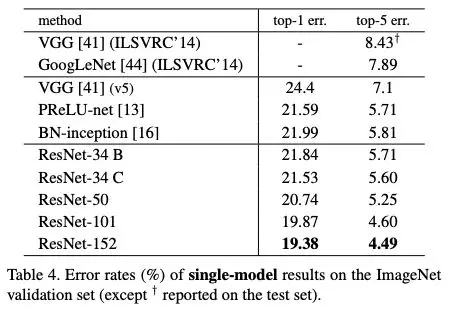
表4:ImageNet驗證集上sigle-model的錯誤率結(jié)果
由于其結(jié)果優(yōu)異,ResNet 迅速成為各種計算機(jī)視覺任務(wù)最流行的架構(gòu)之一。
新智元昨天發(fā)表的文章《對 ResNet 本質(zhì)的一些思考》,對 ResNet 做了較深入的探討。作者表示:
不得不贊嘆 Kaiming He 的天才,ResNet 這東西,描述起來固然簡單,但是對它的理解每深一層,就會愈發(fā)發(fā)現(xiàn)它的精妙及優(yōu)雅,從數(shù)學(xué)上解釋起來非常簡潔,非常令人信服,而且直切傳統(tǒng)痛點。
ResNet 本質(zhì)上就干了一件事:降低數(shù)據(jù)中信息的冗余度。
具體說來,就是對非冗余信息采用了線性激活(通過 skip connection 獲得無冗余的 identity 部分),然后對冗余信息采用了非線性激活(通過 ReLU 對 identity 之外的其余部分進(jìn)行信息提取 / 過濾,提取出的有用信息即是殘差)。
其中,提取 identity 這一步,就是 ResNet 思想的核心。
何愷明回應(yīng)ResNet結(jié)果不能復(fù)現(xiàn)
再回到文章開頭的討論:原始 ResNet 的結(jié)果真的無法復(fù)現(xiàn)嗎?
針對網(wǎng)友的質(zhì)疑,不少人在帖子下回復(fù),可以總結(jié)為兩個方面:
ImageNet 有多種測試策略,后來的論文在復(fù)現(xiàn)ImageNet時采用的是當(dāng)時流行的策略,而非 ResNet 原始論文的策略;
后來的論文在訓(xùn)練時采用了一些與原始論文不同的優(yōu)化技巧,使得結(jié)果甚至比原始 ResNet 論文的結(jié)果更好
何愷明本人也第一時間作出回復(fù):
ImageNet 上有幾種測試策略:(i) single-scale, single-crop 測試; (ii) single-scale, multi-crop 或 fully-convolutional 測試;(iii) multi-scale, multi-crop 或 fully-convolutional 測試;(iv) 多個模型集成。
在這些設(shè)置下,這篇論文的 ResNet-50 模型的 top-1 錯誤率為:(i) 24.7% (1-crop,如我的 GitHub repo 所展示), (ii) 22.85% (10-crop,論文中的表 3),(iii) 20.74% (full -conv, multi-scale, 論文中的 Table 4)。論文中使用的 (ii) 和 (iii) 的描述見第 3.4 節(jié)。
當(dāng)時是 2015 年,(ii) 和 (iii) 是最流行的評估設(shè)置。策略 (ii) 是 AlexNet 的默認(rèn)值 (10-crop), (ii) 和 (iii) 是 OverFeat、VGG 和 GoogleNet 中常用的設(shè)置。Single-crop 測試在當(dāng)時并不常用。
2015/2016 年后,Single-crop 測試開始流行。這在一定程度上是因為社區(qū)已經(jīng)變成一個對網(wǎng)絡(luò)精度的差異很感興趣的環(huán)境 (因此 single-crop 足以提供這些差異)。
ResNet 是近年來被復(fù)現(xiàn)得最多的架構(gòu)之一。在我的 GitHub repo 中發(fā)布的 ResNet-50 模型是第一次訓(xùn)練的 ResNet-50,盡管如此,它仍然十分強(qiáng)大,并且在今天的許多計算機(jī)視覺任務(wù)中仍然是預(yù)訓(xùn)練的骨干。我認(rèn)為,ResNet 的可復(fù)現(xiàn)性經(jīng)受住了時間的考驗。
Reddit用戶ajmooch指出:
你忘記了測試時數(shù)據(jù)增強(qiáng) (test-time augmentation, TTA)。表 4 中的數(shù)字來自于不同 scales 的 multi-crop 的平均預(yù)測 (以計算時間為代價優(yōu)化精度),而其他論文中的數(shù)字是 single-crop 的。
表 3 列出了 10-crop 測試的數(shù)據(jù)。表 4 的數(shù)字更好,所以它肯定不是 single crop 的數(shù)字。我的猜測是 n-crop,可能還包括其他增強(qiáng),比如翻轉(zhuǎn)圖像。
這個帖子讀起來有點像指責(zé),我不喜歡。ResNet 因為在 ImageNet 測試集上表現(xiàn)出色而著名,而 ImageNet 測試集隱藏在服務(wù)器上,他們沒有辦法在那里處理這些數(shù)字。ResNet 是我能想到的被復(fù)現(xiàn)最多的架構(gòu)之一。它顯然是合理的。在開始批評別人之前,我們應(yīng)該先了解我們在批評什么。
谷歌大腦工程師hardmaru也回復(fù)道:
在何愷明加入 FAIR 之前, FAIR Torch-7 團(tuán)隊獨立復(fù)現(xiàn)了 ResNet:https://github.com/facebook/fb.resnet.torch
經(jīng)過訓(xùn)練的 ResNet 18、34、50、101、152 和 200 模型,可供下載。我們包括了使用自定義數(shù)據(jù)集,對圖像進(jìn)行分類并獲得模型的 top5 預(yù)測,以及使用預(yù)訓(xùn)練的模型提取圖像特征的說明。
他們的結(jié)果如下表:

經(jīng)過訓(xùn)練的模型比原始 ResNet 模型獲得了更好的錯誤率。
但是,考慮到:
這個實現(xiàn)與 ResNet 論文在以下幾個方面有所不同:
規(guī)模擴(kuò)大 (Scale augmentation):我們使用了 GooLeNet 中的的規(guī)模和長寬比,而不是 ResNet 論文中的 scale augmentation。我們發(fā)現(xiàn)這樣的驗證錯誤更好。
顏色增強(qiáng) (Color augmentation):除了在 ResNet 論文中使用的 AlexNet 風(fēng)格的顏色增強(qiáng)外,我們還使用了 Andrew Howard 提出的的亮度失真 (photometric distortions)。
權(quán)重衰減 (Weight decay):我們將權(quán)重衰減應(yīng)用于所有權(quán)重和偏差,而不僅僅是卷積層的權(quán)重。
Strided convolution:當(dāng)使用瓶頸架構(gòu)時,我們在 3x3 卷積中使用 stride 2,而不是在第一個 1x1 卷積。
何愷明的 GitHub 有 Caffe 模型訓(xùn)練的原始版本和更新版本的 resnet,而且報告的也不同:
(https://github.com/KaimingHe/deep-residual-networks/blob/master/README.md)

也許他的 GitHub 報告中的方法與論文不一致,但為了可重復(fù)性而不使用相同的方法也有點奇怪。
也許 arxiv 或 repo 應(yīng)該使用一致的數(shù)字進(jìn)行更新,或者更好的是,使用多次獨立運行的平均值。
但是隨著 SOTA 的改進(jìn)和該領(lǐng)域的發(fā)展,其他人花費資源來產(chǎn)生舊的結(jié)果的動機(jī)就更少了。人們寧愿使用他們的資源來復(fù)現(xiàn)當(dāng)前的 SOTA 或嘗試其他新想法。
許多人引用它是因為它的概念本身,而不是為了報告排行榜分?jǐn)?shù)。
聲明:本文版權(quán)歸原作者所有,文章收集于網(wǎng)絡(luò),為傳播信息而發(fā),如有侵權(quán),請聯(lián)系小編及時處理,謝謝!歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4864.html
摘要:為了探索多種訓(xùn)練方案,何愷明等人嘗試了在不同的迭代周期降低學(xué)習(xí)率。實驗中,何愷明等人還用預(yù)訓(xùn)練了同樣的模型,再進(jìn)行微調(diào),成績沒有任何提升。何愷明在論文中用來形容這個結(jié)果。 何愷明,RBG,Piotr Dollár。三位從Mask R-CNN就開始合作的大神搭檔,剛剛再次聯(lián)手,一文終結(jié)了ImageNet預(yù)訓(xùn)練時代。他們所針對的是當(dāng)前計算機(jī)視覺研究中的一種常規(guī)操作:管它什么任務(wù),拿來ImageN...
摘要:何愷明和兩位大神最近提出非局部操作為解決視頻處理中時空域的長距離依賴打開了新的方向。何愷明等人提出新的非局部通用網(wǎng)絡(luò)結(jié)構(gòu),超越。殘差連接是何愷明在他的年較佳論文中提出的。 Facebook何愷明和RGB兩位大神最近提出非局部操作non-local operations為解決視頻處理中時空域的長距離依賴打開了新的方向。文章采用圖像去噪中常用的非局部平均的思想處理局部特征與全圖特征點的關(guān)系。這種...
摘要:從標(biāo)題上可以看出,這是一篇在實例分割問題中研究擴(kuò)展分割物體類別數(shù)量的論文。試驗結(jié)果表明,這個擴(kuò)展可以改進(jìn)基準(zhǔn)和權(quán)重傳遞方法。 今年10月,何愷明的論文Mask R-CNN摘下ICCV 2017的較佳論文獎(Best Paper Award),如今,何愷明團(tuán)隊在Mask R-CNN的基礎(chǔ)上更近一步,推出了(以下稱Mask^X R-CNN)。這篇論文的第一作者是伯克利大學(xué)的在讀博士生胡戎航(清華...
摘要:但是其仍然存在一些問題,而新提出的解決了式歸一化對依賴的影響。上面三節(jié)分別介紹了的問題,以及的工作方式,本節(jié)將介紹的原因。作者基于此,提出了組歸一化的方式,且效果表明,顯著優(yōu)于等。 前言Face book AI research(FAIR)吳育昕-何愷明聯(lián)合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度學(xué)習(xí)里程碑式的工作B...
摘要:目前目標(biāo)檢測領(lǐng)域的深度學(xué)習(xí)方法主要分為兩類的目標(biāo)檢測算法的目標(biāo)檢測算法。原來多數(shù)的目標(biāo)檢測算法都是只采用深層特征做預(yù)測,低層的特征語義信息比較少,但是目標(biāo)位置準(zhǔn)確高層的特征語義信息比較豐富,但是目標(biāo)位置比較粗略。 目前目標(biāo)檢測領(lǐng)域的深度學(xué)習(xí)方法主要分為兩類:two stage的目標(biāo)檢測算法;one stage的目標(biāo)檢測算法。前者是先由算法生成一系列作為樣本的候選框,再通過卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行樣本...

閱讀 904·2021-09-29 09:35
閱讀 1252·2021-09-28 09:36
閱讀 1522·2021-09-24 10:38
閱讀 1066·2021-09-10 11:18
閱讀 631·2019-08-30 15:54
閱讀 2496·2019-08-30 13:22
閱讀 1963·2019-08-30 11:14
閱讀 697·2019-08-29 12:35






