資訊專欄INFORMATION COLUMN

摘要:自從和在年贏得了的冠軍,卷積神經網絡就成為了分割圖像的黃金準則。事實上,從那時起,卷積神經網絡不斷獲得完善,并已在挑戰上超越人類。現在,卷積神經網絡在的表現已超越人類。
卷積神經網絡(CNN)的作用遠不止分類那么簡單!在本文中,我們將看到卷積神經網絡(CNN)如何在圖像實例分割任務中提升其結果。
自從 Alex Krizhevsky、Geoff Hinton 和 Ilya Sutskever 在 2012 年贏得了 ImageNet 的冠軍,卷積神經網絡就成為了分割圖像的黃金準則。事實上,從那時起,卷積神經網絡不斷獲得完善,并已在 ImageNet 挑戰上超越人類。
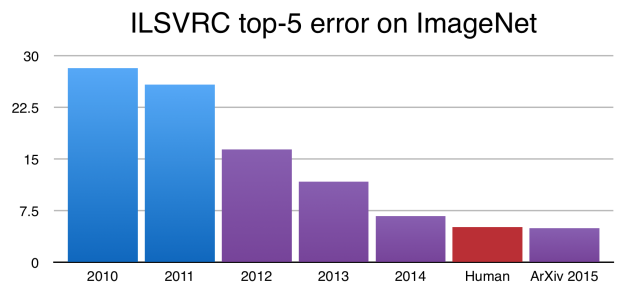
現在,卷積神經網絡在 ImageNet 的表現已超越人類。圖中 y 軸代表 ImageNet 錯誤率。
雖然這些結果令人印象深刻,但與真實的人類視覺理解的多樣性和復雜性相比,圖像分類還是簡單得多。

分類挑戰賽使用的圖像實例。注意圖像的構圖以及對象的性。
在分類中,圖像的焦點通常是一個單一目標,任務即是對圖像進行簡單描述(見上文)。但是當我們在觀察周遭世界時,我們處理的任務相對復雜的多。

現實中的情景通常由許多不同的互相重疊的目標、背景以及行為構成。
我們看到的情景包含多個互相重疊的目標以及不同的背景,并且我們不僅要分類這些不同的目標還要識別其邊界、差異以及彼此的關系!

在圖像分割中,我們的目的是對圖像中的不同目標進行分類,并確定其邊界。來源:Mask R-CNN
卷積神經網絡可以幫我們處理如此復雜的任務嗎?也就是說,給定一個更為復雜的圖像,我們是否可以使用卷積神經網絡識別圖像中不同的物體及其邊界?事實上,正如 Ross Girshick 和其同事在過去幾年所做的那樣,答案毫無疑問是肯定的。
本文的目標
在本文中,我們將介紹目標檢測和分割的某些主流技術背后的直觀知識,并了解其演變歷程。具體來說,我們將介紹 R-CNN(區域 CNN),卷積神經網絡在這個問題上的最初的應用,及變體 Fast R-CNN 和 Faster R-CNN。最后,我們將介紹 Facebook Research 最近發布的一篇文章 Mask R-CNN,它擴展了這種對象檢測技術從而可以實現像素級分割。上述四篇論文的鏈接如下:
1. R-CNN: https://arxiv.org/abs/1311.2524
2. Fast R-CNN: https://arxiv.org/abs/1504.08083
3. Faster R-CNN: https://arxiv.org/abs/1506.01497
4. Mask R-CNN: https://arxiv.org/abs/1703.06870
2014 年:R-CNN - 首次將 CNN 用于目標檢測

目標檢測算法,比如 R-CNN,可分析圖像并識別主要對象的位置和類別。
受到多倫多大學 Hinton 實驗室的研究的啟發,加州伯克利大學一個由 Jitendra Malik 領導的小組,問了他們自己一個在今天看來似乎是不可避免的問題:
Krizhevsky et. al 的研究成果可在何種程度上被推廣至目標檢測?
目標檢測是一種找到圖像中的不同目標并進行分類的任務(如上圖所示)。通過在 PASCAL VOC Challenge 測試(一個知名的對象檢測挑戰賽,類似于 ImageNet),由 Ross Girshick(將在下文細講)、Jeff Donahue 和 Trevor Darrel 組成的團隊發現這個問題確實可通過 Krizhevsky 的研究結果獲得解決。他們寫道:
Krizhevsky et. al 第一次提出:相比基于更簡單、HOG 般的特征的系統,卷及神經網絡可顯著提升 PASCAL VOC 上的目標檢測性能。
現在讓我們花點時間來了解他們的架構 R-CNN 的運作的方式。
理解 R-CNN
R-CNN 的目的為接收圖像,并正確識別圖像中主要目標(通過邊界框)的位置。
輸入:圖像
輸出:邊界框+圖像中每個目標的標注
但是我們如何找出這些邊界框的位置?R-CNN 做了我們也可以直觀做到的——在圖像中假設了一系列邊界,看它們是否可以真的對應一個目標。

通過多個尺度的窗口選擇性搜索,并搜尋共享紋理、顏色或強度的相鄰像素。圖片來源:https://www.koen.me/research/pub/uijlings-ijcv2013-draft.pdf
R-CNN 創造了這些邊界框,或者區域提案(region proposal)關于這個被稱為選擇性搜索(Selective Search)的方法,可在這里(鏈接:http://www.cs.cornell.edu/courses/cs7670/2014sp/slides/VisionSeminar14.pdf)閱讀更多信息。在高級別中,選擇性搜索(如上圖所示)通過不同尺寸的窗口查看圖像,并且對于不同尺寸,其嘗試通過紋理、顏色或強度將相鄰像素歸類,以識別物體。
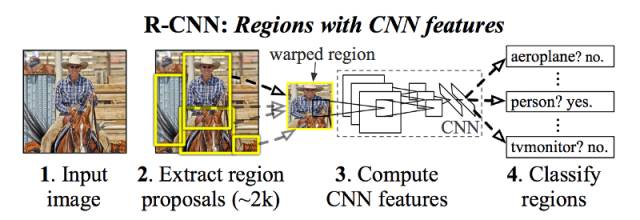
在創建一組區域提案(region proposal)后,R-CNN 只需將圖像傳遞給修改版的 AlexNet 以確定其是否為有效區域。
一旦創建了這些提案,R-CNN 簡單地將該區域卷曲到一個標準的平方尺寸,并將其傳遞給修改版的 AlexNet(ImageNet 2012 的冠軍版本,其啟發了 R-CNN),如上所示。
在 CNN 的最后一層,R-CNN 添加了一個支持向量機(SVM),它可以簡單地界定物體是否為目標,以及是什么目標。這是上圖中的第 4 步。
提升邊界框
現在,在邊界框里找到了目標,我們可以收緊邊框以適應目標的真實尺寸嗎?我們的確可以這樣做,這也是 R-CNN 的最后一步。R-CNN 在區域提案上運行簡單的線性回歸,以生成更緊密的邊界框坐標從而獲得最終結果。下面是這一回歸模型的輸入和輸出:
輸入:對應于目標的圖像子區域
輸出:子區域中目標的新邊界框坐標
所以,概括一下,R-CNN 只是以下幾個簡單的步驟
1. 為邊界框生成一組提案。
2. 通過預訓練的 AlexNet 運行邊界框中的圖像,最后通過 SVM 來查看框中圖像的目標是什么。
3. 通過線性回歸模型運行邊框,一旦目標完成分類,輸出邊框的更緊密的坐標。
2015: Fast R-CNN - 加速和簡化 R-CNN

Ross Girshick 編寫了 R-CNN 和 Fast R-CNN,并持續推動著 Facebook Research 在計算機視覺方面的進展。
R-CNN 性能很棒,但是因為下述原因運行很慢:
1. 它需要 CNN(AlexNet)針對每個單圖像的每個區域提案進行前向傳遞(每個圖像大約 2000 次向前傳遞)。
2. 它必須分別訓練三個不同的模型 - CNN 生成圖像特征,預測類別的分類器和收緊邊界框的回歸模型。這使得傳遞(pipeline)難以訓練。
2015 年,R-CNN 的第一作者 Ross Girshick 解決了這兩個問題,并創造了第二個算法——Fast R-CNN。下面是其主要思想。
Fast R-CNN 見解 1:ROI(興趣區域)池化
對于 CNN 的前向傳遞,Girshick 意識到,對于每個圖像,很多提出的圖像區域總是相互重疊,使得我們一遍又一遍地重復進行 CNN 計算(大約 2000 次!)。他的想法很簡單:為什么不讓每個圖像只運行一次 CNN,然后找到一種在 2000 個提案中共享計算的方法?
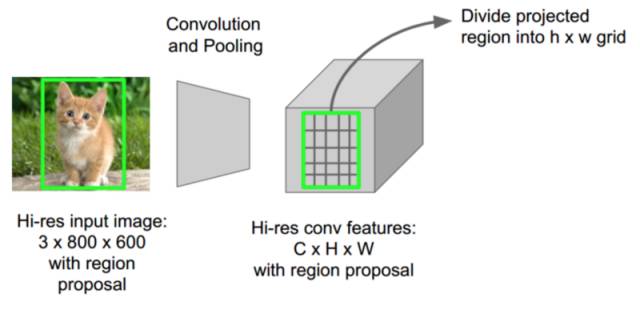
在 ROIPool 中,創建了圖像的完整前向傳遞,并從獲得的前向傳遞中提取每個興趣區域的轉換特征。來源:CS231N 幻燈片,Fei Fei Li、Andrei Karpathy、和 Justin Johnson 斯坦福大學
這正是 Fast R-CNN 使用被稱為 RoIPool(興趣區域池化)的技術所完成的事情。其要點在于,RoIPool 分享了 CNN 在圖像子區域的前向傳遞。在上圖中,請注意如何通過從 CNN 的特征映射選擇相應的區域來獲取每個區域的 CNN 特征。然后,每個區域的特征簡單地池化(通常使用較大池化(Max Pooling))。所以我們所需要的是原始圖像的一次傳遞,而非大約 2000 次!
Fast R-CNN 見解 2:將所有模型并入一個網絡
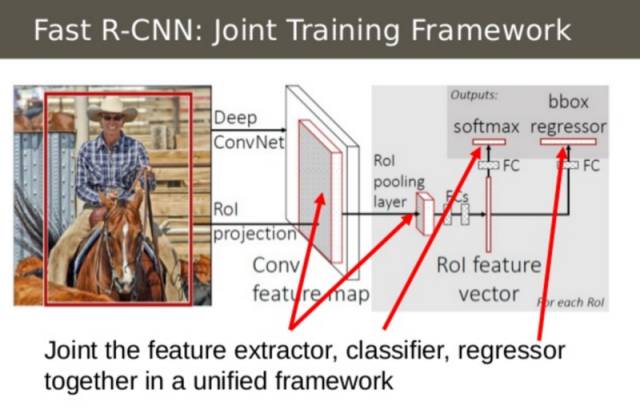
Fast R-CNN 將卷積神經網絡(CNN),分類器和邊界框回歸器組合為一個簡單的網絡。
Fast R-CNN 的第二個見解是在單一模型中聯合訓練卷積神經網絡、分類器和邊界框回歸器。之前我們有不同的模型來提取圖像特征(CNN),分類(SVM)和緊縮邊界框(回歸器),而 Fast R-CNN 使用單一網絡計算上述三個模型。
在上述圖像中,你可以看到這些工作是如何完成的。Fast R-CNN 在 CNN 頂部用簡單的 softmax 層代替了支持向量機分類器(SVM classfier)以輸出分類。它還添加了與 softmax 層平行的線性回歸層以輸出邊界框坐標。這樣,所有需要的輸出均來自一個單一網絡!下面是整個模型的輸入和輸出:
輸入:帶有區域提案的圖像
輸出:帶有更緊密邊界框的每個區域的目標分類
2016:Faster R-CNN—加速區域提案
即使有了這些進步,Faster R-CNN 中仍存在一個瓶頸問題——區域提案器(region proposer)。正如我們所知,檢測目標位置的第一步是產生一系列的潛在邊界框或者供測試的興趣區域。在 Fast R-CNN,通過使用選擇性搜索創建這些提案,這是一個相當緩慢的過程,被認為是整個流程的瓶頸。

微軟研究院首席研究員孫劍領導了 Faster R-CNN 團隊。
2015 年中期,由 Shaoqing Ren、Kaiming He、Ross Girshick 和孫劍組成的微軟研究團隊,找到了一種被其命為 Faster R-CNN 的架構,幾乎把區域生成步驟的成本降為零。
?Faster R-CNN 的洞見是,區域提案取決于通過 CNN 的前向(forward pass)計算(分類的第一步)的圖像特征。為什么不重復使用區域提案的相同的 CNN 結果,以取代多帶帶運行選擇性搜索算法?
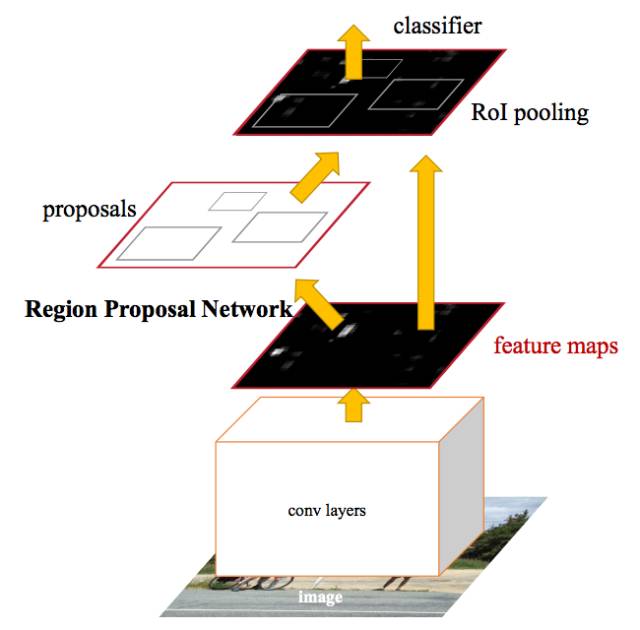
在 Faster R-CNN,單個 CNN 用于區域提案和分類。
事實上,這正是 Faster R-CNN 團隊取得的成就。上圖中你可以看到單個 CNN 如何執行區域提案和分類。這樣一來,只需訓練一個 CNN,我們幾乎就可以免費獲得區域提案!作者寫道:
我們觀察到,區域檢測器(如 Fast R-CNN)使用的卷積特征映射也可用于生成區域提案 [從而使區域提案的成本幾乎為零]。
以下是其模型的輸入和輸出:
?
輸入:圖像(注意并不需要區域提案)。
輸出:圖像中目標的分類和邊界框坐標。
如何生成區域
讓我們花點時間看看 Faster R-CNN 如何從 CNN 特征生成這些區域提案。Faster R-CNN 在 CNN 特征的頂部添加了一個簡單的完全卷積網絡,創建了所謂的區域提案網絡。
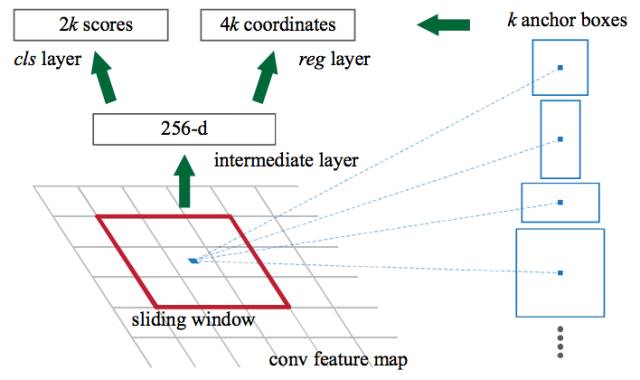
區域提案網絡在 CNN 的特征上滑動一個窗口。在每個窗口位置,網絡在每個錨點輸出一個分值和一個邊界框(因此,4k 個框坐標,其中 k 是錨點的數量)。
?
區域生成網絡的工作是在 CNN 特征映射上傳遞滑動窗口,并在每個窗口中輸出 k 個潛在邊界框和分值,以便評估這些框有多好。這些 k 框表征什么?

我們知道,用于人的邊框往往是水平和垂直的。我們可以使用這種直覺,通過創建這樣維度的錨點來指導區域提案網絡。
我們知道圖像中的目標應該符合某些常見的縱橫比和尺寸。例如,我們想要一些類似人類形狀的矩形框。同樣,我們不會看到很多非常窄的邊界框。以這種方式,我們創建 k 這樣的常用縱橫比,稱之為錨點框。對于每個這樣的錨點框,我們在圖像中每個位置輸出一個邊界框和分值。
考慮到這些錨點框,我們來看看區域提案網絡的輸入和輸出:
?
輸入:CNN 特征圖。
輸出:每個錨點的邊界框。分值表征邊界框中的圖像作為目標的可能性。
然后,我們僅將每個可能成為目標的邊界框傳遞到 Fast R-CNN,生成分類和收緊邊界框。
2017:Mask R-CNN - 擴展 Faster R-CNN 以用于像素級分割

圖像實例分割的目的是在像素級場景中識別不同目標。
到目前為止,我們已經懂得如何以許多有趣的方式使用 CNN,以有效地定位圖像中帶有邊框的不同目標。
我們能進一步擴展這些技術,定位每個目標的較精確像素,而非僅限于邊框嗎?這個問題被稱為圖像分割。Kaiming He 和一群研究人員,包括 Girshick,在 Facebook AI 上使用一種稱為 Mask R-CNN 的架構探索了這一圖像分割問題。

Facebook AI 的研究員 Kaiming He 是 Mask R-CNN 的主要作者,也是 Faster R-CNN 的聯合作者。
很像 Fast R-CNN 和 Faster R-CNN,Mask R-CNN 的基本原理非常簡單直觀。鑒于 Faster R-CNN 目標檢測的效果非常好,我們能將其簡單地擴展到像素級分割嗎?
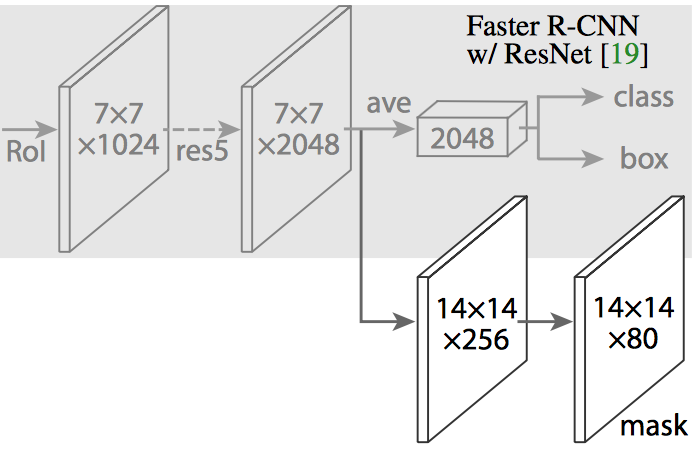
在 Mask R-CNN 中,在 Faster R-CNN 的 CNN 特征的頂部添加了一個簡單的完全卷積網絡(FCN),以生成 mask(分割輸出)。請注意它是如何與 Faster R-CNN 的分類和邊界框回歸網絡并行的。
Mask R-CNN 通過簡單地向 Faster R-CNN 添加一個分支來輸出二進制 mask,以說明給定像素是否是目標的一部分。如上所述,分支(在上圖中為白色)僅僅是 CNN 特征圖上的簡單的全卷積網絡。以下是其輸入和輸出:
輸入:CNN 特征圖。
輸出:在像素屬于目標的所有位置上都有 1s 的矩陣,其他位置為 0s(這稱為二進制 mask)。
但 Mask R-CNN 作者不得不進行一個小的調整,使這個流程按預期工作。
RoiAlign——重對齊 RoIPool 以使其更準確
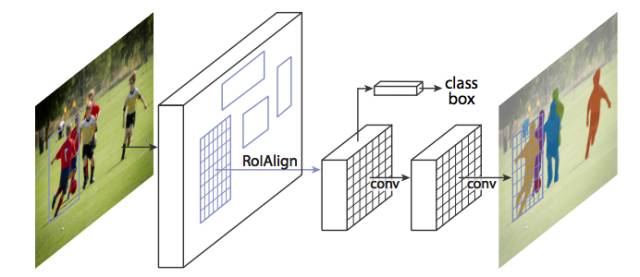
圖像通過 RoIAlign 而不是 RoIPool 傳遞,使由 RoIPool 選擇的特征圖區域更較精確地對應原始圖像的區域。這是必要的,因為像素級分割需要比邊界框更細粒度的對齊。
當運行沒有修改的原始 Faster R-CNN 架構時,Mask R-CNN 作者意識到 RoIPool 選擇的特征圖的區域與原始圖像的區域略不對齊。因為圖像分割需要像素級特異性,不像邊框,這自然地導致不準確。
作者通過使用 RoIAlign 方法簡單地調整 RoIPool 來更較精確地對齊,從而解決了這個問題。
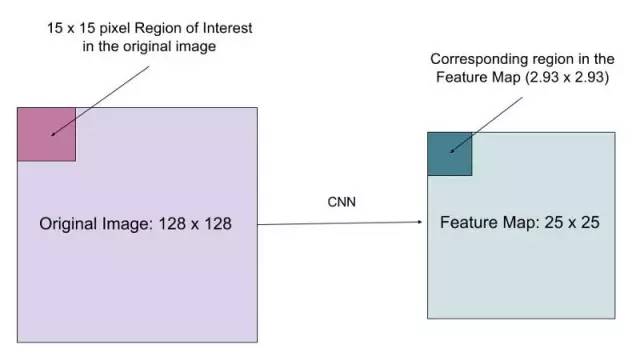
我們如何準確地將原始圖像的相關區域映射到特征圖上?
想象一下,我們有一個尺寸大小為 128x128 的圖像和大小為 25x25 的特征圖。想象一下,我們想要的是與原始圖像中左上方 15x15 像素對應的區域(見上文)。我們如何從特征圖選擇這些像素?
我們知道原始圖像中的每個像素對應于原始圖像中的?25/128 像素。要從原始圖像中選擇 15 像素,我們只需選擇 15 * 25/128?=2.93 像素。
?
在 RoIPool,我們會舍棄一些,只選擇 2 個像素,導致輕微的錯位。然而,在 RoIAlign,我們避免了這樣的舍棄。相反,我們使用雙線性插值來準確得到 2.93 像素的內容。這很大程度上,讓我們避免了由 RoIPool 造成的錯位。
一旦這些掩碼生成,Mask R-CNN 簡單地將它們與來自 Faster R-CNN 的分類和邊界框組合,以產生如此驚人的較精確分割:

Mask R-CNN 也能對圖像中的目標進行分割和分類.
展望
在過去短短 3 年里,我們看到研究界如何從 Krizhevsky 等人最初結果發展為 R-CNN,最后一路成為 Mask R-CNN 的強大結果。多帶帶來看,像 MASK R-CNN 這樣的結果似乎是無法達到的驚人飛躍。然而,通過這篇文章,我希望你們認識到,通過多年的辛勤工作和協作,這些進步實際上是直觀的且漸進的改進之路。R-CNN、Fast R-CNN、Faster R-CNN 和最終的 Mask R-CNN 提出的每個想法并不一定是跨越式發展,但是它們的總和卻帶來了非常顯著的效果,幫助我們向人類水平的視覺能力又前進了幾步。
特別令我興奮的是,R-CNN 和 Mask R-CNN 間隔只有三年!隨著持續的資金、關注和支持,計算機視覺在未來三年會有怎樣的發展?我們非常期待。
原文鏈接:https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4544.html
摘要:這個像素級別的圖像分割問題被等科學家解決,這個框架被稱為。由于圖像分割需要做到像素級,這與邊框分割不同,所以必然導致不準確。 作者:chen_h微信號 & QQ:862251340微信公眾號:coderpai簡書地址:https://www.jianshu.com/p/867... 自從?Alex Krizhevsky, Geoff Hinton, and Ilya Sutskeve...
摘要:目前目標檢測領域的深度學習方法主要分為兩類的目標檢測算法的目標檢測算法。原來多數的目標檢測算法都是只采用深層特征做預測,低層的特征語義信息比較少,但是目標位置準確高層的特征語義信息比較豐富,但是目標位置比較粗略。 目前目標檢測領域的深度學習方法主要分為兩類:two stage的目標檢測算法;one stage的目標檢測算法。前者是先由算法生成一系列作為樣本的候選框,再通過卷積神經網絡進行樣本...
摘要:基于候選區域的目標檢測器滑動窗口檢測器自從獲得挑戰賽冠軍后,用進行分類成為主流。一種用于目標檢測的暴力方法是從左到右從上到下滑動窗口,利用分類識別目標。這些錨點是精心挑選的,因此它們是多樣的,且覆蓋具有不同比例和寬高比的現實目標。 目標檢測是很多計算機視覺任務的基礎,不論我們需要實現圖像與文字的交互還是需要識別精細類別,它都提供了可靠的信息。本文對目標檢測進行了整體回顧,第一部分從RCNN...
摘要:然而,幸運的是,目前更為成功的目標檢測方法是圖像分類模型的擴展。幾個月前,發布了一個用于的新的目標檢測。 隨著自動駕駛汽車、智能視頻監控、人臉檢測和各種人員計數應用的興起,快速和準確的目標檢測系統也應運而生。這些系統不僅能夠對圖像中的每個目標進行識別和分類,而且通過在其周圍畫出適當的邊界來對其進行局部化(localizing)。這使得目標檢測相較于傳統的計算機視覺前身——圖像分類來說更加困難...

閱讀 1102·2021-10-14 09:43
閱讀 1145·2021-10-11 11:07
閱讀 3112·2021-08-18 10:23
閱讀 1484·2019-08-29 16:18
閱讀 998·2019-08-28 18:21
閱讀 1473·2019-08-26 12:12
閱讀 3760·2019-08-26 10:11
閱讀 2501·2019-08-23 18:04





