資訊專欄INFORMATION COLUMN

摘要:未來向何處去做領袖不容易,要不斷地指明方向。又譬如想識別在這些黑白圖像中,是否包含從到的手寫體數字,那么深度學習的傳統做法是,輸出一個維向量,,其中每個元素的取值范圍是,表示出現相應數字的概率。老爺子的論文中,輸出的是十個維向量,其中。
CNN 未來向何處去?
做領袖不容易,要不斷地指明方向。所謂正確的方向,不僅前途要輝煌,而且道路要盡可能順暢。
Geoffrey Hinton 是深度學習領域的領袖。2011 年,正當 CNN 模型爆發性地取得一個又一個靚麗成就時,老爺子卻開始冷靜地剖析 CNN 模型存在的致命弱點,指出前進的方向。
老爺子上周剛剛發表了一篇論文,題為 Dynamic Routing Between Capsules。一看這題目就預料得到,這篇論文一定會引起廣泛關注。因為這題目里,涉及到兩個概念,Capsule 和 Dynamic Routing。而這兩個概念,正是老爺子主張的 CNN 前進的方向。
老爺子的論文,讀起來略感晦澀,其實道理并不難懂。筆者嘗試用淺顯的語言,把論文梳理一下,或許有助于理解。
Capsule:實體的視覺數學表征
深度學習,其實就是一系列的張量變換。
從圖像、視頻、音頻、文字等等原始數據中,通過一系列張量變換,篩選出特征數據,以便完成識別、分解、翻譯等等任務。
譬如原始數據是 28 x 28 的黑白圖像,每個黑白像素可以用 8 個 bits 來表達,那么這張黑白圖像就可以用 28 * 28 * 8 的張量來表達,張量中每個元素的取值是布爾值,0 或者 1。
又譬如想識別在這些黑白圖像中,是否包含從 0 到 9 的手寫體數字,那么深度學習的傳統做法是,輸出一個 10 維向量,( x_{0}, x_{1}, ... x_{9} ),其中每個元素 x_{i} 的取值范圍是 [0, 1.0],表示出現相應數字的概率。
例如,輸出的向量是 ( 0.2, 0.1, 0.7, 0.9, 0.2, ..., 0.1 ),那么意味著,圖像中出現數字 2 的概率是 70%,出現數字 3 的概率是 90% 等等。
Capsule 的創新,在于改變了輸出,不是輸出一個向量,而是輸出 10 個向量。每個向量分別表達某個數字的若干個屬性。
老爺子的論文中,輸出的是十個 16 維向量,( x_{i, j} ) 其中 i = 0 ... 15, j = 0, ... 9。也就是說,老爺子認為每個手寫體數字包含 16 個屬性,包含幾個圓圈,幾個彎勾,幾個折角,幾根橫豎,彎勾折角的大小,筆劃的粗細,整個字體的傾斜度,等等。
Capsule 的想法,不難理解。但是仔細想想,存在以下幾個問題。
傳統的圖像識別的解決方案,是把識別問題轉化為分類問題。這個方法已經足以解決識別問題。實體的視覺數學表征 capsule 的意義是什么?
如何證明 16 維的 capsule 向量,能夠作為手寫體數字的視覺數學表征?為什么不是 32 維或者更多?
Capsule 向量中的元素 x_{i},與實體的屬性之間的關聯,是機器自動學習出來的。但是是否可以被人為預先強制指定?
低級 capsule 與高級 capsule 之間的關聯關系,是機器自動學習出來的,還是可以被人為預先強制指定?
Capsule 的意義
老爺子試圖用 capsule 向量,囊括實體的所有重要屬性。如果某個實體的所有屬性,都在圖像中出現,那么可以確認,這個圖像一定包含這個實體。所以他把這個向量,稱為實體膠囊 capsule。
一個手寫體數字,不管字體是否端正,筆劃是粗還是細,圓圈和彎勾是大還是小,都用同一個膠囊 capsule 來表征。
一個輪胎,不管拍攝的角度如何,不管是正圓還是橢圓,不管輪轂是什么式樣,也都可以用同一個膠囊 capsule 來表征。
說得抽象一點,capsule 就是實體的視覺的數學表征。
想起了詞向量,word vector,詞向量是文字詞匯的數學表征。
能否把 capsule 和 word vector 統一起來,不管實體的表達是圖像還是文字,都可以用同一個數學向量來表征?
論文中沒有明說,但是老爺子多半心懷這個想法。
說得更直白一點,capsule 作為視覺數學表征,很可能是為了把視覺,聽覺、閱讀的原本相互獨立的數學向量,統一起來,完成多模態機器學習的終極目標。
重構圖像:驗證 Capsule 的猜想?
假設 capsule 包含了某個實體的所有重要視覺屬性,那么理論上來說,應該可以從 capsule 還原包含該實體的圖像。
為了證明這個猜測,論文使用了一個神經網絡,把 capsule 向量作為輸入,重構手寫體數字圖像并輸出。
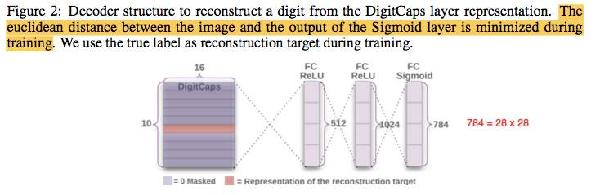
實驗結果證明,capsule 確實能夠重構出正確的手寫體數字圖像。
而且更讓人驚奇的是,這些 capsules 中的某些屬性,也就是 ( x_{i, j} ), i = 0...15,j = 0...9,其中的幾個 x{i},具有明確的物理意義,譬如手寫體字體大小寬窄傾斜度,以及字體中彎勾圓弧等局部特征的大小位置等等。
為什么每個手寫體數字只包含 16 個屬性,而不是 32 個或者更多屬性?
16 個屬性,已經足以正確地重構手寫體數字圖像。32 個或者更多屬性,無非是表達方式更細膩而已,這個問題不太重要。

Dynamic Routing:從原始數據中尋找實體屬性的存在證據
Capsule 向量的元素 x_{i},與實體的屬性之間的關聯,是人為確定的,還是機器自動對應的?
根據論文的描述,關聯關系是機器自動對應的,所以在 capsule 向量 ( x_{i} ), i = 0...15 中,某些 x_{i} 的物理意義比較明確,其它 x_{i} 的物理意義卻可能難以解釋。
假如人為強制指定 capsule 中各個 x_{i} ?的物理意義,換句話說,人為強制指定 capsule 向量元素 x_{i} 與實體屬性之間的關聯關系,是否會有助于提高識別精度,降低訓練數據的數量?
回答這個問題之前,需要先了解的 capsule 向量中 ( x_{i} ) 的取值,是怎么來的。
前文說到,深度學習其實就是一系列的張量變換。通過一系列張量變換,從圖像、視頻、音頻、文字等等原始數據中,篩選出特征數據,以便完成識別、分解、翻譯等等任務。
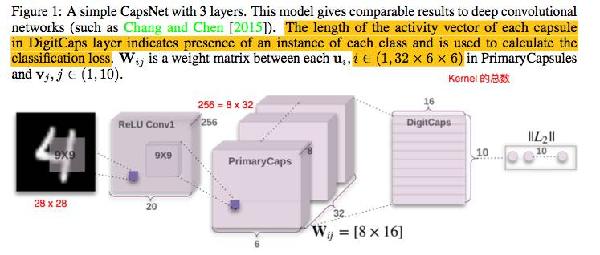
論文使用了兩層卷積神經網絡,對原始黑白照片,也就是 28 * 28 * 8 的原始張量,用兩層卷積,完成一系列張量變換,轉變成新的張量 ( x_{attr, lon, lat, channel} ) ,attr ?= 0 ... 7, lon = 0 ... 5, lat = 0 ... 5, channel = 0 ... 31。
這個新張量中的 ( x_{attr} ) 是初級 capsule,表達原始圖像中值得注意的特征。其中 attr 代表初級 capsule 的屬性,維度為 8。
新張量中的 ( x_{lon, lat} ) ?表示 capsule ( x_{attr} ) 在原始圖像中的方位。經過張量變換后,28 * 28 的原始圖像,被縮略為 6 * 6 個方位。( x_{channel} ) 是頻道,類似于多機位拍攝同一個場景,全面表達 capsule 在原始圖像中的視覺特點,總共有 32 個頻道。
在新張量中,總共有 lon * lat * channel = 6 * 6 * 32 = 1152 個初級 capsule ( x_{attr} ) 。換句話說,經過一系列張量變換,從原始圖像中,篩選出了 1152 個值得注意的圖像特征。
高級 capsule 是前文說的十個手寫體數字的 16 維屬性向量,即 ( x_{attr, class} ), attr = 0 ... 15, class = 0 ... 9。
想識別原始圖像中,是否包含手寫體數字 3,也就是 class = 2,只需要把 1152 個初級 capsules,逐一與高級 capsule 向量 x_{*, 2} ?做比對。
如何做比對呢?先做一次線性變換,把 8 維的初級 capsule,變換成 16 維的初級 capsule。然后計算 16 維的初級 capsule 與 16 維的高級 capsule 之間的余弦距離,也就是兩個向量之間的點乘。
從每個高級 capsule 出發,在低級 capsules 中尋找它存在的證據,這個過程,就是 Dynamic Routing。
如果某一個高級 capsule 中每一個屬性,都能在 1152 個初級 capsules 中,找到 “對應的” 一個或多個 capsules,那么就證實了高級 capsule 中的這個屬性,確實在圖像中存在。
如果某一個高級 capsule 中的全部 16 個屬性,都能在 1152 個初級 capsules 中,找到存在的證據,那么就認定這個高級 capsule 在原始圖像中存在。
如果有多個高級 capsules,都能在 1152 個初級 capsules 中,找到各自存在的證據,那么就認定在原始圖像中存在多個高級 capsules。

Capsule 與先驗知識
回到前文的問題,假如人為強制指定 capsule 中各個 x_{i} ?的物理意義,換句話說,人為強制指定 capsule 向量元素 x_{i} 與實體屬性之間的關聯關系,是否會有助于提高識別精度,降低訓練數據的數量?
假如人為強制指定 capsule 中某個 x_{i} 用于表達圖像中是否存在圓圈,那么需要改變訓練數據。
現在的訓練數據,由輸入和輸出一對數據構成。輸入數據是原始照片,輸出數據是標簽,說明原始照片中含有哪些數字。
如果要人為指定手寫體數字的 capsule 中的元素 x_{i},那么需要改變訓練數據。譬如輸入是原始照片,輸出的標簽,是說明這張照片中是否有圓圈。
改變訓練數據有什么意義?一個可能的意義是 transfer learning。
一張輪胎的照片中,也包含圓圈。用現在的方法,輪胎的照片無助于手寫體數字的識別,但是用 ?transfer learning,可以用輪胎的照片,來訓練機器識別圓圈,然后把識別圓圈的算法模塊,融合到手寫體數字的識別系統中。
至于用這種方法,是否能夠提高識別精度,降低訓練數據的數量,需要做實驗來驗證。
Parse Tree:實體特征的多層次分解,及與先驗知識的融合
在原始圖像中,識別手寫體數字,這個實驗比較簡單。
假如設計一個難度更高的實驗,在原始圖像中,識別自行車。自行車由兩個輪胎,兩個腳踏板,一個龍頭和骨架等等構件組成。
要完成這個實驗,需要先識別原始圖像中,是否存在輪胎、腳踏板、龍頭和骨架等等構件。然后識別這些構件之間的位置關系。
老爺子提議,用 Parse Tree 來分解整個識別任務,從原始圖像,到圖像特征,到不同構件,到自行車的識別。
Parse Tree 的生成,當然可以完全靠機器,從大量訓練數據中自動學習。而且是一氣呵成地完成各個環節,從原始圖像,到圖像特征,到不同構件,到最終的自行車識別。
但是如果融合先驗知識,人為預先指定 Parse Tree 的結構,或許有助于把識別自行車的問題,拆解為若干子問題,分別識別輪胎、腳踏板、龍頭和骨架等等構件,然后再把子模塊整合成為自行車的識別系統。
當然,把大問題拆解為若干子問題,需要針對各個子問題,準備各自的訓練數據。
這樣做是否有利于提高識別精度,降低訓練數據的數量,也需要做實驗來驗證。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4656.html
摘要:在普通的全連接網絡或中,每層神經元的信號只能向上一層傳播,樣本的處理在各個時刻獨立,因此又被成為前向神經網絡。不難想象隨著深度學習熱度的延續,更靈活的組合方式更多的網絡結構將被發展出來。 從廣義上來說,NN(或是更美的DNN)確實可以認為包含了CNN、RNN這些具體的變種形式。在實際應用中,所謂的深度神經網絡DNN,往往融合了多種已知的結構,包括卷積層或是LSTM單元。這里的DNN特指全連接...
摘要:傳統神經網絡的問題到目前為止,圖像分類問題上較先進的方法是。我們把卡戴珊姐姐旋轉出現這個問題的原因,用行話來說是旋轉的程度超出了較大池化所帶來的旋轉不變性的限度。 Capsule Networks,或者說CapsNet,這個名字你應該已經聽過好幾次了。這是深度學習之父的Geoffrey Hinton近幾年一直在探索的領域,被視為突破性的新概念。最近,關于Capsule的論文終于公布了。一篇即...
摘要:近日,該論文的一作終于在上公開了該論文中的代碼。該項目上線天便獲得了個,并被了次。 當前的深度學習理論是由Geoffrey Hinton大神在2007年確立起來的,但是如今他卻認為,CNN的特征提取層與次抽樣層交叉存取,將相同類型的相鄰特征檢測器的輸出匯集到一起是大有問題的。去年9月,在多倫多接受媒體采訪時,Hinton大神斷然宣稱要放棄反向傳播,讓整個人工智能從頭再造。10月,人們關注已久...
摘要:本文試圖揭開讓人迷惘的云霧,領悟背后的原理和魅力,品嘗這一頓盛宴。當然,激活函數本身很簡單,比如一個激活的全連接層,用寫起來就是可是,如果我想用的反函數來激活呢也就是說,你得給我解出,然后再用它來做激活函數。 由深度學習先驅 Hinton 開源的 Capsule 論文 Dynamic Routing Between Capsules,無疑是去年深度學習界最熱點的消息之一。得益于各種媒體的各種...
摘要:論文鏈接會上其他科學家認為反向傳播在人工智能的未來仍然起到關鍵作用。既然要從頭再來,的下一步是什么值得一提的是,與他的谷歌同事和共同完成的論文已被大會接收。 三十多年前,深度學習著名學者 Geoffrey Hinton 參與完成了論文《Experiments on Learning by Back Propagation》,提出了反向傳播這一深刻影響人工智能領域的方法。今天的他又一次呼吁研究...

閱讀 1006·2019-08-30 15:55
閱讀 3446·2019-08-30 13:10
閱讀 1274·2019-08-29 18:45
閱讀 2352·2019-08-29 16:25
閱讀 2113·2019-08-29 15:13
閱讀 2427·2019-08-29 11:29
閱讀 559·2019-08-26 17:34
閱讀 1491·2019-08-26 13:57






