資訊專欄INFORMATION COLUMN

摘要:代碼地址在這篇文章中,我將盡我所能揭秘三種降維技術和自編碼器。動機當處理真實問題和真實數據時,我們往往遇到維度高達數百萬的高維數據。盡管在其原來的高維結構中,數據能夠得到較好的表達,但有時候我們可能需要給數據降維。
代碼地址:https://github.com/eliorc/Medium/blob/master/PCA-tSNE-AE.ipynb
在這篇文章中,我將盡我所能揭秘三種降維技術:PCA、t-SNE 和自編碼器。我做這件事的主要原因是基本上這些方法都被當作黑箱對待,因此有時候會被誤用。理解它們將能讓讀者有辦法決定在何時如何使用哪一種方法。
為了實現這一目標,我將深入到每種方法的內部,并且將使用 TensorFlow 從零開始為每種方法編寫代碼(t-SNE 除外)。為什么選擇 TensorFlow?因為其最常被用于深度學習領域,讓我們能有點挑戰。
動機
當處理真實問題和真實數據時,我們往往遇到維度高達數百萬的高維數據。
盡管在其原來的高維結構中,數據能夠得到較好的表達,但有時候我們可能需要給數據降維。
降維的需求往往與可視化有關(減少兩三個維度,好讓我們可以繪圖),但這只是其中一個原因。
有時候,我們認為性能比精度更重要,那么我們就可以將 1000 維的數據降至 10 維,從而讓我們可以更快地對這些數據進行操作(比如計算距離)。
有時候對降維的需求是真實存在的,而且有很多應用。
在我們開始之前,先看一個問題:如果你要為以下案例選擇一種降維技術,你會怎么選?
1. 你的系統可以使用余弦相似度測量距離,但你需要將其可視化,以便不懂技術的董事會成員也能理解,這些人可能甚至從來沒聽說過余弦相似度;你會怎么做?
2. 你有必要將數據的維度壓縮到盡可能較低,你的限制是要保留大約 80% 的數據,你會怎么做?
3. 你有一個數據庫,其中的數據是耗費了大量時間收集的,而且還時不時有新的(相似類型的)數據加入。你需要降低你已有數據的維度,并且還要給到來的新數據降維,你會選擇什么方法?
這篇文章的目的是希望能幫助你更好地了解降維,以便你能輕松應對類似這樣的問題。
讓我們從 PCA 開始吧。
PCA
PCA,即主成分分析(Principal Component Analysis),可能是最古老的技巧了。
PCA 已經得到了充分的研究,而且有很多方法可以實現這種解決方案,這里我們會談到其中兩種:Eigen 分解和奇異值分解(SVD),然后我們會在 TensorFlow 中實現其中的 SVD 方法。
從現在起,假設我們的數據矩陣為 X,其 shape 為 (n, p),其中 n 是指樣本的數量,而 p 是指維度。
所以給定了 X 之后,這兩種方法都要靠自己的方式找到一種操作并分解 X 的方法,以便接下來我們可以將分解后的結果相乘,從而以更少的維度表征較大化的信息。我知道,這聽起來很唬人,但我們不會深入到數學證明中去,僅保留有助于我們理解這種方法的優缺點的部分。
所以 Eigen 分解和 SVD 都是分解矩陣的方式,讓我們看看它們可以在 PCA 中提供怎樣的幫助,以及它們有怎樣的聯系。
先看看下面的流程圖,我會在后面解釋。
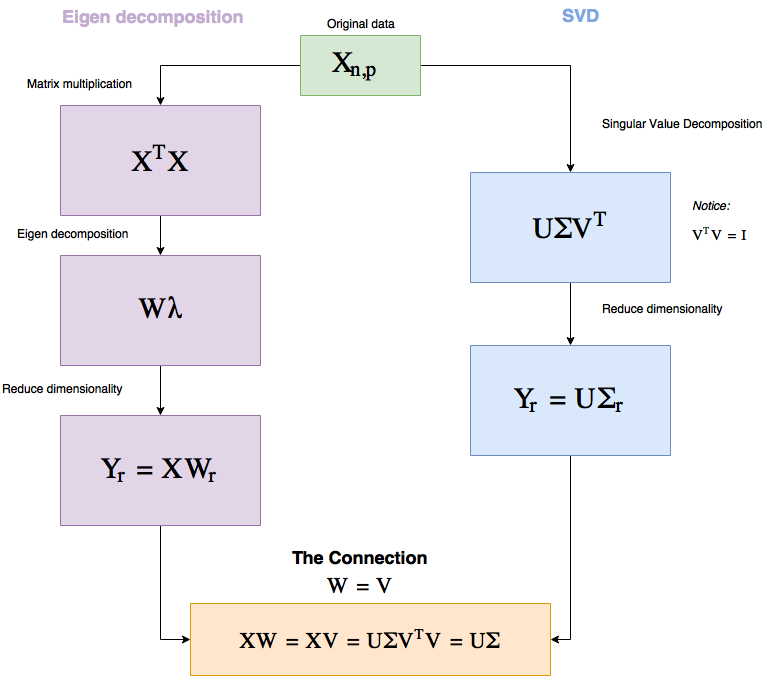
圖 1:PCA 工作流程
所以,你為什么要關心這個?實際上,這兩個流程中有一些非常基本的東西,能夠給我們理解 PCA 提供很大幫助。
你可以看到,這兩種方法都是純線性代數,這基本上就意味著:使用 PCA 就是在另一個角度看待真實數據——這是 PCA 獨有的特性,因為其它方法都是始于低維數據的隨機表征,然后使其表現得就像是高維數據。
另外值得一提的是因為所有的運算都是線性的,所以 SVD 的速度非常快。
另外,給定同樣的數據,PCA 總是會給出同樣的答案(而其它兩種方法卻不是這樣)。
注意我們在 SVD 中是怎樣選擇 r(r 是我們想要降低至的維度)的,以便將 Σ 中的大部分值保留到更低的維度上。
Σ 則有一些特別之處。
Σ 是一個對角矩陣(diagonal matrix),其中有 p(維度數)個對角值(被稱為奇異值(singular value)),它們的大小表明了它們對保存信息的重要程度。
所以我們可以選擇降維到能保留給定比例的數據的維度數,后面我將通過代碼說明。(比如讓我們降維,但最多失去 15% 的數據。)
你將看到,用 TensorFlow 寫這個代碼是很簡單的,我們要編碼的是一個帶有 fit 方法和我們將提供維度的 reduce 方法的類。
代碼(PCA)
設 self.X 包含數據且 self.dtype=tf.float32,那么 fit 方法看起來就是這樣:
def fit(self):
? ? self.graph = tf.Graph()
? ? with self.graph.as_default():
? ? ? ? self.X = tf.placeholder(self.dtype, shape=self.data.shape)
? ? ? ? # Perform SVD
? ? ? ? singular_values, u, _ = tf.svd(self.X)
? ? ? ? # Create sigma matrix
? ? ? ? sigma = tf.diag(singular_values)
? ? with tf.Session(graph=self.graph) as session:
? ? ? ? self.u, self.singular_values, self.sigma = session.run([u, singular_values, sigma],
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?feed_dict={self.X: self.data})
所以 fit 的目標是創建我們后面要用到的 Σ 和 U。
我們將從 tf.svd 行開始,這一行給了我們奇異值(就是圖 1 中標記為 Σ 的對角值)和矩陣 U 和 V。
然后 tf.diag 是 TensorFlow 的將一個 1D 向量轉換成一個對角矩陣的方法,在我們的例子中會得到 Σ。
在 fit 調用結束后,我們將得到奇異值、Σ 和 U。
現在讓我們實現 reduce。
def reduce(self, n_dimensions=None, keep_info=None):
? ? if keep_info:
? ? ? ? # Normalize singular values
? ? ? ? normalized_singular_values = self.singular_values / sum(self.singular_values)
? ? ? ? # Create the aggregated ladder of kept information per dimension
? ? ? ? ladder = np.cumsum(normalized_singular_values)
? ? ? ? # Get the first index which is above the given information threshold
? ? ? ? index = next(idx for idx, value in enumerate(ladder) if value >= keep_info) + 1
? ? ? ? n_dimensions = index
? ? with self.graph.as_default():
? ? ? ? # Cut out the relevant part from sigma
? ? ? ? sigma = tf.slice(self.sigma, [0, 0], [self.data.shape[1], n_dimensions])
? ? ? ? # PCA
? ? ? ? pca = tf.matmul(self.u, sigma)
? ? with tf.Session(graph=self.graph) as session:
? ? ? ? return session.run(pca, feed_dict={self.X: self.data})
如你所見,reduce 既有 keep_info,也有 n_dimensions(我沒有實現輸入檢查看是否只提供了其中一個)。
如果我們提供 n_dimensions,它就會降維到那個數;但如果我們提供 keep_info(應該是 0 到 1 之間的一個浮點數),就說明了我們將從原來的數據中保存多少信息(假如是 0.9,就保存 90% 的數據)。
在第一個 if 中,我們規范化并檢查了需要多少了奇異值,基本上能從 keep_info 得知 n_dimensions。
在這個圖中,我們只需要從 Σ (sigma) 矩陣切下我們所需量的數據,然后執行矩陣乘法。
現在讓我們在鳶尾花數據集上試一試,這是一個 (150, 4) 的數據集,包含了三種鳶尾花。
from sklearn import datasets
import matplotlib.pyplot as plt
import seaborn as sns
tf_pca = TF_PCA(iris_dataset.data, iris_dataset.target)
tf_pca.fit()
pca = tf_pca.reduce(keep_info=0.9) ?# Results in 2 dimensions
color_mapping = {0: sns.xkcd_rgb["bright purple"], 1: sns.xkcd_rgb["lime"], 2: sns.xkcd_rgb["ochre"]}
colors = list(map(lambda x: color_mapping[x], tf_pca.target))
plt.scatter(pca[:, 0], pca[:, 1], c=colors)
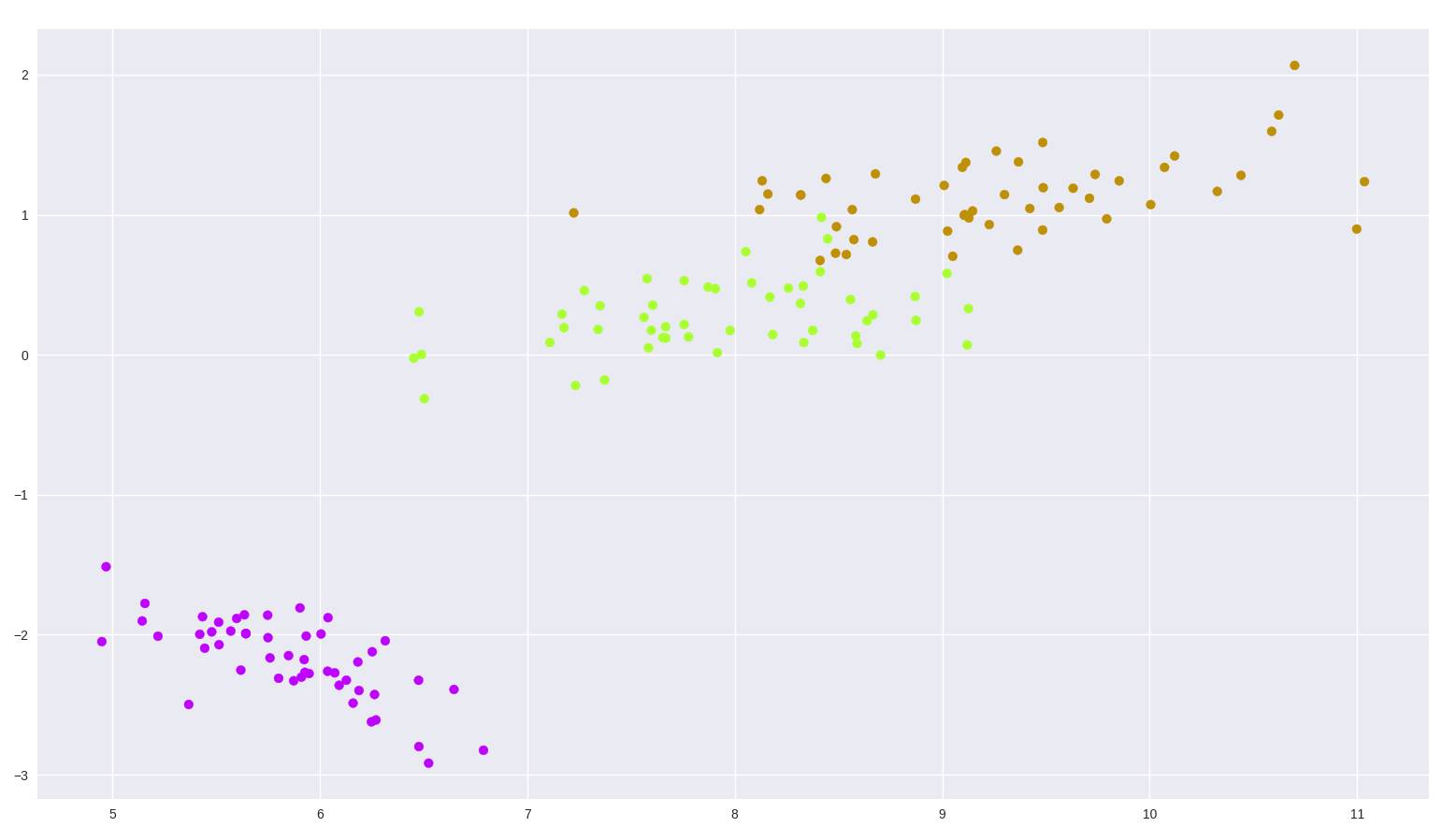
圖 2:鳶尾花數據集 PCA 二維繪圖
還不錯吧?
t-SNE
相對于 PCA,t-SNE 是一種相對較新的方法,起源于 2008 年的論文《Visualizing Data using t-SNE》:http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
它也比 PCA 更難理解,所以讓我們一起堅持一下。
我們對 t-SNE 的符號定義為:X 是原來的數據;P 是一個矩陣,顯示了高維(原來的)空間中 X 中的點之間的親和度(affinities,約等于距離);Q 也是一個矩陣,顯示了低維空間中數據點之間的親和度。如果你有 n 個數據樣本,那么 Q 和 P 都是 n×n 的矩陣(從任意點到任意點的距離包含自身)。
現在 t-SNE 有自己的「獨特的」測量事物之間距離的方式(我們下面就會介紹)、一種測量高維空間中數據點之間的距離的方式、一種測量低維空間中數據點之間的距離的方式以及一種測量 P 和 Q 之間的距離的方式。
根據原始論文,一個數據點 x_j 與另一個點 x_i 之間的相似度是 p_j|i,其定義為:「x_i 選取 x_j 為其近鄰點(neighbor),而近鄰點的選取與以 x_i 為中心的高斯分布概率密度成正比。」
「這是什么意思!」不要擔心,我前面說了,t-SNE 有自己測量距離的獨特方式,所以讓我們看看用于測量距離(親和度)的公式,然后從中取出我們理解 t-SNE 的行為所需的見解。
從高層面來講,這就是算法的工作方式(注意和 PCA 不一樣,這是一個迭代式的算法)。
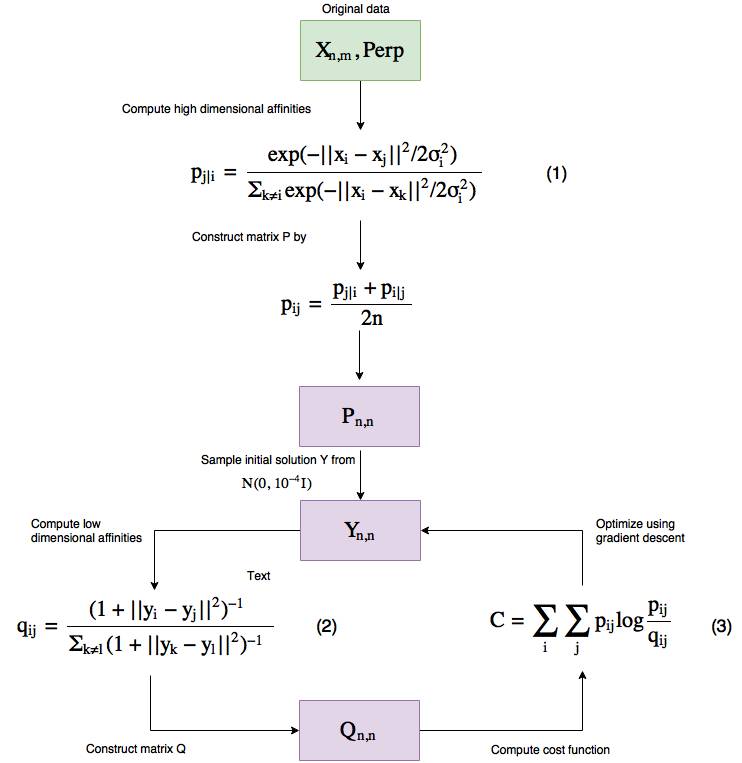
圖 3:t-SNE 工作流程
讓我們一步步地研究一下這個流程。
這個算法有兩個輸入,一個是數據本身,另一個被稱為困惑度(Perp)。
簡單來說,困惑度(perplexity)是指在優化過程中數據的局部(封閉點)和全局結構的焦點的平衡程度——本文建議將其保持在 5 到 50 之間。
更高的困惑度意味著一個數據點會把更多的數據點看作是其緊密的近鄰點,更低的困惑度就更少。
困惑度會實際影響可視化的結果,而且你需要小心應對,因為它可能會在可視化低維數據時出現誤導現象——我強烈推薦閱讀這篇文章了解如何使用 t-SNE 困惑度:http://distill.pub/2016/misread-tsne,其中介紹了不同困惑度的影響。
這種困惑度從何而來?它被用于求解式子 (1) 中的 σ_i,而且因為它們有單調的連接,所以可以通過二元搜索(binary search)找到。
所以使用我們提供給算法的困惑度,我們基本上會找到不同的 σ_i。
讓我們看看公式為我們提供了哪些關于 t-SNE 的信息。
在我們探索公式 (1) 和 (2) 之前,需要知道 p_ii 和 q_ii 被設置為 0(即使我們將它們應用到兩個相似的點上,公式的輸出也不會是 0,這只是給定的值)。
所以看看公式 (1) 和 (2),我希望你注意到,當兩個點很接近時(在高維表征中),分子的值大約為 1,而如果它們相距非常遠,那么我們會接近無窮小——這將有助于我們后面理解成本函數。
現在我們可以了解關于 t-SNE 的一些事情了。
一是因為親和度公式的構建方式,在 t-SNE 圖中解讀距離可能會出問題。
這意味著聚類之間的距離和聚類大小可能被誤導,并且也會受到所選擇的困惑度的影響(在上面我推薦的文章中,你可以看到這些現象的可視化)。
第二件要注意的事情是,怎么在等式 (1) 中我們基本上計算的是點之間的歐幾里得距離?這方面 t-SNE 很強大,我們可以用任何我們喜歡的距離測量來取代它,比如余弦距離、Manhattan 距離,也可以使用任何你想用的測量方法(只要其保持空間度量(space metric),而且保持低維親和度一樣)——以歐幾里得的方式會得到復雜的距離繪圖。
比如說,如果你是一位 CTO,你有一些數據需要根據余弦相似度測量距離,而你的 CEO 想要你通過圖表的形式呈現這些數據。我不確定你是否有時間向董事會解釋什么是余弦相似度以及解讀聚類的方式,你可以直接繪制余弦相似度聚類,因為歐幾里得距離聚類使用 t-SNE——要我說,這確實很酷。
在代碼中,你可以在 scikit-learn 中通過向 TSNE 方法提供一個距離矩陣來實現。
現在,我們知道當 x_i 和 x_j 更近時,p_ij/q_ij 的值更大;相反則該值更小。
讓我們看看這會對我們的成本函數(被稱為 KL 散度(Kullback–Leibler divergence))帶來怎樣的影響。讓我們繪圖,然后看看沒有求和部分的公式 (3)。

圖 4:沒有求和部分的 t-SNE 成本函數
很難看明白這是啥?但我在上面給軸加了名字。
如你所見,這個成本函數是不對稱的。
對于高維空間中臨近的點,其得出了非常高的成本(p 軸),但這些點是低維空間中很遠的點表示的;而在高維空間中遠離的點則成本更低,它們則是用低維空間中臨近的點表示的。
這說明在 t-SNE 圖中,距離解釋能力的問題甚至還更多。
model = TSNE(learning_rate=100, n_components=2, random_state=0, perplexity=5)
tsne5 = model.fit_transform(iris_dataset.data)
model = TSNE(learning_rate=100, n_components=2, random_state=0, perplexity=30)
tsne30 = model.fit_transform(iris_dataset.data)
model = TSNE(learning_rate=100, n_components=2, random_state=0, perplexity=50)
tsne50 = model.fit_transform(iris_dataset.data)
plt.figure(1)
plt.subplot(311)
plt.scatter(tsne5[:, 0], tsne5[:, 1], c=colors)
plt.subplot(312)
plt.scatter(tsne30[:, 0], tsne30[:, 1], c=colors)
plt.subplot(313)
plt.scatter(tsne50[:, 0], tsne50[:, 1], c=colors)
plt.show()
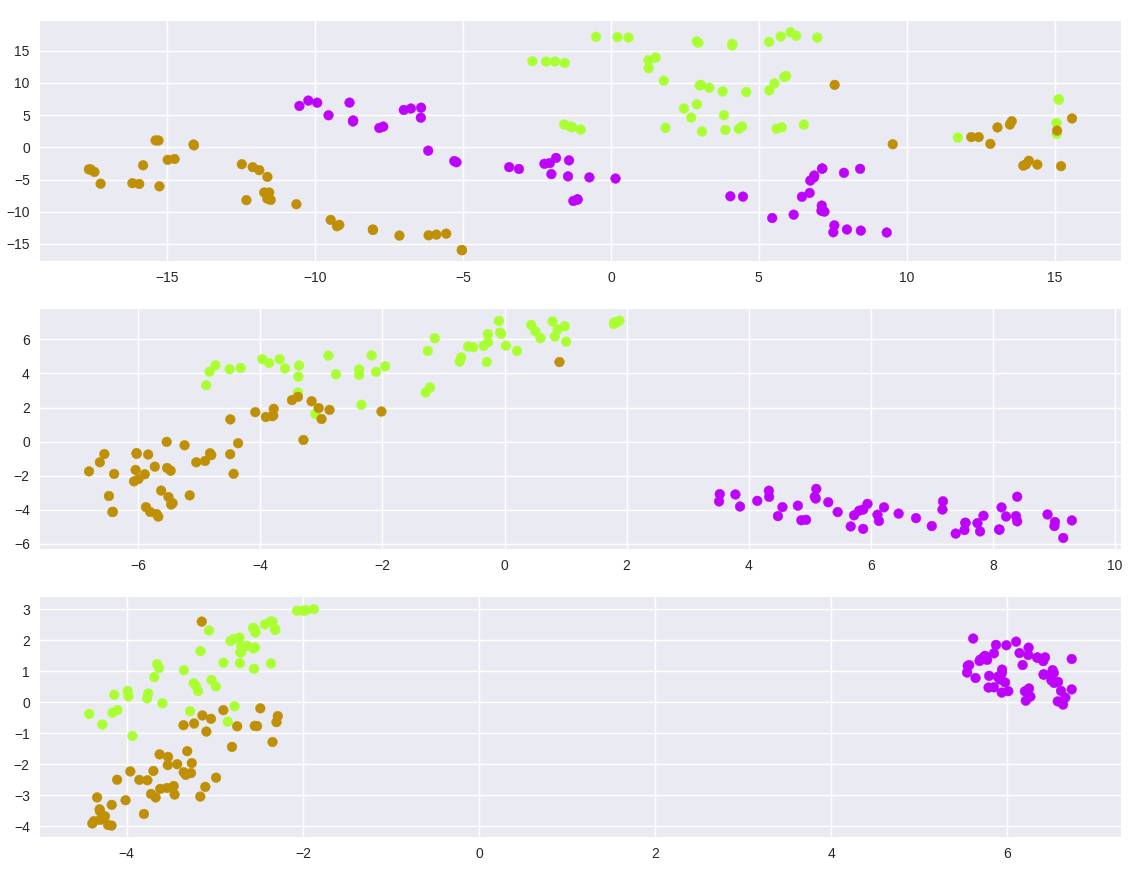
圖 5:在鳶尾花數據集上的 t-SNE,不同的困惑度
正如我們從數學中了解到的那樣,你可以看到給定一個好的困惑度,數據會聚類,但要注意超參數的敏感性(如果不給梯度下降提供學習率,我無法找到聚類)。
在我們繼續之前,我想說如果使用正確,t-SNE 會是一種非常強大的方法,而不會受到前面提及的負面影響,只是你要清楚如何使用它。
接下來是自編碼器。
自編碼器(Auto Encoders)
PCA 和 t-SNE 是方法,而自編碼器則是一系列的方法。
自編碼器是一種神經網絡,其目標是通過使用比輸入節點更少的隱藏節點(在編碼器一端)預測輸入(訓練該網絡使其輸出盡可能與輸入相似),為此該網絡需要盡可能多地將信息編碼到隱藏節點中。
圖 6 給出了一個用于 4 維鳶尾花數據集的基本自編碼器,其中輸入層到隱藏層之間的連接線被稱為編碼器(encoder),而隱藏層到輸出層之間的線被稱為解碼器(decoder)。

圖 6:用于鳶尾花數據集的基本自編碼器
所以為什么自編碼器是一系列方法呢?因為我們僅有的約束條件是其輸入層和輸出層具有同樣的維度,在兩者之間,我們可以創建任何我們想要的可以較好地編碼我們的高維數據的結構。
自編碼器始于一些隨機的低維表征(z)并會通過梯度下降改變其輸入層和隱藏層以及隱藏層和輸出層之間連接的權重,從而找到它們的解。
現在,我們對自編碼器已經有了一定了解,因為我們可以控制該網絡的內部,我們可以讓編碼器能挑選出特征之間的非常復雜的關系。
自編碼器還有一個加分項。因為在訓練結束時,我們有與隱藏層的連接權重,所以我們可以在特定的輸入上訓練,如果后面我們遇到了另一個數據點,那么我們無需重新訓練就可以使用這些權重進行降維——但這種操作要小心,只有當新數據點與我們訓練所用的數據點類似時這才有效。
在這種情況下,探索自編碼器的數學可能很簡單,但卻沒什么用處,因為對于每一種架構和我們選擇的成本函數,其數學形式可能是不同的。
但如果我們想一想自編碼器權重的優化方式,我們會理解我們定義的成本函數具有非常重要的作用。
因為自編碼器會使用成本函數來確定其預測結果的質量,那么我們就可以使用這個功能來強化我們希望實現的東西。
不管我們想要的是歐幾里得距離還是其它測量,我們都可以通過成本函數、使用不同的距離方法、使用不對稱函數和其它方法而將其反映到編碼的數據上。
而且因為自編碼器本質上是神經網絡,所以它還具有更大的力量,我們甚至可以在訓練時給類和樣本加權,從而為數據中的特定現象提供更大的重要性。
這能給我們壓縮數據的方式提供很大的靈活性。
自編碼器非常強大,而且在一些案例中能實現比其它方法更好的結果(谷歌搜一下「PCA vs Auto Encoders」,你就知道),所以它們肯定是一種有效的方法。
讓我們用 TensorFlow 實現一個基于鳶尾花數據集的基本自編碼器,并且繪圖。
代碼(自編碼器)
同樣,我們將其分成了 fit 和 reduce。
def fit(self, n_dimensions):
? ? graph = tf.Graph()
? ? with graph.as_default():
? ? ? ? # Input variable
? ? ? ? X = tf.placeholder(self.dtype, shape=(None, self.features.shape[1]))
? ? ? ? # Network variables
? ? ? ? encoder_weights = tf.Variable(tf.random_normal(shape=(self.features.shape[1], n_dimensions)))
? ? ? ? encoder_bias = tf.Variable(tf.zeros(shape=[n_dimensions]))
? ? ? ? decoder_weights = tf.Variable(tf.random_normal(shape=(n_dimensions, self.features.shape[1])))
? ? ? ? decoder_bias = tf.Variable(tf.zeros(shape=[self.features.shape[1]]))
? ? ? ? # Encoder part
? ? ? ? encoding = tf.nn.sigmoid(tf.add(tf.matmul(X, encoder_weights), encoder_bias))
? ? ? ? # Decoder part
? ? ? ? predicted_x = tf.nn.sigmoid(tf.add(tf.matmul(encoding, decoder_weights), decoder_bias))
? ? ? ? # Define the cost function and optimizer to minimize squared error
? ? ? ? cost = tf.reduce_mean(tf.pow(tf.subtract(predicted_x, X), 2))
? ? ? ? optimizer = tf.train.AdamOptimizer().minimize(cost)
? ? with tf.Session(graph=graph) as session:
? ? ? ? # Initialize global variables
? ? ? ? session.run(tf.global_variables_initializer())
? ? ? ? for batch_x in batch_generator(self.features):
? ? ? ? ? ? self.encoder["weights"], self.encoder["bias"], _ = session.run([encoder_weights, encoder_bias, optimizer],
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? feed_dict={X: batch_x})
這里沒什么特別要說的,代碼本身就已經給出了解釋。我們可以看到在偏置中的編碼器權重,然后我們可以在下面的 reduce 方法中給該數據降維。
def reduce(self):
? ? return np.add(np.matmul(self.features, self.encoder["weights"]), self.encoder["bias"])
沒錯,就是這么簡單 :)
讓我們看看它的效果(批大小:50,1000 epoch)。
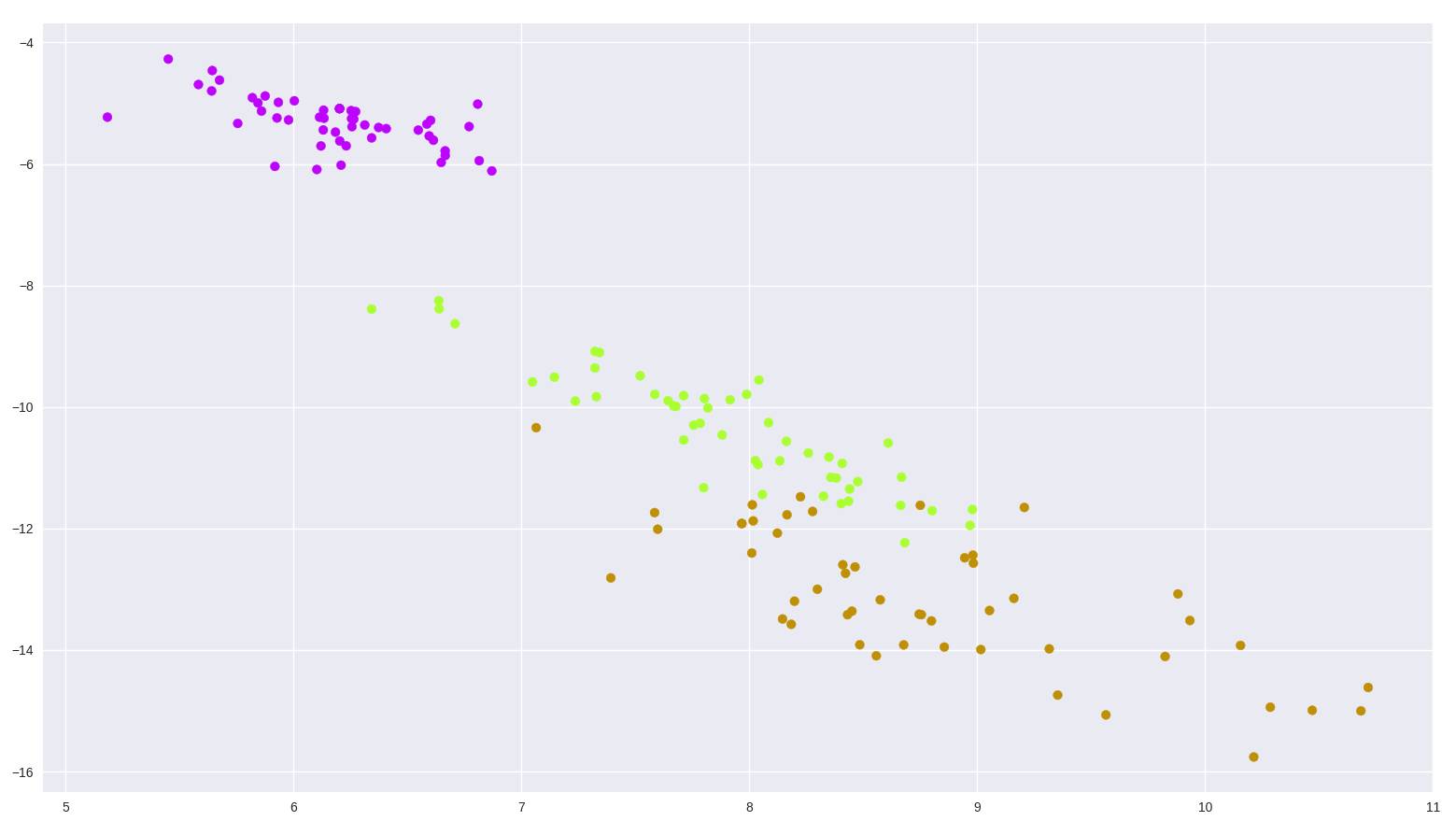
圖 7:這個簡單自編碼器在鳶尾花數據集上的輸出
我們可以繼續調整批大小、epoch 數和不同的優化器,甚至無需改變架構我們就能得到不同的結果。
注意這里我給超參數隨便選擇了一些值,在真實場景中,我們需要通過交叉驗證或測試數據來檢驗我們的結果,并借此找到最優的設置。
結語
這樣的文章往往會通過某種形式的對比表格收尾,看看它們長處短處之類的。但那正好不是我想做的事情。
我的目標是深入到這些方法內部,讓讀者可以自己明白它們各自的優勢和劣勢。
我希望你喜歡這篇文章,并且能從中獲益。現在回到文章開始處的問題,你知道它們的答案了嗎?
原文鏈接:https://reinforce.io/blog/introduction-to-tensorforce/
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4603.html
摘要:作者微信號微信公眾號簡書地址上個星期,我花了一些時間參加了的機器學習金融比賽。每個星期,都會重置比賽,然后公布一個新的數據集。然后經過一周短短的比賽,來評出第一名和第二名。 作者:chen_h微信號 & QQ:862251340微信公眾號:coderpai簡書地址:http://www.jianshu.com/p/af7e... showImg(https://segmentfaul...
摘要:主頁暫時下線社區暫時下線知識庫自媒體平臺微博知乎簡書博客園我們不是的官方組織機構團體,只是技術棧以及的愛好者合作侵權,請聯系請抄送一份到預處理離散化等值分箱等量分箱獨熱標準化最小最大標準化歸一化特征選擇信息增益信息增益率模型驗證評價指 【主頁】 apachecn.org 【Github】@ApacheCN 暫時下線: 社區 暫時下線: cwiki 知識庫 自媒體平臺 微博...
摘要:主頁暫時下線社區暫時下線知識庫自媒體平臺微博知乎簡書博客園我們不是的官方組織機構團體,只是技術棧以及的愛好者合作侵權,請聯系請抄送一份到預處理離散化等值分箱等量分箱獨熱標準化最小最大標準化歸一化特征選擇信息增益信息增益率模型驗證評價指 【主頁】 apachecn.org 【Github】@ApacheCN 暫時下線: 社區 暫時下線: cwiki 知識庫 自媒體平臺 微博...

閱讀 1585·2021-09-30 09:47
閱讀 3581·2021-09-22 15:05
閱讀 2829·2021-08-30 09:44
閱讀 3617·2019-08-30 15:55
閱讀 1365·2019-08-30 13:08
閱讀 1322·2019-08-29 16:40
閱讀 544·2019-08-29 12:45
閱讀 1379·2019-08-29 11:25




