文章專欄ARTICLE COLUMN


Llama3 中文聊天項目綜合資源庫,該文檔集合了與Lama3 模型相關的各種中文資料,包括微調(diào)版本、有趣的權重、訓練、推理、評測和部署的教程視頻與文檔。1. 多版本支持與創(chuàng)新:該倉庫提供了多個版本的Lama3 模型,包括基于不同技術和偏好的微調(diào)版本,如直接中文...

NVIDIA和MIT的研究人員推出了一種新的視覺語言模型(VLM)預訓練框架,名為VILA。這個框架旨在通過有效的嵌入對齊和動態(tài)神經(jīng)網(wǎng)絡架構,改進語言模型的視覺和文本的學習能力。VILA通過在大規(guī)模數(shù)據(jù)集如Coy0-700m上進行預訓練,采用基于LLaVA模型的不同預訓練策略...
OpenAI最近發(fā)布了新一代AI推理模型——o1,標志著其在復雜推理任務上的重大進展。該模型包括兩個版本:o1-preview和o1-mini,分別針對復雜推理和快速處理任務。模型需要長時間思考,非GPT家族,調(diào)用方式需要修改調(diào)用成本3倍起步調(diào)用次數(shù)嚴格限制,每周幾十次...

v0是一個專為網(wǎng)頁開發(fā)設計的智能助手,它通過對話形式提供服務。你可以與v0進行互動,無論是代碼調(diào)試、解答編程問題還是生成代碼片段,v0都能在前端開發(fā)領域提供專業(yè)的幫助。它精通TypeScript、React、Next.js、Vercel等前端技術,能夠為你提供深入的技術指導...
AI視頻生成賽道風起云涌,國內(nèi)外新穎的文生、圖生視頻產(chǎn)品層出不窮。在各大廠商的內(nèi)卷之下,當下的視頻生成模型各方面已經(jīng)接近以假亂真的效果。例如,OpenAI 的 Sora 和國內(nèi)的 Vidu、可靈等模型,通過利用 Diffusion Transformer 的擴展特性,不僅能...
在人工智能的浪潮中,個性化體驗已成為創(chuàng)新的關鍵。而隨著各種各樣的模型迭代更新,如何為AI應用提供持久、智能的記憶系統(tǒng)逐漸成為了一個關鍵挑戰(zhàn)。最近開源的Mem0項目為我們提供了一個強大的解決方案。它為大型語言模型(LLM)提供了一個智能、自我優(yōu)化的記憶...
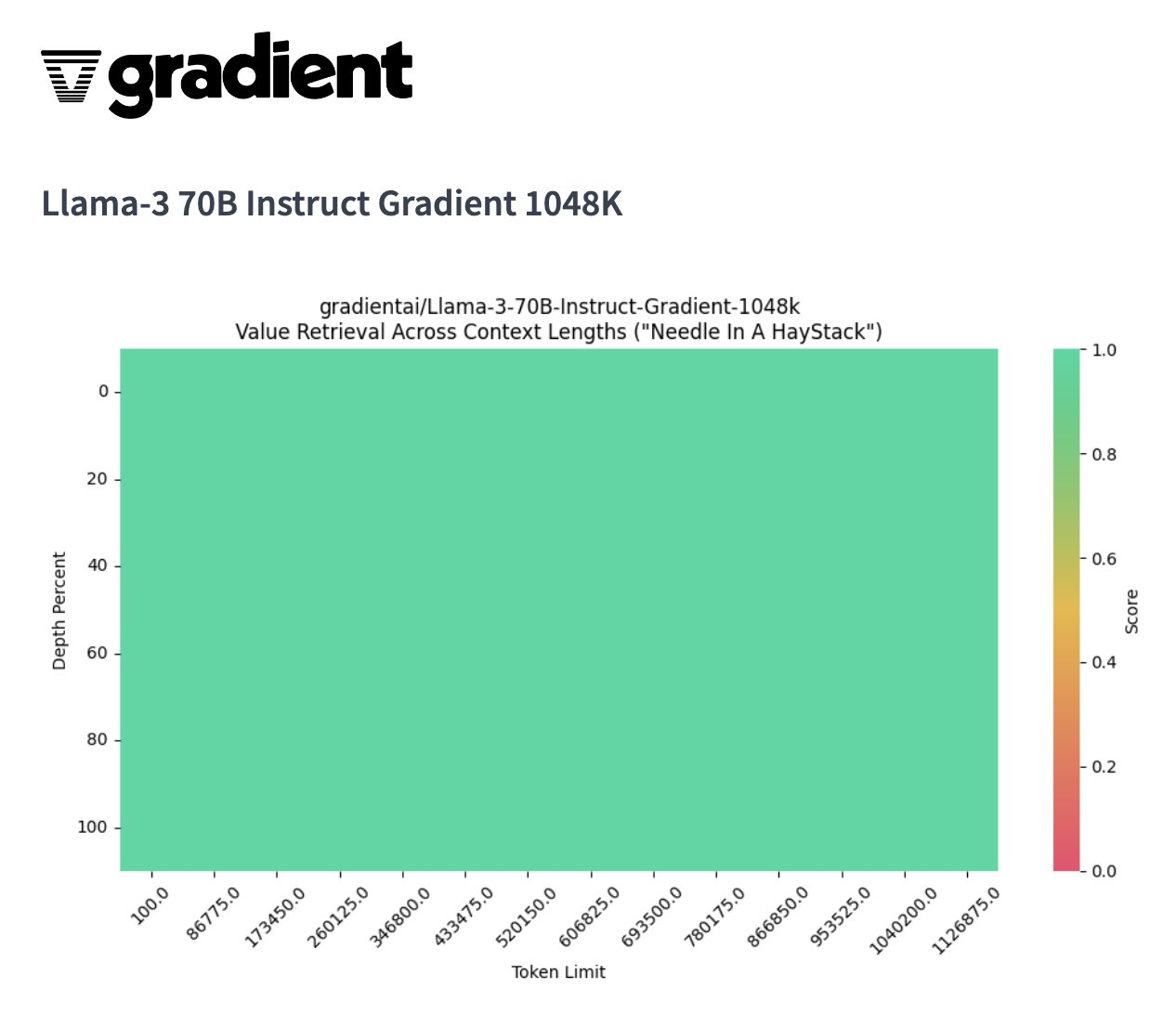
Gradient Al最近將Llama-3 8B和7B模型通過漸進式訓練方法不斷將Llama-3模型的上下文長度從8k-路擴展到262k、524k今天Gradient Al成功宣布成功地將Llama-3 系列模型的上下文長度擴展到超過1 M...并且1M上下文窗口 70B 模型在 NIAH(大海撈針)上取得了完美分數(shù)。...
隨著大型模型技術的持續(xù)發(fā)展,視頻生成技術正逐步走向成熟。以Sora、Gen-3等閉源視頻生成模型為代表的技術,正在重新定義行業(yè)的未來格局。而近幾個月,國產(chǎn)的AI視頻生成模型也是層出不窮,像是快手可靈、字節(jié)即夢、智譜清影、Vidu、PixVerse V2 等。就在近日,...
簡介近年來,人工智能(AI)技術的進步極大地改變了人類與機器的互動方式,特別是在語音處理領域。阿里巴巴通義實驗室最近開源了一個名為FunAudioLLM的語音大模型項目,旨在促進人類與大型語言模型(LLMs)之間的自然語音交互。FunAudioLLM包含兩個核心模型:...
繼前幾日推出完開源大模型Llama 3.1后,就在剛剛,Meta在 SIGGRAPH 上重磅宣布 Segment Anything Model 2 (SAM 2) 來了。在其前身的基礎上,SAM 2 的誕生代表了領域內(nèi)的一次重大進步 —— 為靜態(tài)圖像和動態(tài)視頻內(nèi)容提供實時、可提示的對象分割,將圖像和視頻...
近日,當下炙手可熱的快手宣布開源旗下明星產(chǎn)品可靈中一項重要技術項目LivePortrait。,該框架能夠準確、實時地將驅動視頻的表情、姿態(tài)遷移到靜態(tài)或動態(tài)人像視頻上,生成極具表現(xiàn)力的視頻結果。如下動圖所示:LivePortrait的主要功能包括從單一圖像生成生動動...
前幾個月OpenAI大名鼎鼎的Sora 一經(jīng)發(fā)布,似乎象征著視頻領域已經(jīng)進入了生成式 AI 時代。不過直到今天,我們?nèi)匀粵]有用上OpenAI 的官方視頻生成工具,等不及的人們已經(jīng)開始尋找其他的方法。其中不乏一些國內(nèi)的廠商如快手的可靈等等。而在近日,一款全新的開源...
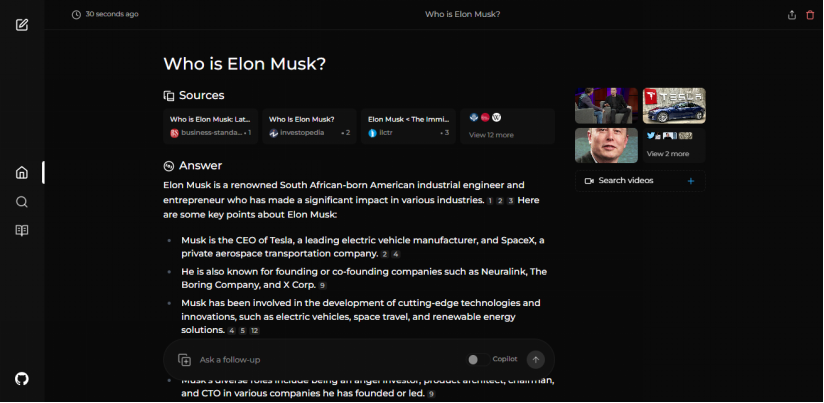
Perplexica是一個開源的人工智能搜索工具,也可以說是一款人工智能搜索引擎,它深入互聯(lián)網(wǎng)以找到答案。受Perplexity AI啟發(fā),它是一個開源選擇,不僅可以搜索網(wǎng)絡,還能理解您的問題。它使用先進的機器學習算法,如相似性搜索和嵌入式技術,以精細化結果,并...
項目介紹Code2prompt 是一個命令行工具,能將你的代碼庫轉化為單一的大型語言模型(LLM)提示,結合源碼樹結構,模板定制,以及令牌計數(shù)。它旨在簡化與高級上下文窗口模型如GPT或Claude的交互,助你在重寫代碼、查找bug、編寫文檔和實現(xiàn)新功能等方面提升效率...
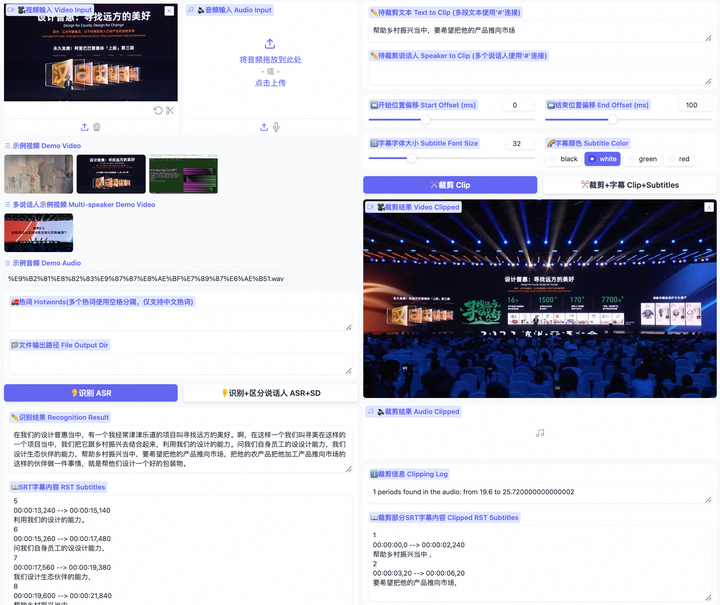
項目簡介Funclip 是阿里巴巴通義實驗室開源的一款視頻剪輯工具,專門用于精準、便捷的視頻切片。它能夠自動識別視頻中的中文語音并允許用戶根據(jù)語音內(nèi)容來裁剪視頻。該工具使用了阿里巴巴語音識別模型FunASR Paraformer-Large確保了剪輯的精準性。你可以根據(jù)...
GOT-OCR2.0是一款新一代的光學字符識別(OCR)技術,標志著人工智能在文本識別領域的重大進步。作為一款開源模型,GOT-OCR2.0不僅支持傳統(tǒng)的文本和文檔識別,還能夠處理樂譜、圖表以及復雜的數(shù)學公式,為用戶提供了更加全面和高效的解決方案。產(chǎn)品功能及特點...
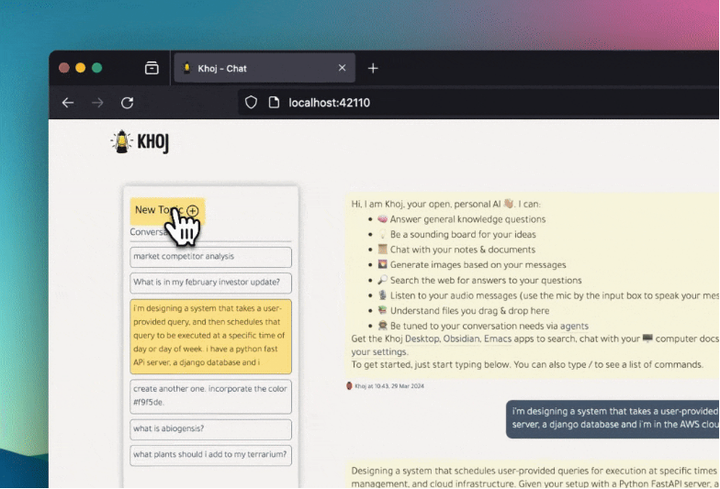
項目簡介Khoj是一個開源的、個人化的AI助手,旨在充當你的第二大腦。它能夠幫助你回答任何問題,不論這些問題是在線上的還是在你自己的筆記中。Khoi 支持使用在線AI模型(例如 GPT-4)或私有、本地的語言模型(例如 Llama3)。你可以選擇自托管 Khoj,也可以使用...
小模型,成為本周的AI爆點。與動輒上千億參數(shù)的大模型相比,小模型的優(yōu)勢是顯而易見的:它們不僅計算成本更低,訓練和部署也更為便捷,可以滿足計算資源受限、數(shù)據(jù)安全級別較高的各類場景。因此,在大筆投入大模型訓練之余,像 OpenAI、谷歌等科技巨頭也在積極...
在視頻中插入手繪動畫!傳統(tǒng)上這是一項非常困難的任務,但 VideoDoodles 讓它成為可能。VideoDoodles是Adobe公司聯(lián)合多所大學推出的AI視頻編輯框架。支持用戶在視頻中輕松插入手繪動畫,實現(xiàn)與視頻內(nèi)容的無縫融合。通過預處理視頻幀,系統(tǒng)提供平面畫布,用戶...
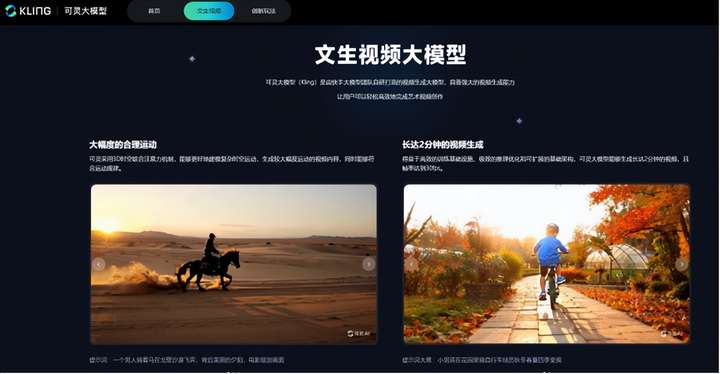
自從OpenAI公布了Sora后,震爆了全世界,但由于其技術的不成熟和應用的局限性,未能大規(guī)模推廣,只有零零散散的幾個公布出來的一些視頻。昨日,快手成立13周年,可靈(Kling)大模型發(fā)布,體驗后不由得感嘆,炸裂,太震撼了,快手可靈,除了那個沒發(fā)布的Sora...

6月20日周四,OpenAI競爭對手Anthropic發(fā)布了公司迄今為止性能最強大的AI模型Claude 3.5 Sonnet。在覆蓋閱讀、編程、數(shù)學和視覺等領域的多項性能測試中,Claude 3.5 Sonnet的性能略勝一籌,吊打GPT-4o等一眾競爭對手的AI模型,且優(yōu)于自家旗艦模型Claude 3 Opu...

在人工智能領域,自然語言處理技術一直備受關注。就在昨日,今年備受關注的國內(nèi)AI公司北京智譜AI發(fā)布了第四代 GLM 系列開源模型:GLM-4-9B。這是一個集成了先進自然語言處理技術的創(chuàng)新平臺,它憑借清華大學KEG實驗室提出的GLM模型結構,為智能體功能的發(fā)展帶來...

項目簡介AniTalker是一個開源項目,它利用靜態(tài)照片和音頻文件來創(chuàng)造動態(tài)的面部說話視頻。AniTalker采用了一種通用的運動表示方法。這種創(chuàng)新的表示方法有效地捕捉了廣泛的面部動態(tài),包括微妙的表情和頭部動作。AniTalker通過兩種自監(jiān)督學習策略增強了運動描述...
檢查內(nèi)容是否用了ChatGPT,準確率高達99.9%!OpenAI又左右互搏上了,給AI生成的文本打水印,高達99.9%準確率抓「AI槍手」作弊代寫。其能夠精準識別出論文或研究報告是否由ChatGPT撰寫,甚至能追溯其使用的具體時間點。它能專門用來檢測是否用ChatGPT水了論文...
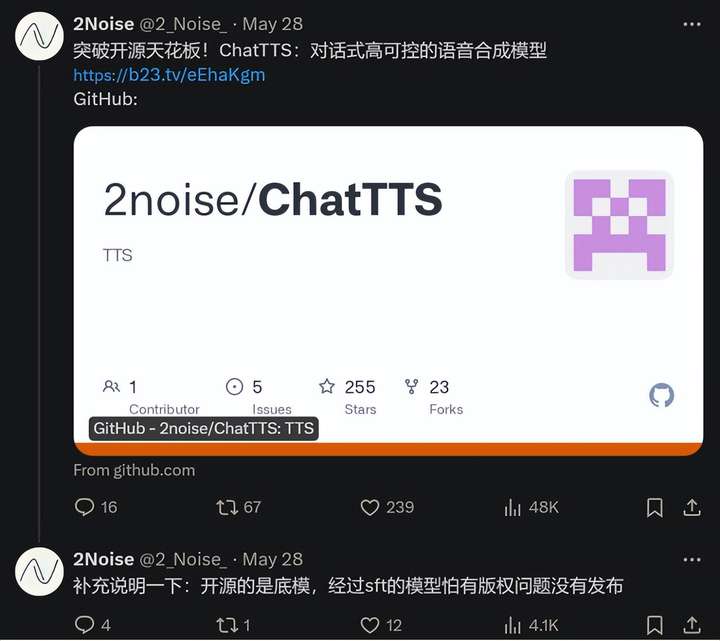
過去我們讓AI說話,它給出的總是不咸不淡的機器合成聲音,毫無波瀾的死板音調(diào)讓人聽得昏昏欲睡。但由于chatTTS的到來,一切都將會變得不一樣。作為一款強大的對話式文本轉語音模型,它完美解決了用戶對于生動對話的需求。如此功能不可小覷,可以稱得上在業(yè)界...

