資訊專欄INFORMATION COLUMN

摘要:近幾年以卷積神經網絡有什么問題為主題做了多場報道,提出了他的計劃。最初提出就成為了人工智能火熱的研究方向。展現了和玻爾茲曼分布間驚人的聯系其在論文中多次稱,其背后的內涵引人遐想。
Hinton 以“深度學習之父” 和 “神經網絡先驅” 聞名于世,其對深度學習及神經網絡的諸多核心算法和結構(包括“深度學習”這個名稱本身,反向傳播算法,受限玻爾茲曼機,深度置信網絡,對比散度算法,ReLU激活單元,Dropout防止過擬合,以及深度學習早期在語音方面突破)做出了基礎性的貢獻。盡管已經將大半輩子的時間投入到神經網絡之上,這位老人卻絲毫沒有想退休的意思。
Hinton 近幾年以 “卷積神經網絡有什么問題?” 為主題做了多場報道 [1] [2],提出了他的 Capsule 計劃。Hinton似乎毫不掩飾要推翻自己盼了30多年時間才建立起來的深度學習帝國的想法 [3]。他的這種精神也獲得了同行李飛飛(ImageNet創始者)等人肯定 [4]。
Hinton 為什么突然想要推倒重來?這肯定不是出于巧合或者突然心血來潮,畢竟作為一個領域的先驅,質疑自己親手建立的理論,不是誰都愿意做的事情。(試想一下,如果你到處做報告,說自己的領域有各種各樣的問題,就算不會影響到自己,也讓做這個領域的同行和靠這個領域吃飯的人不是很舒服)
說推倒重來有點過分,Hinton并沒有否定一切,并且他的主要攻擊目標是深度學習在計算機視覺方面的理論。但是從幾次演講來看,他的 Capsule 計劃確實和以前的方法出入比較大。Hinton 演講比較風趣,但是也存在思維跳躍,難度跨度太大等問題。這些問題在他的關于 Capsule 的報告中還是比較突出的。可以說僅僅看報告很難理解完全 Hinton 的想法。我這幾天結合各類資料,整理了一下 Hinton 的思路和動機,和大家分享一下。
Hinton 與神經網絡
(以下用NN指代人工神經網絡,CNN指代(深度)卷積神經網絡,DNN指代深度神經網絡)
要深入理解Hinton的想法,就必須了解神經網絡發展的歷史,這也幾乎是Hinton的學術史。
人工智能才起步的時候,科學家們很自然的會有模擬人腦的想法(被稱為連接主義),因為人腦是我們知道的擁有高級智能的實體。
NN 起源于對神經系統的模擬,最早的形式是感知機,學習方法是神經學習理論中著名的 Hebb"s rule 。NN最初提出就成為了人工智能火熱的研究方向。不過 Hebb"s rule 只能訓練單層NN,而單層NN甚至連簡單的“異或”邏輯都不能學會,而多層神經網絡的訓練仍然看不到希望,這導致了NN的第一個冬天。
Hinton 意識到,人工神經網絡不必非要按照生物的路子走。在上世紀80年代, Hinton 和 LeCun 奠定和推廣了可以用來訓練多層神經網絡的反向傳播算法(back-propagation)。NN再次迎來了春天。
反向傳播算法,說白了就是一套快速求目標函數梯度的算法。
對于最基本的梯度下降(Gradient Descent):

不過在那時,NN就埋下了禍根。
首先是,反向傳播算法在生物學上很難成立,很難相信神經系統能夠自動形成與正向傳播對應的反向傳播結構(這需要精準地求導數,對矩陣轉置,利用鏈式法則,并且解剖學上從來也沒有發現這樣的系統存在的證據)。反向傳播算法更像是僅僅為了訓練多層NN而發展的算法。失去了生物學支持的NN無疑少了很多底氣,一旦遇到問題,人們完全有更多理由拋棄它(歷史上上也是如此)
其次是,反向傳播算法需要SGD等方式進行優化,這是個高度非凸的問題,其數學性質是堪憂的,而且依賴精細調參。相比之下,(當時的)后起之秀SVM等等使用了凸優化技術,這些都是讓人們遠離NN的拉力。當那時候的人們認為DNN的訓練沒有希望(當時反向傳播只能訓練淺層網絡)的時候,NN再次走向低谷。
深度學習時代的敲門磚——RBM
第二次NN低谷期間,Hinton沒有放棄,轉而點了另外一個科技樹:熱力學統計模型。
Hinton由玻爾茲曼統計相關的知識,結合馬爾科夫隨機場等圖學習理論,為神經網絡找到了一個新的模型:玻爾茲曼機(BM)。Hinton用能量函數來描述NN的一些特性,期望這樣可以帶來更多的統計學支持。
不久Hinton發現,多層神經網絡可以被描述為玻爾茲曼機的一種特例——受限玻爾茲曼機(RBM)。Hinton 在 Andrew Ng 近期對他的采訪中 (https://www.youtube.com/watch?v=-eyhCTvrEtE),稱其為 "most beautiful work I did"。
當年我第一次看到 RBM 的相關數學理論的時候,真的非常激動,覺得這樣的理論不work有點說不過去。這里我給出相關的數學公式,以展示NN可以有完全不同于生物的詮釋方式。
在統計力學中,玻爾茲曼分布(或稱吉布斯分布)可以用來描述量子體系的量子態的分布,有著以下的形式:


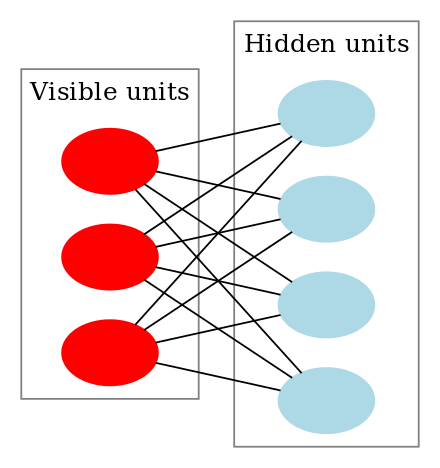
(RBM示意圖,取自Wikipedia)

這個形式讓人驚訝之處在于,在沒有浪費任何一個NN中的參量的情況下做到了最簡,并且非常合理的直覺:神經元的偏置只和神經元本身通過乘法直接相關,而兩個神經元間的權重也只和對應的兩個神經元通過乘法直接相關,而整體的貢獻用加法聯系起來。

這不就是sigmoid函數嗎?也就是

總之一切看上去都很有道理。Hinton展現了NN和玻爾茲曼分布間驚人的聯系(其在論文中多次稱 surprisingly simple [7]),其背后的內涵引人遐想。甚至有人在聽過Hinton的講座之后,還發現RBM的訓練模式和量子重整化群的重整化步驟是同構的 [6]。

Hinton 發現用這個粗糙的算法預訓練網絡(這個時候是無監督學習,也就是只需要數據,不需要標簽;在下面會提到)后,就可以通過調優(加上標簽,使用反向傳播繼續訓練,或者干脆直接在后面接個新的分類器)高效且穩定地訓練深層神經網絡。
之后“深度學習”這個詞逐漸走上歷史的前臺,雖然 1986年就有這個概念了 [8]。可以說 RBM 是這一波人工智能浪潮的先行者。
這讓人想起另外一個相當粗糙但是甚至更加成功的算法——SGD。可以說,利用梯度的算法 中很難有比SGD還簡單的了,但是SGD(加上動量后)效果確實特別好。非常粗糙的算法為何卻對NN的優化這種非常復雜的問題很有效,這仍然是一個非常有趣的開放問題。
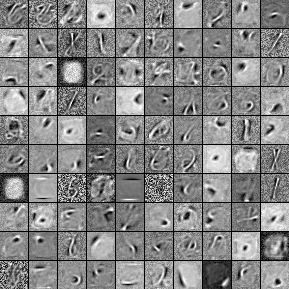
由于玻爾茲曼機本身的特性,其可以被用來解決“無監督學習”(Unsupervised learning)相關的問題。即使沒有標簽,網絡也可以自己學會一些良好的表示,比如下面是從MNIST數據集中學到的表示:
當我們將人類智能,和目前的人工智障對比時,常常舉的例子就是“現在機器學習依賴大數據,而人類的學習卻是相反的,依賴小數據”。這個說法其實不盡準確。人類擁有太多的感知器官,無時無刻不接收著巨量的數據:就按人眼的分辨率而言,目前幾乎沒有什么實際的機器學習模型模型使用如此高清晰度的數據進行訓練的。我們觀察一個東西的時候,所有的知覺都潛移默化地給我們灌輸海量的數據,供我們學習,推理,判斷。我們所謂的“小數據”,實際上主要分為兩個部分:
少標簽。我們遇到的“題目”很多,我們無時無刻不在接受信息;但是我們的“答案”很少,我們可能看過各種各樣的人,各種各樣的動物,直到某一天才有人用3個字告訴我們,“這是貓”。可能一生中,別人給你指出這是貓的次數,都是屈指可數的。但是,僅僅通過這一兩次提示(相當于一兩個標簽),你就能在一生中記得這些概念。甚至別人從不告訴這是貓,你也知道這應該不是狗或者其他動物。這種“沒有答案”的學習稱為 “無監督學習”(Yann LeCun將其比作蛋糕胚,以示其基礎性的作用),目前機器學習在無監督學習方面進展很少。
邏輯推斷,因果分析。也可以說是少證據。如果你看過探案相關的小說,那些偵探,能從非常細微的證據中,得出完整的邏輯鏈;現實中,愛因斯坦等物理學家能夠從非常少的幾點假設構建出整套物理學框架。最早的人工智能研究很多集中在類似的方面(流派被稱為“符號主義”),但是事實證明這些研究大多數很難應用到實際問題中。現在NN為人所詬病的方面之一就是很難解決邏輯問題,以及因果推斷相關的問題(不過最近有些進步,比如在視覺問答VQA方面)

(Yann LeCun的蛋糕,來自網絡上公開的Yann LeCun PPT的圖片)
無監督學習和先驗知識
這是為了幫助理解而在中間插入的一小節。這一小節強調先驗知識對無監督學習的重要性,這有助于理解后面為什么Hinton要強行把所謂“坐標框架”體現在模型中,因為“坐標框架”就是一種先驗知識,而且是從認知神經科學中總結的先驗知識。
無監督學習是一種沒有答案的學習。很關鍵的一點是,沒有答案怎么學?
子曰:學而不思則罔,思而不學則殆。無監督學習就像一個“思而不學”(這里的“學”是指學習書本(即較直接答案),不是指廣義的學習)的學生。顯然這個學生如果沒有正確的思路和指導方向,自己一直憑空想下去,八成會變成一個瘋狂級的黑暗民科。
這個“思路和指導方向”就是我們的先驗知識。先驗知識并沒有限定思考的范圍,但是卻給出了一些“建議的方向”。這對有監督和無監督學習都很重要,但是可能對無監督更加關鍵。
我們可以回顧一下為什么同為神經網絡,CNN在圖像,甚至語音等領域全方面碾壓那種“簡單”的密連接網絡(參數少,訓練快,得分高,易遷移)?
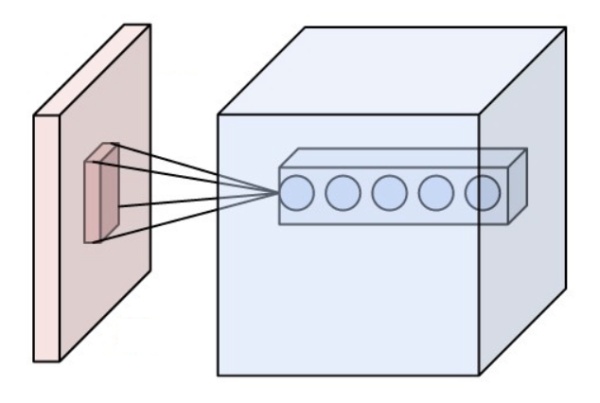
(CNN示意圖,來自Wikipedia)
顯然CNN有一個很強的先驗關系:局部性。它非常在意局部的關系,以及從局部到整體的過渡。

(AlphaGo中使用CNN提取圍棋的特征,取自 DeepMind 關于 AlphaGo的論文 )
這在圍棋中也非常明顯,使用CNN的AlphaGo能夠“看清”局部的關系,同時能夠有很好的大局觀。
而換一個領域,Kaggle 比如上面表格數據的學習,CNN就差多了,這時候勝出往往是各種集成方法,比如 Gradient Boosting 和 Random Forest。因為這些數據很少有局部關聯。
無監督領域比較成熟的算法大多是聚類算法,比如 k-Means 等等。
這些算法聚類顯著的特點是強調空間相關的先驗,認為比較靠近的是一類。

(圖為兩個不同的聚類算法的效果,取自Wikipedia k-Means頁面)
然而即使如此,兩個聚類算法的不同的先驗知識仍然導致不同的結果。上面圖中,k-Means的先驗更強調cluster的大小均勻性(損失是聚類中心到類成員的距離平方),因此有大而平均的聚類簇;而高斯EM聚類則更強調密集性(損失是中心到成員的距離的指數),因此有大小不一但是密集的聚類簇。(大多數人更加偏向EM的結果,這大多是因為我們對米老鼠的,或者對動物頭部的先驗知識,希望能夠分出“耳朵”和“臉”)
人的先驗知識是我們最關心的,這可能是AI的核心。近期有不少RL(強化學習)方面的論文試圖探究這一點。比如下面的這篇論文試圖建模關于“好奇心”的先驗知識,鼓勵模型自己探究特殊之處,還是有一些奇效的。
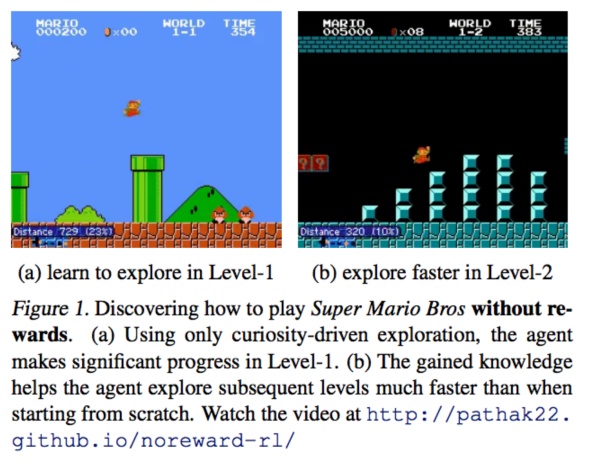
(圖片取自論文 Curiosity-driven Exploration by Self-supervised Prediction)
后面我們會看到 Hinton 通過認知科學和圖形學總結出來的一些先驗知識,以及他如何將這些先驗知識加入到模型中去。
反向傳播,它就是有效
不過不久,人們發現,使用ReLU以及合適的初始化方法,用上CNN,搭配上強勁的GPU之后,發現原來的深度神經網絡可以照常訓練,根本不用RBM預訓練。RBM雖然數學上很漂亮,但是受結構限制嚴重,而且在supervised learning方面往往搞不過直接暴力反向傳播。前幾年Andrew Y. Ng在Google讓神經網絡自動檢測視頻中的貓的時候,Google內部的深度學習框架幾乎就是用來支持RBM等的訓練的。而現在Google開源的TensorFlow等主流框架中都沒有RBM的影子。很多從TensorFlow入手的新人估計也沒有聽過RBM。
好了,現在除了各種小修小改(殘差網絡,Adam優化器,ReLU,Batchnorm,Dropout,GRU,和稍微創意點的GAN),神經網絡訓練主流算法又回到了30年前(那個時候CNN,LSTM已經有了)的反向傳播了。
目前來看,很多對 NN 的貢獻(特別是核心的貢獻),都在于NN的梯度流上,比如
sigmoid會飽和,造成梯度消失。于是有了ReLU。
ReLU負半軸是死區,造成梯度變0。于是有了LeakyReLU,PReLU。
強調梯度和權值分布的穩定性,由此有了ELU,以及較新的SELU。
太深了,梯度傳不下去,于是有了highway。
干脆連highway的參數都不要,直接變殘差,于是有了ResNet。
強行穩定參數的均值和方差,于是有了BatchNorm。
在梯度流中增加噪聲,于是有了 Dropout。
RNN梯度不穩定,于是加幾個通路和門控,于是有了LSTM。
LSTM簡化一下,有了GRU。
GAN的JS散度有問題,會導致梯度消失或無效,于是有了WGAN。
WGAN對梯度的clip有問題,于是有了WGAN-GP。
說到底,相對于8,90年代(已經有了CNN,LSTM,以及反向傳播算法),沒有特別本質的改變。
但是為什么當前這種方式實際效果很好?我想主要有:
全參數優化,end-to-end。反向傳播(下面用BP代替)可以同時優化所有的參數,而不像一些逐層優化的算法,下層的優化不依賴上層,為了充分利用所有權值,所以最終還是要用BP來fine-tuning;也不像隨機森林等集成算法,有相對分立的參數。很多論文都顯示end-to-end的系統效果會更好。
形狀靈活。幾乎什么形狀的NN都可以用BP訓練,可以搞CNN,可以搞LSTM,可以變成雙向的 Bi-LSTM,可以加Attention,可以加殘差,可以做成DCGAN那種金字塔形的,或者搞出Inception那種復雜的結構。如果某個結構對NN很有利,那么就可以隨便加進去;將訓練好的部分加入到另一個NN中也是非常方便的事情。這樣隨著時間推進,NN結構會被人工優化得越來越好。BP的要求非常低:只要連續,就可以像一根導線一樣傳遞梯度;即使不連續,大部分也可以歸結為離散的強化學習問題來提供Loss。這也導致了大量NN框架的誕生,因為框架制作者知道,這些框架可以用于所有需要計算圖的問題(就像萬能引擎),應用非常廣泛,大部分問題都可以在框架內部解決,所以有必要制作。
計算高效。BP要求的計算絕大多數都是張量操作,GPU跑起來賊快,并且NN的計算圖的形式天生適合分布式計算;而且有大量的開源框架以及大公司的支持。
神經解剖學與 Capsule 的由來
不過 Hinton 看上去是不會對目前這種結果滿意的。他在2011年的時候,就第一次提出了Capsule 結構[9](我們會在后面解釋Capsule是什么)。不過那次Hinton打擂顯然沒有成功。
Hinton最近抓住了NN中最成功的CNN批判了一番,又重新提出了Capsule 結構。可以明確的是,Hinton 受到了下面3個領域的啟示:
神經解剖學
認知神經科學
計算機圖形學
其中前兩者明顯是和人腦相關的。可能不少讀者都有疑問:NN非要按照生物的路子走嗎?
回答是:看情況。
對于人腦中存在的結構和現象,可以從不同的觀點看待:
這是生物基礎導致的妥協,是進化的累贅。由于細胞構成的生物系統難以完成某些特定任務,而以實質上非常低效的方式勉強實現。這時候不模仿人腦是正確的。典型的例子是算術計算以及數據存儲。生物結構很難進化出較精確的運算元件,以及大容量的存儲元件,并且讓它們能以GHz量級的頻率持續工作。我們只能用高層的、抽象的方式進行不保證精準的運算、記憶,這大大慢于當代的計算機,也沒有計算機準確。比如知乎上這個問題 比特幣挖礦一定要用計算機嗎?用紙筆來計算可行嗎?,有很多折疊的回答是“這孩子能用來做顯卡”。雖然這些回答有侵犯性,但是確實足以說明這些方面生物結構的顯著弱勢。
這是演化中的中性功能。進化只要求“夠用”,而不是“較好”。有些人腦的結構和功能也許可以被完全不同的實現方式替代。這里的一個例子是 AlphaGo 下圍棋。圍棋高手能夠把圍棋下的很好,但是普通人不能。下圍棋確乎關系到人的直覺,但是這種直覺不是強制的,也不是先天的:不會下圍棋不意味著會在進化中淘汰,人腦中也沒有專用的“圍棋模塊”。這個時候,我們可以設計一個和人腦機制差異很大的系統,比如AlphaGo,它可以下得比人還要好。
這是演化中的重大突破,這些功能造就了我們“人”的存在。比如人的各類感知系統,人的因果分析系統,學習系統,規劃系統,運動控制系統。這些是人工智能尚且欠缺的。
不過首要問題是,我們怎么知道某個人腦的功能或者結構屬于上面的第3點呢?按照上面的觀點,顯然生物的某個結構和功能本身的出現不能說明它很有用。我們需要更多證據。
一個重要的統計學證據是普遍性。我們為什么會有拿NN做AI的想法?因為NN本身正是生物進化中的重大突破,凡是有NN的生物中,我們都發現NN對其行為調控起了關鍵性作用,尤其是人類。這也是我們如今愿意相信它的理由,而不只是因為人有一個大腦,所以我們就必須搞一個(就像我們不給AI做肝臟一樣)。
人的實際神經系統是有分層的(比如視覺系統有V1, V2等等分層),但是層數不可能像現在的大型神經網絡(特別是ResNet之后)一樣動不動就成百上千層(而且生物學上也不支持如此,神經傳導速度很慢,不像用GPU計算神經網絡一層可能在微秒量級,生物系統傳導一次一般在ms量級,這么多層數不可能支持我們現在這樣的反應速度,并且同步也存在問題)。
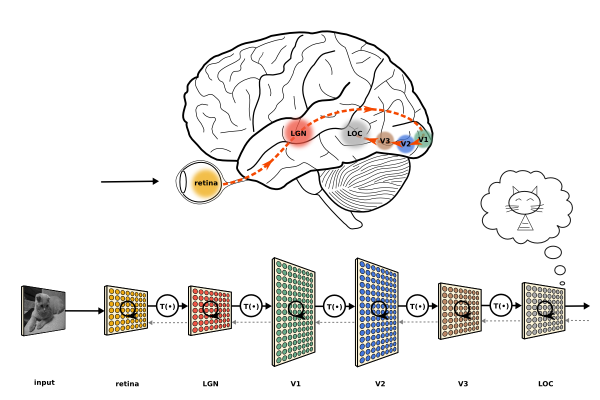
(將人腦視覺通路分層和DNN分層的類比。Image (c) Jonas Kubilias)
Hinton 注意到的一個有趣的事實是,目前大多數神經解剖學研究都支持(大部分哺乳類,特別是靈長類)大腦皮層中大量存在稱為 Cortical minicolumn 的柱狀結構(皮層微柱),其內部含有上百個神經元,并存在內部分層。這意味著人腦中的一層并不是類似現在NN的一層,而是有復雜的內部結構。

(mini-column 圖片,引自 minicolumn hypothesis in neuroscience | Brain | Oxford Academic)
為什么大腦皮層中普遍存在 mini-column?這顯然是一個重要的統計學證據,讓 Hinton 愿意相信 mini-column 肯定起了什么作用。于是 Hinton 也提出了一個對應的結構,稱為 capsule (膠囊,和微柱對應)。這就是 capsule 的由來。
但是 capsule 做了什么?之前的CNN又有什么問題?統計學證據不能給出這些的答案。Hinton的這部分答案來自認知神經科學。
認知神經科學和“沒有免費的午餐”
每一個機器學習的初學者都應該了解關于機器學習的重要定律——“沒有免費的午餐”[10]
這個可以通過科幻小說《三體》里面的提到一個例子來理解:
“農場主假說”則有一層令人不安的恐怖色彩:一個農場里有一群火雞,農場主每天中午十一點來給它們喂食。火雞中的一名科學家觀察這個現象,一直觀察了近一年都沒有例外,于是它也發現了自己宇宙中的偉大定律:“每天上午十一點,就有食物降臨。”它在感恩節早晨向火雞們公布了這個定律,但這天上午十一點食物沒有降臨,農場主進來把它們都捉去殺了。
在這個例子中,問題是,火雞愚蠢嗎?
觀點1:火雞很聰明。它能夠發現和總結規律。只不過它在農場很不走運。
觀點2:火雞很愚蠢。無論如何,它沒有能夠讓自己逃脫死亡的命運。而且正是它自己得到的“規律”將它們送上死亡之路。
觀點2就是“沒有免費的午餐”。這是在“數學現實”中成立的,在“數學現實”中,一切可能性都存在,感恩節那天,火雞有可能被殺,也有可能被農場主的孩子當成寵物,也有可能農場主決定把一部分雞再養一年然后殺掉。雞無論做出怎樣的猜想都可能落空。可以證明,無論我們學習到了什么東西,或者掌握到了什么規律,我們總是可以(在數學上)構造一個反例(比如,讓太陽從西邊升起,讓黃金變成泥土),與我們的判斷不一致。這不管對于機器,而是對于人,都是一樣的。也就是在“一般“的意義上,或者數學的意義上,沒有哪個生物,或者哪個算法,在預測能力上比瞎猜更好。
而看似矛盾的觀點1,卻在物理現實中得以成立。可以說,物理定律是一部分不能用數學證明的真理。我們相信這些定律,一是因為我們尚且沒有發現違背的情況,二是某種直覺告訴我們它很可能是對的。為什么我們能總結出這些定律,這是一個讓人困惑的問題,因為看起來人并不是先天就能總結出各種定律。但是可以確定的是,我們本身就是定律約束下進化的產物,雖然對物理定律的理解不是我們的本能,但是很多“準定律”已然成為我們的本能,它們塑造了我們本能的思考問題的方式,對對稱性的理解,等等等等。
現實中的情況介于觀點1和觀點2之間。很多東西既不是完全沒有規律,也不是一種物理定律,但是對我們的進化和存活意義重大(也就是上面說的“準定律”),它們是一種非常強的“先驗分布”,或者說,是我們的常識,而且我們通常情況下意識不到這種常識。
既然不是物理定律,那么按照觀點2,我們就能夠找到一些反例。這些反例對我們來說是某種“錯誤”,這種錯誤正是非常非常強的證據。理由是,我們很少出錯(指認知和腦功能上的出錯)。人腦是個黑盒,在絕大多數時候都工作正常,我們從中獲得的信息量很小。但是一旦出錯,就能給予我們很大的信息量,因為我們得以有機會觀察到一些奇特的現象,好似百年一遇的日全食一般。很多神經科學上面的發現都建立在錯誤之上(比如腦損傷導致了語言區的發現,以及左右腦功能的確認等等)。它揭示了一些我們的本能,或者我們習得的先驗知識。
根據上文所述,這種先驗知識,對于機器學習,尤其是無監督學習,是極度重要的。
而認知神經科學就可以通過一些實驗揭示出這些錯誤。下面給出一些例子:
第一個例子是下面的人臉:
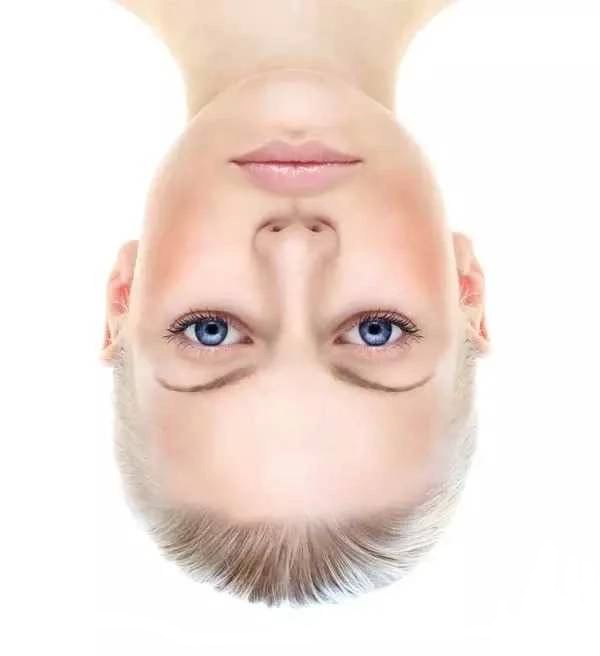
這個人是什么樣的表情?倒過來再看看?
這個例子說明了人對倒過來的人臉的表情的識別能力很差。長期的進化過程中,我們對正著的人臉造成了“過擬合”,“正著”的信息變得不是很重要。上面的圖出現錯覺的原因是,雖然人臉是倒著的,我們卻用“正著”的思路觀察圖片中眼睛,而眼睛的線條走向給了我們表情信息:
(甚至一些簡單的線條,都會讓我們覺得是人臉,并且得出它的表情。其中眼睛和嘴的線條在我們表情識別中起了重要作用)

這啟示我們,人類識別臉,其實就是通過幾個關鍵的結構(眼睛,眉毛,嘴,鼻子)完成的。當今很多算法都模仿這一點,標注出人臉的關鍵結構,成功率很高。
另外人對臉的形狀過擬合,也讓我們看二次元中動畫人物的臉時覺得很正常,實際上這和真實的臉差異很大,但是我們大腦不這么認為,因為這種識別機制已經成為了我們的本能。
第二個例子是這個錯覺圖:

(圖片取自 Wikipedia)
很難想象,A和B的顏色居然是一樣的。

造成這個錯覺的原因是,對了對應自然界中陰影對顏色識別的副作用,我們大腦擅自“減去”了陰影對顏色的影響。在進化中,我們正如火雞一樣,覺得“每天上午十一點,就有食物降臨”;同樣的,我們覺得“把陰影對顏色的干擾消除掉,就能識別得更好”,這成為了我們的“準定律”。然而,上面的錯覺圖中,要求我們比較A和B的顏色,就好似感恩節對火雞一樣,我們大腦仍然不聽話地擅自改變顏色,導致我們在這個極其特殊的問題上判斷失誤。只不過這個失誤不導致什么后果罷了,當然如果外星人打算利用這個失誤作為我們的弱點來對付我們,那就是另外一種劇情。
下面這個圖片是更加極端的情況。中間的條帶其實沒有漸變。

第三個錯覺是關于線條的:
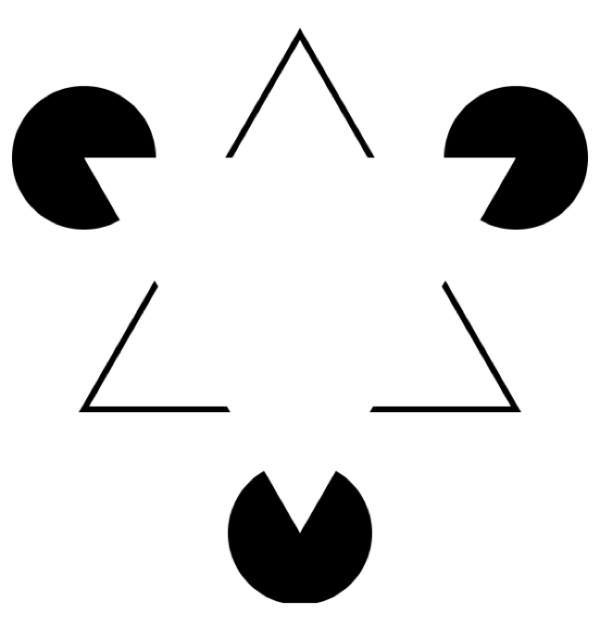
人類會不由自主的覺得中間似乎有個白色三角形,因為我們大腦“騙”我們,讓我們覺得似乎有一些“看不見的邊”。
把效果變得更夸張一點:

按照一定距離觀察這幅圖,會讓我們覺得產生了“纏繞”或者“扭曲”。實際上這些就是一個個同心圓。產生錯覺的原因是,大腦給我們“腦補”了很多傾斜邊(這些方塊是傾斜的,并且采用了不同的顏色加強邊的效果),這些邊的形狀不同于它們的排列方向,因此會覺得“纏繞”。如果我們到了這樣的圖案居多的世界中,我們的現在視覺系統將難以正常工作。
我們生活中的絕大多數物體,都有著明確的邊界。這不是一個物理定律,但是就其普遍性而言,足夠成為一個“準定律”。以至于人和動物的大腦視覺皮層擁有專門識別邊的結構:
CNN 被認為在生物學上收到支持的原因之一,在于能夠通過學習自動得到邊緣等特征的filter(非常像所謂的 Gabor filter):

CNN成功之處在于能夠非常成功的抽取到圖像的特征。這在 Neural Style 項目的風格遷移(原圖+風格->帶風格的原圖)中表現得非常好:

人類的這些錯覺同時也暗示了人類和算法模型一樣受“沒有免費午餐定理”的限制,人的認知并沒有特別異于算法的地方,或許是可以被算法復現的。
Hinton 從認知神經科學中得到的反對CNN的理由
說 Hinton 是一個認知神經科學家并沒有問題。Hinton做過不少認知實驗,也在認知科學領域發過不少論文。
Hinton自己也承認,CNN做的非常好。但是當Hinton做了一系列認知神經科學的試驗后,HInton 覺得有些動搖,直至他現在反對CNN。
第一個實驗稱為四面體謎題(tetrahedron puzzle),也是 Hinton 認為最有說服力的實驗。
如圖,有兩個全等的簡單積木,要求你把它們拼成一個正四面體(不要看答案,先自己試試)。

這理應是個非常非常簡單的問題,對于類似的問題,人們平均能在5秒內解決。但是Hinton 驚訝的發現,對于這個問題人們平均解決的時間超乎意料的長,往往要幾十秒甚至幾分鐘。

(視頻中Hinton親自演示這個實驗的樣子很有趣,取自Youtube[2])
Hinton 此處狂黑MIT,說MIT教授解決這個問題的分鐘數和和他們在MIT工作的年數基本一致,甚至有一個MIT教授看來半天寫了一個證明了說這是不可能的(然后底下MIT的學生聽了非常高興,他們很喜歡黑自己的教授)。
但是兩類人解決得非常快,一類是本來就對四面體的構型非常了解的;另外就是不認真對待隨便瞎試的(畢竟就幾種可能情況,枚舉起來很快)。但是如果希望通過觀察,通過視覺直覺解決問題會非常困難。
這意味著我們出現了錯覺,而且是一種視覺錯覺。
Hinton 通過人們嘗試的過程發現,錯覺是由于人們不自覺地會根據物體形狀建立一種“坐標框架”(coordinate frame)

人們會不自主地給兩個全等的幾何體使用相同的坐標框架。這個坐標框架會造成誤導,導致人們總是先嘗試一些錯誤的解。
如果給兩個幾何體不同的坐標框架
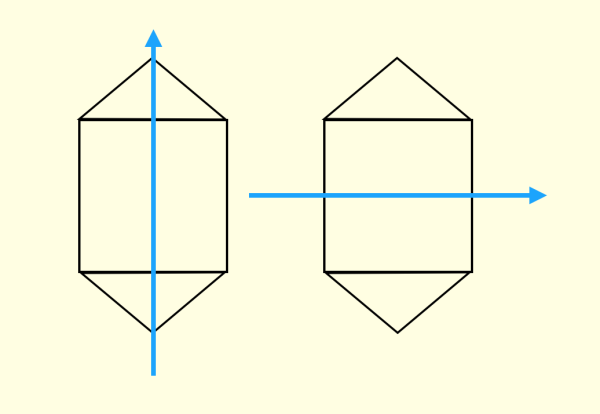
幾乎就立即可以得到解
第二個實驗關于手相性(handedness),手相性不一致的結構不能通過平面旋轉重合。這個做有機化學的同學應該最熟了(各種手性碳),比如被手向性控制的恐懼(來報一下巖沙海葵毒素的IUPAC命名?):
最簡單的手相性就是分清左右,這個到現在很多人都會搞混。判斷手相性對人來說是很困難的。Hinton 給的例子是“意識旋轉”(mental rotation),這個問題是判斷某兩個圖形的手相性是否一致:

(圖片取自Hinton在University of Toronto 的名為 Does the Brain do Inverse Graphics? 的講座的公開PPT)
我們無法直接回答,而是要在意識中“旋轉”某個R,才能判斷手相性是否一致。并且角度差的越大,人判斷時間就越長。
而“意識旋轉”同樣突出了“坐標框架”的存在,我們難以判斷手相性,是因為它們有不一致的坐標框架,我們需要通過旋轉把坐標框架變得一致,才能從直覺上知道它們是否一致。
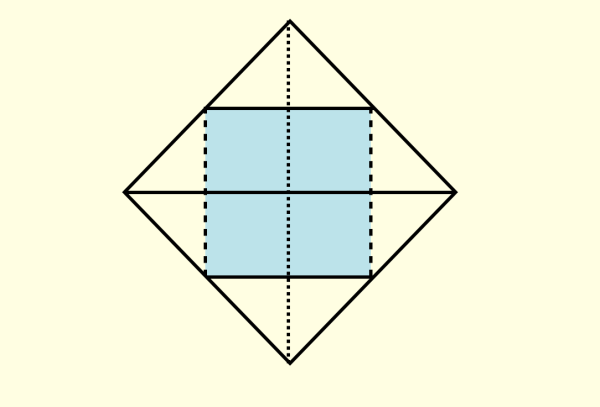
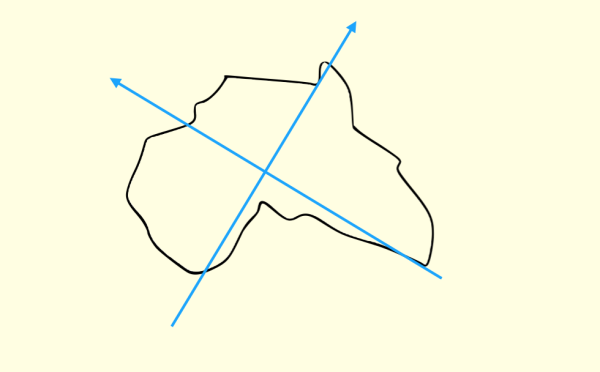
第三個實驗是關于地圖的。我們需要讓一個對地理不是特別精通,但是有基礎知識的人,回答一個簡單的問題:
下面的圖案是什么洲?

相當多的人(特別是憑直覺直接答的)回答,像澳洲。
這是因為對于不規則圖案,我們想當然地建立了這樣的坐標框架:

但是如果你這樣建立:
就會立即發現這是非洲,而且和澳洲相差的挺大。
通過這幾個實驗,Hinton得出了這樣的結論:
人的視覺系統會建立“坐標框架”,并且坐標框架的不同會極大地改變人的認知。
但是在CNN上卻很難看到類似“坐標框架”的東西。
Hinton 提出了一個猜想:
物體和觀察者之間的關系(比如物體的姿態),應該由一整套激活的神經元表示,而不是由單個神經元,或者一組粗編碼(coarse-coded,這里意思是指類似一層中,并沒有經過精細組織)的神經元表示。這樣的表示比較適合實現類似“坐標框架”的原理。
而這一整套神經元,Hinton認為就是Capsule。
同變性(Equivariance)和不變性(Invariance)
Hinton 反對 CNN的另外一個理由是,CNN的目標不正確。問題主要集中在 Pooling 方面(我認為可以推廣到下采樣,因為現在很多CNN用卷積下采樣代替Pooling層)。Hinton認為,過去人們對Pooling的看法是能夠帶來 invariance 的效果,也就是當內容發生很小的變化的時候(以及一些平移旋轉),CNN 仍然能夠穩定識別對應內容。
但是這個目標并不正確,因為最終我們理想的目標不是為了“識別率”,而是為了得到對內容的良好的表示(representation)。如果我們找到了對內容的良好表示,那么就等于我們“理解”了內容,因為這些內容可以被用來識別,用來進行語義分析,用來構建抽象邏輯,等等等等。而現在的 CNN 卻一味地追求識別率,這不是Hinton想要的東西,Hinton想要 “something big”。
Hinton的看法是,我們需要 Equivariance 而不是 Invariance。
所謂 Invariance,是指表示不隨變換變化,比如分類結果等等。
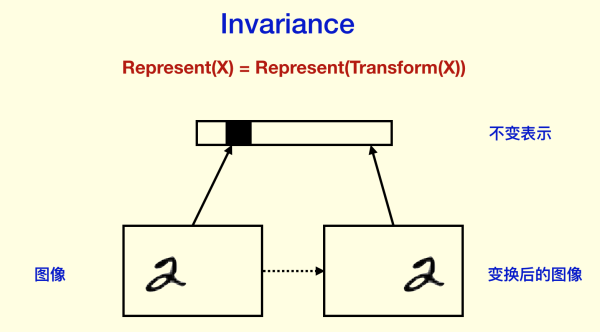
Invariance 主要是通過 Pooling 等下采樣過程得到的。如果你對訓練神經網絡有經驗,你可能會想到我們在做圖像預處理和數據拓增的時候,會把某些圖片旋轉一些角度,作為新的樣本,給神經網絡識別。這樣CNN能夠做到對旋轉的 invariance,并且是“直覺上”的invariance,根本不需要像人那樣去旋轉圖片,它直接就“忽視”了旋轉,因為我們希望它對旋轉invariance。
CNN同樣強調對空間的 invariance,也就是對物體的平移之類的不敏感(物體不同的位置不影響它的識別)。這當然極大地提高了識別正確率,但是對于移動的數據(比如視頻),或者我們需要檢測物體具體的位置的時候,CNN本身很難做,需要一些滑動窗口,或者R-CNN之類的方法,這些方法很反常(幾乎肯定在生物學中不存在對應結構),而且極難解釋為什么大腦在識別靜態圖像和觀察運動場景等差異很大的視覺功能時,幾乎使用同一套視覺系統。
對平移和旋轉的 invariance,其實是丟棄了“坐標框架”,Hinton認為這是CNN不能反映“坐標框架”的重要原因。
而 equivariance 不會丟失這些信息,它只是對內容的一種變換:

Hinton 認為 CNN 前面非 Pooling 的部分做的很好,因為它們是 equivariance 的。
那么在 Capsule 的框架下,又應該如何體現 equivariance 呢?
Hinton 認為存在兩種 equivariance:
位置編碼(place-coded):視覺中的內容的位置發生了較大變化,則會由不同的 Capsule 表示其內容。
速率編碼(rate-coded):視覺中的內容為位置發生了較小的變化,則會由相同的 Capsule 表示其內容,但是內容有所改變。
并且,兩者的聯系是,高層的 capsule 有更廣的域 (domain),所以低層的 place-coded 信息到高層會變成 rate-coded。
這里Hinton雖然沒有指明,但是我感覺到 Hinton 是希望能夠統一靜態視覺和動態視覺的(通過兩種編碼方式,同時感知運動和內容)。人腦中對于靜態和動態內容的處理通路并沒有特別大的變化,但是現在做視頻理解的框架和做圖片理解的差異還是不小的。
但是,畢竟 invariance 是存在的,比如我們對物體的識別確實不和物體的位置有關。這里Hinton解釋了一下:
knowledge,but not activities have to be invariant of viewpoint
也就是Hinton談論的問題是關于 activation 的,之前人們所說的CNN的 invariance 是關于神經元 activation 的。Hinton 希望 invariance 僅僅是對于 knowledge 的(對于Capsule而言,是其輸出的概率部分)。通過這可以看到Hinton使用Capsule的一個原因是覺得Capsule相比單個神經元更適合用來做表示。
Capsule 與 coincidence filtering (巧合篩分)
那么高層的 Capsule 怎么從底層的 Capsule 獲取信息呢?
首先 Capsule 的輸出是什么?
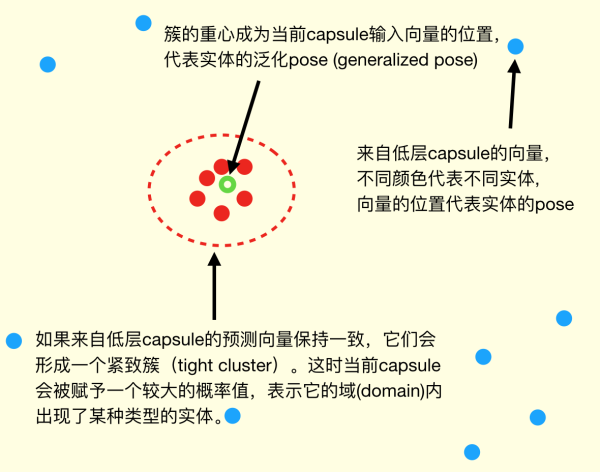
Hinton 假設 Capsule 輸出的是 instantiation parameters (實例參數) ,這是一個高維向量:
其模長代表某個實體(某個物體,或者其一部分)出現的概率
其方向/位置代表實體的一般姿態 (generalized pose),包括位置,方向,尺寸,速度,顏色等等
Capsule 的核心觀念是,用一組神經元而不是一個來代表一個實體,且僅代表一個實體。
然后通過對底層的 Capsule 做 coincidence filtering (巧合篩分)決定激活哪些高層的Capsule 。coincidence filtering是一種通過對高維度向量進行聚類來判斷置信的方式,Hinton舉了一個例子:
比如你在街上聽到有人談論11號的紐約時報,你一開始可能并不在意;但是如果你沿路聽到4個或者5個不同的人在談論11號的紐約時報,你可能就立即意識到一定有什么不平常的事情發生了
我們的(非日常)語句就像高維空間中向量,一組相近語句的出現,自然條件下概率很小,我們會很本能地篩分出這種巧合。
coincidence filtering 能夠規避一些噪聲,使得結果比較 robust。
這讓我想起了現在CNN容易被對抗樣本欺騙的問題。雖然幾乎所有的機器學習模型都存在對抗樣本的問題,但是CNN可以被一些對人而言沒有區別的對抗樣本欺騙,這是嚴峻的問題(這也是CNN異于我們視覺系統的一點)。一部分原因在于NN的線性結構,其對噪聲的耐受不是很好。不知道 coincidence filtering 能否緩解這個問題。
用圖來表示就像這樣:
Hinton采用的聚類(他稱為Agree)方式是使用以下評估:
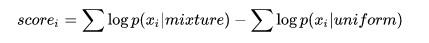
其中 mixture 是gaussian mixture,可以通過EM算法得到。也就是,如果簇的形狀越接近高斯分布(也就是越集中),得分越高;反之越分散越接近均勻分布,得分越低:
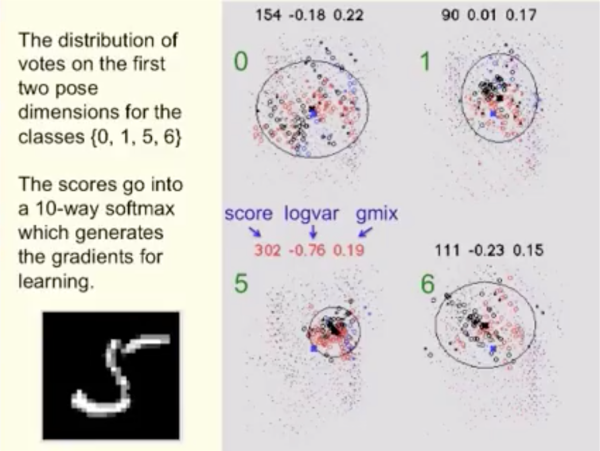
(圖片取自 Youtube [2])
得到高分的簇的分類所對應的上層capsule會接受下層capsule提供的generalized pose,相當于做了routing。這是因為下層的這些輸出,“選擇”了上層的capsule,“找到較好的(處理)路徑等價于(正確)處理了圖像”,Hinton 這樣解釋。Hinton 稱這種機制為 “routing by agreement”。
這種 routing 不是靜態的,而是動態的(隨輸入決定的),這是 Pooling 等方式不具備的:
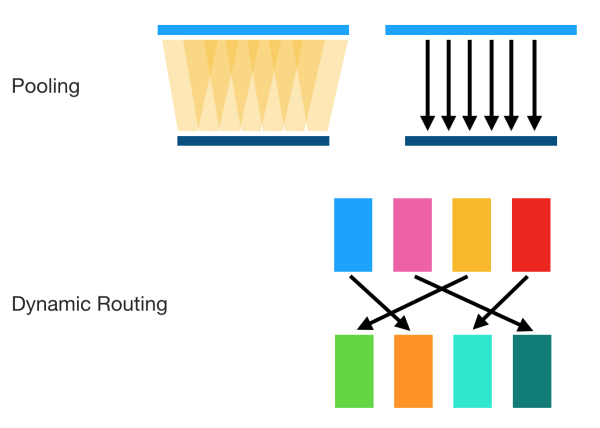
由于使用這種類似聚類的方式,其有潛在的 unsupervised learning 的能力,不過Hinton還沒有透露具體的算法。但是 Hinton 在 [2] 中提到,對于 MNIST 數據集,經過 unsupervised learning 后,只需要25個例子,就可以達到98.3%的識別準確率,并且解決了CNN識別重疊圖像困難等問題。這些應該在最近被 NIPS 接受的關于 Capsules 論文 Dynamic Routing between Capsules (尚未發表)https://research.google.com/pubs/pub46351.html 中可以看到。讓我們拭目以待。
圖形學和線性流形(linear manifold)
Hinton 這次明顯受到了計算機圖形學的啟發。他在報告[2]中說 literally,literally, reverse of graphics. (我非常非常認真地想要“逆向”圖形學)。
計算機圖形學中有個非常重要的性質,就是其使用了 linear manifold,有良好的視角不變性。
說明白一點,也就是用視角變換矩陣作用到場景中,不改變場景中物體的相對關系。
于是Hinton決定用矩陣處理兩個物體間的關聯。


(圖片取自Hinton在University of Toronto 的名為 Does the Brain do Inverse Graphics? 的講座的公開PPT)
而且這對三維也是有效的,這里看到了 Hinton 沖擊三維視覺的野心。
Hinton 這波會成功嗎?
Hinton 是個很“固執”的人,在 Andrew Ng 對他的采訪中,他說出了自己的想法:
If your intuitions are good, you should follow them and you will eventually be successful; if your intuitions are not good, it doesn"t matter what you do. You might as well trust your intuitions there"s no point not trusting them.
(意思是如果直覺一直很好,那么當然應該堅持;如果直覺很差,那么怎么做也沒有關系了(反正你也搞不出什么,即使你換個想法大抵也不會成功))。當然后半句可能是 Hinton 的高級黑。
但是 Hinton 確乎堅信自己的直覺,從反向傳播提出,到深度學習的火爆,Hinton已經堅守了30年了,并沒有任何放棄的意思。
現在 Capsule 給了 Hinton 很多直覺,Hinton 估計也是會一條路走到黑。Hinton 的目標也很大,從他對 capsule 的介紹中可以看到有沖擊動態視覺內容、3D視覺、無監督學習、NN魯棒性這幾個“老大難”問題的意思。
如果Hinton會失敗(我不是不看好Hinton,而是僅僅做一個假設),大抵是兩種情況,
第一種是因為現在反向傳播的各種優點,上面已經總結過了。一個模型要成功,不僅要求效果良好,還要求靈活性(以便應用在實際問題中),高效性,和社區支持(工業界和學術界的采納程度和熱門程度)。現在的反向傳播在這幾點上都非常 promising,不容易給其他模型讓步。
第二種是因為即使一個直覺特別好的人,也有可能有直覺特別不好的一天,尤其是晚年。這點非常著名的例子是愛因斯坦。愛因斯坦性格和 Hinton 很像,有非常敏銳的直覺,并且對自己的直覺的值守到了近乎固執的程度。愛因斯坦晚年的時候,想要搞統一場論,這是一個很大的目標,就好像現在Hinton希望能夠創造顛覆BP機制的目標一樣;愛因斯坦也獲得了很多直覺,比如他覺得電磁場和引力是非常相似的,都和相對論緊密關聯,都是平方反比,都是一種傳遞力的波色子,并且玻色子靜質量都是0,力的范圍都是無窮遠,等等等等,就好像現在Hinton找到的各種各樣很有說服力的論據一樣;于是愛因斯坦決定首先統一電磁力和引力,結果是失敗的。反而是兩種看上去很不搭的力——弱相互作用力(3種玻色子,范圍在原子核大小內)和電磁力首先被統一了(電弱統一理論)。而引力恰恰是目前最難統一的,也就是愛因斯坦的直覺走反了。我很擔心 Hinton 也會如此。
不過即使愛因斯坦沒有成功,后人也為其所激勵,繼續扛起GUT的大旗推動物理前沿;對于Hinton 我想也是一樣。
尾注
Hinton 曾經在1987年左右發明了 recirculation 算法代替BP來訓練神經網絡,雖然不算特別成功,但是卻預言了后來神經科學才發現的spike timing-independent plasticity。
Hinton 最初提出 capsule 的時候(5年前),幾乎“逢投必拒”,沒有人相信,但是 Hinton 自己一致堅信這一點,并且一直堅持到現在。
在 Andrew Ng對其采訪中,Hinton 對未來的趨勢(對CS從業者)的一句很有意思的描述:showing computers is going to be as important as programming computers.
Reference
[1] 2017年8月17日,于加拿大多倫多大學 Fields Institute,Hinton 的報告 https://www.youtube.com/watch?v=Mqt8fs6ZbHk
[2] 2017年4月3日發布 Brain & Cognitive Sciences 于 MIT,Hinton 的報告 https://www.youtube.com/watch?v=rTawFwUvnLE
[3] 媒體報道 Hinton 要將當前的深度學習核心算法推倒重來 Artificial intelligence pioneer says we need to start over
[4] Fei-Fei Li 在 Twitter 上的評論:Echo Geoff"s sentiment no tool is eternal, even backprop or deeplearning. V. important to continue basic research.
[5] Le, Q. V. (2013, May). Building high-level features using large scale unsupervised learning. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on (pp. 8595-8598). IEEE.
[6] Bény, C. (2013). Deep learning and the renormalization group. arXiv preprint arXiv:1301.3124.
[7] Hinton, G. (2010). A practical guide to training restricted Boltzmann machines. Momentum, 9(1), 926.
[8] Rina Decher (1986). Learning while searching in constraint-satisfaction problems. University of California, Computer Science Department, Cognitive Systems Laboratory.
[9] Hinton, G. E., Krizhevsky, A., & Wang, S. D. (2011, June). Transforming auto-encoders. In International Conference on Artificial Neural Networks (pp. 44-51). Springer Berlin Heidelberg.
[10] Wolpert, D. H. (1996). The lack of a priori distinctions between learning algorithms. Neural computation, 8(7), 1341-1390.
[11] Hinton, G. E., & McClelland, J. L. (1988). Learning representations by recirculation. In Neural information processing systems (pp. 358-366).
[12] Pathak, D., Agrawal, P., Efros, A. A., & Darrell, T. (2017). Curiosity-driven exploration by self-supervised prediction. arXiv preprint arXiv:1705.05363.
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4625.html
摘要:論文鏈接會上其他科學家認為反向傳播在人工智能的未來仍然起到關鍵作用。既然要從頭再來,的下一步是什么值得一提的是,與他的谷歌同事和共同完成的論文已被大會接收。 三十多年前,深度學習著名學者 Geoffrey Hinton 參與完成了論文《Experiments on Learning by Back Propagation》,提出了反向傳播這一深刻影響人工智能領域的方法。今天的他又一次呼吁研究...
摘要:近幾年,深度學習高速發展,出現了大量的新模型與架構,以至于我們無法理清網絡類型之間的關系。是由深度學習先驅等人提出的新一代神經網絡形式,旨在修正反向傳播機制。當多個預測一致時本論文使用動態路由使預測一致,更高級別的將變得活躍。 近幾年,深度學習高速發展,出現了大量的新模型與架構,以至于我們無法理清網絡類型之間的關系。在這篇文章中,香港科技大學(HKUST)助理教授金成勳總結了深度網絡類型之間...
摘要:傳統神經網絡的問題到目前為止,圖像分類問題上較先進的方法是。我們把卡戴珊姐姐旋轉出現這個問題的原因,用行話來說是旋轉的程度超出了較大池化所帶來的旋轉不變性的限度。 Capsule Networks,或者說CapsNet,這個名字你應該已經聽過好幾次了。這是深度學習之父的Geoffrey Hinton近幾年一直在探索的領域,被視為突破性的新概念。最近,關于Capsule的論文終于公布了。一篇即...
摘要:本文試圖揭開讓人迷惘的云霧,領悟背后的原理和魅力,品嘗這一頓盛宴。當然,激活函數本身很簡單,比如一個激活的全連接層,用寫起來就是可是,如果我想用的反函數來激活呢也就是說,你得給我解出,然后再用它來做激活函數。 由深度學習先驅 Hinton 開源的 Capsule 論文 Dynamic Routing Between Capsules,無疑是去年深度學習界最熱點的消息之一。得益于各種媒體的各種...
斯蒂文認為機器學習有時候像嬰兒學習,特別是在物體識別上。比如嬰兒首先學會識別邊界和顏色,然后將這些信息用于識別形狀和圖形等更復雜的實體。比如在人臉識別上,他們學會從眼睛和嘴巴開始識別最終到整個面孔。當他們看一個人的形象時,他們大腦認出了兩只眼睛,一只鼻子和一只嘴巴,當認出所有這些存在于臉上的實體,并且覺得這看起來像一個人。斯蒂文首先給他的女兒悠悠看了以下圖片,看她是否能自己學會認識圖中的人(金·卡...

閱讀 3189·2023-04-26 03:06
閱讀 3688·2021-11-22 09:34
閱讀 1133·2021-10-08 10:05
閱讀 3023·2021-09-22 15:53
閱讀 3529·2021-09-14 18:05
閱讀 1385·2021-08-05 09:56
閱讀 1878·2019-08-30 15:56
閱讀 2123·2019-08-29 11:02






