資訊專欄INFORMATION COLUMN

文章版權歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/131130.html
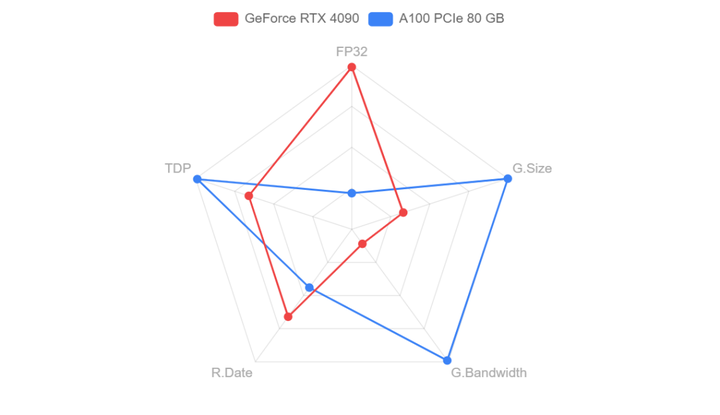
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,而是非常香!直接上圖!通過Tensor FP32(TF32)的數(shù)據(jù)來看,H100性能是全方面碾壓4090,但是頂不住H100價格太貴,推理上使用性價比極低。但在和A100的PK中,4090與A100除了在顯存和通信上有差異,算力差異與顯存相比并不大,而4090是A100價格的1/10,因此如果用在模...
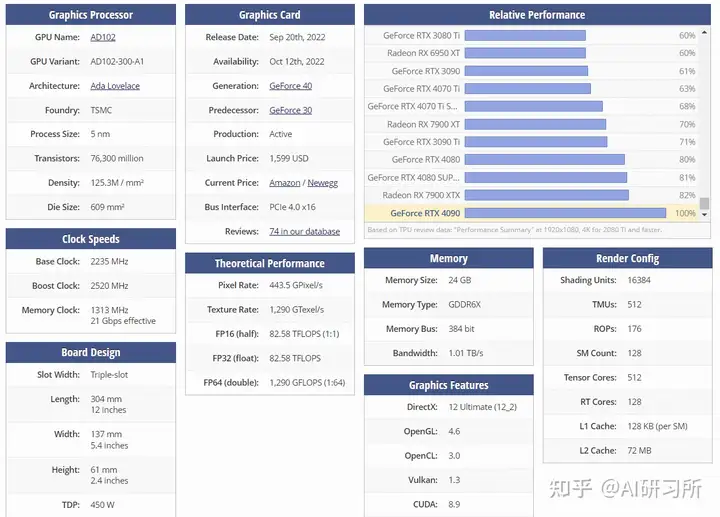
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據(jù)訓練、推理能力由高到低做了排名。我們可以看到,H100 GPU的8位性能與16位性能的優(yōu)化與其他GPU存在巨大差距。針對大模型訓練來說,H100和A100有絕對的優(yōu)勢首先,從架構角度來看,A100采用了NVIDIA的Ampere架構,而H100則是基于Hopper架構。Ampere架構以其高效的圖形處理性能和多任務處理能力而...
自2022年年末英偉達發(fā)布4090芯片以來,這款產(chǎn)品憑借著其優(yōu)異的性能迅速在科技界占據(jù)了一席之地。現(xiàn)如今,不論是在游戲體驗、內(nèi)容創(chuàng)作能力方面還是模型精度提升方面,4090都是一個繞不過去的名字。而A100作為早些發(fā)布的產(chǎn)品,其優(yōu)異的能力和適配性已經(jīng)為它打下了良好的口碑。RTX 4090芯片和A100芯片雖然都是高性能的GPU,但它們在設計理念、目標市場和性能特點上有著明顯的區(qū)別,而本篇文章將簡單概...

2023年12月28日 英偉達宣布正式發(fā)布GeForce RTX 4090D,對比于一年前上市的4090芯片,兩者的區(qū)別與差異在哪?而在當前比較火熱的大模型推理、AI繪畫場景方面 兩者各自的表現(xiàn)又如何呢?規(guī)格與參數(shù)信息對比現(xiàn)在先來看看GeForce RTX 4090D到底與之前的GeForce RTX 4090顯卡有何區(qū)別。(左為4090 右為4090D)從簡單的規(guī)格來看,GeForce RTX ...
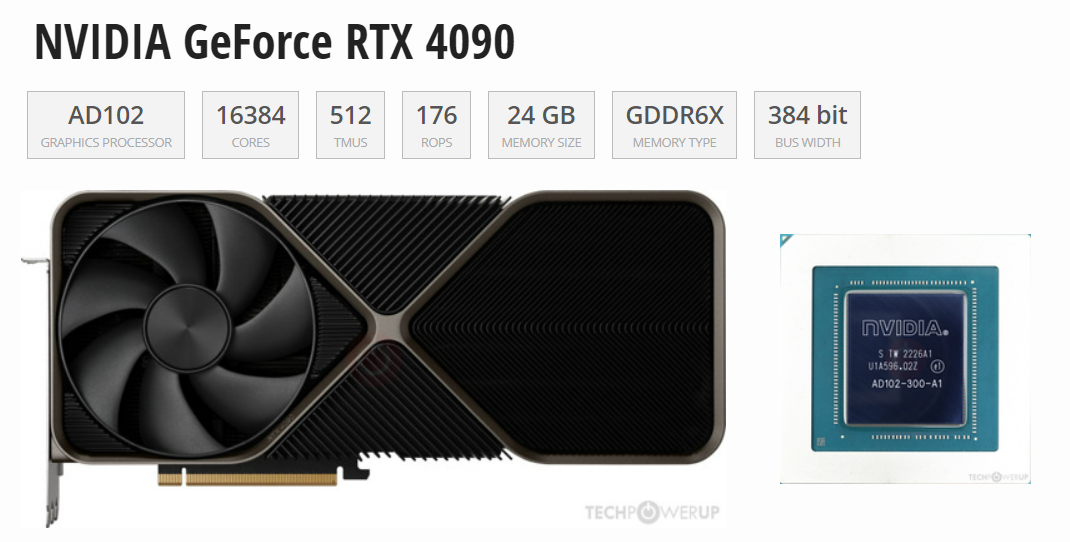
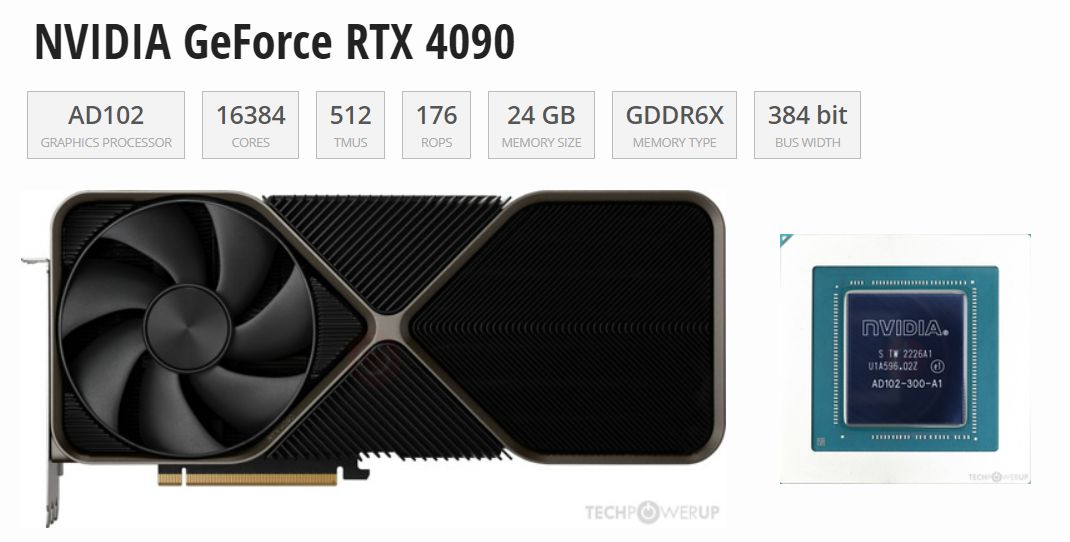
隨著人工智能的持續(xù)火熱,好的加速卡成為了各行業(yè)的重點關注對象,因為在AI機器學習中,通常涉及大量矩陣運算、向量運算和其他數(shù)值計算。這些計算可以通過并行處理大幅提高效率,而高端顯卡的存在,使得在處理要求擁有大量算力的任務時,變得不那么難了。這篇文章大家伙聊聊RTX4090這款顯卡,4090論性能不如H100,論價格不如3090,那為什么能成為眾多企業(yè)、高校科研人員眼中的香餑餑?1. 強大的性能RTX...

閱讀 157·2024-12-10 11:51
閱讀 303·2024-11-07 17:59
閱讀 329·2024-09-27 16:59
閱讀 466·2024-09-23 10:37
閱讀 540·2024-09-14 16:58
閱讀 335·2024-09-14 16:58
閱讀 531·2024-08-29 18:47
閱讀 812·2024-08-16 14:40


