資訊專欄INFORMATION COLUMN

摘要:而在卷積神經(jīng)網(wǎng)絡(luò)中,這兩個神經(jīng)元可以共用一套參數(shù),用來做同一件事情。卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)如圖所示從右到左,輸入一張圖片卷積層池化層卷積層池化層展開全連接神經(jīng)網(wǎng)絡(luò)輸出。
最近幾天陸續(xù)補充了一些“線性回歸”部分內(nèi)容,這節(jié)繼續(xù)機器學(xué)習(xí)基礎(chǔ)部分,這節(jié)主要對CNN的基礎(chǔ)進行整理,僅限于基礎(chǔ)原理的了解,更復(fù)雜的內(nèi)容和實踐放在以后再進行總結(jié)。
前面對全連接神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)進行了簡要的介紹,這一節(jié)主要對卷積神經(jīng)網(wǎng)絡(luò)的基本原理進行學(xué)習(xí)和總結(jié)。
所謂卷積,就是通過一種數(shù)學(xué)變換的方式來對特征進行提取,通常用于圖片識別中。
既然全連接的神經(jīng)網(wǎng)絡(luò)可以用于圖片識別,那么為什么還要用卷積神經(jīng)網(wǎng)絡(luò)呢?
(1)首先來看下面一張圖片:

在這個圖片當(dāng)中,鳥嘴是一個很明顯的特征,當(dāng)我們做圖像識別時,當(dāng)識別到有“鳥嘴”這樣的特征時,可以具有很高的確定性認為圖片是一個鳥類。
那么,在提取特征的過程中,有時就沒有必要去看完整張圖片,只需要一小部分就能識別出一定具有代表的特征。
因此,使用卷積就可以使某一個特定的神經(jīng)元(在這里,這個神經(jīng)元可能就是用來識別“鳥嘴”的)僅僅處理帶有該特征的部分圖片就可以了,而不必去看整張圖片。
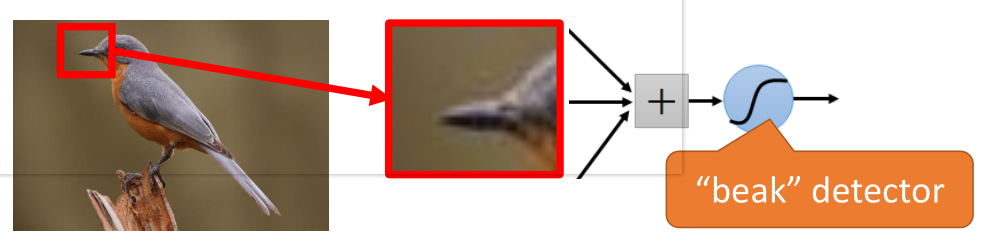
那么這樣就會使得這個神經(jīng)元具有更少的參數(shù)(因為不用再跟圖片的每一維輸入都連接起來)。
(2)再來看下面一組圖片:

上面兩張圖片都是鳥類,而不同的是,兩只鳥的“鳥嘴”的位置不同,但在普通的神經(jīng)網(wǎng)絡(luò)中,需要有兩個神經(jīng)元,一個去識別左上角的“鳥嘴”,另一個去識別中間的“鳥嘴”:

但其實這兩個“鳥嘴”的形狀是一樣的,這樣相當(dāng)于上面兩個神經(jīng)元是在做同一件事情。
而在卷積神經(jīng)網(wǎng)絡(luò)中,這兩個神經(jīng)元可以共用一套參數(shù),用來做同一件事情。
(3)對樣本進行子采樣,往往不會影響圖片的識別。
如下面一張圖:

假設(shè)把一張圖片當(dāng)做一個矩陣的話,取矩陣的奇數(shù)行和奇數(shù)列,可看做是對圖片的一種縮放,而這種縮放往往不會影響識別效果。
卷積神經(jīng)網(wǎng)絡(luò)中就可以對圖片進行縮放,是圖片變小,從而減少模型的參數(shù)。
卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)如圖所示:
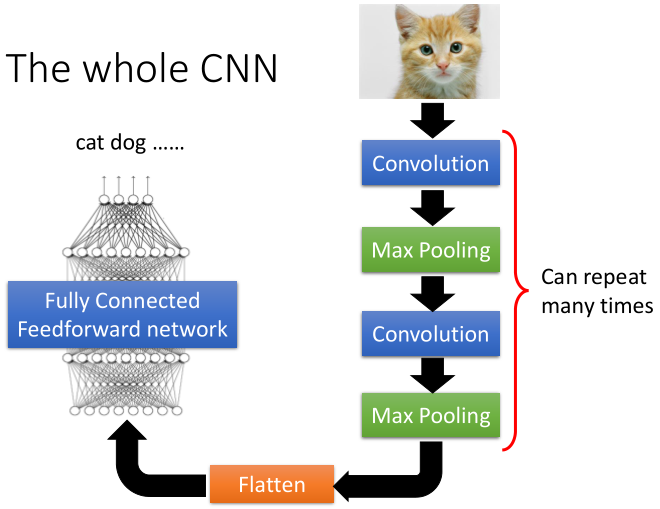
從右到左,輸入一張圖片→卷積層→max pooling(池化層)→卷積層→max pooling(池化層)→......→展開→全連接神經(jīng)網(wǎng)絡(luò)→輸出。
中間的卷積層和池化層可以重復(fù)多次。后面會一一介紹每一層是如何工作的。
對于第0部分的三個功能:
(1)某個神經(jīng)元只需偵測某一部分的圖片,來識別某種特征這個工作是在卷積層內(nèi)完成的。
(2)具有相同功能的神經(jīng)元共用一套參數(shù),這個工作也是在卷積層內(nèi)完成的。
(3)通過縮小圖片,來減少模型的參數(shù),這個工作是在池化層中完成的。
稍后會解釋上面三個部分是如何進行的。
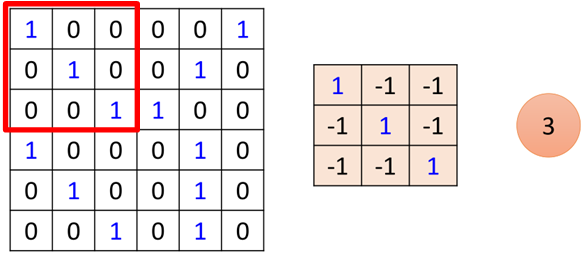
假設(shè)有一張6*6的黑白圖片,如圖所示:
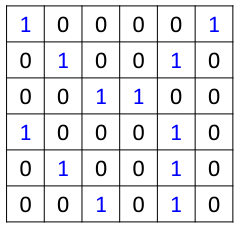
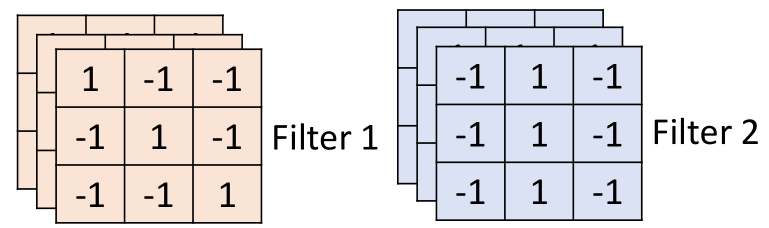
首先圖片經(jīng)過卷積層,卷積層有一組filter,每個filter用來抓取圖片中的某一種特征,如圖所示:
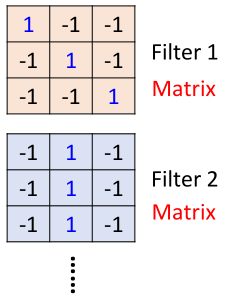
假設(shè)filter是3*3的矩陣,每個filter有9個參數(shù),而這些參數(shù)就是通過訓(xùn)練學(xué)習(xí)得到的,這里假設(shè)我們已經(jīng)學(xué)習(xí)得到了上面一組參數(shù)的值。
因此也就說明了問題(1)中,每一個filter只偵測圖片中的很小一部分數(shù)據(jù)。
那么每個filter是如何去抓取特征的呢?也就是(1)中使某一個神經(jīng)元只偵測一部分圖片就能提取某一種特征的問題。
首先看filter1,filter大小為3*3,那么相當(dāng)于這個filter1依次從左到右去覆蓋整張圖片,然后與覆蓋區(qū)域做內(nèi)積,如圖所示:
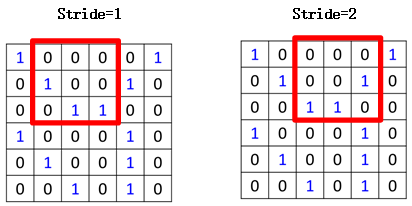
首先從左上角開始,覆蓋圖片左上角3*3的區(qū)域,計算結(jié)果得到3,然后向右移動,這里移動的步長稱之為stride,當(dāng)stride為1時,即一次移動一格,為2時,一次移動兩格,如圖所示:
移動之后再次用圖片被覆蓋的區(qū)域與filter做內(nèi)積,得到第二個值:

依次進行移動和計算,當(dāng)移到最右邊盡頭時,則從下一行開始繼續(xù)移動,最終得到如圖所示矩陣:
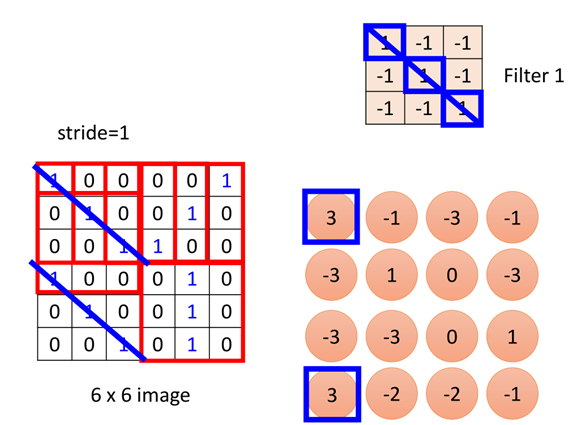
通過觀察這個filter1可以看出,filter1的對角矩陣全為1,其他為-1,那么對于圖片中對角為1的部分,與filter1做內(nèi)積后的值就會很大(例子中等于3),其他的則會很小。
因此filter1是一種用于偵測對角都為1的圖片這種屬性,在圖片中可以看到,坐上角和右下角都具有這種特征。
所以這也就說明了(2)中的問題,一個filter的一組參數(shù),可以偵測到圖片中兩個位置的相同屬性。
接下來是第二個filter,filter2,那么filter2與圖片的計算方式一模一樣,如圖所示:

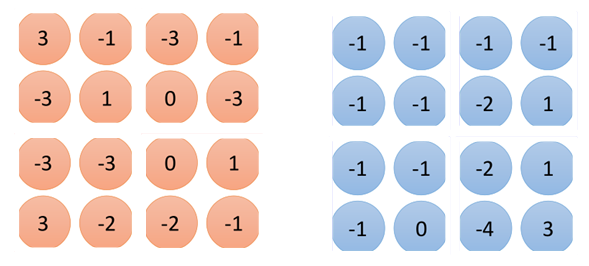
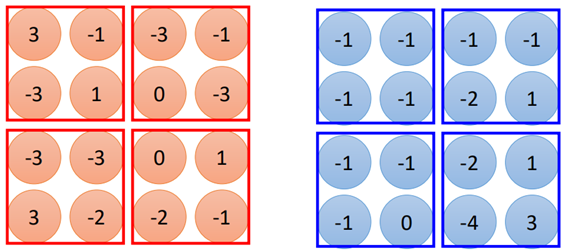
其他的filter也是如此,依次計算,然后把每個filter處理結(jié)果放在一起,如圖所示:

那么相當(dāng)于一個紅色方框現(xiàn)在是由2個值來描述的,最終得到的是2個4*4的圖片,稱之為“feature map”。
上面是對于一張黑白的圖片進行一次卷積(convolution)的過程,那么對于彩色的圖片是怎樣處理的呢?
彩色圖片通常是由“RGB”組成,分別表示紅色、綠色和藍色,那么就相當(dāng)于有三個部分的組成,如圖所示:
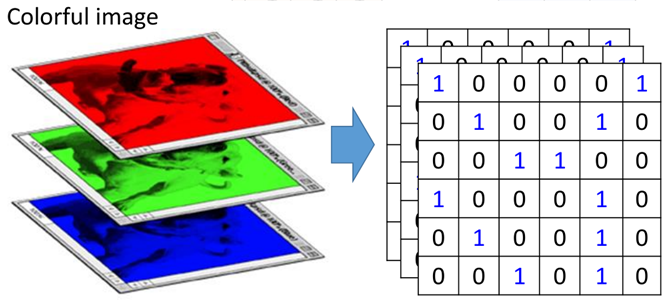 這三個層稱之為“通道”(channel),那么利用卷積處理這種圖片時,filter也應(yīng)該是三層,即3*3*3的,是帶有深度的,長下面這個樣子:
這三個層稱之為“通道”(channel),那么利用卷積處理這種圖片時,filter也應(yīng)該是三層,即3*3*3的,是帶有深度的,長下面這個樣子:
相當(dāng)于每個filter具有27個參數(shù)。
其實卷積就是一種特殊形式的全連接網(wǎng)絡(luò),還是假設(shè)是上面那張6*6的圖片,如下是全連接的網(wǎng)絡(luò)結(jié)構(gòu):
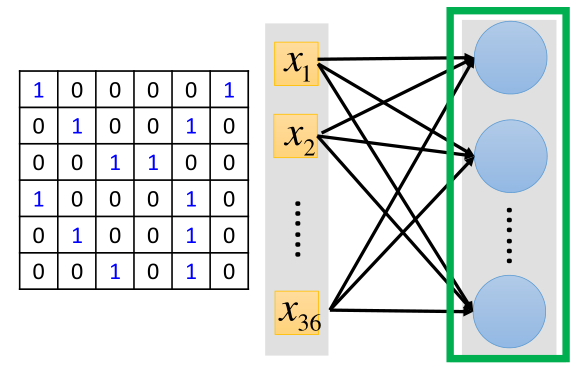
把圖片進行拉直展開,但在卷積中,這個網(wǎng)絡(luò)有些連接的地方被切斷了,只有一部分輸入與神經(jīng)元相連接。下面進行解釋:
正如上面的卷積過程,如下是其中的一步,如圖所示:
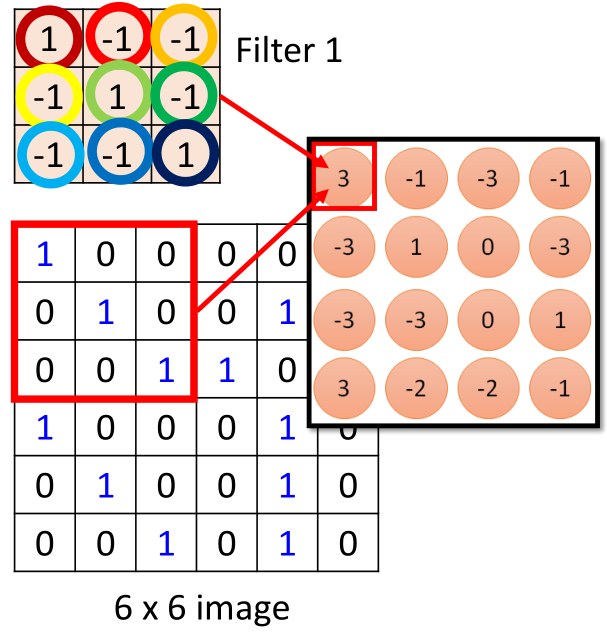
那么這個步驟我們可以想象成是這樣子的:

左邊把圖片的36個數(shù)值拉直,然后,對于filter1所覆蓋的區(qū)域為左上角,那么元素對應(yīng)的位置為1、2、3、7、8、9、13、14、15。
然后這9個數(shù)值,依次經(jīng)過各自的weight相乘再相加,得到第一個值3,這里的weight就是對應(yīng)的filter中各個位置的值,圖中weight線的顏色與filter中圓圈顏色一一對應(yīng)。
到這里就很清楚的看出卷積與全連接之間的關(guān)系,相當(dāng)于簡化了全連接神經(jīng)網(wǎng)絡(luò),從而使得參數(shù)量更少。
然后filter開始向右移動一格(stride=1,上面計算過程的第二個方框,元素依次為2、3、4、8、9、10、14、15、16),與filter做inner product,得到結(jié)果-1,對應(yīng)到全連接網(wǎng)絡(luò)中如圖所示:

依舊是每個元素的weight與輸入輸出連接,顏色對應(yīng)的filter圓圈與weight的顏色一致。
從上面的圖可以看出,兩個神經(jīng)元(3和-1)都是通過filter1作為weight與輸入進行連接的,也就是說,這兩個神經(jīng)元是共用同一組參數(shù),這樣,在上面減少參數(shù)的基礎(chǔ)上,使得模型的參數(shù)更少了。
上述過程就是卷積層的工作過程,主要用于圖片中特征的抓取,完成第0節(jié)內(nèi)容的前兩個。
池化層的作用上面說了,就是為了圖片的縮放,那么池化層是如何進行縮放的呢?
其實池化層的原理很簡單,這里以max-pooling為例,經(jīng)過卷積層之后的圖片變?yōu)?*4大小的圖片,有2個filter,也就是兩張4*4的圖片:
池化就是將上面得到的數(shù)據(jù)進行分組,如圖所示:
如圖示中的分組方法,這種分組方法可以是任意的,也可以三個一組等等,然后取每個組中的最大值:
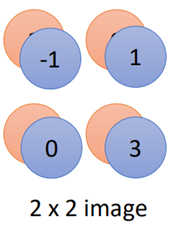
那么原來4*4的圖片經(jīng)過maxpooling之后就縮小為2*2的圖片了,當(dāng)然這里也不一定非要取最大值,也可以取平均,或者又取平均又取最大值等。
那么上面的過程總結(jié)一下就可以用如下圖進行概括:
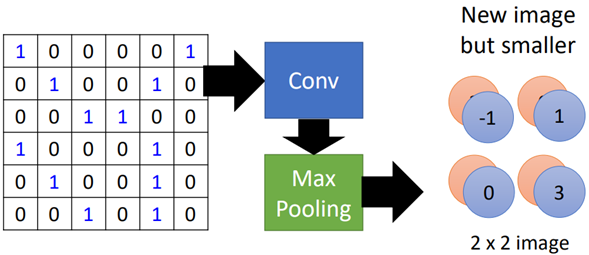
這就是池化層的工作原理,比較簡單。
接下來就來到了flatten和全連接層了,flatten的作用就是把上面得到的兩個2*2的image拉直展開,然后再丟進全連接網(wǎng)絡(luò)中計算就可以了,這個跟前面全連接神經(jīng)網(wǎng)絡(luò)的方法一樣,如圖所示:
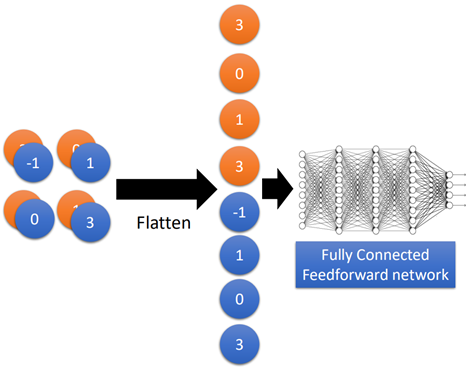
這里就不再詳細贅述了。那么整個網(wǎng)絡(luò)就是利用梯度下降的方法進行訓(xùn)練的,所有的參數(shù)被一起學(xué)習(xí)得到。
這里還是使用keras對CNN的建模過程進行一個簡單的實現(xiàn),首先先來看一下keras分別添加卷積層和池化層的過程:
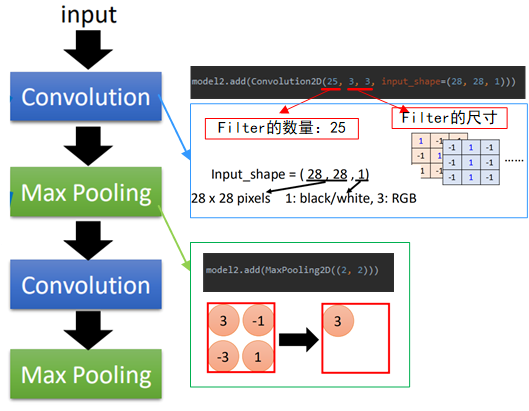
如圖中所示,首先要導(dǎo)入Convolution2D(后來這個接口會改成Conv2D)和Maxpooling2D。
然后與之前神經(jīng)網(wǎng)絡(luò)中一樣,不過是把“Dense”換成了上面兩個方法,其中Convolution2D中,25表示filter的數(shù)量,3,3表示filter的尺寸,input_shape為輸入圖片的大小,28*28為圖片大小,1表示黑白圖片,3則表示彩圖“RGB”;
Maxpooling2D中只有分組的形狀,即2*2大小的。
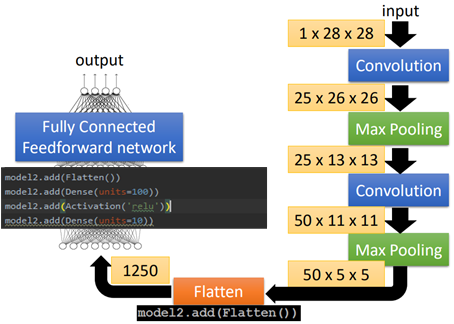
接下來就是根據(jù)設(shè)計的網(wǎng)絡(luò)的形狀,重復(fù)上面兩個步驟,完成卷積和池化。如圖所示:

圖中黑色的方框為代碼的實現(xiàn)內(nèi)容,在keras1.0和2.0中可能有些差異;
黃色的框中是輸入和輸出的尺寸大小,可以看到,輸入為28*28的圖片,經(jīng)過25個3*3的filter組成的第一個卷積層之后,變成了25*26*26的尺寸;
然后經(jīng)過第一個2*2的池化層,縮小后的輸出尺寸大小為25*13*13;
然后經(jīng)過第二個由50個3*3的filter之后,輸出變?yōu)?strong>50*11*11;
之后經(jīng)過第二個2*2的池化層后,縮小后的輸出尺寸變?yōu)?strong>50*5*5(這里由于輸入為基數(shù),最后一格就忽略掉了)。
而在卷積層中,filter的參數(shù)數(shù)量是在變化的,在第一個卷積層的參數(shù)為3*3=9個,這個比較好理解;
而在第二個卷積層中,參數(shù)就變成了225個,這是因為上一層的輸出為25*13*13大小的圖片,這時是帶有channel的(就相當(dāng)于一開始輸入為RGB時,通道數(shù)為3)當(dāng)使用3*3的filter進行處理時,需要帶有深度25,因此每個filter的參數(shù)數(shù)量為25*3*3=225。
然后就是經(jīng)過Faltten和fully-connection了,這個與之前的神經(jīng)網(wǎng)絡(luò)一致:
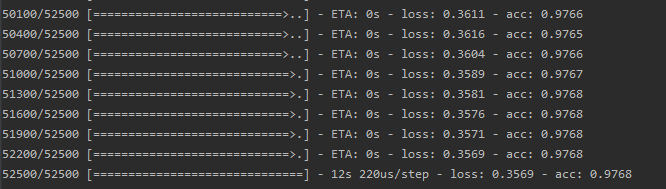
然后就可以對模型進行訓(xùn)練了。這里要注意的是,這里的輸入跟全連接有所不同,要把輸入圖片數(shù)據(jù)轉(zhuǎn)化為(28,28,1)的格式。完整代碼如下:
from sklearn.datasets import fetch_openmlfrom sklearn.preprocessing import OneHotEncoderfrom sklearn.model_selection import train_test_splitimport numpy as npfrom keras import Sequentialfrom keras.layers import Densefrom keras.layers import Activationfrom keras.layers import Convolution2D, MaxPooling2D, Flattendata_x, data_y = fetch_openml(mnist_784, version=1, return_X_y=True)x = []for i in range(len(data_x)): tmp = data_x.iloc[i, :].tolist() tmp = np.array(tmp).reshape((28, 28, 1)) x.append(tmp)x = np.array(x)one_hot = OneHotEncoder()data_y = one_hot.fit_transform(np.array(data_y).reshape(data_y.shape[0], 1)).toarray()train_x, test_x, train_y, test_y = train_test_split(x, data_y)model2 = Sequential()model2.add(Convolution2D(25, 3, 3, input_shape=(28, 28, 1)))model2.add(MaxPooling2D((2, 2)))model2.add(Convolution2D(50, 3, 3))model2.add(MaxPooling2D((2, 2)))model2.add(Flatten())model2.add(Dense(units=100))model2.add(Activation(relu))model2.add(Dense(units=10))model2.add(Activation(softmax))model2.compile(optimizer=adam, loss=categorical_crossentropy, metrics=[accuracy])model2.fit(train_x, train_y, batch_size=300, epochs=20)
最后的輸出如下:
通過CNN的原理我們大致知道,CNN的卷積是不斷提取特征的過程,池化是對圖片的縮放,那么究竟CNN學(xué)習(xí)到了什么呢?如下面一張圖:

給機器一張圖片,那么對人來說,這張圖片是一雙鞋,而對機器來說,它可能認為是是美洲獅,因為圖中的鞋標(biāo)有一只美洲獅。
因此,我們想要知道CNN究竟學(xué)習(xí)到了啥,下面介紹幾種方法來查看CNN都在偵測什么特征的方法。
前面我們說到,filter就是為了抓取某一種特征的,那么我們是不是可以看一下這些filter分別都是偵測什么樣的特征的。
根據(jù)CNN的原理,隨著網(wǎng)絡(luò)越來越靠近輸出層,那么這一層所學(xué)習(xí)到的東西就越來越抽象,不太容易觀察。因此,我們選取第一個卷積層的filters來看一下。
對于一個訓(xùn)練好的模型,將第一個卷積層的filters多帶帶拿出來,并畫出來,如圖所示:

上面一共96個filter,每個filter的大小為11*11,從filter我們可以看出,上面幾排的filter主要是偵測形狀特征的,下面幾排的filter主要是偵測色彩特征的。
我們也可以通過多帶帶看一個filter,然后把圖片依次輸入的CNN中,看哪些圖片經(jīng)過這個filter后的輸出(Activate)最大,如下圖所示:

白色的框表示filter,這里白色的框看著很大,主要是因為這個filter比較靠后,也就是它所看到的是前面經(jīng)過縮小后的輸入,因此框就會變得很大。
第一排的圖片中的框是一個filter1,可以看到,這個filter對于臉部的偵測比較強;
第二排的框是另一個filter2,可以看到filter2偵測的主要是洞狀排列的特征;
第三排的filter3則是偵測紅色的特征;
以此類推...
這種方法是查看特征的,也就是說使用反卷積、反池化的方法,來可視化輸入圖像的激活特征。
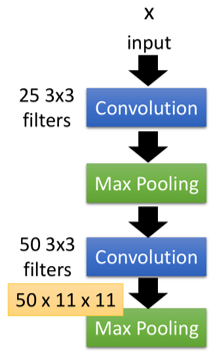
還用原理部分那個CNN結(jié)構(gòu)的例子,如下圖左邊的結(jié)構(gòu):
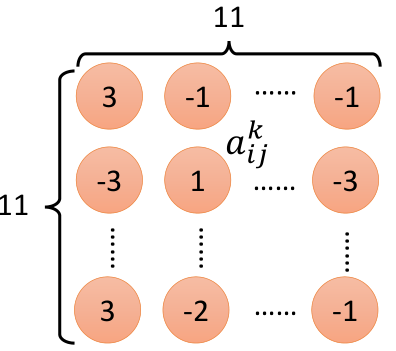
在第二個卷積層中,假設(shè)第k個filter,它與輸入作用以后得到的結(jié)果如上圖中右側(cè),每一個元素aij,然后把aij相加,即為ak,即:

那么現(xiàn)在我們想要通過輸入x使得ak最大,也就是找一張圖片x,使得ak的輸出最大,即:
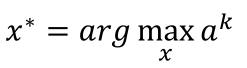
這里就要利用gradient ascent的方法去找這個最大值了,即求:
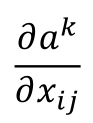
就相當(dāng)于原先經(jīng)過卷積、池化過程,現(xiàn)在要將x當(dāng)做未知量,反過來求反池化、反卷積去求解出一個使得ak最大的x(注意這里x并不是真正的圖片了,相當(dāng)于是通過反池化和反卷積所得到的的帶有一些特征的圖像);
具體原因就在于反池化和反卷積的求解過程,無法還原為原先的圖片,這里暫不過多介紹如何反池化和反卷積的原理,后續(xù)再補充。
那么經(jīng)過上面的步驟,還原得到的x的結(jié)果如圖所示:

一共50個filter,這里取前12個,每個圖片的意思代表1個filter所還原得到的圖片x,也就是說,比如第一張圖片,將其作為input丟進上面那個網(wǎng)絡(luò)后,其輸出與第一個filter作用后得到的ak最大。
仔細觀察一下上面的圖,還是有一定的規(guī)律可循的。
同時我們也可以去查看fully-connection部分的神經(jīng)元,原理跟上面一樣,不過再求解釋時又多了一層反向傳播的過程,如圖:
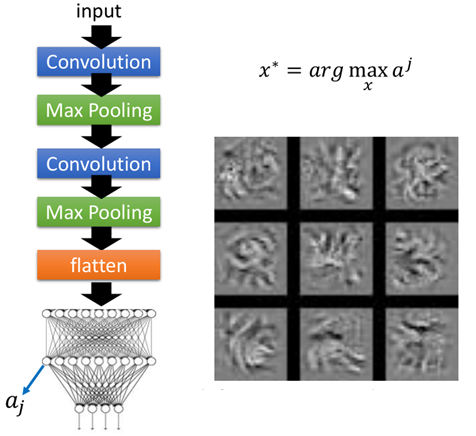
當(dāng)然也可以去拿輸出層的神經(jīng)元,比如識別結(jié)果為0,輸出層在第0維值就很大,然后一樣根據(jù)上面的原理得到的結(jié)果如圖:
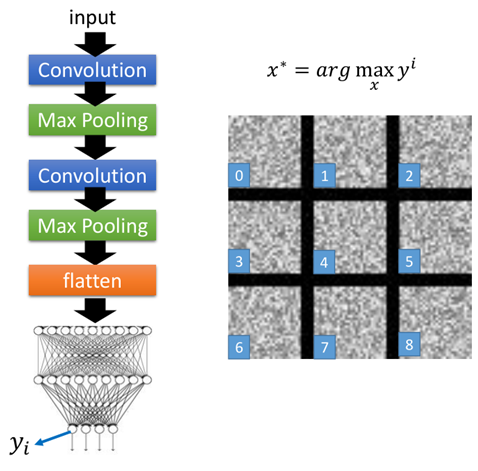
會發(fā)現(xiàn)得到的結(jié)果什么也看不到,但是當(dāng)把某張圖片再次輸入進網(wǎng)絡(luò)之后,得到的確實是對應(yīng)的結(jié)果。
這也就說明了深度學(xué)習(xí)很容易被欺騙,但從側(cè)面也反映出了,深度學(xué)習(xí)確實學(xué)習(xí)到了某些特征,并非僅僅簡單“記住”數(shù)據(jù),也說明深度學(xué)習(xí)的“玄學(xué)”性,難以解釋。
當(dāng)然,在上面的求解過程中,我們可以適當(dāng)加一些限制,比如正則化:
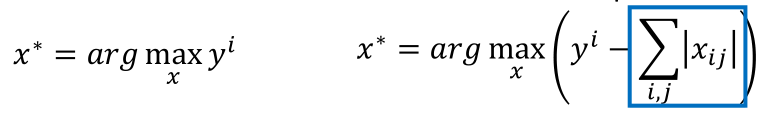
那么得到的結(jié)果如圖:

發(fā)現(xiàn)結(jié)果稍微清晰了一些,有些能夠看到一些筆畫。
那么正則化的目的是在保證y越大越高的同時,也要使得xij(圖片中的每一個pixel)越小越好,也就是說對于圖片顯示(白色的是筆畫,黑色的是空白)時,盡可能使空白減少,能連的連起來。所以效果會好些。
對于一張圖片的識別,我們可以計算類別y對圖像像素pixel的微分的值:

通過改變像素xij,來看這個像素對識別的影響是否重要,也就是說,當(dāng)xij稍微做一下改變,對識別的結(jié)果影響有多大,用這樣的方法可以得到如下的結(jié)果:

白色區(qū)域表示對識別影響較為重要的pixel,可以大概看到一些形狀。那這樣做有什么意義呢?
有時當(dāng)我們從網(wǎng)上爬取圖片進行建模后,發(fā)現(xiàn)對馬的識別率很高,但對其他的識別一般,這是因為可能關(guān)于“馬”的圖片都包含“horse”字樣的標(biāo)簽,機器真正識別到的是“horse”的標(biāo)簽,而并非知道馬長什么樣子。
同樣的道理,我們可以通過蓋住圖片的一部分,去看看蓋住的部分結(jié)果的影響有多大,比如:

圖中灰色的區(qū)域是被蓋住的,不斷移動灰色的區(qū)域,看對結(jié)果的影響有多大,那么可以獲取到下面一樣的熱力圖:
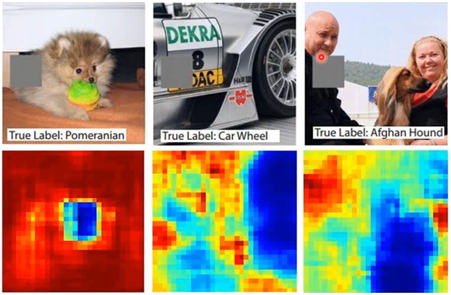
圖中顏色越淺表示對辨識的結(jié)果影響越大,越不能辨別出是什么,可以看到,第一張當(dāng)蓋住狗的臉的時候,很難分辨出狗;
第二張圖片當(dāng)蓋住輪胎部分的時候,就很難辨別出輪胎;
第三張圖片當(dāng)蓋住狗的身子的部分,就很難辨別出狗了。
更多有關(guān)CNN可視化的內(nèi)容,可搜索一些有關(guān)博客進行學(xué)習(xí):https://blog.csdn.net/xys430381_1/article/details/90413169
根據(jù)上面的理論,我們可以通過修改某個filter的參數(shù),去還原出一張另類的圖片,比較有趣的應(yīng)用有deep dream和風(fēng)格遷移,如下圖(圖片來源于網(wǎng)絡(luò)):

這里就暫時不具體介紹原理了,后面會找一些開源的項目去玩。
參考資料:臺大李宏毅《機器學(xué)習(xí)-卷積神經(jīng)網(wǎng)絡(luò)》
上面是對CNN進行的一個初步的介紹,后面會對深度學(xué)習(xí)部分進行系統(tǒng)的學(xué)習(xí)和整理,這里主要是對原理有個初步的認識,因此很多都是概念性的東西,后續(xù)會進一步添加補充。
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/125103.html
摘要:用離散信一文清晰講解機器學(xué)習(xí)中梯度下降算法包括其變式算法無論是要解決現(xiàn)實生活中的難題,還是要創(chuàng)建一款新的軟件產(chǎn)品,我們最終的目標(biāo)都是使其達到最優(yōu)狀態(tài)。 提高駕駛技術(shù):用GAN去除(愛情)動作片中的馬賽克和衣服 作為一名久經(jīng)片場的老司機,早就想寫一些探討駕駛技術(shù)的文章。這篇就介紹利用生成式對抗網(wǎng)絡(luò)(GAN)的兩個基本駕駛技能: 1) 去除(愛情)動作片中的馬賽克 2) 給(愛情)動作片中...
摘要:深度學(xué)習(xí)在過去的幾年里取得了許多驚人的成果,均與息息相關(guān)。機器學(xué)習(xí)進階筆記之一安裝與入門是基于進行研發(fā)的第二代人工智能學(xué)習(xí)系統(tǒng),被廣泛用于語音識別或圖像識別等多項機器深度學(xué)習(xí)領(lǐng)域。零基礎(chǔ)入門深度學(xué)習(xí)長短時記憶網(wǎng)絡(luò)。 多圖|入門必看:萬字長文帶你輕松了解LSTM全貌 作者 | Edwin Chen編譯 | AI100第一次接觸長短期記憶神經(jīng)網(wǎng)絡(luò)(LSTM)時,我驚呆了。原來,LSTM是神...

閱讀 724·2023-04-25 19:43
閱讀 3921·2021-11-30 14:52
閱讀 3794·2021-11-30 14:52
閱讀 3859·2021-11-29 11:00
閱讀 3790·2021-11-29 11:00
閱讀 3882·2021-11-29 11:00
閱讀 3562·2021-11-29 11:00
閱讀 6138·2021-11-29 11:00



