資訊專欄INFORMATION COLUMN

摘要:在本次競賽中,南京信息工程大學和帝國理工學院的團隊獲得了目標檢測的最優成績,最優檢測目標數量為平均較精確率為。最后在視頻目標檢測任務中,帝國理工大學和悉尼大學所組成的團隊取得了較佳表現。
在本次 ImageNet 競賽中,南京信息工程大學和帝國理工學院的團隊 BDAT 獲得了目標檢測的最優成績,最優檢測目標數量為 85、平均較精確率為 0.732227。而在目標定位任務中Momenta和牛津大學的 WMV 團隊和 NUS-Qihoo_DPNs (CLS-LOC) 團隊分別在提供的數據內和加上額外數據上取得了最優成績。最后在視頻目標檢測任務中,帝國理工大學和悉尼大學所組成的 IC&USYD 團隊取得了較佳表現。
ImageNet 2017 簡介:
這次挑戰賽評估了從大規模的圖像/影像中進行物體定位/檢測的算法。最成功和富有創新性的隊伍會被邀請至 CVPR 2017 workshop 進行展示。
1. 對 1000 種類別進行物體定位
2. 對 200 種全標注類別進行物體檢測
3. 對 30 種全標注類別的視頻進行物體檢測
此次大賽是最后一屆 ImageNet 挑戰賽,并且聚焦于還未解決的問題和未來的方向。此次大賽的重點是: 1)呈現挑戰賽的結果,包含新的測試器挑戰賽(tester challenges),2)通過圖像和視頻中的物體檢測,還有分類(classification)競賽,回顧識別領域的尖端科技,3)這些方法是如何與工業界采用的計算機視覺領域的較高端技術相關聯的——這也是本次挑戰賽的初衷之一。4)邀請者對將來仍然存在的挑戰提出了自己的看法,不論是從認知視覺,到機器視覺,還是一些其他方面。
目標檢測(Object detection)
如下所示,目標檢測任務取得較好成績的是由南京信息工程大學和帝國理工學院組成的 BDAT,該隊成員 Hui Shuai、Zhenbo Yu、Qingshan Liu、 Xiaotong Yuan、Kaihua Zhang、Yisheng Zhu、Guangcan Liu 和 Jing Yang 來自于南京信息工程大學,Yuxiang Zhou 和 Jiankang Deng 來自于帝國理工學院(IC)。
該團隊表示他們在 LOC 任務中使用了適應性注意力機制 [1] 和深度聯合卷積模型 [2,3]。Scale[4,5,6]、context[7]、采樣和深度聯合卷積網絡在 DET 任務中得到了有效的使用。同時他們的得分排名也使用了物體概率估計。
[1] Residual Attention Network for Image Classification[J]. arXiv:1704.06904, 2017.?
[2] Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.?
[3] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[C]//AAAI. 2017: 4278-4284.?
[4] U-net: Convolutional networks for biomedical image segmentation[J]. arXiv:1505.04597, 2015.?
[5] Feature pyramid networks for object detection[J]. arXiv:1612.03144, 2016.?
[6] Beyond skip connections: Top-down modulation for object detection[J]. arXiv:1612.06851, 2016.?
[7] Crafting GBD-Net for Object Detection[J]. arXiv:1610.02579, 2016.
任務 1a:使用提供的訓練數據進行目標檢測
根據檢測出的目標數量排序
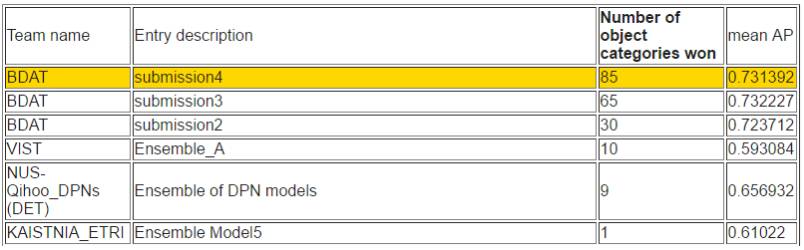
根據平均準確率排序

而在目標檢測任務中新加坡國立大學(NUS)和奇虎 360 組成的 NUS-Qihoo_DPNs (DET) 也獲得了不錯的成績。
他們在基于 Faster R-CNN 的目標檢測任務中,采用了一個包含全新雙路徑拓撲的雙路徑網絡(DPN/Dual Path Network)。DPN 中的特征共享機制和探索新特征的靈活性被證明在目標檢測中有效。特別地,研究人員采用了若干個 DPN 模型——即 DPN-92、DPN-107、DPN-131 等——作為 Faster R-CNN 框架中的中繼特征學習器(trunk feature learner)和頭分類器(head classifier)。他們只使用最多 131 層的網絡,因為在大多數常用的 GPU 內,它易于訓練和適應,且性能良好。對于區域提案生成,利用低級細粒度特征取得了有效的 proposals 召回。進而,通過在分割成檢測框架中采用擴展卷積,他們合并了有益的語境信息。在測試期間,他們設計了一個類別加權策略,以探索不同類別的專家模型,并根據多任務推斷把權重用到不同的專家。除此之外,他們在圖像分類任務中采用了預訓練的模型以提取整體語境信息,這可在整體輸入圖像中為探測結果的推理提供有益的線索。
任務 1b:使用額外的訓練數據進行目標檢測
根據檢測出的目標數量排序
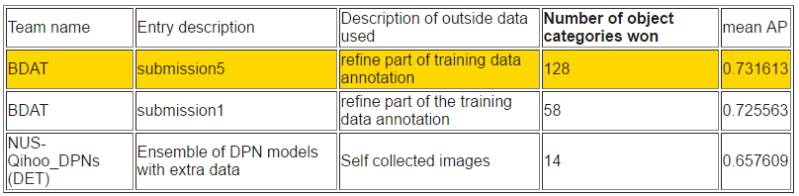
根據平均準確率排序

目標定位(Object localization)
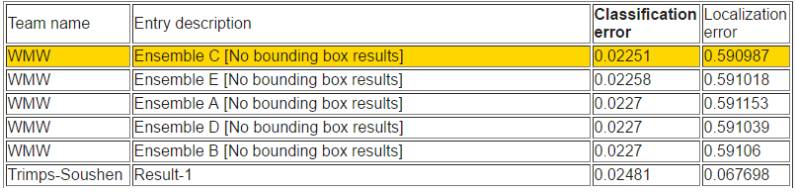
在給定訓練數據進行分類和定位的任務中,WMW 取得了優異的成績,分類誤差率是較低的。
他們設計了一個新型結構的構造模塊,叫做「擠壓與激勵」(「Squeeze-and-Excitation——SE」)。每一個基礎構造模塊通過「擠壓」操作在全局接收域中嵌入信息,并且通過「激勵」操作選擇性地引起增強型響應(response enhancement)。SE 模型是該團隊參賽作品的基礎。他們研發了多個版本的 SENet,比如 SE-ResNet,SE-ResNeXt 和 SE-Inception-ResNet,在增加少量運算和 GPU 內存的基礎上,這明顯超過了它們的非 SE 對應部分。該團隊在驗證數據集中達到了 2.3% 的 top-5 誤差率。
任務 2a:使用提供的訓練數據進行分類+定位
根據定位錯誤率排序

根據分類錯誤率排名
在使用附加訓練數據進行分類和定位的任務中,NUS-Qihoo_DPNs (CLS-LOC) 的定位誤差率和分類誤差率如下所示都取得很好的成績。據該團隊介紹,他們構建了一個簡單、高效、模塊化的雙路徑網絡,引入了全新雙路徑拓撲。這一 DPN 模型包含一個殘差路徑和一個稠密連接路徑,二者能夠在保持學習探索新特征的靈活性的同時共享共同特征。DPN 是該團隊完成全部任務使用的主要網絡。在 CLS-LOC 任務中,他們采用 DPN 來預測 Top-5 目標,然后使用基于 DPN 的 Faster RCNN 分配對應的定位邊界框。
任務 2b:使用額外的訓練數據進行分類+定位
根據定位錯誤率排名

根據分類錯誤率排名

視頻目標檢測(Object detection from video)
如下所示,在視頻目標檢測任務中,帝國理工大學和悉尼大學所組成的 IC&USYD 團隊在各個子任務和排序上都取得了最優的成績。該團隊是視頻目標檢測任務中使用了流加速(Flow acceleration)[1, 2]。并且最終的分值也是適應性地在檢測器(detector)和追蹤器(tracker)選擇。
任務 3a:使用提供的訓練數據進行視頻目標檢測
根據檢測出的目標數量排序

根據平均準確率排序
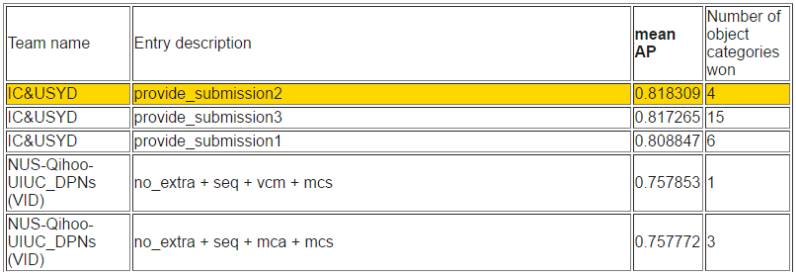
同時 NUS-Qihoo-UIUC_DPNs (VID) 在視頻任務中同樣有非凡的表現。他們在視頻目標檢測任務上的模型主要是基于 Faster R-CNN 并使用雙路徑網絡作為支柱。具體地他們采用了三種 DPN 模型(即 DPN-96、DPN-107 和 DPN-131)和 Faster R-CNN 框架下的頂部分類器作為特征學習器。他們團隊單個模型在驗證集較好能實現 79.3%(mAP)。此外他們還提出了選擇性平均池化(selected-average-pooling)策略來推斷視頻情景信息,該策略能精煉檢測結果。
任務 3b:使用額外的訓練數據進行視頻目標檢測
根據檢測出的物體數量排序
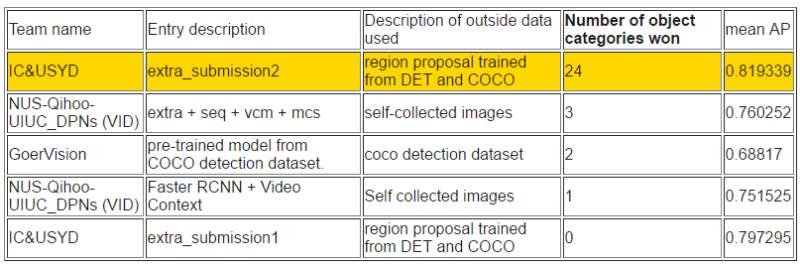
根據平均準確率排序
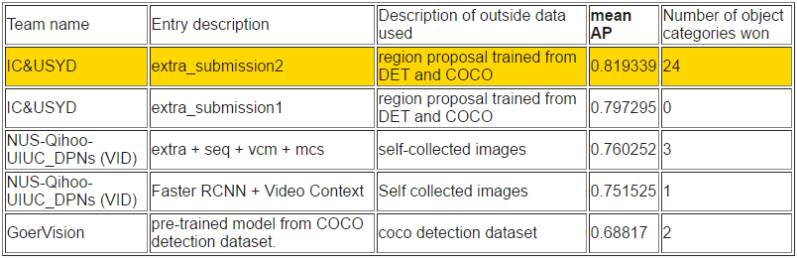
任務 3c:使用提供的訓練數據進行視頻目標檢測/跟蹤
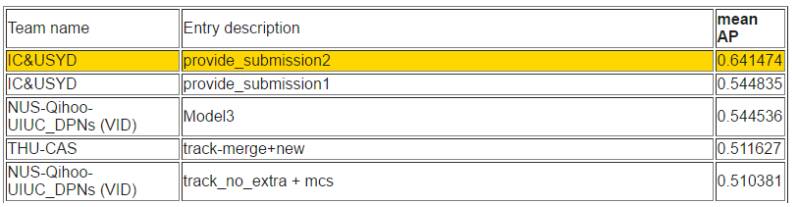
任務 3d:使用額外的訓練數據進行視頻目標檢測/跟蹤

本次 ImageNet 競賽是最后一次,但同時 WebVision 近日也發布了其視覺競賽的結果。相對于人工標注的 ImageNet 數據集,WebVision 中的數據擁有更多的噪聲,并且它們更多的是從網絡中獲取,因此成本要比 ImageNet 低廉地多。正如近日谷歌發表的論文「Revisiting Unreasonable Effectiveness of Data in Deep Learning Era」,他們表示隨著計算力的提升和模型性能的大大增強,我們很有必要構建一個更大和不那么標準的數據集。在該篇論文中,谷歌發現巨型非標準數據集(帶噪聲)同樣能令模型的精度達到目前較好的水平,那么 ImageNet 下一步是否會被 JFT-300M 這樣的數據集替換?因此我們很有必要關注能在噪聲數據下學習到很好模型的競賽——WebVision。

近日,WebVision 也發布了其視覺競賽的結果,Malong AI Research 獲得了圖像分類任務的最優成績。
WebVision 2017 挑戰賽結果
WebVision 圖像分類任務
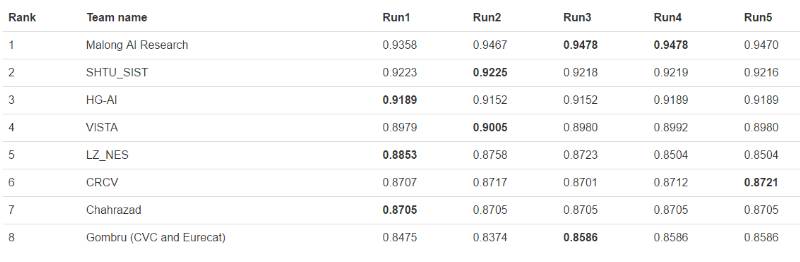
Pascal VOC 遷移學習任務

獲勝團隊 Malong AI Research:
我們使用半監督學習方法解決如何利用有噪聲的不均衡數據訓練大規模深度神經網絡的問題。我們首先使用聚類算法將訓練數據分成兩部分:干凈數據和噪聲數據,然后使用干凈數據訓練一個深度網絡模型。之后,我們使用所有數據(包括干凈數據和噪聲數據)來訓練第一個模型(干凈數據訓練出的模型)上的網絡。值得注意的是,我們在該網絡的原始卷積層上使用了兩個不同大小的卷積核(5,9)。至于訓練,我們在干凈數據上進行數據平衡,并設計了一個新的自適應 lr 下降系統,該系統根據噪聲的類型(干凈數據和噪聲數據)略有不同。
WEBVISION 數據集
WebVision 數據集的設計是用來促進從嘈雜互聯網數據中學習視覺表征的相關研究的。我們的目的是使深度學習方法從巨大的人工勞力(標注大規模視覺數據集)中解脫出來。我們把這個大規模網絡圖像數據集作為基準來發布,以推進在網絡數據中進行學習的相關研究,包括弱監督視覺表征學習(weakly supervised visual representation learning),視覺遷移學習(visual transfer learning),文本與視覺(text and vision)等等(詳見 WebVision 數據集的推薦環境配置)。
WebVision 數據集包含超過 24 萬張的圖像,它們是從 Flickr 網站和谷歌圖像搜索引擎中爬取出來的。與 ILSVRC 2012 數據集相同的 1000 張圖像用于查詢(query),因此可以對一些現有方法直接進行研究,而且可以與在 ILSVRC 2012 數據集中進行訓練的模型進行比較,還可以使在大規模場景中研究數據集偏差(dataset bias)的問題成為可能。伴隨那些圖片的文本信息(例如字注、用戶標簽或描述)也作為附加的元數據信息(meta information)來提供。提供一個包括 50,000 張圖像(每一類別 50 張)的驗證數據集以推進算法級研發。一個簡單基準的初級結果展示了 WebVision 在一些視覺任務中是能夠學習魯棒性表征的,其性能表現與在人工標注的 ILSVRC 2012 數據集中學習的模型相類似。
數據集詳情
數據統計
在我們的數據集中,每一類別的圖像數量如圖 1 所示,從幾百到超過 10,000。每一類別中的圖像數量依賴于:1)每一類別中的同義詞集合生成的查詢指令(query)的數量,2)Flickr 和谷歌的圖像的有效性。
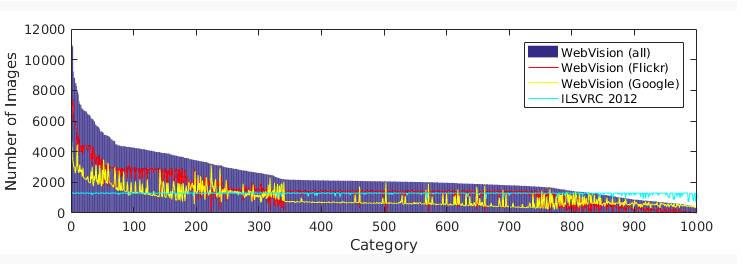
圖 1:WebVision 數據集中每一類別的圖像數量
簡易基準評估
我們使用一個簡單的基準對用于學習視覺表征的網絡數據容量進行了調查研究。我們把來自 Flickr 和 Google 的已查詢圖像作為我們的訓練數據集,并且從零開始在這一訓練集上對 AlexNet 模型進行訓練。然后我們在 Caltech-256 數據集和 PASCAL VOC 2007 數據集的圖像分類任務中對學習后的 AlexNet 模型進行了評估,并且也在 PASCAL VOC 2007 數據集的物體識別相關任務中做了檢測。
圖像分類
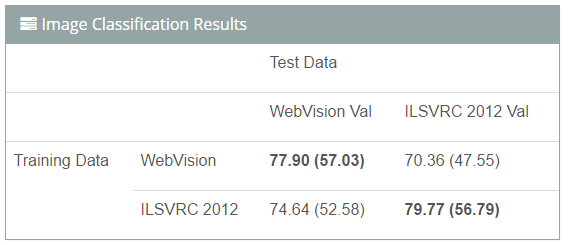
我們使用一個簡單的基準調查研究了用于學習深度網絡的網絡數據容量。我們分別在 WebVision 訓練集和 ILSVRC 2012 數據集上從頭訓練 AlexNet 模型,然后在 WebVision 驗證集和 ILSVRC 2012 驗證集上對這兩個模型進行評估。需要注意的是,在 WebVision 數據集上訓練模型時未使用人工標注數據。這里我們對 top-5(top-1)的準確率進行了報道。
結果如下:(1)使用 WebVision 數據集訓練的 CNN 模型性能優于使用人工標注的 ILSVRC 2012 數據集訓練的模型;(2)存在數據偏差,即在 WebVision 驗證集上對這兩個模型進行評估時,在 WebVision 上訓練的模型優于在 ILSVRC 2012 上訓練的模型,反之亦然。這對領域適應研究者可能是一個有意思的話題。
挑戰賽結果地址:http://image-net.org/challenges/LSVRC/2017/results
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4602.html
摘要:年月日,將標志著一個時代的終結。數據集最初由斯坦福大學李飛飛等人在的一篇論文中推出,并被用于替代數據集后者在數據規模和多樣性上都不如和數據集在標準化上不如。從年一個專注于圖像分類的數據集,也是李飛飛開創的。 2017 年 7 月 26 日,將標志著一個時代的終結。那一天,與計算機視覺頂會 CVPR 2017 同期舉行的 Workshop——超越 ILSVRC(Beyond ImageNet ...
摘要:月日至日,由麥思博主辦的第屆軟件工作坊在深圳華僑城洲際大酒店盛大召開,位來自互聯網行業的一線大咖與超過位中高層技術管理精英匯聚交流,共同探討最前沿技術熱點與技術思維。軟件工作坊的每一屆舉辦在技術交流案例分析達成共識上都取得了豐碩的成果。 6月24日至25日,由麥思博(msup)主辦的第35屆MPD軟件工作坊在深圳華僑城洲際大酒店盛大召開,25位來自互聯網行業的一線大咖與超過500位中高...
摘要:月日日,由主辦的人工智能與機器學習創新峰會在上海海神諾富特大酒店圓滿結束。簽到現場,秩序井然本次峰會匯聚了超過位國內外頂級人工智能專家及一線技術大咖。本屆峰會共設置了個專題,大主題分會場并行。話題主要圍繞知乎搜索排序召回展開的。 人工智能的迅速發展深刻改變了世界的發展模式和人們的生活方式。5月18日-19日,由msup主辦的A2M人工智能與機器學習創新峰會在上海海神諾富特大酒店圓滿結束...
摘要:不僅闡明了應對一系列問題的解決方案,還介紹了在百花齊放的公鏈項目中的核心競爭力,并透露了主網會在月份正式發布的利好消息。共識之夜圓滿落幕月日,聯合星球日報及區塊律動舉辦的共識之夜圓滿落幕。 親愛的ETM小伙伴: 隨著高考、中考、期末考陸續結束 學生們似乎迎來了一年中最輕松的時刻 而對于區塊鏈圈的人來說 卻到了最難熬的時期 豐水期來臨本是好事 奈何幣價起起伏伏 算力再次大幅提升 伊朗加入...

閱讀 688·2023-04-25 19:53
閱讀 4260·2021-09-22 15:13
閱讀 2564·2019-08-30 10:56
閱讀 1320·2019-08-29 16:27
閱讀 2931·2019-08-29 14:00
閱讀 2406·2019-08-26 13:56
閱讀 425·2019-08-26 13:29
閱讀 1610·2019-08-26 11:31





