資訊專欄INFORMATION COLUMN

摘要:鏈接是他們在數據集上達到了較先進的性能,并且在高度重疊的數字上表現出比卷積神經網絡好得多的結果。在常規的卷積神經網絡中,通常會有多個匯聚層,不幸的是,這些匯聚層的操作往往會丟失很多信息,比如目標對象的準確位置和姿態。
PPT
由于筆者能力有限,本篇所有備注皆為專知內容組成員根據講者視頻和PPT內容自行補全,不代表講者本人的立場與觀點。

膠囊網絡Capsule Networks
你好!我是AurélienGéron,在這個視頻中,我將告訴你們關于膠囊網絡,一個神經網絡的新架構。Geoffrey Hinton幾年前就有膠囊網絡的想法,他在2011年發表了一篇文章,介紹了許多重要的想法,他還是很難讓這些想法實現,但直到現在。

幾周前,在2017年10月,一篇名為“動態路由膠囊” 由作者Sara Sabour,NicholasFrosst,當然還有Geoffrey Hinton一起發表了。?
鏈接是:https://arxiv.org/abs/1710.09829
他們在MNIST數據集上達到了較先進的性能,并且在高度重疊的數字上表現出比卷積神經網絡好得多的結果。那么膠囊網絡究竟是什么?
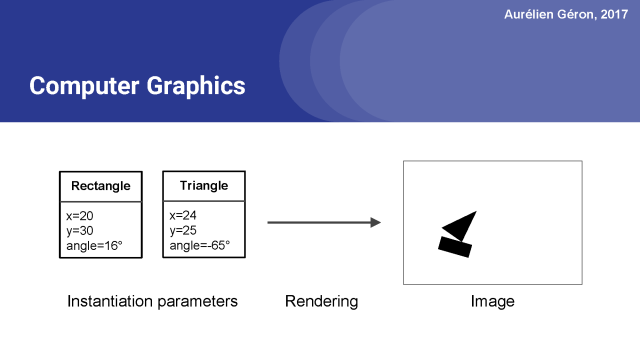
在計算機圖形學中,你表達一個場景都是從抽象的表示開始。
例如,位置x=20和y=30的矩形,旋轉16°,等等。每個對象類型都有不同的實例化參數。然后你調用一些渲染函數,然后你得到一個圖像。
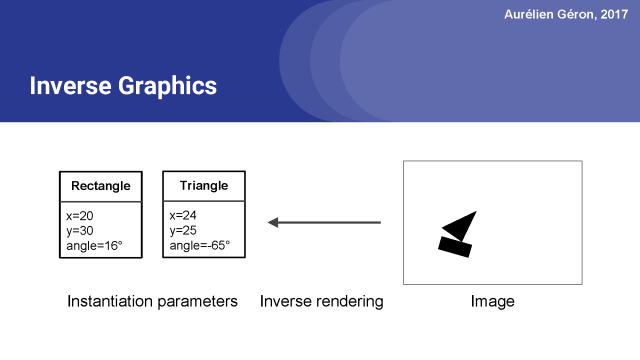
逆向圖形,只是上面抽象表示的一個逆向過程。你從一個圖像開始,你試著找出它包含的對象,以及它們的實例化參數是什么。
一個膠囊網絡基本上是一個試圖執行反向圖形解析的神經網絡。
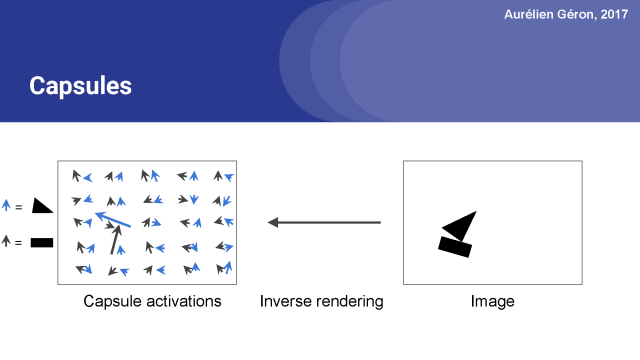
它由許多膠囊組成。一個膠囊是一個函數,它試圖在給特定位置的目標預測它的存在性以及實例化參數。
例如,上面的網絡包含50個膠囊。 箭頭表示這些膠囊的輸出向量。 膠囊輸出許多向量。 黑色箭頭對應于試圖找到矩形的膠囊,而藍色箭頭則表示膠囊尋找三角形的輸出。激活向量的長度表示膠囊正在查找的物體確實存在的估計概率。?
你可以看到大多數箭頭很小,這意味著膠囊沒有檢測到任何東西,但是兩個箭頭相當長。 這意味著在這些位置的膠囊非常有自信能夠找到他們要尋找的東西,在這個情況下是矩形和三角形。
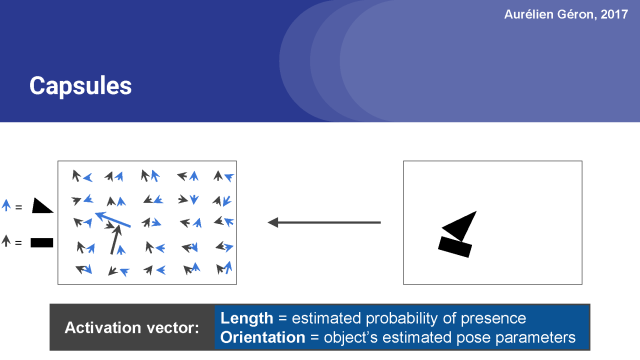
接下來,激活向量的方向編碼對象的實例化參數,例如在這個情況下,對象的旋轉,但也可能是它的厚度,它是如何拉伸或傾斜的,它的確切位置(可能有輕微的翻轉),等等。為了簡單起見,我只關注旋轉參數,但在真實的膠囊網絡中,激活向量可能有5, 10個維度或更多。
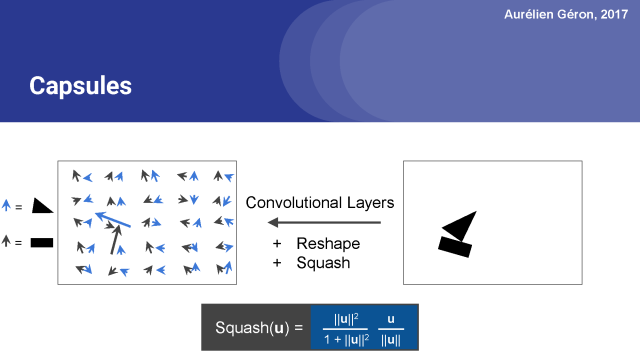
實際上,實現這一點的一個好方法是首先應用一對卷積層,就像在常規的卷積神經網絡中一樣。這將輸出一個包含一堆特征映射的數組。 然后你可以重塑這個數組來獲得每個位置的一組向量。
例如,假設卷積圖層輸出一個包含18個特征圖(2×9)的數組,則可以輕松地重新組合這個數組以獲得每個位置9個維度的2個向量。 你也可以得到3個6維的向量,等等。
這看起來像在這里在每個位置用兩個向量表示的膠囊網絡。最后一步是確保沒有向量長度大于1,因為向量的長度意味著代表一個概率,它不能大于1。
為此,我們應用一個squashing(壓扁)函數。它保留了矢量的方向,但將它壓扁,以確保它的長度在0到1之間。
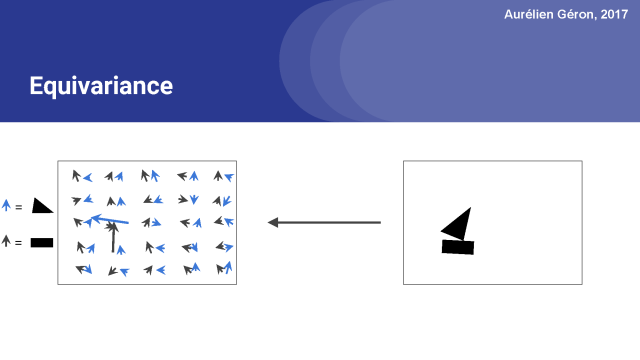
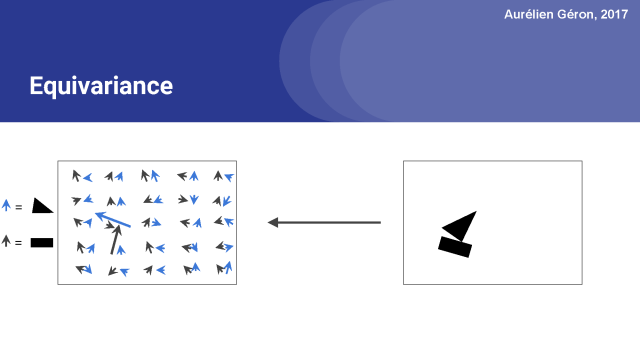
膠囊網絡的一個關鍵特性是在網絡中保存關于物體位置和姿態的詳細信息。例如,如果我稍微旋轉一下圖像,注意激活向量也會稍微改變,對吧?這叫做equivariance。
在常規的卷積神經網絡中,通常會有多個匯聚層,不幸的是,這些匯聚層的操作往往會丟失很多信息,比如目標對象的準確位置和姿態。如果你只是想要對整個圖像進行分類,就算丟失這些信息也沒什么大不了的,但是這些丟失的信息對你進行較精確的圖像分割或對象檢測(這需要較精確的位置和姿勢)等任務是非常重要的。
膠囊的equivariance等變特性使得它在這些任務上都有非常有前景。

好了,現在讓我們來看看膠囊網絡如何處理由層次結構組成的對象。
例如,考慮一個船,它的位置為x=22,y=28,旋轉16°。
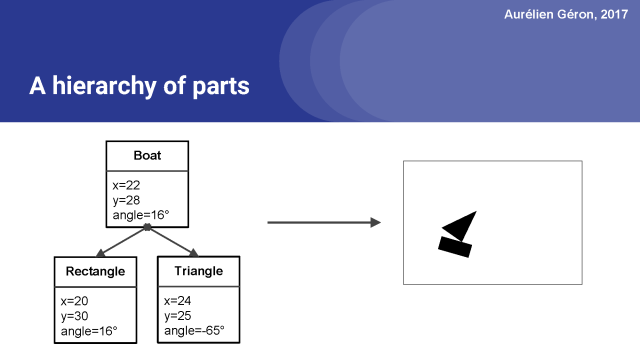
這艘船是由幾個部件組成的。在當前演示的情況下,也就是說船由一個矩形和一個三角形組成。
現在我們要做相反的事情,我們需要逆向圖形,所以我們想要從圖像到這個完整的層次結構的部件和它們的實例化參數。
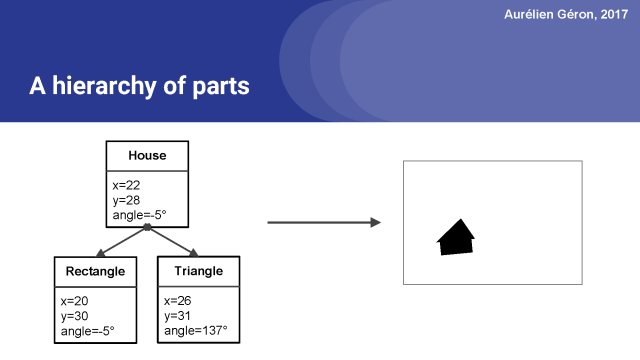
同樣,我們也可以繪制一個房子,使用相同的部分,一個矩形和一個三角形,但這次以不同的方式組織。
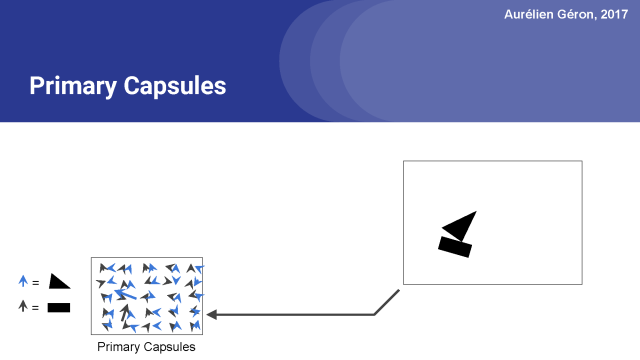
所以關鍵是要試著從這個包含一個矩形和一個三角形的圖像,找出這個位置和這個方向,并且說明它們是船的一部分,而不是房子。來讓我們弄清楚它將如何做到這一點。第一步(之前我們已經看到過):我們運行一對卷積層,我們將輸出重構以得到向量,然后將它們歸一化。這就得到了主膠囊的輸出。
我們已經有第一層了。下一步是則是展示膠囊網絡的魔力和復雜性的一步了。第一層中的每個膠囊試圖預測下一層中每個膠囊的輸出。你可能想停下來想一想這意味著什么。
第一層膠囊試圖預測第二層膠囊將輸出什么。
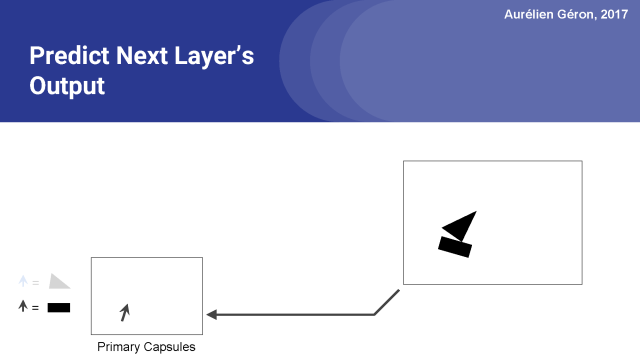
例如,讓我們考慮檢測矩形的膠囊。我會稱之為矩形膠囊。
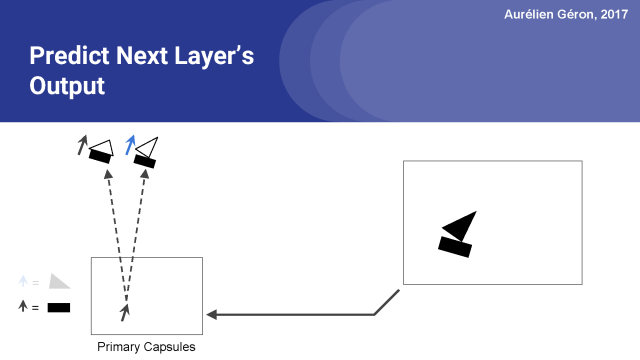
假設下一層只有兩個膠囊,房子膠囊和船膠囊。由于矩形膠囊檢測到一個旋轉了16°的矩形,所以房子膠囊將檢測到一個旋轉了16°的房子,這是有道理的,船膠囊也會檢測到旋轉了16°的船。 這與矩形的方向是一致的。
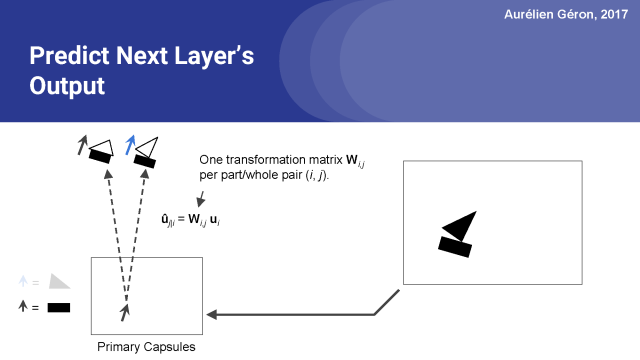
所以,為了做出這個預測,矩形膠囊所做的就是簡單地計算一個變換矩陣W_i,j與它自己的激活向量u_i的點積。在訓練期間,網絡將逐漸學習第一層和第二層中的每對膠囊的變換矩陣。 換句話說,它將學習所有的部分 - 整體關系,例如墻和屋頂之間的角度,等等。
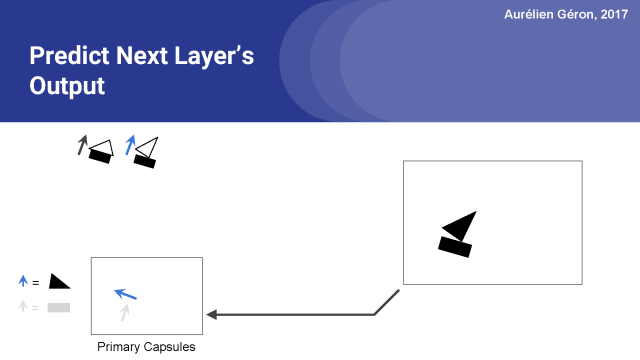
現在讓我們看看三角形的膠囊是什么。

這一次,它更有趣了:給定三角形的旋轉角度,它預測房子的膠囊會檢測到一個倒置的房子,并且船膠囊會探測到一艘船旋轉16°。這些位置與三角形的旋轉角度是一致的。
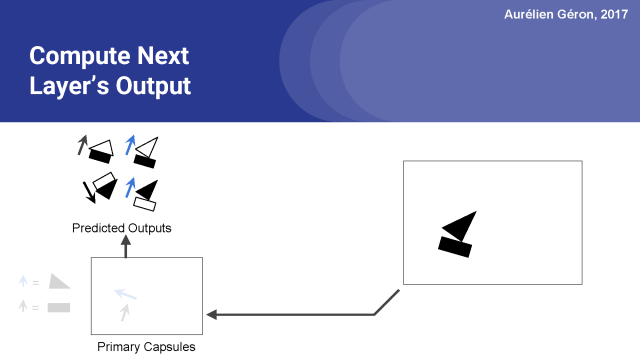
現在我們有一堆預測輸出,也就是圖上的四個,我們下一步用它們做什么呢?
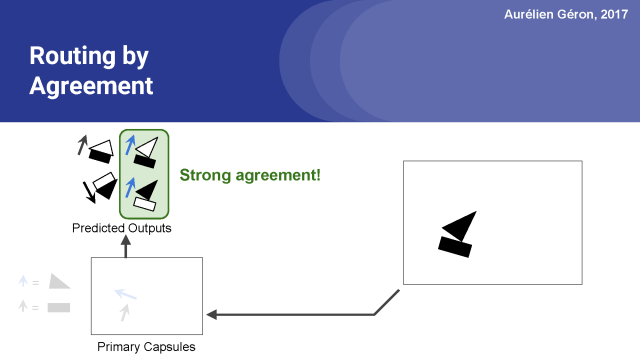
正如你所看到的,矩形膠囊和三角膠囊在船膠囊的輸出方面有著強烈的一致性。
換言之,矩形膠囊和三角膠囊都同意船會以什么樣的形式輸出來。
然而,矩形膠囊和三角膠囊他們倆完全不同意房子膠囊會產出什么,從圖中可以看出房子的輸出方向是一上一下的。。
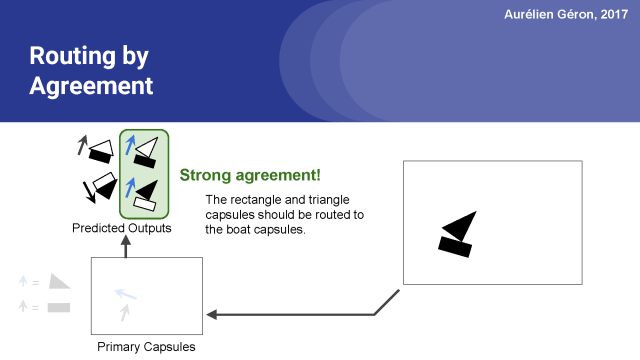
因此,可以很合理的假設矩形和三角形是船的一部分,而不是房子的一部分。
既然我們知道矩形和三角形是船的一部分,矩形膠囊和三角膠囊的輸出也就是真的只關注船膠囊,所以就沒有必要發送這些輸出到任何其他膠囊,這樣只會增加噪音。這叫做同意協議路由。它有幾個好處:
?
首先,由于一個膠囊的輸出僅路由到下一層的想對應的膠囊中,所以下一層的這些膠囊將得到更清晰的輸入信號,同時也更能準確地確定物體的姿態。
第二,通過查看激活的路徑,您可以輕松地查看部件的層次結構,并確切地知道哪個部分屬于哪個對象(如矩形屬于小船或者三角形屬于船等等)。
最后,按同意協議路由幫助解析那些有重疊對象的擁擠場景(我們將在幾個幻燈片中看到)。
?
但是首先,讓我們看看協議是如何在膠囊網絡中實現的。
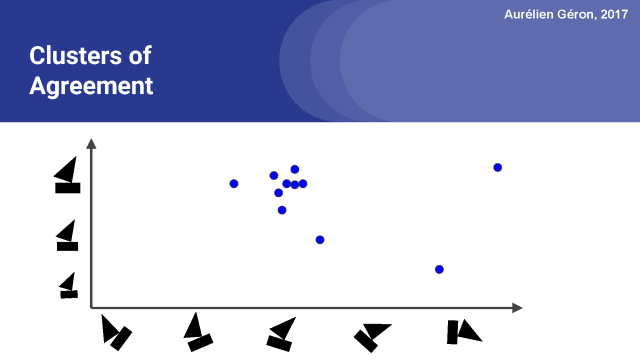
在這里,我把船的各種姿態都表示出來,正如低層次的膠囊可能會預測的那樣。
例如,這些圓圈中的一個可能代表矩形膠囊對船的最可能姿勢的看法,而另一個圓圈可能代表三角膠囊的想法,如果我們假設有許多其他低層的膠囊,然后我們可能就會有有大量用于船膠囊的預測向量。
在這個例子中,有兩個姿態參數:一個代表旋轉角度,另一個代表船的大小。正如我前面提到的,姿態參數可以捕獲許多不同類型的視覺特征,如傾斜、厚度或較精確定位。
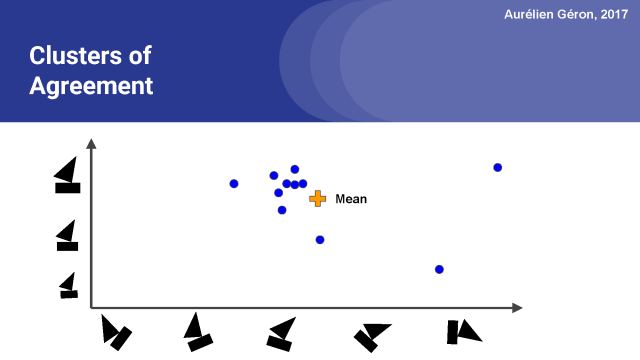
所以我們做的第一件事,就是計算所有這些預測的平均值。然后我們就得到了一個平均向量。下一步是度量每個預測向量與平均向量之間的距離。我在這里會用歐氏距離做演示,但膠囊網絡實際使用點積。
隨后我們要測量每個預測向量與平均預測向量的一致性程度。
利用這個計算出的一致性程度值,我們可以相應地更新每個預測向量的權重。
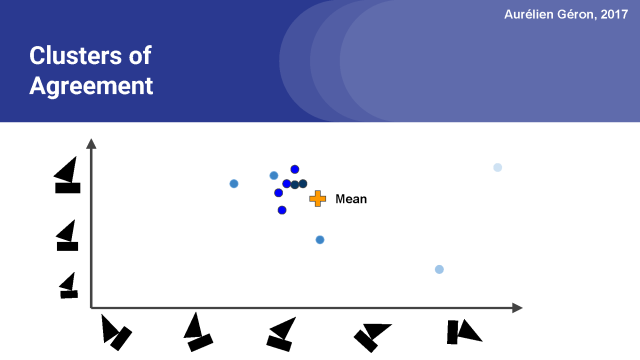
注意,遠離平均值的預測向量現在有一個非常小的重量,在圖中可以看到顏色比較淺。而最接近平均值的向量有更大的權重,我們用黑色來代表。
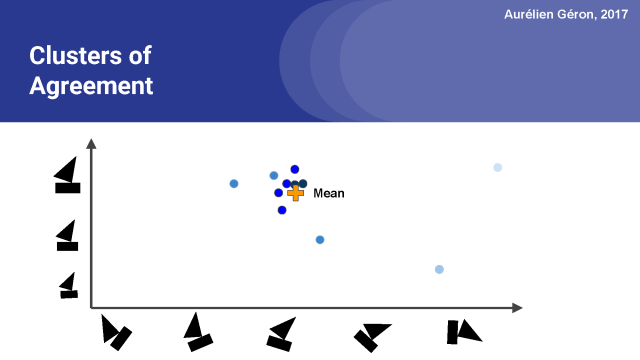
現在我們可以再一次計算均值(或者說,加權平均數),你會注意到跟上圖相比它稍微向聚類的中心移動。
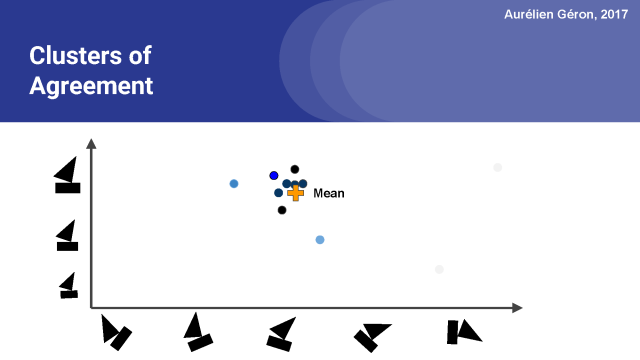
接下來,我們可以再次更新權重,現在聚類中的大部分向量變黑了,
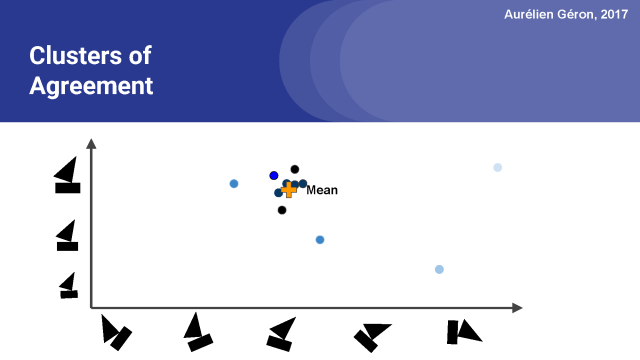
我們可以再次更新平均值。我們可以重復這個過程幾次,在實踐中,3到5次迭代通常是足夠的。我想這可能提醒你,如果你知道k-均值聚類算法的話,就很容易明白這是我們如何找到這個所有向量都任何的聚類的。現在讓我們看看整個算法在細節方面的工作原理。
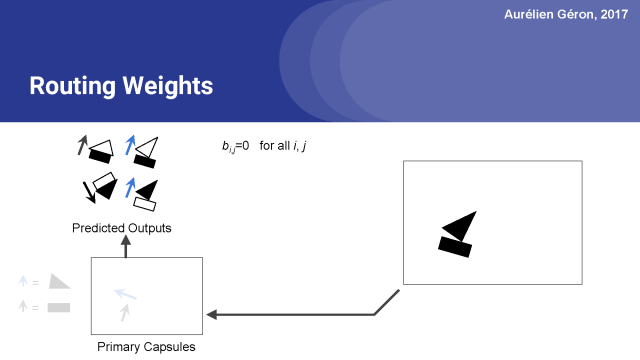
首先,對于每個預測的輸出,我們首先設置原始路由權重b_i,j等于0。
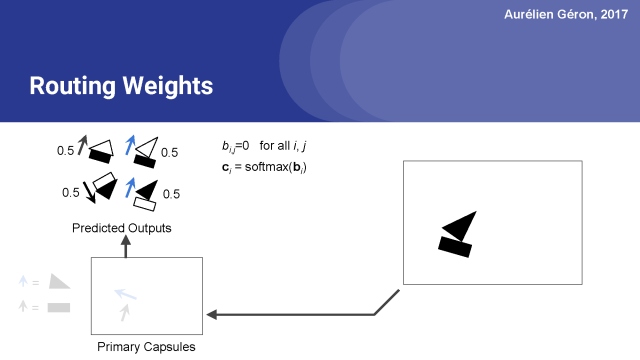
接下來對于每個基本的膠囊,我們將為應用softmax函數對他們的初始權重進行歸一化。這樣就得出了了每個預測輸出的實際路由權重,在本例中是0.5。
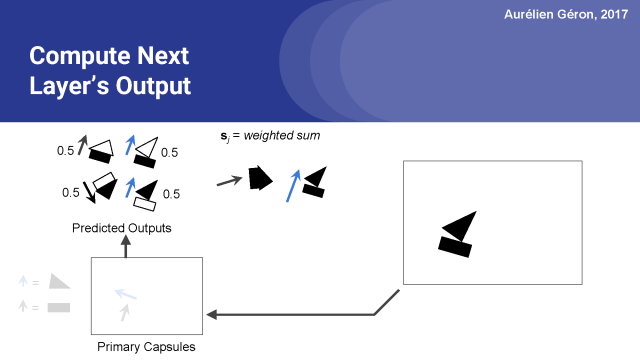
接下來,我們計算下一層的每個膠囊的預測的加權和。
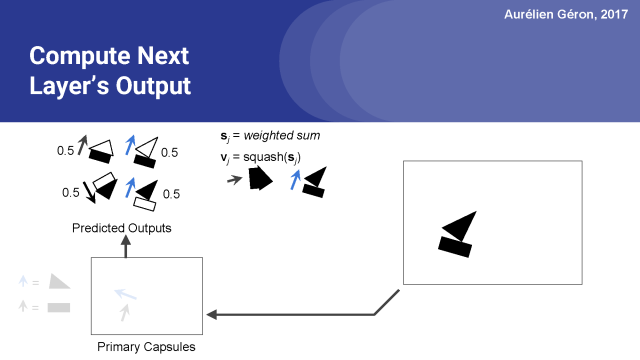
這可能會使向量長于1,所以通常會用到歸一化函數。
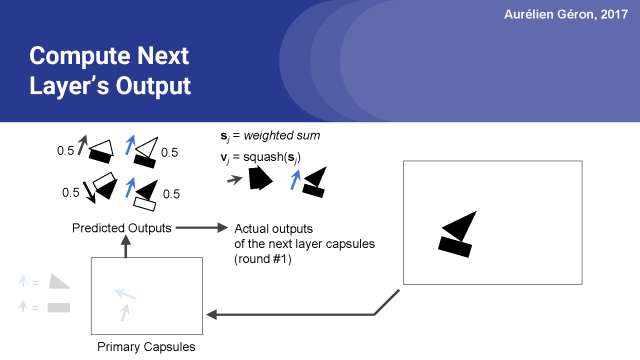
然后,我們現在有了房子膠囊和船艙的實際輸出。但這不是最終的輸出,這僅僅是第一輪的第一次迭代。
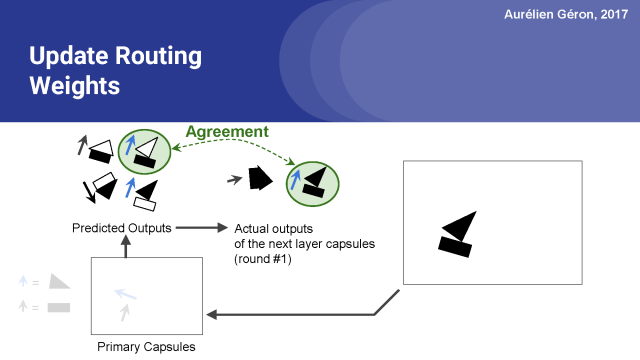
現在我們可以看到哪些預測是最準確的。例如,矩形膠囊對船艙的輸出做出了很好的預測。看上去它真的很接近。
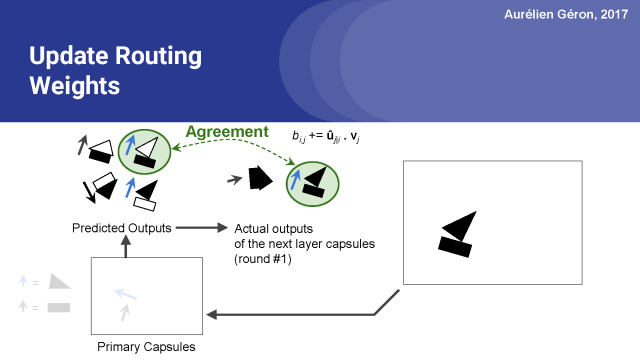
這是通過計算預測輸出向量?_j |i和實際乘積向量v_j的點積來估計的。這個點積操作被簡單地添加到預測輸出的原始路由權重b_i,j中。所以這個特定的預測輸出的權重增加了。
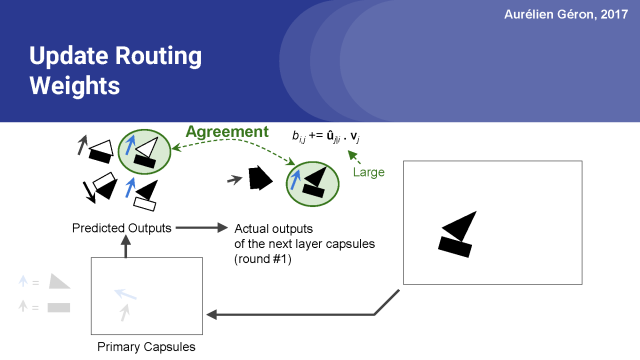
當預測的結果是一個強烈的同意時,這個點積也會很大,所以好的預測將有更高的權重。
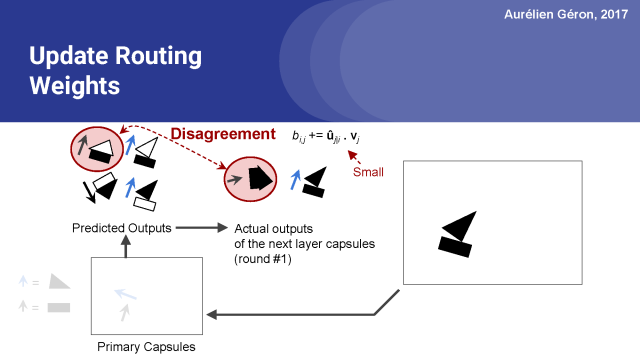
另一方面,長方形膠囊對房子膠囊的輸出作出了相當糟糕的預測,所以這種情況下的點積將相當小,這個預測向量的原始路由權重不會增長太多。
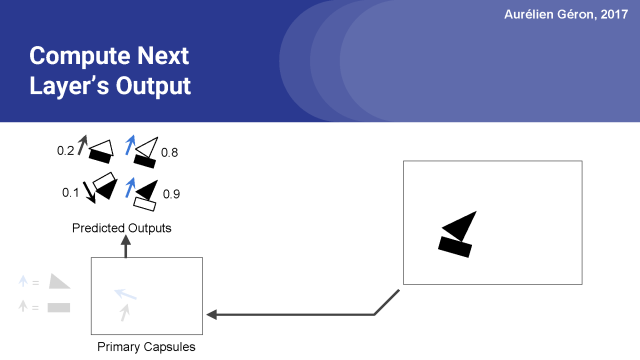
接下來,我們再次更新路由權值計算的原始權重的softmax函數。
正如你所看到的,矩形膠囊對船膠囊的預測矢量從初始的0.5更新到現在的0.8,而對房子膠囊的預測矢量下降到0.2。所以它的大部分輸出現在去了船膠囊,而不是房子膠囊。
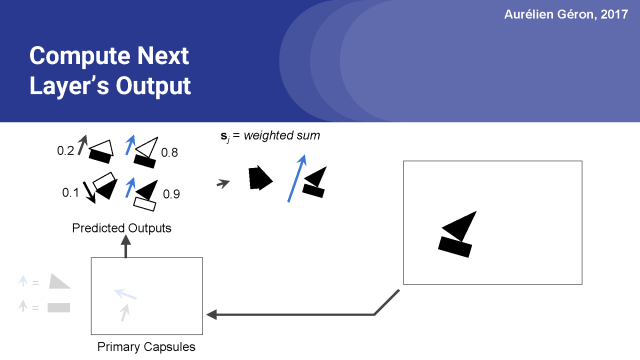
我們重復以上的操作再次計算下一層膠囊預測的輸出向量的加權和,也就是對下一層是房子膠囊和船膠囊的預測。此時,房子膠囊得到很少的輸入,它的輸出是一個很小的向量。?
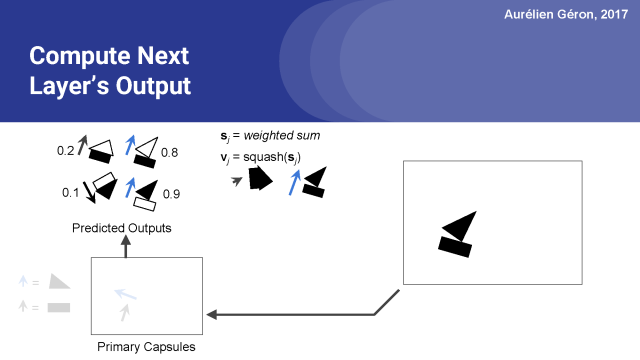
另一方面船膠囊得到很多輸入,它的輸出向量遠遠長于1,所以我們又把它壓扁(歸一化)了。
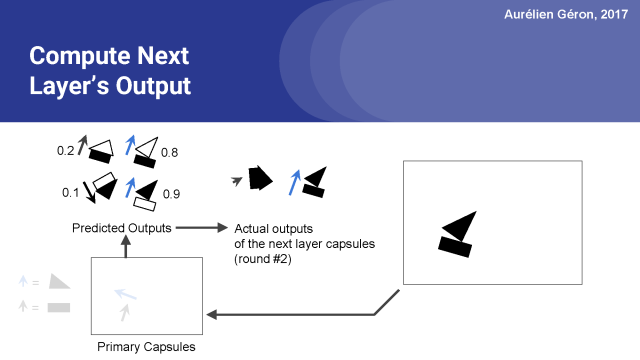
至此第二輪就結束了,正如你所看到的,在幾次迭代中,我們已經可以排除房屋并且清楚地挑選出船。也許一兩個回合之后,我們可以停下來,繼續以同樣的方式進入下一個膠囊層。
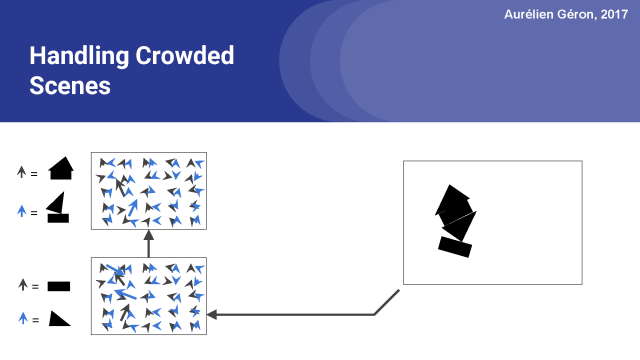
正如我前面提到的,通過協議來處理擁擠重疊的場景是非常有用的,如圖中所示的場景。

該圖像的一種解釋是(可以看到圖像中有一點模糊),你可以在中間看到一個倒掛的房子 。
在這種情況下,就沒法解釋底部矩形或頂部三角形,也沒有辦法解釋它們到底屬于哪個位置。
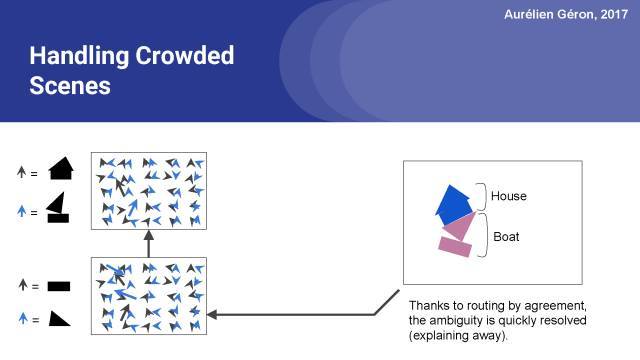
解釋圖像的較好方法是,在頂部有一個房子,底部有一艘船。并通過協議的路由傾向于選擇這個解決方案,因為它使所有的膠囊都狀態較佳,每一個都對下一層的膠囊進行完美的預測。這樣就可以消除歧義了。
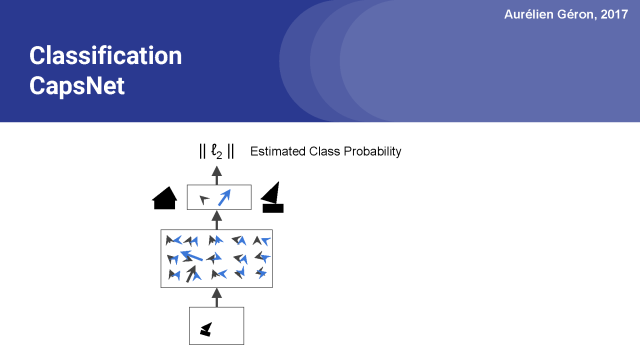
Okay,既然你知道膠囊網絡是如何工作的,那么你可以用一個膠囊網絡做什么?
首先,你可以創建一個好的圖像分類器。只需要在最頂層為每一個類分配一個膠囊,這幾乎就是這個網絡的全部內容了。
你只需要再添加一個用來計算頂層激活向量長度的層,這一層灰給出了每一類的估計概率。然后和常規的分類神經網絡一樣,你可以通過最小化交叉熵損失來訓練網絡,這樣你就可以完成了一個圖像分類器。
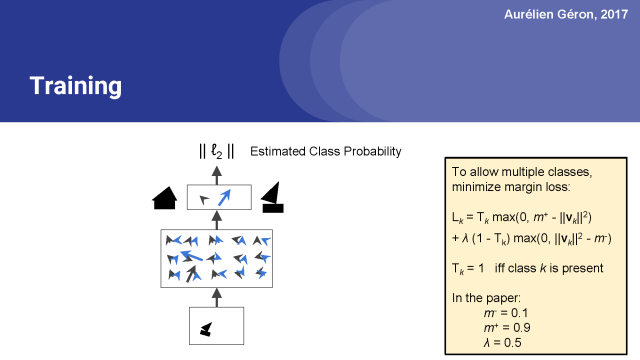
然而,在論文中,他們使用了一個邊緣(margin)損失,使得對圖像進行多分類成為可能。?
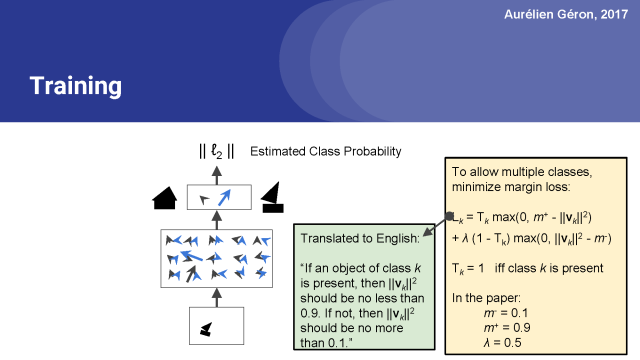
因此,簡單來說,這個邊緣損失就是下面這樣的:如果圖像中存在出現了第k類的對象,那么相應這個類的頂層膠囊應該輸出一個長度至少為0.9的向量。這樣才足夠長到確信是這一類。
?
相反,如果圖像中沒有第k類的對象,則該膠囊將輸出一個短向量,該向量的平方長度小于0.1。因此,總損失是所有類損失的總和。
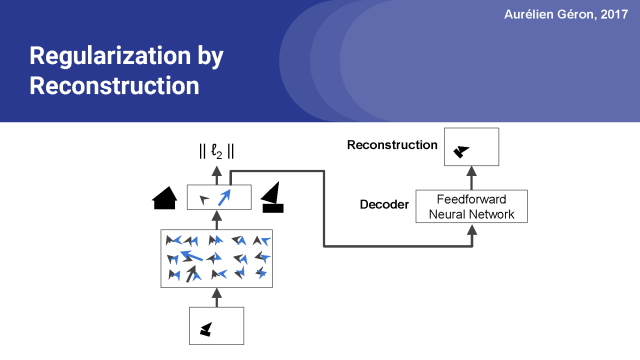
在論文中,他們還在膠囊網絡頂端添加了一個解碼器網絡。它只有3個全連接層,并且在輸出層中有一個sigmoid激活函數。它通過最小化重建圖像和輸入圖像之間的平方差,來重構輸入圖像。
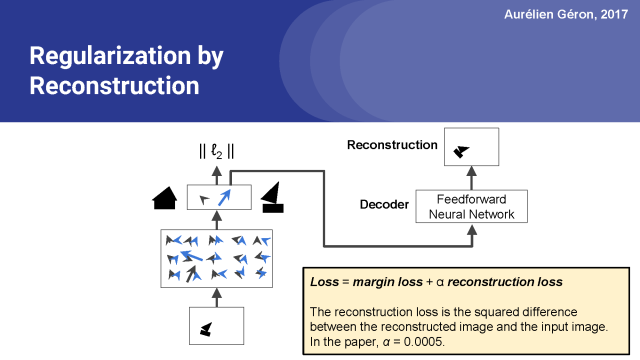
全部損失是我們先前討論的邊緣損失,加上重建損失(為確保邊緣損失占主導地位,應大幅度減少重建損失)。應用這種重建損失的好處是,它迫使網絡保存重建圖像所需的所有信息,直至膠囊網絡的頂層及其輸出層。這種約束的行為有點像正則化:它減少了過度擬合的風險,有助于模型泛化到新的實例。
就這樣,你知道一個膠囊網絡是如何工作的,以及如何去訓練它。接下來,讓我們看看論文中展示的一些有趣的結果。
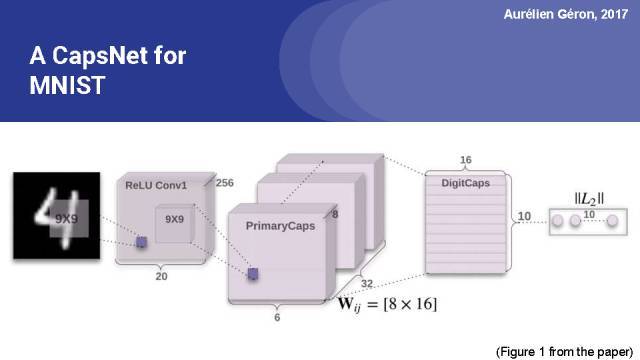
這是文中的圖1,展示了對于MNIST數據集的完全膠囊網絡。你可以看到前兩個正則卷積層,其輸出被重新構建和壓縮,以獲得主膠囊的激活向量。這些初級膠囊按照6 6的網格進行組織,在這個網格中每一個cell有32個初級膠囊,每個膠囊的主要輸出8維向量。
因此,第一層膠囊全連接成10個輸出膠囊,輸出16維向量。這些向量的長度用來計算邊緣損失。
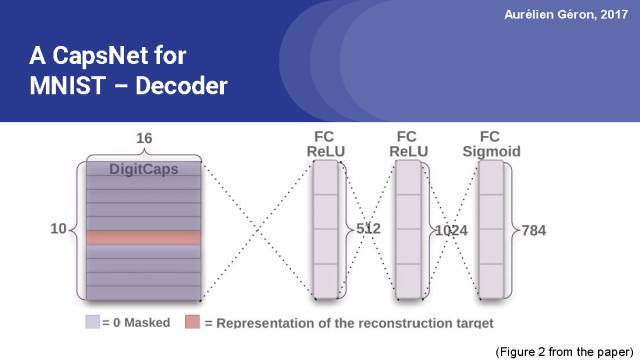
這是論文中的圖2,展示了膠囊網絡頂層的解碼器。它是由兩個全連接的ReLU層加上一個全連接的sigmoid層組成,該解碼器輸出784個數字,對應重構圖像的像素個數(圖像是28x28=784像素)。
重建圖像與輸入圖像的平方差是重建損失。

這是論文中的圖4。膠囊網絡的一個優點是激活向量通常是可解釋的。例如,該圖展示了當逐漸修改頂層膠囊輸出的16個維度中的一個時,所得到的重建圖像。你可以看到第一個維度似乎代表尺度和厚度,第四個維度表示局部傾斜,第五個維度表示數字的寬度加上輕微的平移得到確切的位置。
因此,可以很清楚大部分參數分別是表示什么的。

最后,讓我們總結一下膠囊網絡的利弊。膠囊網絡已經達到對MNIST數據集的較佳精度。在CIFAR10數據集上的表現還可以繼續提升,也是很值得期待的。膠囊網絡需要較少的訓練數據。它提供等變映射,這意味著位置和姿態信息得以保存。這在圖像分割和目標檢測領域是非常有前景的。
路由協議算法對于處理擁擠的場景具有很好的效果。路由樹還映射目標的部分的層次結構,因此每個部分都分配給一個整體。它對旋轉、平移和其他仿射變換有很強的健壯性。激活向可解釋性也比較好。最后,這是Hinton大神的idea,前瞻性是毋庸置疑的。

然而,該網絡有一些缺點:首先,如前面所提到在CIFAR10數據集上的準確性還不高。另外,現在還不清楚膠囊網絡是否可以建模規模較大的圖像,如ImageNet數據集,準確度是多少?膠囊網絡也很慢,在很大程度上是因為具有內部循環的路由協議算法。
最后,在給定的位置上只有一個給定類型的膠囊,因此如果一個膠囊網絡彼此之間太接近,就不可能檢測到同一類型的兩個對象。這被稱為膠囊擁擠,而且在人類的視覺中也能觀察到。

我強烈建議你看一看膠囊網絡實現代碼,如這里列出的(鏈接將在下面的視頻中描述)。花點時間,你應該可以理解代碼的所有內容。
?
實施膠囊網絡的主要困難是,它包含了路由協議算法形成的內回路。在Keras的代碼實現和tensorflow實現可以比PyTorch麻煩一點,不過也是可以做到的。如果你沒有特別的語言偏好,那么pytorch代碼是最容易理解的。
NIPS 2017 Paper:
* Dynamic Routing Between Capsules,
* by Sara Sabour, Nicholas Frosst, Geoffrey E. Hinton
* https://arxiv.org/abs/1710.09829
?
The 2011 paper: * Transforming Autoencoders
* by Geoffrey E. Hinton, Alex Krizhevsky and Sida D.Wang
* https://goo.gl/ARSWM6
CapsNet implementations:
* Keras w/ TensorFlow backend: https://github.com/XifengGuo/CapsNet-keras.
* TensorFlow: https://github.com/naturomics/CapsNet-Tensorflow
* PyTorch: https://github.com/gram-ai/capsule-networks

這就是我本節課講的所有內容,希望你喜歡這個視頻。如果你喜歡,請關注、分享、評論、訂閱、blablabla。這是我的第一個真正的YouTube視頻,如果你發現它有用,我可能會做更多。
如果你想了解更多關于機器學習、深度學習和深入的學習,你可能想讀機器學習與我自己實現的scikit學習TensorFlow O"Reilly的書。它涵蓋了非常多的話題,有很多的實例代碼,你可以在我的GitHub賬戶中找到,在這里留下視頻鏈接。今天就到這里,下次再見!
論文信息:Dynamic Routing Between Capsules

?
論文地址:https://arxiv.org/pdf/1710.09829.pdf
摘要:Capsule 是一組神經元,其活動向量(activity vector)表示特定實體類型的實例化參數,如對象或對象部分。我們使用活動向量的長度表征實體存在的概率,向量方向表示實例化參數。同一水平的活躍 capsule 通過變換矩陣對更高級別的 capsule 的實例化參數進行預測。當多個預測相同時,更高級別的 capsule 變得活躍。我們展示了判別式訓練的多層 capsule 系統在 MNIST 數據集上達到了較好的性能效果,比識別高度重疊數字的卷積網絡的性能優越很多。為了達到這些結果,我們使用迭代的路由協議機制:較低級別的 capsule 偏向于將輸出發送至高級別的 capsule,有了來自低級別 capsule 的預測,高級別 capsule 的活動向量具備較大的標量積。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4693.html
摘要:而加快推動這一趨勢的,正是卷積神經網絡得以雄起的大功臣。卷積神經網絡面臨的挑戰對的深深的質疑是有原因的。據此,也斷言卷積神經網絡注定是沒有前途的神經膠囊的提出在批判不足的同時,已然備好了解決方案,這就是我們即將討論的膠囊神經網絡,簡稱。 本文作者 張玉宏2012年于電子科技大學獲計算機專業博士學位,2009~2011年美國西北大學聯合培養博士,現執教于河南工業大學,電子科技大學博士后。中國計...
摘要:而這種舉一反三的能力在機器學習領域同樣適用,科學家將其稱之為遷移學習。與深度學習相比,我們技術較大優點是具有可證明的性能保證。近幾年的人工智能熱潮中,深度學習是最主流的技術,以及之后的成功,更是使其幾乎成為的代名詞。 如今,人類將自己的未來放到了技術手里,無論是讓人工智能更像人類思考的算法,還是讓機器人大腦運轉更快的芯片,都在向奇點靠近。谷歌工程總監、《奇點臨近》的作者庫茲韋爾認為,一旦智能...
摘要:本文從可視化的角度出發詳解釋了的原理的計算過程,非常有利于直觀理解它的結構。具體來說,是那些水平方向的邊緣。訓練過程可以自動完成這一工作。更進一步地說,這意味著每個膠囊含有一個擁有個值的數組,而一般我們稱之為向量。 CapsNet 將神經元的標量輸出轉換為向量輸出提高了表征能力,我們不僅能用它表示圖像是否有某個特征,同時還能表示這個特征的旋轉和位置等物理特征。本文從可視化的角度出發詳解釋了 ...
斯蒂文認為機器學習有時候像嬰兒學習,特別是在物體識別上。比如嬰兒首先學會識別邊界和顏色,然后將這些信息用于識別形狀和圖形等更復雜的實體。比如在人臉識別上,他們學會從眼睛和嘴巴開始識別最終到整個面孔。當他們看一個人的形象時,他們大腦認出了兩只眼睛,一只鼻子和一只嘴巴,當認出所有這些存在于臉上的實體,并且覺得這看起來像一個人。斯蒂文首先給他的女兒悠悠看了以下圖片,看她是否能自己學會認識圖中的人(金·卡...
摘要:本文試圖揭開讓人迷惘的云霧,領悟背后的原理和魅力,品嘗這一頓盛宴。當然,激活函數本身很簡單,比如一個激活的全連接層,用寫起來就是可是,如果我想用的反函數來激活呢也就是說,你得給我解出,然后再用它來做激活函數。 由深度學習先驅 Hinton 開源的 Capsule 論文 Dynamic Routing Between Capsules,無疑是去年深度學習界最熱點的消息之一。得益于各種媒體的各種...

閱讀 2020·2023-04-25 22:50
閱讀 2833·2021-09-29 09:35
閱讀 3390·2021-07-29 10:20
閱讀 3153·2019-08-29 13:57
閱讀 3355·2019-08-29 13:50
閱讀 3032·2019-08-26 12:10
閱讀 3529·2019-08-23 18:41
閱讀 2634·2019-08-23 18:01






