資訊專欄INFORMATION COLUMN

摘要:卷積神經網絡除了為機器人和自動駕駛汽車的視覺助力之外,還可以成功識別人臉,物體和交通標志。卷積卷積神經網絡的名字來源于卷積運算。在卷積神經網絡中,卷積的主要目的是從輸入圖像中提取特征。
什么是卷積神經網絡,它為何重要?
卷積神經網絡(也稱作 ConvNets 或 CNN)是神經網絡的一種,它在圖像識別和分類等領域已被證明非常有效。 卷積神經網絡除了為機器人和自動駕駛汽車的視覺助力之外,還可以成功識別人臉,物體和交通標志。

圖1
如圖1所示,卷積神經網絡能夠識別圖片的場景并且提供相關標題(“足球運動員正在踢足球”),圖2則是利用卷積神經網絡識別日常物品、人類和動物的例子。最近,卷積神經網絡在一些自然語言處理任務(如語句分類)中也發揮了很大作用。

圖2
因此,卷積神經網絡是當今大多數機器學習實踐者的重要工具。但是,理解卷積神經網絡并開始嘗試運用著實是一個痛苦的過程。本文的主要目的是了解卷積神經網絡如何處理圖像。
對于剛接觸神經網絡的人,我建議大家先閱讀這篇關于多層感知機的簡短教程 ,了解其工作原理之后再繼續閱讀本文。多層感知機即本文中的“完全連接層”。
LeNet 框架(20世紀90年代)
LeNet 是最早推動深度學習領域發展的卷積神經網絡之一。這項由 Yann LeCun 完成的開創性工作自1988年以來多次成功迭代之后被命名為 LeNet5。當時 LeNet 框架主要用于字符識別任務,例如閱讀郵政編碼,數字等。
接下來,我們將直觀地了解 LeNet 框架如何學習識別圖像。 近年來有人提出了幾種基于 LeNet 改進的新框架,但是它們的基本思路與 LeNet 并無差別,如果您清楚地理解了 LeNet,那么對這些新的框架理解起來就相對容易很多。
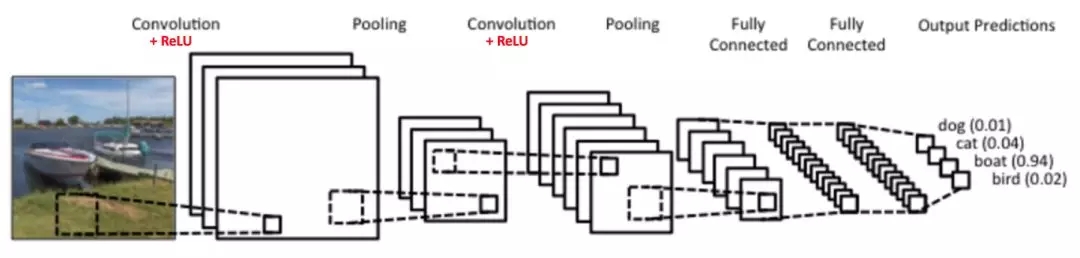
圖3: 一個簡單的卷積神經網絡
圖3中的卷積神經網絡在結構上與原始的 LeNet 類似,并將輸入圖像分為四類:狗,貓,船或鳥(原始的 LeNet 主要用于字符識別任務)。 從上圖可以看出,接收船只圖像作為輸入時,神經網絡在四個類別中正確地給船只分配了較高概率值(0.94)。輸出層中所有概率的總和應該是1(之后會做解釋)。
圖3 的卷積神經網絡中有四個主要操作:
卷積
非線性變換(ReLU)
池化或子采樣
分類(完全連接層)
這些操作是所有卷積神經網絡的基本組成部分,因此了解它們的工作原理是理解卷積神經網絡的重要步驟。下面我們將嘗試直觀地理解每個操作。
一張圖片就是一個由像素值組成的矩陣
實質上,每張圖片都可以表示為由像素值組成的矩陣。
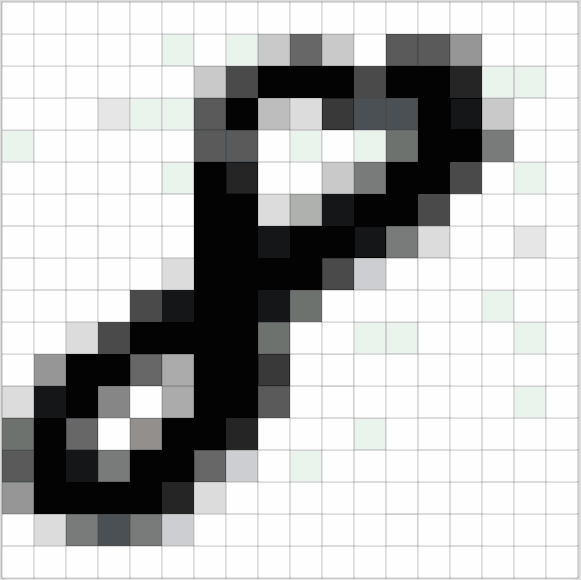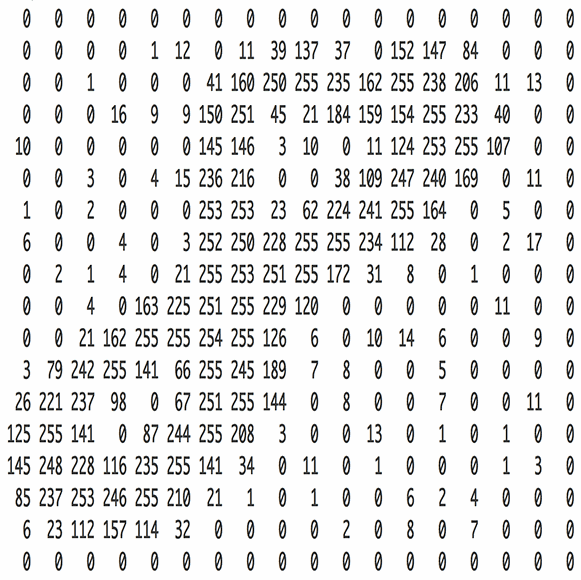
圖4: 每張圖片就是一個像素矩陣
通道(channel)是一個傳統術語,指圖像的一個特定成分。標準數碼相機拍攝的照片具有三個通道——紅,綠和藍——你可以將它們想象為三個堆疊在一起的二維矩陣(每種顏色一個),每個矩陣的像素值都在0到255之間。
而灰度圖像只有一個通道。 鑒于本文的科普目的,我們只考慮灰度圖像,即一個代表圖像的二維矩陣。矩陣中每個像素值的范圍在0到255之間——0表示黑色,255表示白色。
卷積
卷積神經網絡的名字來源于“卷積”運算。在卷積神經網絡中,卷積的主要目的是從輸入圖像中提取特征。通過使用輸入數據中的小方塊來學習圖像特征,卷積保留了像素間的空間關系。我們在這里不會介紹卷積的數學推導,但會嘗試理解它是如何處理圖像的。
正如前文所說,每個圖像可以被看做像素值矩陣。考慮一個像素值僅為0和1的5 × 5大小的圖像(注意,對于灰度圖像,像素值范圍從0到255,下面的綠色矩陣是像素值僅為0和1的特殊情況):

另外,考慮另一個 3×3 矩陣,如下圖所示:
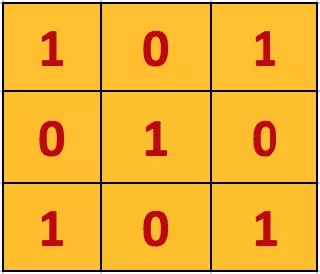
上述5 x 5圖像和3 x 3矩陣的卷積計算過程如圖5中的動畫所示:
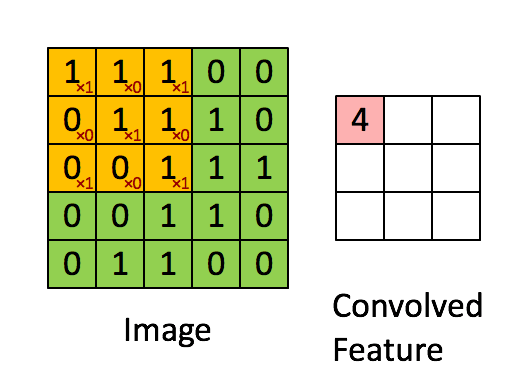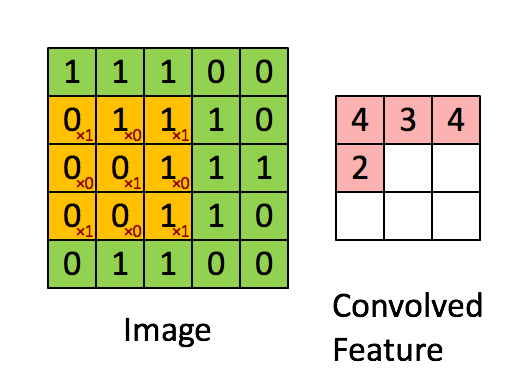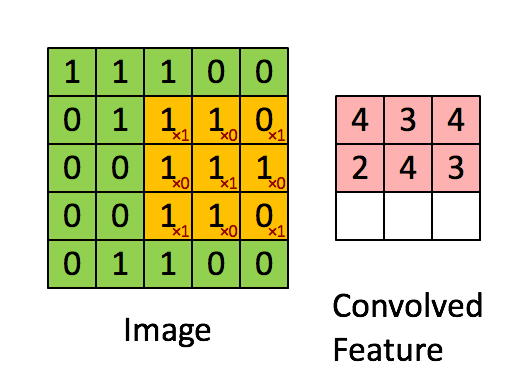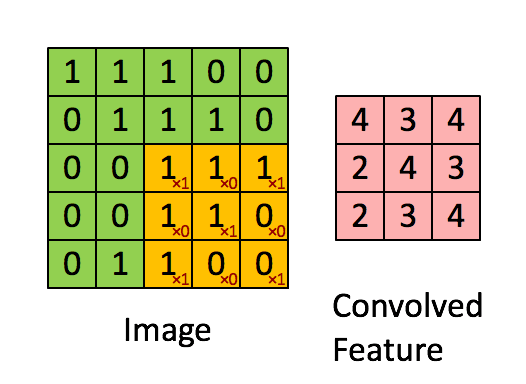
圖5:卷積操作。輸出矩陣稱作“卷積特征”或“特征映射”
我們來花點時間理解一下上述計算是如何完成的。將橙色矩陣在原始圖像(綠色)上以每次1個像素的速率(也稱為“步幅”)移動,對于每個位置,計算兩個矩陣相對元素的乘積并相加,輸出一個整數并作為最終輸出矩陣(粉色)的一個元素。注意,3 × 3矩陣每個步幅僅能“看到”輸入圖像的一部分。
在卷積神經網路的術語中,這個3 × 3矩陣被稱為“過濾器”或“核”或“特征探測器”,通過在圖像上移動過濾器并計算點積得到的矩陣被稱為“卷積特征”或“激活映射”或“特征映射”。重要的是要注意,過濾器的作用就是原始輸入圖像的特征檢測器。
從上面的動畫可以明顯看出,對于同一張輸入圖像,不同的過濾器矩陣將會產生不同的特征映射。例如,考慮如下輸入圖像:

在下表中,我們可以看到上圖在不同過濾器下卷積的效果。如圖所示,只需在卷積運算前改變過濾器矩陣的數值就可以執行邊緣檢測,銳化和模糊等不同操作 [8] —— 這意味著不同的過濾器可以檢測圖像的不同特征,例如邊緣, 曲線等。更多此類示例可在 這里 8.2.4節中找到。

另一個理解卷積操作的好方法可以參考下面圖6中的動畫:

圖6: 卷積操作
一個過濾器(紅色邊框)在輸入圖像上移動(卷積操作)以生成特征映射。在同一張圖像上,另一個過濾器(綠色邊框)的卷積生成了不同的特征圖,如圖所示。需要注意到,卷積操作捕獲原始圖像中的局部依賴關系很重要。還要注意這兩個不同的過濾器如何從同一張原始圖像得到不同的特征圖。請記住,以上圖像和兩個過濾器只是數值矩陣。
實際上,卷積神經網絡在訓練過程中會自己學習這些過濾器的值(盡管在訓練過程之前我們仍需要指定諸如過濾器數目、大小,網絡框架等參數)。我們擁有的過濾器數目越多,提取的圖像特征就越多,我們的網絡在識別新圖像時效果就會越好。
特征映射(卷積特征)的大小由我們在執行卷積步驟之前需要決定的三個參數[4]控制:
深度:深度對應于我們用于卷積運算的過濾器數量。在圖7所示的網絡中,我們使用三個不同的過濾器對初始的船圖像進行卷積,從而生成三個不同的特征圖。可以將這三個特征地圖視為堆疊的二維矩陣,因此,特征映射的“深度”為3。

圖7
步幅:步幅是我們在輸入矩陣上移動一次過濾器矩陣的像素數量。當步幅為1時,我們一次將過濾器移動1個像素。當步幅為2時,過濾器每次移動2個像素。步幅越大,生成的特征映射越小。
零填充:有時,將輸入矩陣邊界用零來填充會很方便,這樣我們可以將過濾器應用于輸入圖像矩陣的邊界元素。零填充一個很好的特性是它允許我們控制特征映射的大小。添加零填充也稱為寬卷積,而不使用零填充是為窄卷積。 這在[14]中有清楚的解釋。
非線性部分介紹(ReLU)
如上文圖3所示,每次卷積之后,都進行了另一項稱為 ReLU 的操作。ReLU 全稱為修正線性單元(Rectified Linear Units),是一種非線性操作。 其輸出如下圖所示:

圖8: ReLU 函數
ReLU 是一個針對元素的操作(應用于每個像素),并將特征映射中的所有負像素值替換為零。ReLU 的目的是在卷積神經網絡中引入非線性因素,因為在實際生活中我們想要用神經網絡學習的數據大多數都是非線性的(卷積是一個線性運算 —— 按元素進行矩陣乘法和加法,所以我們希望通過引入 ReLU 這樣的非線性函數來解決非線性問題)。
從圖9可以很清楚地理解 ReLU 操作。它展示了將 ReLU 作用于圖6中某個特征映射得到的結果。這里的輸出特征映射也被稱為“修正”特征映射。

圖9: ReLU 操作
其他非線性函數諸如 tanh 或 sigmoid 也可以用來代替 ReLU,但是在大多數情況下,ReLU 的表現更好。
池化
空間池化(也稱為子采樣或下采樣)可降低每個特征映射的維度,并保留最重要的信息。空間池化有幾種不同的方式:較大值,平均值,求和等。
在較大池化的情況下,我們定義一個空間鄰域(例如,一個2 × 2窗口),并取修正特征映射在該窗口內較大的元素。當然我們也可以取該窗口內所有元素的平均值(平均池化)或所有元素的總和。在實際運用中,較大池化的表現更好。
圖10展示了通過2 × 2窗口在修正特征映射(卷積+ ReLU 操作后得到)上應用較大池化操作的示例。
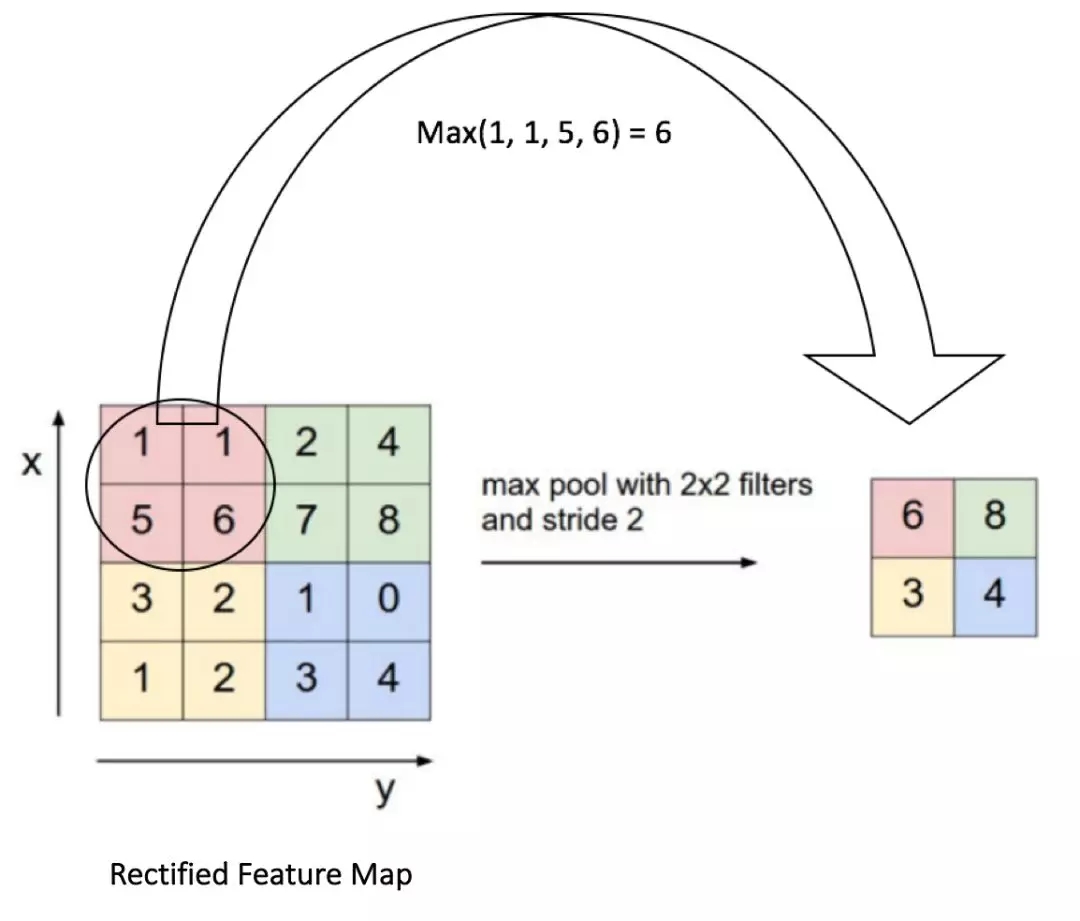
圖10: 較大池化
我們將2 x 2窗口移動2個單元格(也稱為“步幅”),并取每個區域中的較大值。如圖10所示,這樣就降低了特征映射的維度。
在圖11所示的網絡中,池化操作分別應用于每個特征映射(因此,我們從三個輸入映射中得到了三個輸出映射)。

圖11: 在修正特征映射上應用池化
圖12展示了我們對圖9中經過 ReLU 操作之后得到的修正特征映射應用池化之后的效果。

圖12: 池化
池化的作用是逐步減少輸入的空間大小[4]。具體來說有以下四點:
使輸入(特征維度)更小,更易于管理
減少網絡中的參數和運算次數,因此可以控制過擬合 [4]
使網絡對輸入圖像微小的變換、失真和平移更加穩健(輸入圖片小幅度的失真不會改池化的輸出結果 —— 因為我們取了鄰域的較大值/平均值)。
可以得到尺度幾乎不變的圖像(確切的術語是“等變”)。這是非常有用的,這樣無論圖片中的物體位于何處,我們都可以檢測到,(詳情參閱[18]和[19])。
至此…

圖13
目前為止,我們已經了解了卷積,ReLU 和池化的工作原理。這些是卷積神經網絡的基本組成部分,理解這一點很重要。如圖13所示,我們有兩個由卷積,ReLU 和 Pooling 組成的中間層 —— 第二個卷積層使用六個過濾器對第一層的輸出執行卷積,生成六個特征映射。然后將 ReLU 分別應用于這六個特征映射。接著,我們對六個修正特征映射分別執行較大池化操作。
這兩個中間層的作用都是從圖像中提取有用的特征,在網絡中引入非線性因素,同時對特征降維并使其在尺度和平移上等變[18]。
第二個池化層的輸出即完全連接層的輸入,我們將在下一節討論。
完全連接層
完全連接層是一個傳統的多層感知器,它在輸出層使用 softmax 激活函數(也可以使用其他分類器,比如 SVM,但在本文只用到了 softmax)。“完全連接”這個術語意味著前一層中的每個神經元都連接到下一層的每個神經元。 如果對多層感知器不甚了解,我建議您閱讀這篇文章。
卷積層和池化層的輸出代表了輸入圖像的高級特征。完全連接層的目的是利用這些基于訓練數據集得到的特征,將輸入圖像分為不同的類。例如,我們要執行的圖像分類任務有四個可能的輸出,如圖14所示(請注意,圖14沒有展示出完全連接層中節點之間的連接)
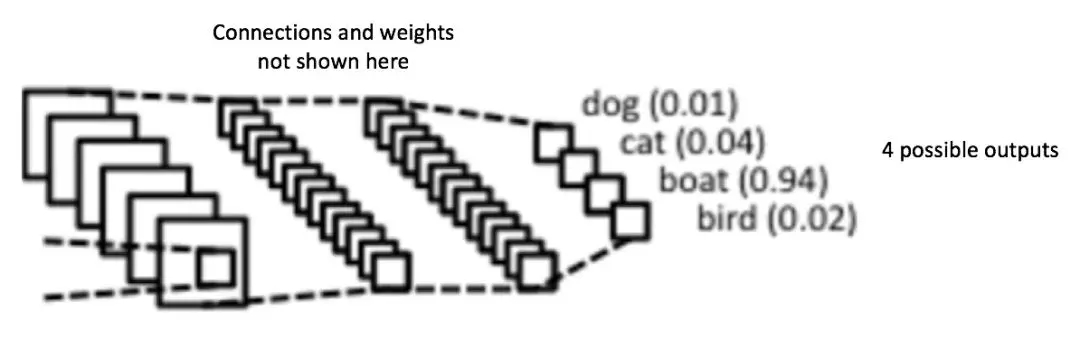
圖14: 完全連接層——每個節點都與相鄰層的其他節點連接
除分類之外,添加完全連接層也是一個(通常來說)比較簡單的學習這些特征非線性組合的方式。卷積層和池化層得到的大部分特征對分類的效果可能也不錯,但這些特征的組合可能會更好[11]。
完全連接層的輸出概率之和為1。這是因為我們在完全連接層的輸出層使用了 softmax 激活函數。Softmax 函數取任意實數向量作為輸入,并將其壓縮到數值在0到1之間,總和為1的向量。
正式開始——使用反向傳播進行訓練
如上所述,卷積+池化層用來從輸入圖像提取特征,完全連接層用來做分類器。
注意,在圖15中,由于輸入圖像是船,對于船類目標概率為1,其他三個類為0
輸入圖像 = 船
目標向量 = [0, 0, 1, 0]
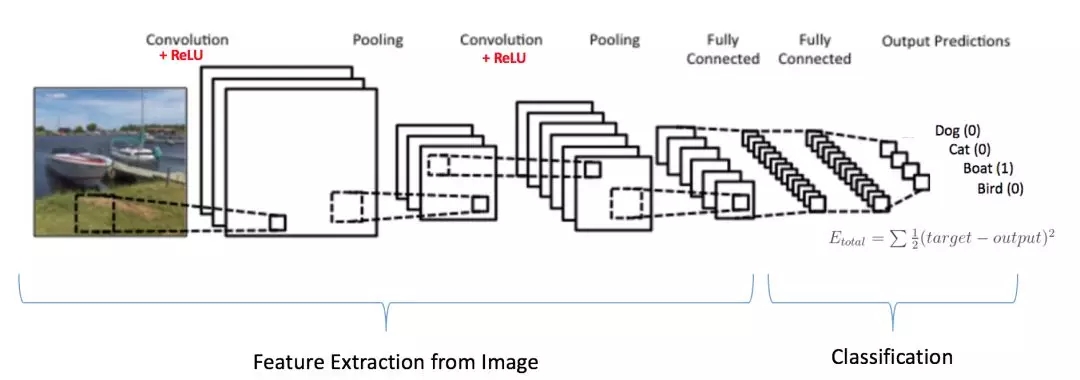
圖15:訓練卷積神經網絡
卷積網絡的整體訓練過程概括如下:
步驟1:用隨機值初始化所有過濾器和參數/權重
步驟2:神經網絡將訓練圖像作為輸入,經過前向傳播步驟(卷積,ReLU 和池化操作以在完全連接層中的前向傳播),得到每個類的輸出概率。
假設上面船只圖像的輸出概率是 [0.2,0.4,0.1,0.3]
由于權重是隨機分配給第一個訓練樣本,因此輸出概率也是隨機的。
步驟3:計算輸出層的總誤差(對所有4個類進行求和)
總誤差=∑ ?(目標概率 – 輸出概率)2
步驟4:使用反向傳播計算網絡中所有權重的誤差梯度,并使用梯度下降更新所有過濾器值/權重和參數值,以最小化輸出誤差。
根據權重對總誤差的貢獻對其進行調整。
當再次輸入相同的圖像時,輸出概率可能就變成了 [0.1,0.1,0.7,0.1],這更接近目標向量 [0,0,1,0]。
這意味著網絡已經學會了如何通過調整其權重/過濾器并減少輸出誤差的方式對特定圖像進行正確分類。
過濾器數量、大小,網絡結構等參數在步驟1之前都已經固定,并且在訓練過程中不會改變 —— 只會更新濾器矩陣和連接權值。
步驟5:對訓練集中的所有圖像重復步驟2-4。
?
通過以上步驟就可以訓練出卷積神經網絡 —— 這實際上意味著卷積神經網絡中的所有權重和參數都已經過優化,可以對訓練集中的圖像進行正確分類。
當我們給卷積神經網絡中輸入一個新的(未見過的)圖像時,網絡會執行前向傳播步驟并輸出每個類的概率(對于新圖像,計算輸出概率所用的權重是之前優化過,并能夠對訓練集完全正確分類的)。如果我們的訓練集足夠大,神經網絡會有很好的泛化能力(但愿如此)并將新圖片分到正確的類里。
注1:為了給大家提供一個直觀的訓練過程,上述步驟已經簡化了很多,并且忽略了數學推導過程。如果想要數學推導以及對卷積神經網絡透徹的理解,請參閱 [4] 和 [12]。
注2:上面的例子中,我們使用了兩組交替的卷積和池化層。但請注意,這些操作可以在一個卷積神經網絡中重復執行多次。實際上,現在效果較好的一些卷積神經網絡都包含幾十個卷積和池化層! 另外,每個卷積層之后的池化層不是必需的。從下面的圖16中可以看出,在進行池化操作之前,我們可以連續進行多個卷積 + ReLU 操作。另外請注意圖16卷積神經網絡的每一層是如何展示的。
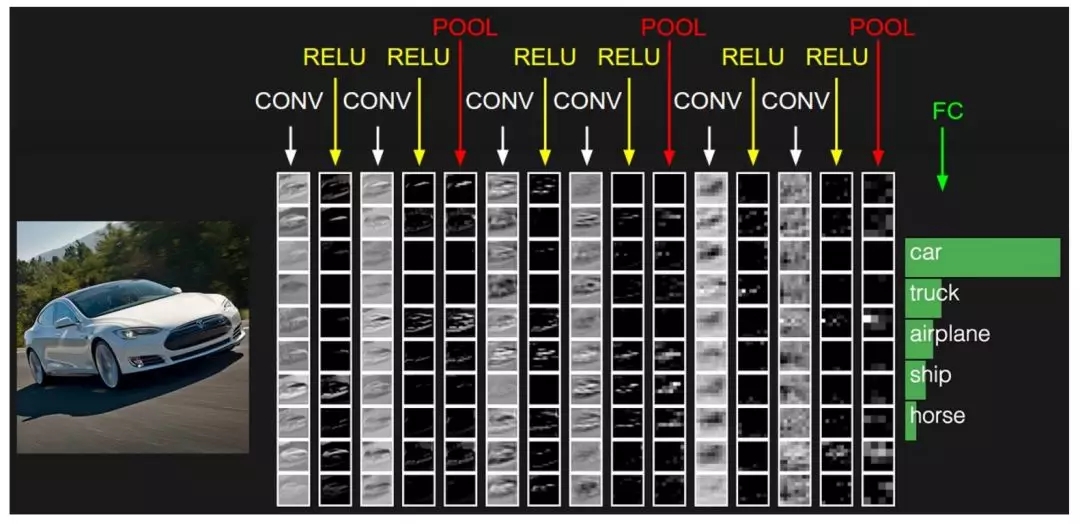
圖16
卷積神經網絡的可視化
一般來說,卷積步驟越多,神經網絡能夠學習識別的特征就更復雜。例如,在圖像分類中,卷積神經網絡在第一層可能會學習檢測原始像素的邊緣,然后在第二層利用這些邊緣檢測簡單形狀,然后在更高級的層用這些形狀來檢測高級特征,例如面部形狀 [14]。圖17演示了這個過程 —— 這些特征是使用卷積深度信念網絡學習的,這張圖片只是為了演示思路(這只是一個例子:實際上卷積過濾器識別出來的對象可能對人來說并沒有什么意義)。
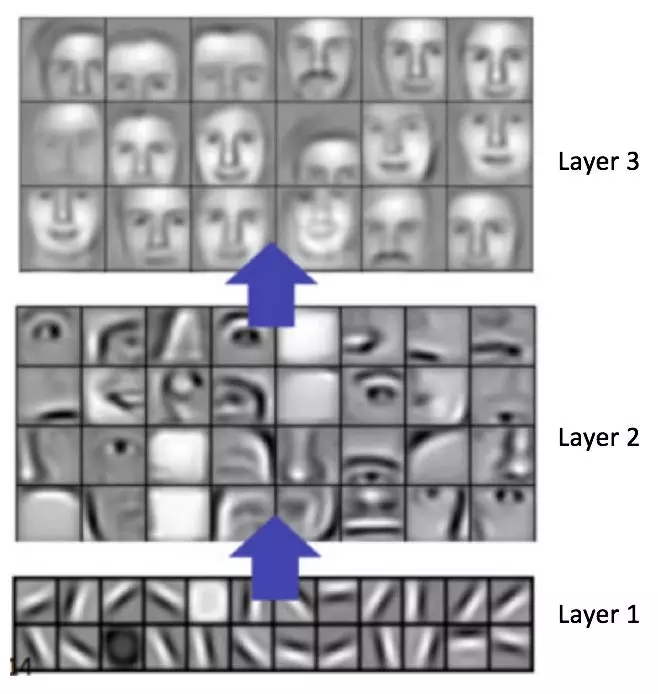
圖17: 卷積深度信念網絡學習特征
Adam Harley 創建了一個基于 MNIST 手寫數字數據集 [13]訓練卷積神經網絡的可視化。我強烈推薦大家 使用它來了解卷積神經網絡的工作細節。
我們在下圖中可以看到神經網絡對于輸入數字“8”的具體操作細節。請注意,圖18中并未多帶帶顯示ReLU操作。
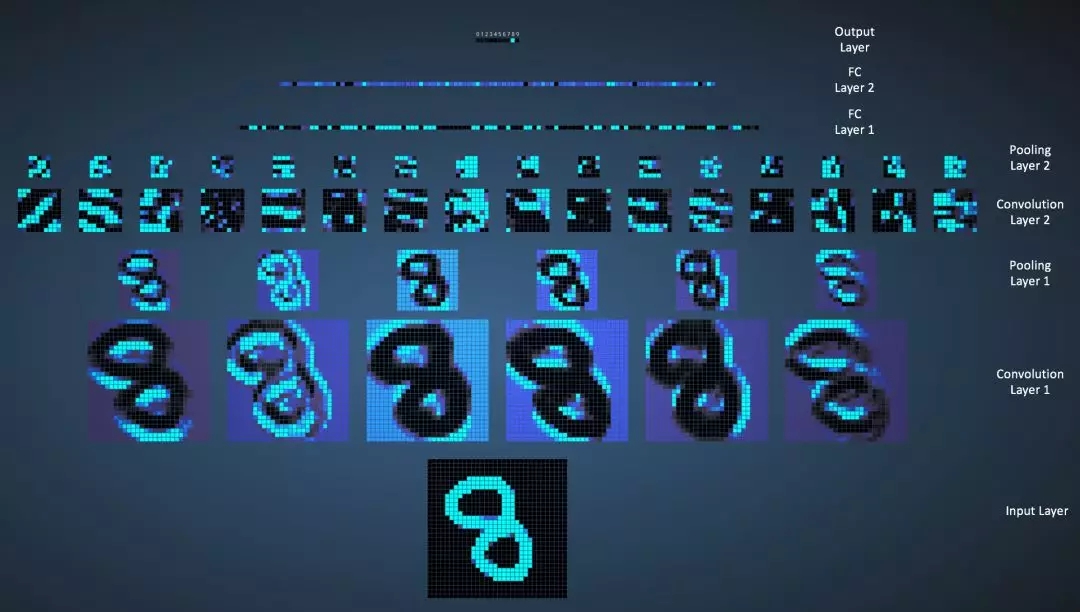
圖18:基于手寫數字訓練卷積神經網絡的可視化
輸入圖像包含 1024 個像素點(32 × 32 圖像),第一個卷積層(卷積層1)由六個不同的5 × 5(步幅為1)過濾器與輸入圖像卷積而成。如圖所示,使用六個不同的過濾器得到深度為六的特征映射。
卷積層1之后是池化層1,它在卷積層1中的六個特征映射上分別進行2 × 2較大池化(步幅為2)。將鼠標指針移動到池化層的任意像素上,可以觀察到它來自于2 x 2網格在前一個卷積層中的作用(如圖19所示)。注意到2 x 2網格中具有較大值(最亮的那個)的像素點會被映射到池化層。

圖19:池化操作可視化
池化層1之后是十六個執行卷積操作的5 × 5(步幅為1)卷積過濾器。然后是執行2 × 2較大池化(步幅為2)的池化層2。 這兩層的作用與上述相同。
然后有三個完全連接(FC)層:
第一個FC層中有120個神經元
第二個FC層中有100個神經元
第三個FC層中的10個神經元對應于10個數字 —— 也稱為輸出層
注意,在圖20中,輸出層的10個節點每一個都連接到第二個完全連接層中的全部100個節點(因此稱為完全連接)。
另外,注意為什么輸出層中明亮的節點是’8’ —— 這意味著神經網絡對我們的手寫數字進行了正確分類(節點亮度越高表示它的輸出更高,即8在所有數字中具有較高的概率)。

圖20:完全連接層可視化
該可視化系統的 3D 版本在此。
其他卷積神經網絡框架
卷積神經網絡始于20世紀90年代初。我們已經討論了LeNet,它是最早的卷積神經網絡之一。下面列出了其他一些有影響力的神經網絡框架 [3] [4]。
LeNet (20世紀90年代):本文已詳述。
20世紀90年代到2012年:從20世紀90年代后期到2010年初,卷積神經網絡正處于孵化期。隨著越來越多的數據和計算能力的提升,卷積神經網絡可以解決的任務變得越來越有趣。
AlexNet(2012) – 2012年,Alex Krizhevsky(和其他人)發布了 AlexNet,它是提升了深度和廣度版本的 LeNet,并在2012年以巨大優勢贏得了 ImageNet 大規模視覺識別挑戰賽(ILSVRC)。這是基于之前方法的重大突破,目前 CNN 的廣泛應用都要歸功于 AlexNet。
ZF Net(2013) – 2013年 ILSVRC 獲獎者來自 Matthew Zeiler 和 Rob Fergus 的卷積網絡。它被稱為 ZFNet(Zeiler 和 Fergus Net 的簡稱)。它在 AlexNet 的基礎上通過調整網絡框架超參數對其進行了改進。
GoogLeNet(2014) – 2014年 ILSVRC 獲獎者是 Google 的 Szegedy 等人的卷積網絡。其主要貢獻是開發了一個初始模塊,該模塊大大減少了網絡中的參數數量(4M,而 AlexNet 有60M)。
VGGNet(2014) – 2014年 ILSVRC 亞軍是名為 VGGNet 的網絡。其主要貢獻在于證明了網絡深度(層數)是影響性能的關鍵因素。
ResNets(2015) – 何凱明(和其他人)開發的殘差網絡是2015年 ILSVRC 的冠軍。ResNets 是迄今為止較先進的卷積神經網絡模型,并且是大家在實踐中使用卷積神經網絡的默認選擇(截至2016年5月)。
DenseNet(2016年8月) – 最近由黃高等人發表,密集連接卷積網絡的每一層都以前饋方式直接連接到其他層。 DenseNet 已經在五項競爭激烈的對象識別基準測試任務中證明自己比之前較先進的框架有了顯著的改進。具體實現請參考這個網址。
結論
本文中,我嘗試著用一些簡單的術語解釋卷積神經網絡背后的主要概念,同時簡化/略過了幾個細節部分,但我希望這篇文章能夠讓你直觀地理解其工作原理。
本文最初是受 Denny Britz 《理解卷積神經網絡在自然語言處理上的運用》這篇文章的啟發(推薦閱讀),文中的許多解釋是基于這篇文章的。為了更深入地理解其中一些概念,我鼓勵您閱讀斯坦福大學卷積神經網絡課程的筆記以及一下參考資料中提到的其他很棒的資源。如果您對上述概念的理解遇到任何問題/建議,請隨時在下面留言。
文中所使用的所有圖像和動畫均屬于其各自的作者,陳列如下。
參考
karpathy/neuraltalk2: Efficient Image Captioning code in Torch, Examples
Shaoqing Ren, et al, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, 2015, arXiv:1506.01497
Neural Network Architectures, Eugenio Culurciello’s blog
CS231n Convolutional Neural Networks for Visual Recognition, Stanford
Clarifai/Technology
Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks
Feature extraction using convolution, Stanford
Wikipedia article on Kernel (image processing)
Deep Learning Methods for Vision, CVPR 2012 Tutorial
Neural Networks by Rob Fergus, Machine Learning Summer School 2015
What do the fully connected layers do in CNNs?
Convolutional Neural Networks, Andrew Gibiansky
W. Harley, “An Interactive Node-Link Visualization of Convolutional Neural Networks,” in ISVC, pages 867-877, 2015 (link). Demo
Understanding Convolutional Neural Networks for NLP
Backpropagation in Convolutional Neural Networks
A Beginner’s Guide To Understanding Convolutional Neural Networks
Vincent Dumoulin, et al, “A guide to convolution arithmetic for deep learning”, 2015, arXiv:1603.07285
What is the difference between deep learning and usual machine learning?
How is a convolutional neural network able to learn invariant features?
A Taxonomy of Deep Convolutional Neural Nets for Computer Vision
Honglak Lee, et al, “Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations” (link)
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4746.html

摘要:而在卷積神經網絡中,這兩個神經元可以共用一套參數,用來做同一件事情。卷積神經網絡的基本結構卷積神經網絡的基本結構如圖所示從右到左,輸入一張圖片卷積層池化層卷積層池化層展開全連接神經網絡輸出。最近幾天陸續補充了一些線性回歸部分內容,這節繼續機器學習基礎部分,這節主要對CNN的基礎進行整理,僅限于基礎原理的了解,更復雜的內容和實踐放在以后再進行總結。卷積神經網絡的基本原理 前面對全連接神經網絡...
摘要:自從和在年贏得了的冠軍,卷積神經網絡就成為了分割圖像的黃金準則。事實上,從那時起,卷積神經網絡不斷獲得完善,并已在挑戰上超越人類。現在,卷積神經網絡在的表現已超越人類。 卷積神經網絡(CNN)的作用遠不止分類那么簡單!在本文中,我們將看到卷積神經網絡(CNN)如何在圖像實例分割任務中提升其結果。自從 Alex Krizhevsky、Geoff Hinton 和 Ilya Sutskever ...
摘要:從到,計算機視覺領域和卷積神經網絡每一次發展,都伴隨著代表性架構取得歷史性的成績。在這篇文章中,我們將總結計算機視覺和卷積神經網絡領域的重要進展,重點介紹過去年發表的重要論文并討論它們為什么重要。這個表現不用說震驚了整個計算機視覺界。 從AlexNet到ResNet,計算機視覺領域和卷積神經網絡(CNN)每一次發展,都伴隨著代表性架構取得歷史性的成績。作者回顧計算機視覺和CNN過去5年,總結...
摘要:是一個深度學習包,里面含有很多機器學習算法,如卷積神經網絡,深度信念網絡,自動編碼堆棧,卷積的作者是。對于每個卷積輸出,表示該層的一個輸出,所對應的所有卷積核,包含的神經元的總數。 deepLearnToolbox-master是一個深度學習matlab包,里面含有很多機器學習算法,如卷積神經網絡CNN,深度信念網絡DBN,自動編碼AutoEncoder(堆棧SAE,卷積CAE)的作者是 R...
摘要:一維卷積常用于序列模型,自然語言處理領域。三維卷積這里采用代數的方式對三維卷積進行介紹,具體思想與一維卷積二維卷積相同。 由于計算機視覺的大紅大紫,二維卷積的用處范圍最廣。因此本文首先介紹二維卷積,之后再介紹一維卷積與三維卷積的具體流程,并描述其各自的具體應用。1、二維卷積?? ? 圖中的輸入的數據維度為 14 × 14 ,過濾器大小為 5 × 5,二者做卷積,輸出的數據維度為 10 × 1...

閱讀 2701·2023-04-25 14:59
閱讀 888·2021-11-22 11:59
閱讀 635·2021-11-17 09:33
閱讀 2468·2021-09-27 13:34
閱讀 3898·2021-09-09 11:55
閱讀 2320·2019-08-30 15:44
閱讀 1123·2019-08-30 14:06
閱讀 1924·2019-08-29 16:55






