資訊專欄INFORMATION COLUMN

摘要:研究證明,用于加工聽覺信號的腦區(qū)可用于視覺任務(wù)。我們已經(jīng)發(fā)現(xiàn)為計(jì)算機(jī)圖像視覺通道開發(fā)出來的圖形處理單元,也可以用于加快語音和語言的機(jī)器學(xué)習(xí)任務(wù)。
最初針對視覺信號設(shè)計(jì)出來的 CNN 也能處理聽覺信號,最終幫助機(jī)器傾聽和更好地理解我們。 CNN 在某些程度上能遷移學(xué)習(xí),掌握多種模式的共同特征。
有一系列神經(jīng)網(wǎng)絡(luò)機(jī)器學(xué)習(xí)方法不只是「有深度的」。在這段時(shí)間,針對先進(jìn)的語音技術(shù)和人工智能的神經(jīng)網(wǎng)絡(luò)變得日益流行,有趣的是當(dāng)前的許多技術(shù)最初是針對圖像或視頻處理開發(fā)出來的。
卷積神經(jīng)網(wǎng)絡(luò) ( CNN )是這些方法中的一種,使得我們很容易理解為什么神經(jīng)網(wǎng)絡(luò)處理圖像的方式極其類似于人腦加工聲音刺激的方式。因此 CNN 很好地闡釋了人腦加工聽覺和視覺信息的過程以多種(而不是一種)方式彼此聯(lián)系。
關(guān)于 CNN ,你需要了解哪些?
作為人類,我們能識別面孔或物體,不管它們出現(xiàn)在我們的視野(或圖片)中的哪個(gè)位置。當(dāng)你試圖通過教機(jī)器如何搜索視覺特征(以面孔識別為例,這些視覺特征是在神經(jīng)網(wǎng)絡(luò)較低層次上的邊或線,或者較高層次上的眼睛和耳朵)來培養(yǎng)它的這種能力,你往往針對局部區(qū)域來做這件事,因?yàn)樗邢嚓P(guān)的像素彼此非常靠近。與此對應(yīng)的人類視覺是這樣工作的,一簇神經(jīng)元專注于一小部分感受野 (receptive field ),這是更大的整個(gè)視野的一部分。
因?yàn)槟悴恢老嚓P(guān)特征將出現(xiàn)在哪里,你必須掃描整個(gè)視野,要么按順序滑動你的一小部分感受野,就像(從上到下且從左到右)掃描一個(gè)窗口一樣;要么使用許多更小的感受野(神經(jīng)元簇),每一個(gè)都專注于(可能重疊)一小部分視覺輸入。
CNN 是按后一種方式來做的。這些感受野合在一起,覆蓋了整個(gè)輸入,這被叫做「卷積( convolutions )」。然后較高層次的 CNN 壓縮來自較低層次的卷積的信息,并從特定位置提取出信息,就像下圖展示的一樣。
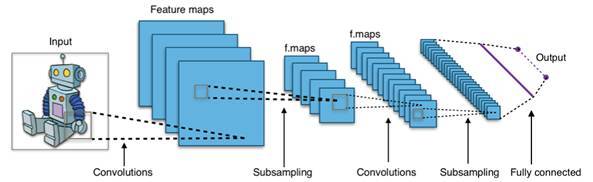
圖源:Wikipedia
所以,如果你在手機(jī)上用谷歌相冊搜索面孔或物品,或者在蘋果 iOS 10 系統(tǒng)中完成相同的新功能,你可以假設(shè) CNNs 用于識別圖片中有關(guān)的候選區(qū)域,在這些區(qū)域中可能出現(xiàn)你想要的面孔或物品。
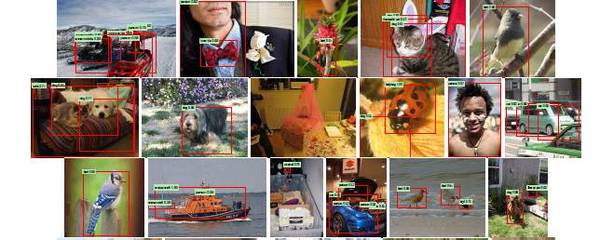
圖源:Ross Girshick, Jeff Donahue, Trevor Darrell and Jitendra Malik
但是我們發(fā)現(xiàn) CNN 在語音和語言方面也有一些作為。
CNN 可以用于以一種端對端的方式處理原始語音信號(不需要人們定義語音特征)。 CNN 通過展開一個(gè)輸入欄( input field )來查看語音信號,其中時(shí)間是一個(gè)維度,語音信號在不同頻率上的能量分布( energy distribution )是第二個(gè)維度,進(jìn)而自動化學(xué)習(xí)哪個(gè)頻率段是與語音最相關(guān)的。然后網(wǎng)絡(luò)中較高的層被用于語音識別的核心任務(wù):找出語音信號中的音素和詞匯。
研究證明,用于加工聽覺信號的腦區(qū)可用于視覺任務(wù)。
一旦你掌握了詞匯,接下來要做的是自然語言理解 ( NLU )中的「意圖分類」,或者從用戶的語音要求中理解用戶想達(dá)到什么目的(在最近的一篇博客中,我講解了 NLU 的其它方面,即實(shí)體識別等)。例如,用戶的語音指令是「從我的存款賬戶中轉(zhuǎn)一筆錢給 John Smith 」,其意圖就是「轉(zhuǎn)錢」。意圖往往是由一個(gè)詞或一組詞(通常是雙方熟悉的)表達(dá)出來的,在查詢系統(tǒng)中這些詞無處不在。
所以,類似于圖像識別,我們需要通過隨時(shí)空變化(發(fā)音;同時(shí)看一個(gè)詞及其上下文)而不是空間域的變化而滑動窗口來搜索局部特征。而且這表現(xiàn)得很好:當(dāng)我們?yōu)檫@個(gè)任務(wù)介紹 CNN 時(shí),它們表現(xiàn)出的準(zhǔn)確率比先前的技術(shù)多了 10% 以上。
視覺和聽覺是大腦內(nèi)部的鄰居
為什么 CNN 在這些任務(wù)上取得了成功?一個(gè)相當(dāng)直接的解釋是它們只是與圖像處理享有相同的特征;兩者都屬于「在更大的信號中找到更小的信號,而且我們不知道所需的更小的信號可能在哪里」類型。但是可能有其它稍微更有趣的解釋,即 CNN 是為視覺任務(wù)而設(shè)計(jì)出來的,也在語音相關(guān)任務(wù)上發(fā)揮作用,這反映了這樣一個(gè)事實(shí),大腦用非常相似的方法加工視覺和聽覺/語音刺激。
考慮一下聯(lián)覺現(xiàn)象,或者「對一種感覺或認(rèn)知通路的刺激在另一種感覺或認(rèn)知通路上引起了自動化的、無意識的體驗(yàn)」。例如,聲音或語音刺激可以導(dǎo)致視覺反應(yīng)。(我使用一個(gè)口味溫和的版本;對我而言,每周的每一天都有獨(dú)特的顏色。周一是暗紅色,周二是灰色,周三是暗灰色,周四是淺紅色,諸如此類。)可以這樣解釋,聲音和語音信號以及視覺加工的過程在大腦中以某種方式肯定是所謂的「鄰居」。
類似地,研究證明用于加工聲音信號和語音的腦區(qū)可以用于視覺任務(wù),比如天生具有聽覺障礙的人能重新部署自己大腦中的聲音/語音區(qū)域,使之加工手勢語。這可能意味著加工視覺或聽覺信號的大腦細(xì)胞(神經(jīng)元)的組織結(jié)構(gòu)一定非常相似。
所以,回到所有這些觀點(diǎn)的實(shí)際應(yīng)用上。不難想象幾年后你自己坐在自動駕駛汽車上與一個(gè)自動化助理聊天,命令它播放你最喜歡的音樂或預(yù)訂一家餐廳。「在這種場景的背后」,可能有一些 CNN 積極發(fā)揮作用:
LIDAR 系統(tǒng)(「光探測和測距」,一種基于激光的雷達(dá)系統(tǒng),被汽車用來創(chuàng)建周圍環(huán)境的模型,包括障礙物和其他車輛)將會使用一個(gè)或一些 CNN 。
汽車很可能也將使用攝像頭檢測和解讀交通信號; CNN 也將擁有被用于做這種事的好機(jī)會。
?在語音識別和自然語言理解組件上,自動化助理將使用 CNN ,從而讓兩種組件分別發(fā)現(xiàn)語音信號中的音素和詞匯以及發(fā)現(xiàn)詞匯流中的概念。
將來可能還有其他應(yīng)用。當(dāng)然,所有這些任務(wù)是由不同 CNN 實(shí)現(xiàn)的,甚至可能在不同的控制元件中。每一個(gè) CNN 只能在自己得到過訓(xùn)練的任務(wù)上表現(xiàn)得很準(zhǔn)確,而不能在其他任務(wù)上表現(xiàn)很好(除非它在其他任務(wù)上得到再次訓(xùn)練)。
你可能說計(jì)算機(jī)游戲中的進(jìn)展有助于切實(shí)可行地訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)。
然而——在此又變得令人著迷——研究表明,當(dāng) CNN 得到訓(xùn)練,它們(尤其是較低層)似乎獲得某種能實(shí)現(xiàn)其他任務(wù)的通用性能(或者觀念)。很容易理解這為什么能在相關(guān)領(lǐng)域中發(fā)揮作用;例如,在語音識別中,你可以用一種語言(比如英語)訓(xùn)練 CNN ,而且用另一種語言(比如德語)只重復(fù)訓(xùn)練較高層,然后 CNN 就能在新的語言上表現(xiàn)良好。顯然,較低層抓住了多種語言之間的共通性。
但是——我發(fā)現(xiàn)這更加令人吃驚——人們也嘗試過用多種模式(比如場景圖像和場景的文本表征)訓(xùn)練 CNN 。結(jié)果,網(wǎng)絡(luò)可以基于文本提取圖像,也能基于圖像提取文本。這些人總結(jié)道, CNN 在某些程度上掌握了這些模式的共同特征——在沒有被告知如何去做這件事的情況下。有趣的結(jié)果又一次證明了視覺和處理語言(文本)之間肯定有很多共同點(diǎn)。
關(guān)于視覺和聲音/語音以及語言處理的相似性,還有其他非常實(shí)際的復(fù)雜結(jié)果。我們已經(jīng)發(fā)現(xiàn)為計(jì)算機(jī)圖像(視覺通道)開發(fā)出來的圖形處理單元( GPU ),也可以用于加快語音和語言的機(jī)器學(xué)習(xí)任務(wù)。其原因是這些需要處理的任務(wù)在本質(zhì)上是相似的:將相對簡單的數(shù)學(xué)運(yùn)算應(yīng)用于許多平行的數(shù)據(jù)點(diǎn)上。所以,你可能說,計(jì)算機(jī)游戲的進(jìn)展有助于切實(shí)可行地訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)。
神經(jīng)網(wǎng)絡(luò)研究和創(chuàng)新產(chǎn)生了廣泛的影響,正如我們看見的,一個(gè)應(yīng)用領(lǐng)域(比如圖像識別)的進(jìn)步,也有益于其他領(lǐng)域(比如語音識別和自然語言理解)的發(fā)展。我們還看見,這可能是由人腦聽覺和視覺感受器的諸多相似之處或大腦常用的組織方式造成的。
結(jié)果,我們在許多領(lǐng)域持續(xù)看到機(jī)器學(xué)習(xí)和人工智能的快速前進(jìn),這些都得益于許多領(lǐng)域內(nèi)可以共享的研究成果。更確切地說,最初是針對視覺設(shè)計(jì)出來的 CNN 將最終幫助機(jī)器傾聽和更好地理解我們,這不再值得大驚小怪——至關(guān)重要的是,我們持續(xù)地推動社會走向人機(jī)交互新時(shí)代。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4386.html
摘要:未來向何處去做領(lǐng)袖不容易,要不斷地指明方向。又譬如想識別在這些黑白圖像中,是否包含從到的手寫體數(shù)字,那么深度學(xué)習(xí)的傳統(tǒng)做法是,輸出一個(gè)維向量,,其中每個(gè)元素的取值范圍是,表示出現(xiàn)相應(yīng)數(shù)字的概率。老爺子的論文中,輸出的是十個(gè)維向量,其中。 CNN 未來向何處去?做領(lǐng)袖不容易,要不斷地指明方向。所謂正確的方向,不僅前途要輝煌,而且道路要盡可能順暢。Geoffrey Hinton 是深度學(xué)習(xí)領(lǐng)域的...
摘要:在本次競賽中,南京信息工程大學(xué)和帝國理工學(xué)院的團(tuán)隊(duì)獲得了目標(biāo)檢測的最優(yōu)成績,最優(yōu)檢測目標(biāo)數(shù)量為平均較精確率為。最后在視頻目標(biāo)檢測任務(wù)中,帝國理工大學(xué)和悉尼大學(xué)所組成的團(tuán)隊(duì)取得了較佳表現(xiàn)。 在本次 ImageNet 競賽中,南京信息工程大學(xué)和帝國理工學(xué)院的團(tuán)隊(duì) BDAT 獲得了目標(biāo)檢測的最優(yōu)成績,最優(yōu)檢測目標(biāo)數(shù)量為 85、平均較精確率為 0.732227。而在目標(biāo)定位任務(wù)中Momenta和牛津...
摘要:深度學(xué)習(xí)推動領(lǐng)域發(fā)展的新引擎圖擁有記憶能力最早是提出用來解決圖像識別的問題的一種深度神經(jīng)網(wǎng)絡(luò)。深度學(xué)習(xí)推動領(lǐng)域發(fā)展的新引擎圖深度神經(jīng)網(wǎng)絡(luò)最近相關(guān)的改進(jìn)模型也被用于領(lǐng)域。 從2015年ACL會議的論文可以看出,目前NLP最流行的方法還是機(jī)器學(xué)習(xí)尤其是深度學(xué)習(xí),所以本文會從深度神經(jīng)網(wǎng)絡(luò)的角度分析目前NLP研究的熱點(diǎn)和未來的發(fā)展方向。我們主要關(guān)注Word Embedding、RNN/LSTM/CN...
摘要:潘新鋼等發(fā)現(xiàn),和的核心區(qū)別在于,學(xué)習(xí)到的是不隨著顏色風(fēng)格虛擬性現(xiàn)實(shí)性等外觀變化而改變的特征,而要保留與內(nèi)容相關(guān)的信息,就要用到。 大把時(shí)間、大把GPU喂進(jìn)去,訓(xùn)練好了神經(jīng)網(wǎng)絡(luò)。接下來,你可能會迎來傷心一刻:同學(xué),測試數(shù)據(jù)和訓(xùn)練數(shù)據(jù),色調(diào)、亮度不太一樣。同學(xué),你還要去搞定一個(gè)新的數(shù)據(jù)集。是重新搭一個(gè)模型呢,還是拿來新數(shù)據(jù)重新調(diào)參,在這個(gè)已經(jīng)訓(xùn)練好的模型上搞遷移學(xué)習(xí)呢?香港中文大學(xué)-商湯聯(lián)合實(shí)驗(yàn)...
摘要:一項(xiàng)由清華大學(xué)計(jì)算機(jī)系智能技術(shù)與系統(tǒng)國家重點(diǎn)實(shí)驗(yàn)室清華國家信息實(shí)驗(yàn)室清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系英特爾中國研究院清華大學(xué)電子工程系的研究人員共同參與的關(guān)于高效視覺目標(biāo)檢測的研究已經(jīng)被接收。 一項(xiàng)由清華大學(xué)計(jì)算機(jī)系智能技術(shù)與系統(tǒng)國家重點(diǎn)實(shí)驗(yàn)室、清華國家信息實(shí)驗(yàn)室、清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系、英特爾中國研究院、清華大學(xué)電子工程系的研究人員共同參與的關(guān)于高效視覺目標(biāo)檢測的研究已經(jīng)被 CVPR 201...

閱讀 1075·2021-10-14 09:42
閱讀 1368·2021-09-22 15:11
閱讀 3284·2019-08-30 15:56
閱讀 1242·2019-08-30 15:55
閱讀 3611·2019-08-30 15:55
閱讀 888·2019-08-30 15:44
閱讀 2027·2019-08-29 17:17
閱讀 2070·2019-08-29 15:37






