資訊專欄INFORMATION COLUMN

大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,而是非常香!直接上圖!
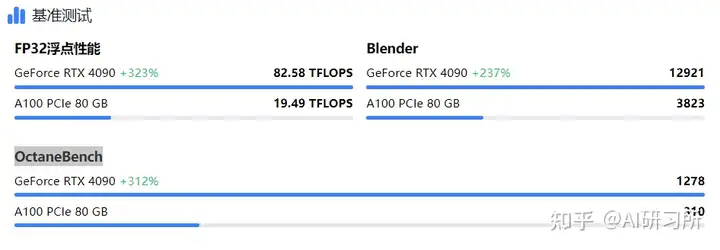
通過Tensor FP32(TF32)的數據來看,H100性能是全方面碾壓4090,但是頂不住H100價格太貴,推理上使用性價比極低。但在和A100的PK中,4090與A100除了在顯存和通信上有差異,算力差異與顯存相比并不大,而4090是A100價格的1/10,因此如果用在模型推理場景下,4090性價比完勝!(尾部附參數源文件)

從推理性能層面看,4090在推理方面的性能是比A100更強的,沒開混合精度的情況下,A100的FP32向量只有19.5T遠低于4090的83T。同時在渲染場景Blender和OctaneBench基準測試中,4090性能也遙遙領先。從推理性能層面看,4090在推理方面的性能是比A100更強的,沒開混合精度的情況下,A100的FP32向量只有19.5T遠低于4090的83T。同時在渲染場景Blender和OctaneBench基準測試中,4090性能也遙遙領先。
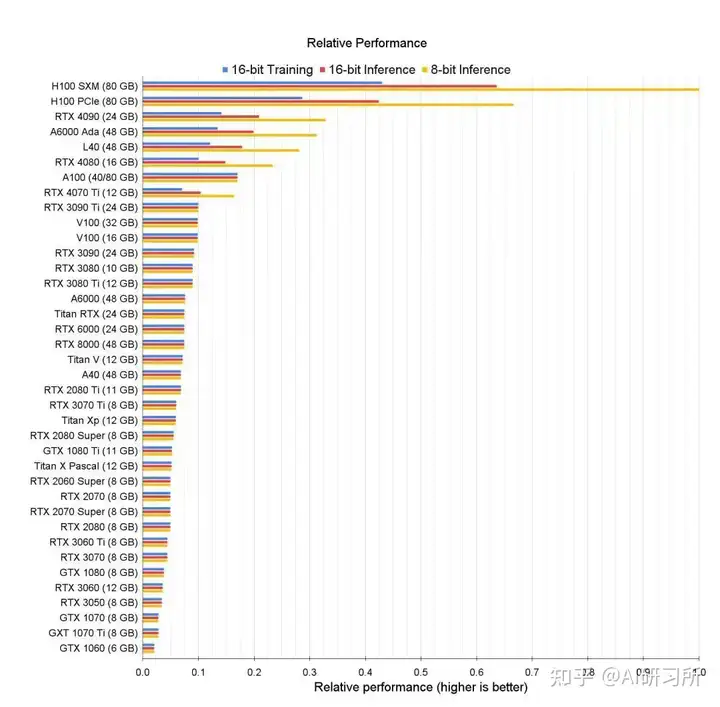
推理性能排行:
首先我們需要計算一下推理需要多少計算量,根據公式:2 * 輸出 token 數量 * 參數數量 flops
總的存儲容量很好算,推理的時候最主要占內存的就是參數、KV Cache 和當前層的中間結果。當 batch size = 8 時,中間結果所需的大小是 batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB,相對來說是很小的。
70B 模型的參數是 140 GB,不管 A100/H100 還是 4090 都是單卡放不下的。那么 2 張 H100 夠嗎?看起來 160 GB 是夠了,但是剩下的 20 GB 如果用來放 KV Cache,要么把 batch size 壓縮一半,要么把 token 最大長度壓縮一半,聽起來是不太明智。因此,至少需要 3 張 H100。
對于 4090,140 GB 參數 + 40 GB KV Cache = 180 GB,每張卡 24 GB,8 張卡剛好可以放下。要知道H100的價格是4090的20倍左右。這個時候4090就非常香了!
首先,軟件用的是StableDiffusion,模型使用的是SDXL,出圖尺寸是888x1280,迭代步數50。A100出一張圖花費11.5秒,而4090則略快,只需11.4秒,兩者差異較小,但A100表現稍顯頹勢。
在繪制八張圖的情況下,A100耗時87秒,而4090僅用80秒,4090表現出色,領先A100約8%。
總體來說,雖然RTX 4090可能不適合超大規模的AI訓練任務,它的強大推理能力使其在大模型的推理應用中顯得更為合適。盡管在數據中心和專業級AI訓練任務中,Tesla A100和H100提供了更高的專業性和適應性,但考慮到成本和可接受的性能輸出,RTX 4090為研究人員和技術企業提供了一種高效且經濟的解決方案。對于那些尋求在預算內實現高效AI推理的用戶,RTX 4090提供了一個既實用又前瞻的選擇。
附高性能NVIDIA RTX 40 系列云服務器購買:
http://specialneedsforspecialkids.com/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
附H100、A100、4090官網參數文檔:
4090: https://images.nvidia.com/aem-dam/Solutions/geforce/ada/nvidia-ada-gpu-architecture.pdf
H100:https://resources.nvidia.com/en
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/131081.html
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了排名。我們可以看到,H100 GPU的8位性能與16位性能的優化與其他GPU存在巨大差距。針對大模型訓練來說,H100和A100有絕對的優勢首先,從架構角度來看,A100采用了NVIDIA的Ampere架構,而H100則是基于Hopper架構。Ampere架構以其高效的圖形處理性能和多任務處理能力而...

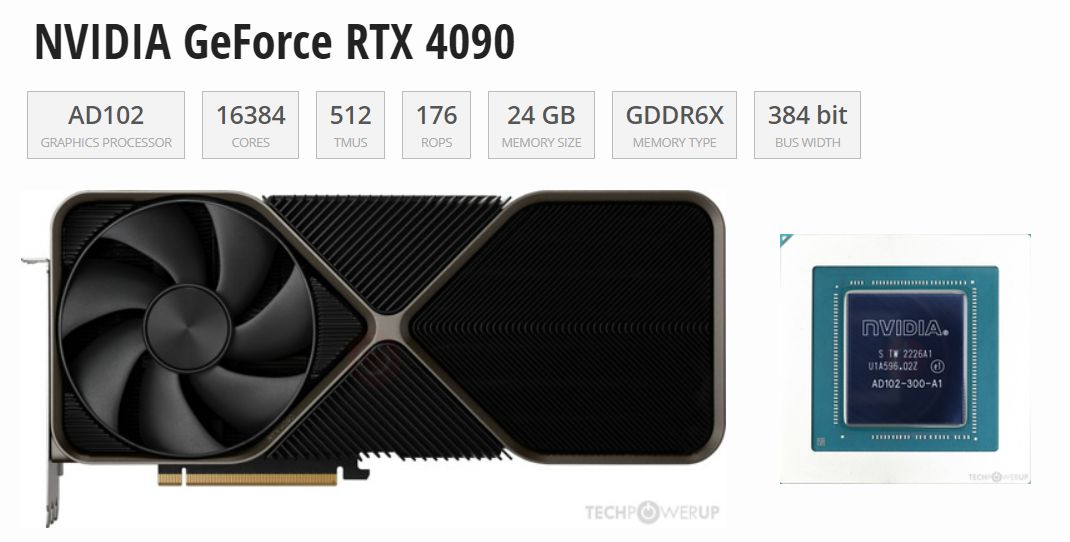
2023年12月28日 英偉達宣布正式發布GeForce RTX 4090D,對比于一年前上市的4090芯片,兩者的區別與差異在哪?而在當前比較火熱的大模型推理、AI繪畫場景方面 兩者各自的表現又如何呢?規格與參數信息對比現在先來看看GeForce RTX 4090D到底與之前的GeForce RTX 4090顯卡有何區別。(左為4090 右為4090D)從簡單的規格來看,GeForce RTX ...

隨著大型模型技術的持續發展,視頻生成技術正逐步走向成熟。以Sora、Gen-3等閉源視頻生成模型為代表的技術,正在重新定義行業的未來格局。而近幾個月,國產的AI視頻生成模型也是層出不窮,像是快手可靈、字節即夢、智譜清影、Vidu、PixVerse V2 等。就在近日,智譜AI秉承以先進技術,服務全球開發者的理念,宣布將與清影同源的視頻生成模型——CogVideoX開源,以期讓每一位開發者、每一家企...

Llama3 中文聊天項目綜合資源庫,該文檔集合了與Lama3 模型相關的各種中文資料,包括微調版本、有趣的權重、訓練、推理、評測和部署的教程視頻與文檔。1. 多版本支持與創新:該倉庫提供了多個版本的Lama3 模型,包括基于不同技術和偏好的微調版本,如直接中文SFT版、Instruct偏好強化學習版、趣味版等。此外,還有Phi3模型中文資料倉庫的鏈接,和性能超越了8b版本的Llama3。2. 部...
在深度學習和人工智能應用,選最合的硬件對于模型訓練和推任務關。在大模型訓練,英偉達4090并不是最的選。訓練任務通常要更大的顯存容量、更的內存帶寬的計算能。這些求,英偉達的高性能顯卡系列,比如A100和H100,更適合處理大數據集和復雜模型。,在推理任務,英偉達4090可能H100系列處理器。推理顯存和帶寬求相對較,而4090的計算能更的和效率。這在推理任務,4090顯卡處理更復雜的模型,在性價比...

閱讀 77·2024-12-10 11:51
閱讀 275·2024-11-07 17:59
閱讀 276·2024-09-27 16:59
閱讀 447·2024-09-23 10:37
閱讀 483·2024-09-14 16:58
閱讀 318·2024-09-14 16:58
閱讀 476·2024-08-29 18:47
閱讀 752·2024-08-16 14:40

