資訊專欄INFORMATION COLUMN

隨著人工智能的持續火熱,好的加速卡成為了各行業的重點關注對象,因為在AI機器學習中,通常涉及大量矩陣運算、向量運算和其他數值計算。這些計算可以通過并行處理大幅提高效率,而高端顯卡的存在,使得在處理要求擁有大量算力的任務時,變得不那么難了。
這篇文章大家伙聊聊RTX4090這款顯卡,4090論性能不如H100,論價格不如3090,那為什么能成為眾多企業、高校科研人員眼中的香餑餑?
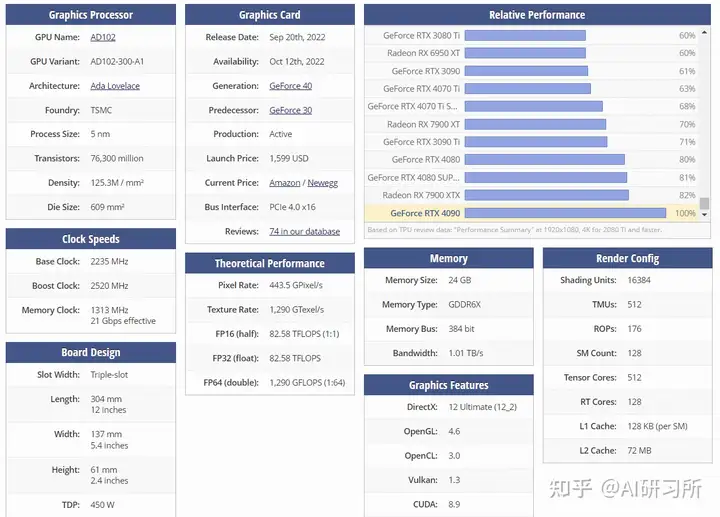
RTX 4090是基于NVIDIA的Ada Lovelace架構,這一架構在圖形處理能力和并行計算能力上都有顯著的提升。特別是其Tensor Cores(張量核心),專為AI計算優化設計,可以極大加速深度學習模型的訓練和推理過程。相較于前代產品,RTX 4090的AI處理速度更快,FP16算力達到了330TFlops,FP32算力達到了83FPlops,能更高效地處理復雜的算法和大規模的數據集。
| 4090 | 參數 |
|---|---|
| 顯卡芯片 | GeForce RTX 4090 |
| CUDA核心 | 16384個 |
| 顯存容量 | 24GB GDDR6X |
| 顯存位寬 | 384bit |
| 核心頻率 | 2230-2520MHz |
| 顯存頻率 | 21000MHz(21Gbps) |
| 內存帶寬 | 高達 1TB/s |
| 通信帶寬 | 64 GB/s |
| FP16算力 | 330 Tflops |
| FP32算力 | 83 Tflops |
Ada Lovelace架構提供了更高的效率和更強的計算密度。RTX 4090利用這一架構,帶來了改進的Ray Tracing Cores(光線追蹤核心)和第三代Tensor Cores,這使得它在執行機器學習任務時,能夠提供更快的響應速度和更高的精度。此外,這種顯卡還引入了多項新技術,如DLSS 3(深度學習超級采樣),進一步提升了AI渲染能力。
RTX 4090配備了24GB的GDDR6X內存,這為處理大型神經網絡模型和復雜的數據集提供了充足的空間。高達1TB的內存帶寬保證了數據在處理過程中的快速傳輸,這對于需要實時分析和決策的AI應用尤為重要。
NVIDIA長期以來都在AI領域提供強有力的軟件支持。RTX 4090完全兼容CUDA、TensorFlow、PyTorch等主流AI開發框架,使得研究人員和開發者可以無縫地遷移和升級他們的應用程序。此外,NVIDIA還提供了全面的開發者工具和庫,如CUDA-X AI庫,這些都是為了幫助開發者更有效地利用硬件性能。
其在AI領域中展現出的性能效益比使其成為了性價比極高的選擇。對于需要進行大模型推理的企業來說,H100和A100這兩種卡雖然性能很好,但是價格過于昂貴,而4090則兼具性能和性價比。
GeForce RTX 4090憑借其強大的性能、大內存容量及較高的性價比,適用于深度學習,渲染、科學計算等場景。雖然性價比出色,但如果普通高校或初創企業想要解決GPU的算力問題,建議還是選擇租賃的方式,因為花錢買的話,不僅貴,還會涉及到管理和維護的問題,但租就不存在了。
附高性能NVIDIA RTX 40 系列云服務器購買:
http://specialneedsforspecialkids.com/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/131083.html
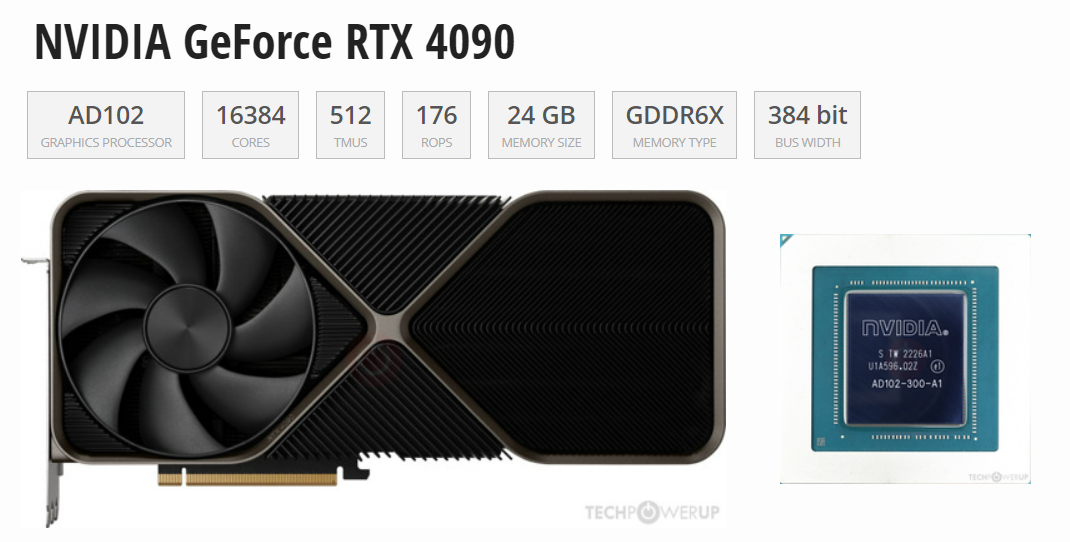
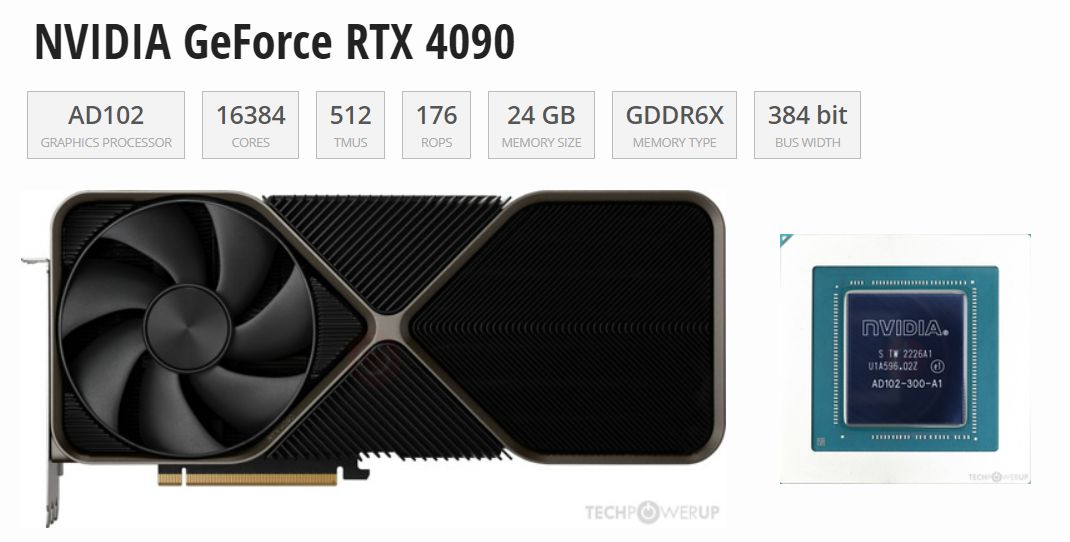
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,而是非常香!直接上圖!通過Tensor FP32(TF32)的數據來看,H100性能是全方面碾壓4090,但是頂不住H100價格太貴,推理上使用性價比極低。但在和A100的PK中,4090與A100除了在顯存和通信上有差異,算力差異與顯存相比并不大,而4090是A100價格的1/10,因此如果用在模...

2023年12月28日 英偉達宣布正式發布GeForce RTX 4090D,對比于一年前上市的4090芯片,兩者的區別與差異在哪?而在當前比較火熱的大模型推理、AI繪畫場景方面 兩者各自的表現又如何呢?規格與參數信息對比現在先來看看GeForce RTX 4090D到底與之前的GeForce RTX 4090顯卡有何區別。(左為4090 右為4090D)從簡單的規格來看,GeForce RTX ...

在當今的圖形處理領域,NVIDIA一直以其卓越的性能和創新的技術引領市場潮流。作為其最新的旗艦級顯卡,GeForce RTX 4090一經發布便吸引了無數玩家的目光。作為最大的賣點,游戲性能以及功效無疑是這張顯卡作為佼佼者的地方;于此同時,其關于視頻編輯、3D建模、深度學習等專業領域的應用以及廣泛的適用性和高效性能同時也是不可忽視的。視頻編輯與后期制作RTX 4090不僅僅是一塊游戲顯卡,它在視頻...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了排名。我們可以看到,H100 GPU的8位性能與16位性能的優化與其他GPU存在巨大差距。針對大模型訓練來說,H100和A100有絕對的優勢首先,從架構角度來看,A100采用了NVIDIA的Ampere架構,而H100則是基于Hopper架構。Ampere架構以其高效的圖形處理性能和多任務處理能力而...
小模型,成為本周的AI爆點。與動輒上千億參數的大模型相比,小模型的優勢是顯而易見的:它們不僅計算成本更低,訓練和部署也更為便捷,可以滿足計算資源受限、數據安全級別較高的各類場景。因此,在大筆投入大模型訓練之余,像 OpenAI、谷歌等科技巨頭也在積極訓練好用的小模型。先是HuggingFace推出了小模型SmoLLM;OpenAI直接殺入小模型戰場,發布了GPT-4o mini。GPT-4o mi...

閱讀 77·2024-12-10 11:51
閱讀 275·2024-11-07 17:59
閱讀 276·2024-09-27 16:59
閱讀 447·2024-09-23 10:37
閱讀 483·2024-09-14 16:58
閱讀 318·2024-09-14 16:58
閱讀 476·2024-08-29 18:47
閱讀 752·2024-08-16 14:40

