資訊專欄INFORMATION COLUMN

摘要:從到,計算機視覺領域和卷積神經網絡每一次發展,都伴隨著代表性架構取得歷史性的成績。在這篇文章中,我們將總結計算機視覺和卷積神經網絡領域的重要進展,重點介紹過去年發表的重要論文并討論它們為什么重要。這個表現不用說震驚了整個計算機視覺界。
從AlexNet到ResNet,計算機視覺領域和卷積神經網絡(CNN)每一次發展,都伴隨著代表性架構取得歷史性的成績。作者回顧計算機視覺和CNN過去5年,總結了他認為不可錯過的標志模型。
在這篇文章中,我們將總結計算機視覺和卷積神經網絡領域的重要進展,重點介紹過去5年發表的重要論文并討論它們為什么重要。從 AlexNet 到 ResNet 主要講基本網絡架構的發展,余下則是各領域的重要文章,包括對抗生成網絡、生成圖像描述模型。
本文結構如下:
AlexNet(2012年)
ZF Net(2013年)
VGG Net(2014年)
GoogLeNet (2015年)
微軟 ResNet (2015年)
區域 CNN(R-CNN - 2013年,Fast R-CNN - 2015年,Faster R-CNN - 2015年)
生成對抗網絡(2014年)
生成圖像描述(2014年)
空間轉化器網絡(2015年)
AlexNet(2012年)
一切都從這里開始(盡管有些人會說是Yann LeCun 1998年發表的那篇論文才真正開啟了一個時代)。這篇論文,題目叫做“ImageNet Classification with Deep Convolutional Networks”,迄今被引用6184次,被業內普遍視為行業最重要的論文之一。Alex Krizhevsky、Ilya Sutskever和 Geoffrey Hinton創造了一個“大型的深度卷積神經網絡”,贏得了2012 ILSVRC(2012年ImageNet 大規模視覺識別挑戰賽)。稍微介紹一下,這個比賽被譽為計算機視覺的年度奧林匹克競賽,全世界的團隊相聚一堂,看看是哪家的視覺模型表現更為出色。2012年是CNN首次實現Top 5誤差率15.4%的一年(Top 5誤差率是指給定一張圖像,其標簽不在模型認為最有可能的5個結果中的幾率),當時的次優項誤差率為26.2%。這個表現不用說震驚了整個計算機視覺界。可以說,是自那時起,CNN才成了家喻戶曉的名字。
論文中,作者討論了網絡的架構(名為AlexNet)。相比現代架構,他們使用了一種相對簡單的布局,整個網絡由5層卷積層組成,較大池化層、退出層(dropout layer)和3層全卷積層。網絡能夠對1000種潛在類別進行分類。
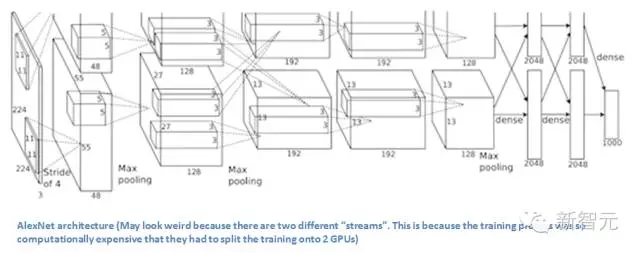
AlexNet 架構:看上去有些奇怪,因為使用了兩臺GPU訓練,因而有兩股“流”。使用兩臺GPU訓練的原因是計算量太大,只能拆開來。
要點
使用ImageNet數據訓練網絡,ImageNet數據庫含有1500多萬個帶標記的圖像,超過2.2萬個類別。
使用ReLU代替傳統正切函數引入非線性(ReLU比傳統正切函數快幾倍,縮短訓練時間)。
使用了圖像轉化(image translation)、水平反射(horizontal reflection)和補丁提取(patch extraction)這些數據增強技術。
用dropout層應對訓練數據過擬合的問題。
使用批處理隨機梯度下降訓練模型,注明動量衰減值和權重衰減值。
使用兩臺GTX 580 GPU,訓練了5到6天
為什么重要?
Krizhevsky、Sutskever 和 Hinton 2012年開發的這個神經網絡,是CNN在計算機視覺領域的一大亮相。這是史上第一次有模型在ImageNet 數據庫表現這么好,ImageNet 數據庫難度是出了名的。論文中提出的方法,比如數據增強和dropout,現在也在使用,這篇論文真正展示了CNN的優點,并且以破紀錄的比賽成績實打實地做支撐。
ZF Net(2013年)
2012年AlexNet出盡了風頭,ILSVRC 2013就有一大批CNN模型冒了出來。2013年的冠軍是紐約大學Matthew Zeiler 和 Rob Fergus設計的網絡 ZF Net,錯誤率 11.2%。ZF Net模型更像是AlexNet架構的微調優化版,但還是提出了有關優化性能的一些關鍵想法。還有一個原因,這篇論文寫得非常好,論文作者花了大量時間闡釋有關卷積神經網絡的直觀概念,展示了將濾波器和權重可視化的正確方法。
在這篇題為“Visualizing and Understanding Convolutional Neural Networks”的論文中,Zeiler和Fergus從大數據和GPU計算力讓人們重拾對CNN的興趣講起,討論了研究人員對模型內在機制知之甚少,一針見血地指出“發展更好的模型實際上是不斷試錯的過程”。雖然我們現在要比3年前知道得多一些了,但論文所提出的問題至今仍然存在!這篇論文的主要貢獻在于提出了一個比AlexNet稍微好一些的模型并給出了細節,還提供了一些制作可視化特征圖值得借鑒的方法。
要點
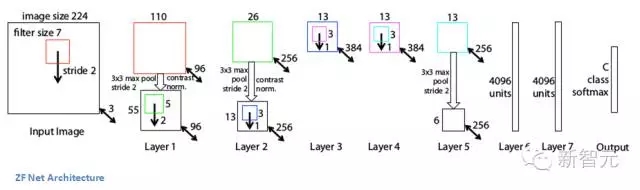
除了一些小的修改,整體架構非常類似AlexNet。
AlexNet訓練用了1500萬張圖片,而ZFNet只用了130萬張。
AlexNet在第一層中使用了大小為11×11的濾波器,而ZF使用的濾波器大小為7x7,整體處理速度也有所減慢。做此修改的原因是,對于輸入數據來說,第一層卷積層有助于保留大量的原始象素信息。11×11的濾波器漏掉了大量相關信息,特別是因為這是第一層卷積層。
隨著網絡增大,使用的濾波器數量增多。
利用ReLU的激活函數,將交叉熵代價函數作為誤差函數,使用批處理隨機梯度下降進行訓練。
使用一臺GTX 580 GPU訓練了12天。
開發可視化技術“解卷積網絡”(Deconvolutional Network),有助于檢查不同的特征激活和其對輸入空間關系。名字之所以稱為“deconvnet”,是因為它將特征映射到像素(與卷積層恰好相反)。
DeConvNet
DeConvNet工作的基本原理是,每層訓練過的CNN后面都連一層“deconvet”,它會提供一條返回圖像像素的路徑。輸入圖像進入CNN之后,每一層都計算激活。然而向前傳遞。現在,假設我們想知道第4層卷積層某個特征的激活值,我們將保存這個特征圖的激活值,并將這一層的其他激活值設為0,再將這張特征圖作為輸入送入deconvnet。Deconvnet與原來的CNN擁有同樣的濾波器。輸入經過一系列unpool(maxpooling倒過來),修正,對前一層進行過濾操作,直到輸入空間滿。
這一過程背后的邏輯在于,我們想要知道是激活某個特征圖的是什么結構。下面來看第一層和第二層的可視化。

ConvNet的第一層永遠是低層特征檢測器,在這里就是對簡單的邊緣、顏色進行檢測。第二層就有比較圓滑的特征了。再來看第三、第四和第五層。

這些層展示出了更多的高級特征,比如狗的臉和鮮花。值得一提的是,在第一層卷積層后面,我們通常會跟一個池化層將圖像縮小(比如將 32x32x32 變為16x16x3)。這樣做的效果是加寬了第二層看原始圖像的視野。更詳細的內容可以閱讀論文。
為什么重要?
ZF Net不僅是2013年比賽的冠軍,還對CNN的運作機制提供了極好的直觀信息,展示了更多提升性能的方法。論文所描述的可視化方法不僅有助于弄清CNN的內在機理,也為優化網絡架構提供了有用的信息。Deconv可視化方法和 occlusion 實驗也讓這篇論文成了我個人的最愛。
VGG Net(2015年)
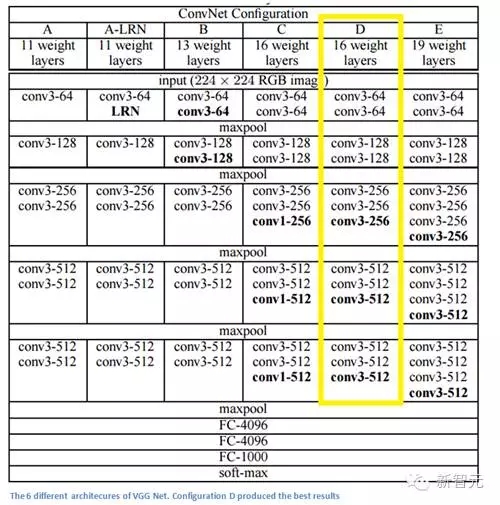
簡單、有深度,這就是2014年錯誤率7.3%的模型VGG Net(不是ILSVRC 2014冠軍)。牛津大學的Karen Simonyan 和 Andrew Zisserman Main Points創造了一個19層的CNN,嚴格使用3x3的過濾器(stride =1,pad= 1)和2x2 maxpooling層(stride =2)。簡單吧?
要點
這里使用3x3的濾波器和AlexNet在第一層使用11x11的濾波器和ZF Net 7x7的濾波器作用完全不同。作者認為兩個3x3的卷積層組合可以實現5x5的有效感受野。這就在保持濾波器尺寸較小的同時模擬了大型濾波器,減少了參數。此外,有兩個卷積層就能夠使用兩層ReLU。
3卷積層具有7x7的有效感受野。
每個maxpool層后濾波器的數量增加一倍。進一步加強了縮小空間尺寸,但保持深度增長的想法。
圖像分類和定位任務都運作良好。
使用Caffe工具包建模。
訓練中使用scale jittering的數據增強技術。
每層卷積層后使用ReLU層和批處理梯度下降訓練。
使用4臺英偉達Titan Black GPU訓練了兩到三周。
為什么重要?
在我看來,VGG Net是最重要的模型之一,因為它再次強調CNN必須夠深,視覺數據的層次化表示才有用。深的同時結構簡單。
GoogLeNet(2015年)
理解了我們剛才所說的神經網絡架構中的簡化的概念了嗎?通過推出 Inception 模型,谷歌從某種程度上把這一概念拋了出來。GoogLeNet是一個22層的卷積神經網絡,在2014年的ILSVRC2014上憑借6.7%的錯誤率進入Top 5。據我所知,這是第一個真正不使用通用方法的卷積神經網絡架構,傳統的卷積神經網絡的方法是簡單堆疊卷積層,然后把各層以序列結構堆積起來。論文的作者也強調,這種新的模型重點考慮了內存和能量消耗。這一點很重要,我自己也會經常忽略:把所有的層都堆疊、增加大量的濾波器,在計算和內存上消耗很大,過擬合的風險也會增加。
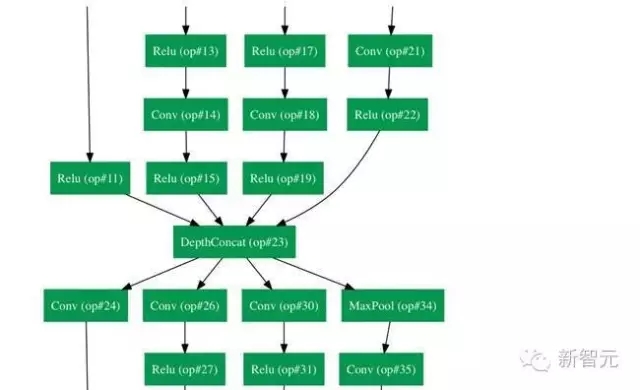
換一種方式看 GoogLeNet:
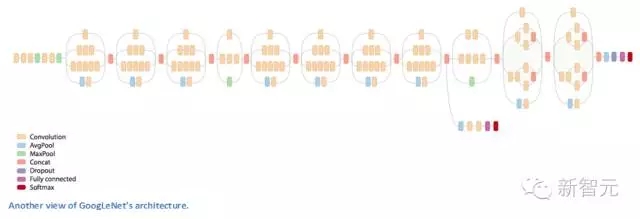
Inception 模型
第一次看到GoogLeNet的構造時,我們立刻注意到,并不是所有的事情都是按照順序進行的,這與此前看到的架構不一樣。我們有一些網絡,能同時并行發生反應。
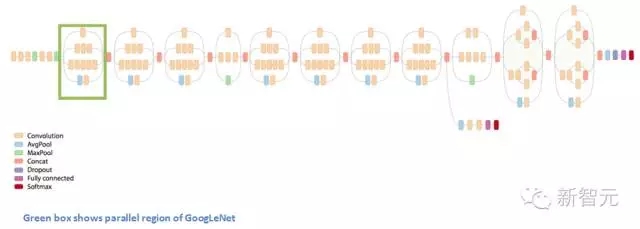
這個盒子被稱為 Inception 模型。可以近距離地看看它的構成。
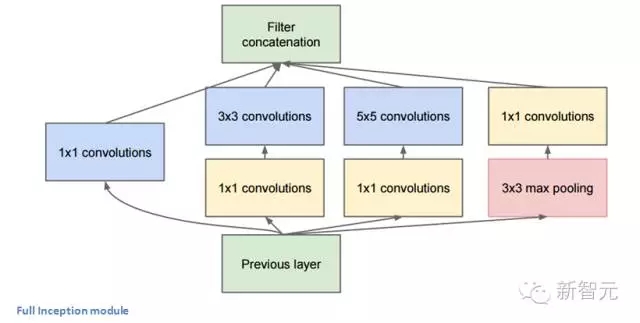
底部的綠色盒子是我們的輸入層,頂部的是輸出層(把這張圖片向右旋轉90度,你會看到跟展示了整個網絡的那張圖片相對應的模型)。基本上,在一個傳統的卷積網絡中的每一層中,你必須選擇操作池還是卷積操作(還要選擇濾波器的大小)。Inception 模型能讓你做到的就是并行地執行所有的操作。事實上,這就是作者構想出來的最“初始”的想法。

現在,來看看它為什么起作用。它會導向許多不同的結果,我們會最后會在輸出層體積上獲得極端大的深度通道。作者處理這個問題的方法是,在3X3和5X5層前,各自增加一個1X1的卷積操作。1X1的卷積(或者網絡層中的網絡),提供了一個減少維度的方法。比如,我們假設你擁有一個輸入層,體積是100x100x60(這并不定是圖像的三個維度,只是網絡中每一層的輸入)。增加20個1X1的卷積濾波器,會讓你把輸入的體積減小到100X100X20。這意味著,3X3層和5X5層不需要處理輸入層那么大的體積。這可以被認為是“池特征”(pooling of feature),因為我們正在減少體積的高度,這和使用常用的較大池化層(maxpooling layers)減少寬度和長度類似。另一個需要注意的是,這些1X1的卷積層后面跟著的是ReLU 單元,這肯定不會有害。
你也許會問,“這個架構有什么用?”這么說吧,這個模型由一個網絡層中的網絡、一個中等大小的過濾卷積、一個大型的過濾卷積、一個操作池(pooling operation)組成。網絡卷積層中的網絡能夠提取輸入體積中的每一個細節中的信息,同時 5x5 的濾波器也能夠覆蓋大部分接受層的的輸入,進而能提起其中的信息。你也可以進行一個池操作,以減少空間大小,降低過度擬合。在這些層之上,你在每一個卷積層后都有一個ReLU,這能改進網絡的非線性特征。基本上,網絡在執行這些基本的功能時,還能同時考慮計算的能力。這篇論文還提供了更高級別的推理,包括的主題有稀疏和緊密聯結(見論文第三和第四節)。
要點
整個架構中使用了9個Inception 模型,總共超過100層。這已經很深了……沒有使用完全連接的層。他們使用一個平均池代替,從 7x7x1024 的體積降到了 1x1x1024,這節省了大量的參數。比AlexNet的參數少了12X在測試中,相同圖像的多個剪裁建立,然后填到網絡中,計算softmax probabilities的均值,然后我們可以獲得最后的解決方案。在感知模型中,使用了R-CNN中的概念。Inception有一些升級的版本(版本6和7),“少數高端的GPU”一周內就能完成訓練。
為什么重要?
GoogLeNet 是第一個引入了“CNN 各層不需要一直都按順序堆疊”這一概念的模型。用Inception模型,作者展示了一個具有創造性的層次機構,能帶來性能和計算效率的提升。這篇論文確實為接下來幾年可能會見到的令人驚嘆的架構打下了基礎。
微軟 ResNet(2015年)
想象一個深度CNN架構,再深、再深、再深,估計都還沒有 ILSVRC 2015 冠軍,微軟的152層ResNet架構深。除了在層數上面創紀錄,ResNet 的錯誤率也低得驚人,達到了3.6%,人類都大約在5%~10%的水平。
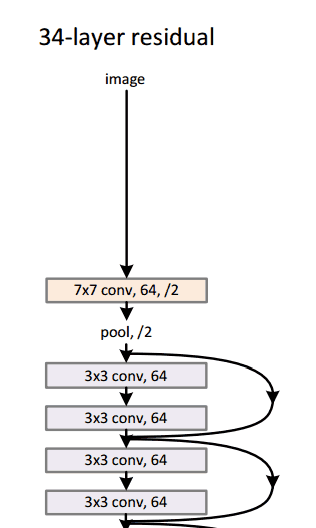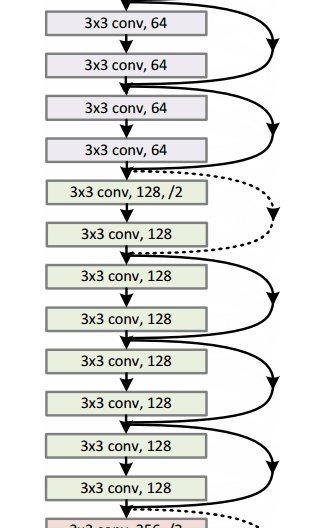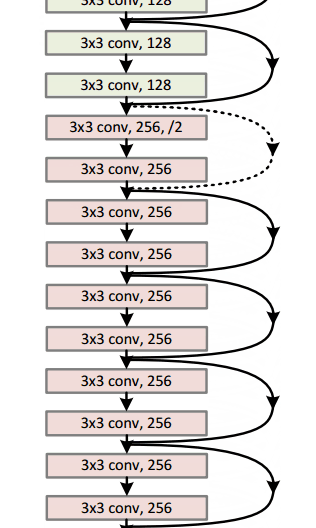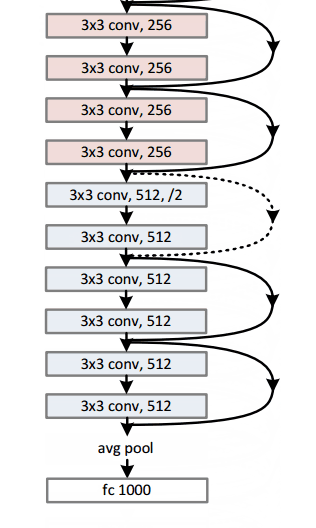
為什么重要?
只有3.6%的誤差率,這應該足以說服你。ResNet模型是目前較好的CNN架構,而且是殘差學習理念的一大創新。從2012年起,錯誤率逐年下降,我懷疑到ILSVRC2016,是否還會一直下降。我相信,我們現在堆放更多層將不會實現性能的大幅提升。我們必須要創造新的架構。
區域 CNN:R-CNN(2013年)、Fast R-CNN(2015年)、Faster R-CNN(2015年)
一些人可能會認為,R-CNN的出現比此前任何關于新的網絡架構的論文都有影響力。第一篇關于R-CNN的論文被引用了超過1600次。Ross Girshick 和他在UC Berkeley 的團隊在機器視覺上取得了最有影響力的進步。正如他們的文章所寫, Fast R-CNN 和 Faster R-CNN能夠讓模型變得更快,更好地適應現代的物體識別任務。?
R-CNN的目標是解決物體識別的難題。在獲得特定的一張圖像后, 我們希望能夠繪制圖像中所有物體的邊緣。這一過程可以分為兩個組成部分,一個是區域建議,另一個是分類。
論文的作者強調,任何分類不可知區域的建議方法都應該適用。Selective Search專用于RCNN。Selective Search 的作用是聚合2000個不同的區域,這些區域有較高的可能性會包含一個物體。在我們設計出一系列的區域建議之后,這些建議被匯合到一個圖像大小的區域,能被填入到經過訓練的CNN(論文中的例子是AlexNet),能為每一個區域提取出一個對應的特征。這個向量隨后被用于作為一個線性SVM的輸入,SVM經過了每一種類型和輸出分類訓練。向量還可以被填入到一個有邊界的回歸區域,獲得最精準的一致性。
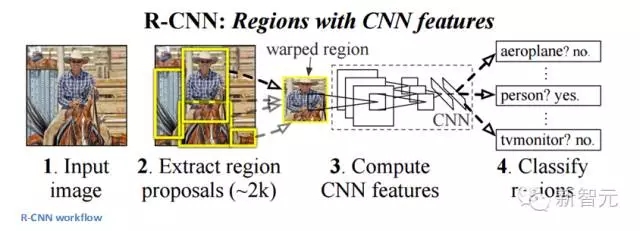
非極值壓抑后被用于壓制邊界區域,這些區域相互之間有很大的重復。
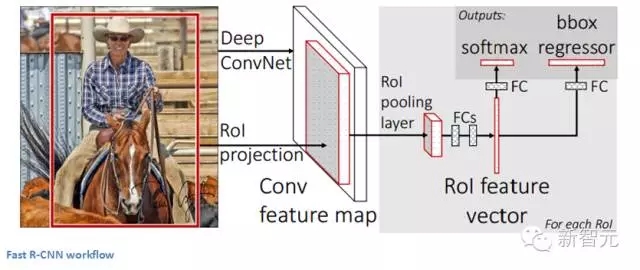
Fast R-CNN
原始模型得到了改進,主要有三個原因:訓練需要多個步驟,這在計算上成本過高,而且速度很慢。Fast R-CNN通過從根本上在不同的建議中分析卷積層的計算,同時打亂生成區域建議的順利以及運行CNN,能夠快速地解決問題。
Faster R-CNN
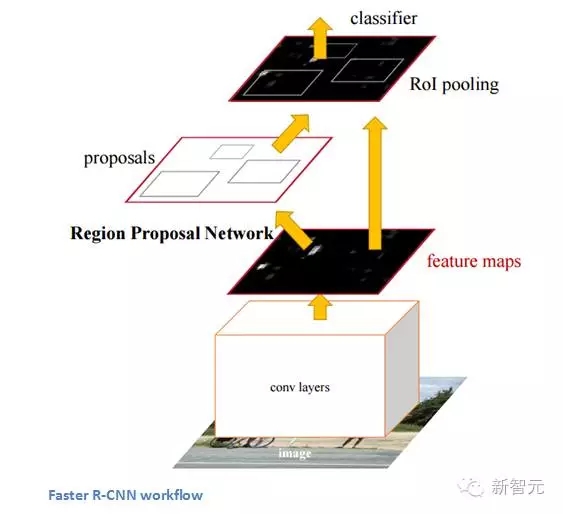
Faster R-CNN的工作是克服R-CNN和 Fast R-CNN所展示出來的,在訓練管道上的復雜性。作者 在最后一個卷積層上引入了一個區域建議網絡(RPN)。這一網絡能夠只看最后一層的特征就產出區域建議。從這一層面上來說,相同的R-CNN管道可用。
為什么重要?
能夠識別出一張圖像中的某一個物體是一方面,但是,能夠識別物體的較精確位置對于計算機知識來說是一個巨大的飛躍。更快的R-CNN已經成為今天標準的物體識別程序。
生成對抗網絡(2015年)
按照Yann LeCun的說法,生成對抗網絡可能就是深度學習下一個大突破。假設有兩個模型,一個生成模型,一個判別模型。判別模型的任務是決定某幅圖像是真實的(來自數據庫),還是機器生成的,而生成模型的任務則是生成能夠騙過判別模型的圖像。這兩個模型彼此就形成了“對抗”,發展下去最終會達到一個平衡,生成器生成的圖像與真實的圖像沒有區別,判別器無法區分兩者。

左邊一欄是數據庫里的圖像,也即真實的圖像,右邊一欄是機器生成的圖像,雖然肉眼看上去基本一樣,但在CNN看起來卻十分不同。
為什么重要?
聽上去很簡單,然而這是只有在理解了“數據內在表征”之后才能建立的模型,你能夠訓練網絡理解真實圖像和機器生成的圖像之間的區別。因此,這個模型也可以被用于CNN中做特征提取。此外,你還能用生成對抗模型制作以假亂真的圖片。
生成圖像描述(2014年)
把CNN和RNN結合在一起會發生什么?Andrej Karpathy 和李飛飛寫的這篇論文探討了結合CNN和雙向RNN生成不同圖像區域的自然語言描述問題。簡單說,這個模型能夠接收一張圖片,然后輸出

很神奇吧。傳統CNN,訓練數據中每幅圖像都有單一的一個標記。這篇論文描述的模型則是每幅圖像都帶有一句話(或圖說)。這種標記被稱為弱標記,使用這種訓練數據,一個深度神經網絡“推斷句子中的部分與其描述的區域之間的潛在對齊(latent alignment)”,另一個神經網絡將圖像作為輸入,生成文本的描述。
為什么重要?
使用看似不相關的RNN和CNN模型創造了一個十分有用的應用,將計算機視覺和自然語言處理結合在一起。這篇論文為如何建模處理跨領域任務提供了全新的思路。
空間轉換器網絡(2015年)
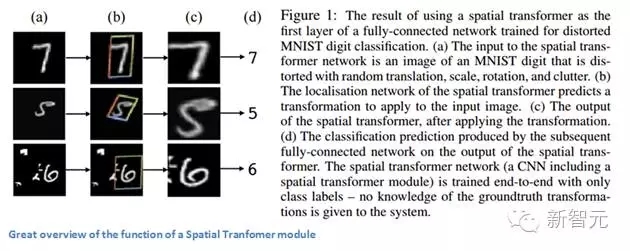
最后,讓我們來看該領域最近的一篇論文。本文是谷歌DeepMind的一個團隊在一年前寫的。這篇論文的主要貢獻是介紹了空間變換器(Spatial Transformer)模塊。基本思路是,這個模塊會轉變輸入圖像,使隨后的層可以更輕松地進行分類。作者試圖在圖像到達特定層前改變圖像,而不是更改主CNN架構本身。該模塊希望糾正兩件事:姿勢標準化(場景中物體傾斜或縮放)和空間注意力(在密集的圖像中將注意力集中到正確的物體)。對于傳統的CNN,如果你想使你的模型對于不同規格和旋轉的圖像都保持不變,那你需要大量的訓練樣本來使模型學習。讓我們來看看這個模塊是如何幫助解決這一問題。
?
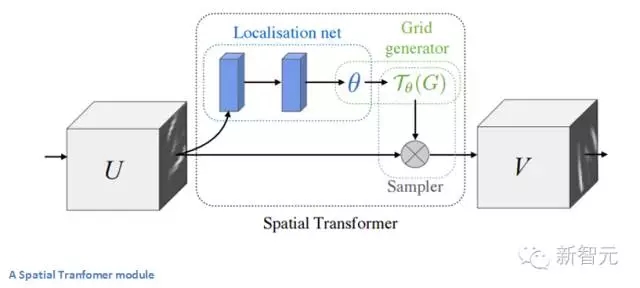
傳統CNN模型中,處理空間不變性的是maxpooling層。其原因是,一旦我們知道某個特定特性還是起始輸入量(有高激活值),它的確切位置就沒有它對其他特性的相對位置重要,其他功能一樣重要。這個新的空間變換器是動態的,它會對每個輸入圖像產生不同的行為(不同的扭曲/變形)。這不僅僅是像傳統 maxpool 那樣簡單和預定義。讓我們來看看這個模塊是如何工作的。該模塊包括:
一個本地化網絡,會吸收輸入量,并輸出應施加的空間變換的參數。參數可以是6維仿射變換。?
采樣網格,這是由卷曲規則網格和定位網絡中創建的仿射變換(theta)共同產生的。?
一個采樣器,其目的是執行輸入功能圖的翹曲。?
該模塊可以放入CNN的任何地方中,可以幫助網絡學習如何以在訓練過程中較大限度地減少成本函數的方式來變換特征圖。
為什么重要?
CNN的改進不一定要到通過網絡架構的大改變來實現。我們不需要創建下一個ResNet或者 Inception 模型。本文實現了對輸入圖像進行仿射變換的簡單的想法,以使模型對平移,縮放和旋轉保持不變。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4409.html
摘要:年,發表,至今,深度學習已經發展了十幾年了。年的結構圖圖片來自于論文基于圖像識別的深度卷積神經網絡這篇文章被稱為深度學習的開山之作。還首次提出了使用降層和數據增強來解決過度匹配的問題,對于誤差率的降低至關重要。 1998年,Yann LeCun 發表Gradient-Based Learning Applied to Document Recognition,至今,深度學習已經發展了十幾年了...
摘要:年月日,將標志著一個時代的終結。數據集最初由斯坦福大學李飛飛等人在的一篇論文中推出,并被用于替代數據集后者在數據規模和多樣性上都不如和數據集在標準化上不如。從年一個專注于圖像分類的數據集,也是李飛飛開創的。 2017 年 7 月 26 日,將標志著一個時代的終結。那一天,與計算機視覺頂會 CVPR 2017 同期舉行的 Workshop——超越 ILSVRC(Beyond ImageNet ...
摘要:一時之間,深度學習備受追捧。百度等等公司紛紛開始大量的投入深度學習的應用研究。極驗驗證就是將深度學習應用于網絡安全防御,通過深度學習建模學習人類與機器的行為特征,來區別人與機器,防止惡意程序對網站進行垃圾注冊,撞庫登錄等。 2006年Geoffery ?Hinton提出了深度學習(多層神經網絡),并在2012年的ImageNet競賽中有非凡的表現,以15.3%的Top-5錯誤率奪魁,比利用傳...
摘要:近幾年以卷積神經網絡有什么問題為主題做了多場報道,提出了他的計劃。最初提出就成為了人工智能火熱的研究方向。展現了和玻爾茲曼分布間驚人的聯系其在論文中多次稱,其背后的內涵引人遐想。 Hinton 以深度學習之父 和 神經網絡先驅 聞名于世,其對深度學習及神經網絡的諸多核心算法和結構(包括深度學習這個名稱本身,反向傳播算法,受限玻爾茲曼機,深度置信網絡,對比散度算法,ReLU激活單元,Dropo...
摘要:深度學習推動領域發展的新引擎圖擁有記憶能力最早是提出用來解決圖像識別的問題的一種深度神經網絡。深度學習推動領域發展的新引擎圖深度神經網絡最近相關的改進模型也被用于領域。 從2015年ACL會議的論文可以看出,目前NLP最流行的方法還是機器學習尤其是深度學習,所以本文會從深度神經網絡的角度分析目前NLP研究的熱點和未來的發展方向。我們主要關注Word Embedding、RNN/LSTM/CN...

閱讀 633·2021-11-24 09:39
閱讀 3478·2019-08-30 15:53
閱讀 2509·2019-08-30 15:44
閱讀 3237·2019-08-30 12:54
閱讀 2206·2019-08-29 12:23
閱讀 3304·2019-08-26 14:05
閱讀 2101·2019-08-26 13:36
閱讀 3429·2019-08-26 13:33






