資訊專欄INFORMATION COLUMN

摘要:深度學(xué)習(xí)推動(dòng)領(lǐng)域發(fā)展的新引擎圖擁有記憶能力最早是提出用來解決圖像識(shí)別的問題的一種深度神經(jīng)網(wǎng)絡(luò)。深度學(xué)習(xí)推動(dòng)領(lǐng)域發(fā)展的新引擎圖深度神經(jīng)網(wǎng)絡(luò)最近相關(guān)的改進(jìn)模型也被用于領(lǐng)域。
從2015年ACL會(huì)議的論文可以看出,目前NLP最流行的方法還是機(jī)器學(xué)習(xí)尤其是深度學(xué)習(xí),所以本文會(huì)從深度神經(jīng)網(wǎng)絡(luò)的角度分析目前NLP研究的熱點(diǎn)和未來的發(fā)展方向。
我們主要關(guān)注Word Embedding、RNN/LSTM/CNN等主流的深度神經(jīng)網(wǎng)絡(luò)在NLP中的應(yīng)用,這已經(jīng)是目前主流的研究方向。此外,已經(jīng)在機(jī)器學(xué)習(xí)或其它領(lǐng)域比較熱門的方法,比如Multi-Model、Reasoning、Attention and Memory等,很有可能是未來NLP研究的熱點(diǎn),我們將著重關(guān)注。
Word Embedding
在Word2vec被Mikolov提出之后,由于它能把一個(gè)詞表示成一個(gè)向量(可以理解為類似隱語義的東西),這樣最小的語義單位就不是詞而是詞向量的每一維了。比如我們訓(xùn)練一個(gè)模型用來做文本分類,如果訓(xùn)練數(shù)據(jù)里都是用“計(jì)算機(jī)”,但測試數(shù)據(jù)里可能用的是“電腦”,用詞作為最基本單位(比如Bag of Words),我們學(xué)出來的模型會(huì)做出錯(cuò)誤的判斷。但是如果我們用一個(gè)很大的未標(biāo)注的語料庫來訓(xùn)練一個(gè)Word2vec,我們就能知道“計(jì)算機(jī)”和“電腦”語義是相似的,因此它們的詞向量也會(huì)是類似的,比如100維的詞向量某一維和計(jì)算機(jī)相關(guān),那么“計(jì)算機(jī)”和“電腦”的詞向量在這一維度都會(huì)比較大,用它作為基本單位訓(xùn)練模型后,我們的模型就能利用這一維特征正確地實(shí)現(xiàn)分類。當(dāng)然如果數(shù)據(jù)量足夠大,可以把模型的參數(shù)和詞向量一起訓(xùn)練,這樣得到的是更優(yōu)化的詞向量和模型。
但是Word2vec忽略了一些有用的信息,比如詞之間的關(guān)系(句法關(guān)系)、詞的順序、以及沒有利用已有的外部資源。針對(duì)這些問題,有很多改進(jìn)的工作。
引入詞的關(guān)系
最常見的思路就是用Dependency Parser,把抽取出來的Relation作為詞的Context。
改進(jìn)Bag of Words
有人認(rèn)為詞(Word)的粒度也太大,可以到Character級(jí)別的,或者M(jìn)orpheme級(jí)別的。
外部資源和知識(shí)庫
Word2vec只使用了詞的上下文的共現(xiàn),沒有使用外部的資源如詞典知識(shí)庫等,因此也有不少工作對(duì)此進(jìn)行改進(jìn)。
RNN/LSTM/CNN
RNN相關(guān)的模型如LSTM基本上算是解決結(jié)構(gòu)化問題的標(biāo)準(zhǔn)方法了,相比于普通的FeedForward Network,RNN是有“記憶”能力的。
普通的神經(jīng)網(wǎng)絡(luò)只會(huì)在學(xué)習(xí)的時(shí)候“記憶”,也就是通過反向傳播算法學(xué)習(xí)出參數(shù),然后就不會(huì)有新的“記憶”了。訓(xùn)練好了之后,不管什么時(shí)候來一個(gè)相同的輸入,都會(huì)給出一個(gè)相同的輸出。對(duì)于像Image Classification這樣的問題來說沒有什么問題,但是像Speech Recognition或者很多NLP的Task,數(shù)據(jù)都是有時(shí)序或結(jié)構(gòu)的。比如語音輸入是一個(gè)時(shí)序的信號(hào),前后幀的數(shù)據(jù)是相關(guān)的;而NLP的很多問題也都是序列或者層次的結(jié)構(gòu)。
RNN擁有“記憶”能力,如圖1所示,前一個(gè)輸出是會(huì)影響后面的判斷的。比如前一個(gè)詞是He,那么后面出現(xiàn)is的概率比出現(xiàn)“are”的概率高得多。最簡單的RNN直接把前一個(gè)時(shí)間點(diǎn)的輸出作為當(dāng)前輸入的一部分,但是會(huì)有Gradient Vanishing的問題,從而導(dǎo)致在實(shí)際的模型中不能處理Long Distance的Dependency。目前比較流行的改進(jìn)如LSTM和GRU等模型通過Gate的開關(guān),來判斷是否需要遺忘/記憶之前的狀態(tài),以及當(dāng)前狀態(tài)是否需要輸出到下個(gè)時(shí)間點(diǎn)。比如語言模型,如果看到句子“I was born in China, …. I can speak fluent Chinese. ”,如果有足夠的數(shù)據(jù),LSTM就能學(xué)到類似這樣?xùn)|西:看到“I was born in”,就記住后面的單詞“China”,當(dāng)遇到“speak”時(shí),就能知道后面很可能說“Chinese”。而遇到“Chinese”之后,其實(shí)就可以“忘掉”“China”了。
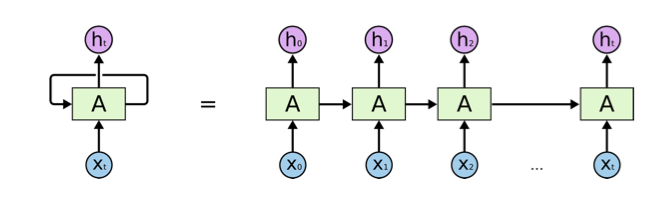
圖1 RNN擁有“記憶”能力
CNN(LeNet)最早是Yann Lecun提出用來解決圖像識(shí)別的問題的一種深度神經(jīng)網(wǎng)絡(luò)。通過卷積來發(fā)現(xiàn)位置無關(guān)(Translational Invariance)的Feature,而且這些Feature的參數(shù)是相同的,從而與全連接的神經(jīng)網(wǎng)絡(luò)相比大大減少了參數(shù)的數(shù)量,如圖2所示。
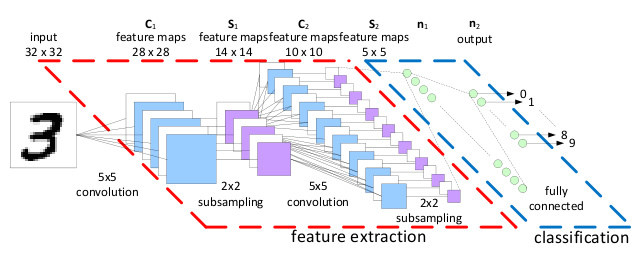
圖2 CNN深度神經(jīng)網(wǎng)絡(luò)
最近CNN相關(guān)的改進(jìn)模型也被用于NLP領(lǐng)域。今年的ACL上有很多RNN/LSTM/CNN用來做機(jī)器翻譯(Machine Translation)、語義角色標(biāo)注(Sematic Role Labeling)等。
Multi-model Deep Learning
這是當(dāng)下的一個(gè)熱門,不只考慮文本,同時(shí)也考慮圖像,比如給圖片生成標(biāo)題(Caption)。當(dāng)然這和傳統(tǒng)的NLP任務(wù)不太一樣,但這是一個(gè)非常有趣的方向,有點(diǎn)像小朋友學(xué)習(xí)看圖說話。
這樣的實(shí)際應(yīng)用非常多,比如像Facebook或者騰訊這樣的社交平臺(tái)每天都有大量的圖片上傳,如果我們能給圖片生成標(biāo)題或者摘要,就可以實(shí)現(xiàn)圖片的文本搜索以及語義分析。
圖3來自Google DeepMind的論文,根據(jù)圖片自動(dòng)生成Caption,很好地為圖片做了文本摘要。

圖3 根據(jù)圖片自動(dòng)生成Caption(圖片來自Google DeepMind的論文Show and Tell: A Neural Image Caption Generator)
Reasoning, Attention and Memory
前面說RNN/LSTM是試圖模擬人類大腦的記憶機(jī)制,但除了記憶之外,Attention也是非常有用的機(jī)制。
Attention
最早Attention是在《Recurrent Models of Visual Attention》這篇文章提出來的,它的主要思想是:人在看一個(gè)視覺場景時(shí)并不是一次看完,而是把注意力集中在某個(gè)區(qū)域,然后根據(jù)現(xiàn)有的數(shù)據(jù)決定下一次把注意力放到哪個(gè)地方(筆者的理解:比如我們看到的圖片是一條蛇,我們先看到蛇的頭部和它彎曲的角度,根據(jù)我們對(duì)于蛇的先驗(yàn)知識(shí),那么我們可能推斷它的身體在右下的某個(gè)地方,我們的注意力可能就會(huì)直接跳到那個(gè)部分)。
這篇文章提出的RAM(Recurrent Attention Model)模型:它把Attention當(dāng)成一個(gè)順序決策問題,決策Agent能夠與視覺環(huán)境交互,并且有一個(gè)目標(biāo)。
這個(gè)Agent有一個(gè)傳感器能探測視覺場景的一部分,它通過這些局部數(shù)據(jù)抽取一些信息,但是它可以自主控制傳感器的運(yùn)動(dòng),也能做出決策來影響環(huán)境的真實(shí)狀態(tài)。每次行動(dòng)都會(huì)有獎(jiǎng)勵(lì)/懲罰(可能是延遲的,就像下棋一樣,短時(shí)間看不出好壞,但多走兩步就能看出來了),而Agent的目標(biāo)就是較大化總的獎(jiǎng)勵(lì)。這個(gè)模型優(yōu)化的目標(biāo)函數(shù)是不可導(dǎo)的,但可以用強(qiáng)化學(xué)習(xí)來學(xué)出針對(duì)具體問題的策略(筆者的理解:比如識(shí)別一條蛇,我可能有一種探測路徑,但識(shí)別章魚,我可能有另一種路徑)。
另外,關(guān)于Attention,Google DeepMind的一篇論文《DRAW:A Recurrent Neural Network For Image》有一段非常好的解釋:
引用
當(dāng)一個(gè)人繪畫或者重建一個(gè)視覺場景時(shí),他能自然地用一種順序迭代的方式,每次修改后重新評(píng)估它。粗糙的輪廓逐漸被更較精確的形狀代替,線條被銳化,變暗或者擦除,形狀被修改,最終完成這幅圖畫。
從上面的分析可以看出,Attention除了模仿人類視覺系統(tǒng)的認(rèn)知過程,還可以減少計(jì)算量,因?yàn)樗懦瞬魂P(guān)心的內(nèi)容。而傳統(tǒng)的模型如CNN,其計(jì)算復(fù)雜度就非常高。另外除了計(jì)算減少的好處之外,有選擇地把計(jì)算資源(注意力)放在關(guān)鍵的地方而不是其它(可能干擾)的地方,還有可能提高識(shí)別準(zhǔn)確率。就像一個(gè)人注意力很分散,哪都想看,反而哪都看不清楚。
Attention最早是在視覺領(lǐng)域應(yīng)用,當(dāng)然很快就擴(kuò)展到NLP和Speech。
用來做機(jī)器翻譯:Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. 2015. In Proceedings of ICLR.
做Summary:Alexander M. Rush, Sumit Chopra, Jason Weston. A Neural Attention Model for Sentence Summarization. 2015. In Proceedings of EMNLP.
Word Embedding: Wang Ling, Lin Chu-Cheng, Yulia Tsvetkov, et al. Not All Contexts Are Created Equal: Better Word Representations with Variable Attention. 2015. In Proceedings of EMNLP.
Speech領(lǐng)域:Attention-Based Models for Speech Recognition. Jan Chorowski*, University of Wroclaw; Dzmitry Bahdanau, Jacobs University, Germany; Dmitriy Serdyuk, Université de Montréal; Kyunghyun Cho, NYU; Yoshua Bengio, U. Montreal. 2015. In Proceedings of NIPS.
其它的應(yīng)用,比如Multimodel,Image的Caption生成:Kelvin Xu, Jimmy Ba, Ryan Kiros, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. 2015. In Proceedings of ICML. Karl Moritz Hermann, Tomá? Ko?isky, Edward Grefenstette, et al. Teaching Machines to Read and Comprehend. 2015. In Proceedings of NIPS.
前面最早的Attention Model是不可導(dǎo)的,只能用強(qiáng)化學(xué)習(xí)來優(yōu)化,也被叫做Hard Attention,也就是把注意力集中在離散的區(qū)域;后來也有Soft的Attention,也就是在所有的區(qū)域都有Attention,但是連續(xù)分布的。Soft的好處是可導(dǎo),因此可以用梯度下降這樣的方法來訓(xùn)練模型,和傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)更加接近。但壞處就是因?yàn)樗械膮^(qū)域都有值(非零),這就增加了計(jì)算量。用個(gè)不恰當(dāng)?shù)谋确剑粋€(gè)是稀疏矩陣,一個(gè)是稠密的矩陣,計(jì)算量當(dāng)然差別就很大。
也有一些工作嘗試融合Soft和Hard Attention的優(yōu)點(diǎn)。
Memory的擴(kuò)展
前面說到RNN,如LSTM,有Memory(記憶),很多模型對(duì)此也進(jìn)行了拓展。
比如Neural Turing Machine (Neural Turing Machines. Alex Graves, Greg Wayne, Ivo Danihelka. arXiv Pre-Print, 2014),NTM用一句話描述就是有外部存儲(chǔ)的神經(jīng)網(wǎng)絡(luò)。如圖4所示。
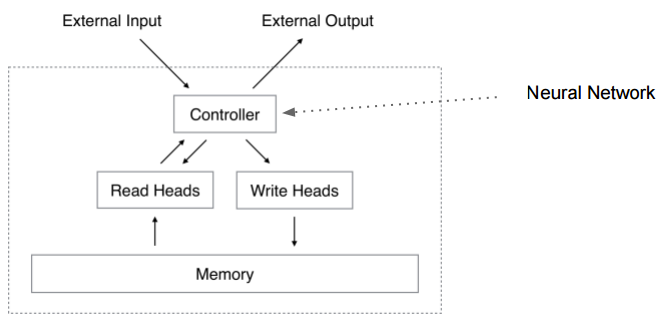
圖4 NTM
Turing Machine有一個(gè)Tape和一個(gè)讀寫頭,Tape可以視為Memory,數(shù)據(jù)都放在Tape上,TM的控制器是一個(gè)“程序”,它讀入Tape上的輸入,然后把處理結(jié)果也輸出到Tape上。此外Turing Machine還有個(gè)當(dāng)前的State。
而NTM的控制器是一個(gè)神經(jīng)網(wǎng)絡(luò)(Feedforward的或者Recurrent的如LSTM),其余的都類似,只是把古董的Tape換成了現(xiàn)代的尋址更方便的Memory,Input和Output也分離出去的(看起來更像是現(xiàn)代體系結(jié)構(gòu)下的計(jì)算機(jī))。
我們傳統(tǒng)的編程其實(shí)就是編寫一個(gè)Turing Machine,然后放到Universal Turing Machine上去運(yùn)行(UTM和TM是等價(jià)的,UTM是能運(yùn)行TM的TM)。傳統(tǒng)的編程比如寫一個(gè)“Copy”程序,我們知道輸入,也知道期望的輸出,那么我們?nèi)四X來實(shí)現(xiàn)一個(gè)程序,我們用程序這種“語言”來表達(dá)我們的想法(算法)。
而NTM呢?它希望給點(diǎn)足夠多的輸入/輸出對(duì)(訓(xùn)練數(shù)據(jù)),Controller(神經(jīng)網(wǎng)絡(luò))能學(xué)習(xí)出“程序”來。
程序真的可以“學(xué)習(xí)”出來嗎?程序員怎么“證明”它寫的算法的正確性呢?
關(guān)于人類學(xué)習(xí)的歸納和演繹的爭論。我覺得人類的學(xué)習(xí)都是歸納的,我們每天看到太陽從西邊出來,因此“歸納”出太陽從西邊出來這個(gè)結(jié)論,但是我們永遠(yuǎn)無法證明(演繹)出這個(gè)結(jié)論。演繹似乎只有“上帝”(或者數(shù)學(xué)家,哈哈,他們是上帝他們定義一些公理,然后不斷演繹出整個(gè)體系,比如歐氏幾何的五大公理演繹出那么多定理)才有的特權(quán),他定義了宇宙的運(yùn)轉(zhuǎn)規(guī)律,然后一切都在這個(gè)規(guī)律下運(yùn)作(演繹)。而人類似乎只能猜測上帝定義的規(guī)律,然后用這個(gè)猜測的規(guī)律進(jìn)行演繹。如果沒有發(fā)現(xiàn)破壞規(guī)律的現(xiàn)象,那么萬事大吉,否則只能拋棄之前的猜測,重新猜測上帝的想法。但是上帝創(chuàng)造的規(guī)律能被受這個(gè)規(guī)律約束的智慧生命發(fā)現(xiàn)嗎?也許得看上帝在創(chuàng)造這個(gè)規(guī)律時(shí)的心情?
普通的計(jì)算機(jī)程序讀取輸入,然后進(jìn)行一些計(jì)算,把臨時(shí)的一些結(jié)果放到Memory里,也從Memory里讀取數(shù)據(jù),最終把結(jié)果輸出。只不過需要我們用計(jì)算機(jī)程序語言來指定其中的每一個(gè)操作步驟。而NTM也是一樣。它對(duì)于每一個(gè)輸入,都讀取一下現(xiàn)有的內(nèi)存,然后根據(jù)現(xiàn)有的內(nèi)存和輸入進(jìn)行計(jì)算,然后更新內(nèi)存。只不過這些操作是通過輸入和輸出“學(xué)習(xí)”出來的。
因?yàn)樯窠?jīng)網(wǎng)絡(luò)學(xué)習(xí)時(shí)需要連續(xù)可導(dǎo),所以NTM的內(nèi)存和我們現(xiàn)在用的計(jì)算機(jī)內(nèi)存不同,現(xiàn)在的計(jì)算機(jī)都是離散的01,而NTM的內(nèi)存是個(gè)連續(xù)的值。計(jì)算機(jī)的寫只能是離散的01值,而NTM的寫入是連續(xù)的實(shí)數(shù)(當(dāng)然受限于硬件肯定是有限的浮點(diǎn)數(shù))。而且和前面的Attention相聯(lián)系,我們會(huì)發(fā)現(xiàn)它也是一種Soft Attention——對(duì)于某個(gè)程序,比如Copy,它的Attention是連續(xù)的變化規(guī)律(假設(shè)我們是用一個(gè)for循環(huán)來復(fù)制輸入到連續(xù)的內(nèi)存)。文章的作者嘗試了一些簡單程序,比如Copy、Associative等,NTM(LSTM作為controller)都比LSTM要好不少。不過Binary Heap Sort這種復(fù)雜一點(diǎn)的程序,NTM就沒有學(xué)習(xí)出來,它學(xué)出來一個(gè)HashTable(這是讓我等碼農(nóng)失業(yè)的節(jié)奏嗎?)。
你也許會(huì)問NTM似乎對(duì)應(yīng)的是TM,那和NLP有什么關(guān)系呢?
NLP是人類的語言,比機(jī)器的語言復(fù)雜。我們可以首先研究一下簡單的機(jī)器語言,或許會(huì)有所啟發(fā)。
但事實(shí)上NTM也可以用來做QA(問答)。
IBM做了著名的Watson,讓人覺得似乎機(jī)器能真正的理解語言了。不過很多業(yè)內(nèi)人士覺得離我們期望的機(jī)器理解語言還差得遠(yuǎn),當(dāng)然他們做了很多很有用的工作。
《Empirical Study on Deep Learning Models for QA》就是IBM Watson團(tuán)隊(duì)的嘗試。在Facebook的人工構(gòu)造QA數(shù)據(jù)集上融合并對(duì)比了當(dāng)下熱門三種DL方法:Neural Machine Translation、Neural Turing Machine及Memory Networks。得出的結(jié)論是:融合Memory組件和Attention機(jī)制在解決QA問題上具有巨大潛力。
我們可以看到在今年NIPS的RAM Workshop上很多用類似NTM這樣的模型來做QA或者相關(guān)任務(wù)的文章。Facebook人工智能研究院(FAIR)在NLP的主要工作都是在RAM上。
Language的復(fù)雜性
相對(duì)于Image和Speech,Language似乎更加復(fù)雜一些。
視覺和聽覺作為人類與外界溝通最主要的兩種感覺,經(jīng)歷了長期的進(jìn)化。大部分動(dòng)物都有發(fā)達(dá)的視覺與聽覺系統(tǒng),很多都比人類更加發(fā)達(dá)。拿視覺來說,老鷹的視力就比人類發(fā)達(dá)的多,而且很多動(dòng)物夜間也有很強(qiáng)的視力,這是人類無法比擬的。但是人類的視覺應(yīng)該有更多高層概念上的東西,因?yàn)槿祟惔竽X的概念很多,因此視覺系統(tǒng)也能處理更多概念。比如人類能利用鋼鐵,對(duì)汽車有細(xì)微的視覺感受,但是對(duì)于一條狗來說可能這些東西都是Other類別,它們可能只關(guān)注食物、異性、天敵等。
聽覺系統(tǒng)也是如此,很多動(dòng)物的聽覺范圍和精度都比人類高得多。但它們關(guān)注的內(nèi)容也很少,大部分是獵物或者天敵的聲音。
我覺得人類與大部分動(dòng)物較大的區(qū)別就是社會(huì)性,社會(huì)性需要溝通,因此語言就非常重要。一些動(dòng)物群落比如狼群或者猴群也有一定的社會(huì)性,像狼群狩獵是也有配合,猴群有嚴(yán)格的等級(jí)制度,但是相對(duì)于人類社會(huì)來說就簡單得多。一個(gè)人能力相當(dāng)有限,但是一個(gè)人類社會(huì)就非常強(qiáng)大,這其實(shí)就跟一個(gè)螞蟻非常簡單,但是整個(gè)蟻群非常智能類似。
作為溝通,人類至少有視覺和聽覺兩種主要的方式,但最終主要的溝通方式語言卻是構(gòu)建在聽覺的基礎(chǔ)上的。為什么進(jìn)化沒有選擇視覺呢?當(dāng)然也許有偶然的因素,但是我們可以分析(或者猜測)一下可能的原因。
你也許會(huì)說聲音可以通過不同的發(fā)音來表示更多的概念,而且聲音是時(shí)序信號(hào),可以用更長的聲音表示更復(fù)雜的概念。
但這是說不通的,人類能比動(dòng)物發(fā)出更多不同種類的聲音,這也是進(jìn)化的結(jié)果。用臉部或者四肢也能表達(dá)很多不同的概念,就像殘疾人的手語或者唇語,或者科幻小說《三體》里的面部表情交流。如果進(jìn)化,面部肌肉肯定會(huì)更加發(fā)達(dá)從而能夠表示更多表情。
至于時(shí)序就更沒有什么了,手語也是時(shí)序的。
當(dāng)然聲音相對(duì)于視覺還是有不少優(yōu)勢的:
聲音通過聲波的衍射能繞過障礙物,這是光無法辦到的(至少人類可見的光波是不行的)
衍生的結(jié)果就是聲音比光傳播得遠(yuǎn)
晚上聲音可以工作,視覺不行(其實(shí)夜視能力也是進(jìn)化出來的)
聲音是四面八方的,視覺必須直面(當(dāng)然有些動(dòng)物的視角能到360度),背對(duì)你的人你是看不到他的表情的。
可以做很多分析,但不管怎么樣,歷史沒法重新選擇,事實(shí)就是人類的進(jìn)化選擇了聲音,因此Speech就成了Language的一部分了。
因此多帶帶說Speech而不說Language其實(shí)是沒有太大意義的。
當(dāng)然后來Language為了便于保存,又發(fā)展出文字這樣的東西,而文字卻是通過視覺來感受的,不過視覺只是把文字映射到概念而已。一些文字如漢字的象形還是和視覺形象有關(guān)聯(lián)的,不過越到后來越抽象,就和視覺沒有太大關(guān)系了。
人類思考的方式也是和語言相關(guān)的,數(shù)學(xué)就是一種語言,這是人類抽象現(xiàn)實(shí)世界的先進(jìn)工具。
上面一大堆啰嗦,目的就是想說明Language是和人類的概念緊密相連的,因此遠(yuǎn)比Image/Vision更復(fù)雜。
人類社會(huì)之所以能進(jìn)步,就是通過社會(huì)化的分工與協(xié)作,讓不同的人進(jìn)化不同的能力,從而使得整個(gè)社會(huì)全方位發(fā)展。而語言文字在其中發(fā)揮著至關(guān)重要的作用,通過語言文字的傳播,人類積累的智慧就可以跨越時(shí)空傳遞。
回到我們的NLP或者NLU或者說機(jī)器理解人類語言,為什么我們對(duì)機(jī)器理解人類語言這么關(guān)注呢,因?yàn)檎Z言基本等同于智力。機(jī)器能夠理解語言也就基本能達(dá)到人工智能的目標(biāo),這也是為什么我們會(huì)認(rèn)為如果機(jī)器能夠通過圖靈測試那么它就是智能的了。
語言其實(shí)是人類表達(dá)概念或者說知識(shí)的一種方式,人類的大腦通過進(jìn)化已經(jīng)很適應(yīng)這種表示方式了。但這種邏輯的表示方式是抽象之后比較上層的表示(大腦神經(jīng)元層級(jí)是怎么表示的還不太清楚)。目前主流的方法是深度神經(jīng)網(wǎng)絡(luò),目的是模擬底層的大腦結(jié)構(gòu)。這種方法是不錯(cuò)的一個(gè)想法。之前的NLP使用的方法都是規(guī)則的,其實(shí)也就是基于邏輯的,現(xiàn)在已經(jīng)不太主流了。
但是不管用什么方法,現(xiàn)在的現(xiàn)實(shí)情況是人類已經(jīng)使用語言來存儲(chǔ)知識(shí)和表示概念,機(jī)器就得面對(duì)這種現(xiàn)實(shí)能夠?qū)W會(huì)這種交流方式。因?yàn)槲覀儧]有時(shí)間也不可能讓它們進(jìn)化出另外一種表達(dá)方式。當(dāng)然它們自己交流可以用自己的語言,比如TCP/IP語言,它們學(xué)習(xí)知識(shí)可以和人類那樣給定很多輸入/輸出訓(xùn)練數(shù)據(jù)學(xué)習(xí)出來,也可以把訓(xùn)練好的模型直接從一個(gè)機(jī)器“復(fù)制”到另外一個(gè)機(jī)器,這是人類做不到的——至少目前還做不到。我們不能把愛因斯坦的物理模型復(fù)制到我的大腦里,也許未來醫(yī)學(xué)和神經(jīng)科學(xué)高度發(fā)達(dá)之后可以實(shí)現(xiàn)。但是目前來看把機(jī)器看成人類能力的拓展更可行。
深度學(xué)習(xí)的一個(gè)方向Representation Learning其實(shí)就是有這個(gè)想法,不過目前更多關(guān)注的是一些具體任務(wù)的Feature的表示。更多是在Image和Speech領(lǐng)域,用在Language的較少,Word2vec等也可以看成表示概念的方式,不過這種向量的表示太過簡單且沒有結(jié)構(gòu)化。更少有工作考慮用神經(jīng)網(wǎng)絡(luò)怎么表示人類已有的復(fù)雜知識(shí)。現(xiàn)在的知識(shí)表示還是以幾十年前基于符號(hào)的形式邏輯的為主。
我們現(xiàn)在甚至有很多結(jié)構(gòu)化的數(shù)據(jù),比如企業(yè)數(shù)據(jù)庫、維基百科的、Google的Freebase以及內(nèi)部的Knowledge Graph。但目前都是用人類習(xí)慣的表示方式,比如三元組、圖或者實(shí)體關(guān)系。但這樣的表示方式是高層的抽象的,大腦里的神經(jīng)元似乎不能處理,因此現(xiàn)在的Deep Neural Network很難整合已有的這些知識(shí)庫進(jìn)行推理等更有用的事情。
總結(jié)
從上面的分析我們大致可以看到最近NLP的發(fā)展趨勢:深度神經(jīng)網(wǎng)絡(luò)尤其是RNN的改進(jìn),模擬人腦的Attention和Memory,更加結(jié)構(gòu)化的Word Embedding或者說Knowledge Representation。我們看到了很多很好的進(jìn)展,比如NIPS的RAM Workshop,很多大公司都在嘗試。但是Language的問題確實(shí)也非常復(fù)雜,所以也不太可能短期就解決。不過也正是這樣有挑戰(zhàn)的問題,才能讓更多有才華的人投身到這個(gè)領(lǐng)域來推動(dòng)它的發(fā)展。
作者簡介
雷欣,人工智能科技公司出門問問&Ticwatch智能手表CTO,美國華盛頓大學(xué)西雅圖分校博士,前斯坦福研究所(SRI)研究工程師,前Google美國總部科學(xué)家,語音識(shí)別領(lǐng)域十多年研究及從業(yè)者,領(lǐng)導(dǎo)開發(fā)了Google基于深度神經(jīng)網(wǎng)絡(luò)的離線語音識(shí)別系統(tǒng)。
李理,人工智能科技公司出門問問工程師,擅長NLP和knowledge graph。
來自: http://www.iteye.com/news/31261
歡迎加入本站公開興趣群
商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4364.html
摘要:年月日,麻省理工科技評(píng)論發(fā)布了年歲以下科技創(chuàng)新人中國榜單,美團(tuán)點(diǎn)評(píng)平臺(tái)部中心負(fù)責(zé)人點(diǎn)評(píng)搜索智能中心負(fù)責(zé)人王仲遠(yuǎn)獲評(píng)為遠(yuǎn)見者。這一次,王仲遠(yuǎn)依然拿到了很多頂級(jí)機(jī)構(gòu)發(fā)出的。年,因?yàn)榧彝シ矫娴目紤],王仲遠(yuǎn)選擇回國發(fā)展。 2019 年 1 月 21 日,《麻省理工科技評(píng)論》發(fā)布了 2018 年35 歲以下科技創(chuàng)新 35 人(35 Innovators Under 35)中國榜單,美團(tuán)點(diǎn)評(píng)AI平...
摘要:達(dá)觀數(shù)據(jù)招人啦面向北京上海深圳成都四個(gè)地區(qū)提供人工智能算法產(chǎn)品銷售等多類崗位畢業(yè)多年,你的狀態(tài)還好嗎是否憂慮被甩在時(shí)代的邊緣是否擔(dān)心被機(jī)器取代是否不安現(xiàn)狀躍躍欲試來吧,選擇對(duì)的行業(yè),與優(yōu)秀的人一起共事,與我們一起走在時(shí)代的風(fēng)口上,從事當(dāng)下最 showImg(https://segmentfault.com/img/bVbeHrX?w=720&h=400);達(dá)觀數(shù)據(jù)招人啦! 面向北京、上...

閱讀 3156·2023-04-25 18:22
閱讀 2390·2021-11-17 09:33
閱讀 3307·2021-10-11 10:59
閱讀 3237·2021-09-22 15:50
閱讀 2809·2021-09-10 10:50
閱讀 859·2019-08-30 15:53
閱讀 448·2019-08-29 11:21
閱讀 2908·2019-08-26 13:58



