資訊專欄INFORMATION COLUMN

摘要:然而,幸運(yùn)的是,目前更為成功的目標(biāo)檢測方法是圖像分類模型的擴(kuò)展。幾個(gè)月前,發(fā)布了一個(gè)用于的新的目標(biāo)檢測。
隨著自動(dòng)駕駛汽車、智能視頻監(jiān)控、人臉檢測和各種人員計(jì)數(shù)應(yīng)用的興起,快速和準(zhǔn)確的目標(biāo)檢測系統(tǒng)也應(yīng)運(yùn)而生。這些系統(tǒng)不僅能夠?qū)D像中的每個(gè)目標(biāo)進(jìn)行識別和分類,而且通過在其周圍畫出適當(dāng)?shù)倪吔鐏韺ζ溥M(jìn)行局部化(localizing)。這使得目標(biāo)檢測相較于傳統(tǒng)的計(jì)算機(jī)視覺前身——圖像分類來說更加困難。
然而,幸運(yùn)的是,目前更為成功的目標(biāo)檢測方法是圖像分類模型的擴(kuò)展。幾個(gè)月前,Google發(fā)布了一個(gè)用于Tensorflow的新的目標(biāo)檢測API。隨著這個(gè)版本的發(fā)布,一些特定模型的預(yù)先構(gòu)建的體系結(jié)構(gòu)和權(quán)重為:
?帶有MobileNets的Single Shot Multibox Detector(SSD)
?帶有Inception V2的SSD
?具有Resnet 101的基于區(qū)域的完全卷積網(wǎng)絡(luò)(R-FCN)
?具有Resnet 101的Faster R-CNN
?具有Inception Resnet v2的Faster R-CNN
在我上一篇博文(https://medium.com/towards-data-science/an-intuitive-guide-to-deep-network-architectures-65fdc477db41)中,我介紹了上面列出的三種基礎(chǔ)網(wǎng)絡(luò)架構(gòu)背后的知識:MobileNets、Inception和ResNet。這一次,我想為Tensorflow的目標(biāo)檢測模型做同樣的事情:Faster R-CNN、R-FCN和SSD。在讀完這篇文章之后,我們希望能夠深入了解深度學(xué)習(xí)是如何應(yīng)用于目標(biāo)檢測的,以及這些目標(biāo)檢測模型是如何激發(fā)而出,以及從一個(gè)發(fā)散到另一個(gè)的。
Faster R-CNN
Faster R-CNN現(xiàn)在是基于深度學(xué)習(xí)的目標(biāo)檢測的標(biāo)準(zhǔn)模型。它幫助激發(fā)了許多后來基于它之后的檢測和分割模型,包括我們今天要研究的另外兩種模型。不幸的是,在不了解它的前任R-CNN和Fast R-CNN的情況下,我們是不能夠真正開始理解Faster R-CNN,所以現(xiàn)在我們來快速了解一下它的起源吧。
R-CNN
R-CNN是Faster R-CNN的鼻祖。換句話說,R-CNN才是一切的開端。
R-CNN或基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)由3個(gè)簡單的步驟組成:
1.使用一種稱為“選擇性搜索”的算法掃描可能是目標(biāo)的輸入圖像,生成約2000個(gè)區(qū)域提案。
2.在這些區(qū)域提案之上運(yùn)行卷積神經(jīng)網(wǎng)絡(luò)(CNN)。
3.取每個(gè)CNN的輸出并將其饋送到a)SVM(支持向量機(jī))以對該區(qū)域進(jìn)行分類,以及b)如果存在該目標(biāo),則線性回歸器可以收緊該目標(biāo)的邊界框。
這三個(gè)步驟如下圖所示:
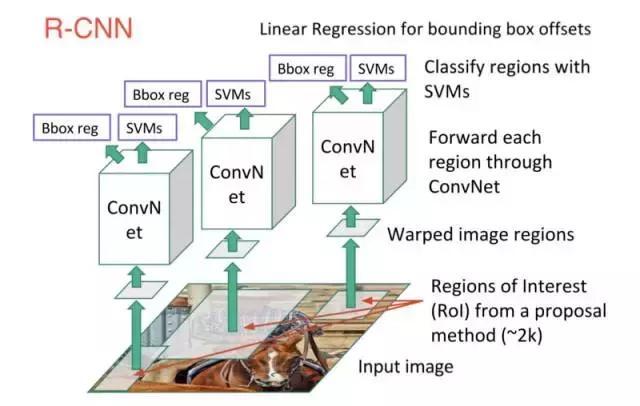
換句話說,我們首先提出區(qū)域,然后提取特征,然后根據(jù)它們的特征對這些區(qū)域進(jìn)行分類。 從本質(zhì)上來說,我們是將目標(biāo)檢測轉(zhuǎn)化為圖像分類問題。R-CNN是非常直觀的,但同時(shí)也很慢。
Fast R-CNN
R-CNN的直系后裔是Fast-R-CNN。Fast R-CNN在許多方面都類似于原版,但是通過兩個(gè)主要的增強(qiáng)來提高其檢測速度:
1.在提出區(qū)域之前在圖像上執(zhí)行特征提取,因此在整個(gè)圖像上僅運(yùn)行一個(gè)CNN而不是在超過2000個(gè)重疊區(qū)域運(yùn)行2000個(gè)CNN。
2.用softmax層代替SVM,從而擴(kuò)展神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測,而不是創(chuàng)建一個(gè)新的模型。
新模型看起來像這樣:
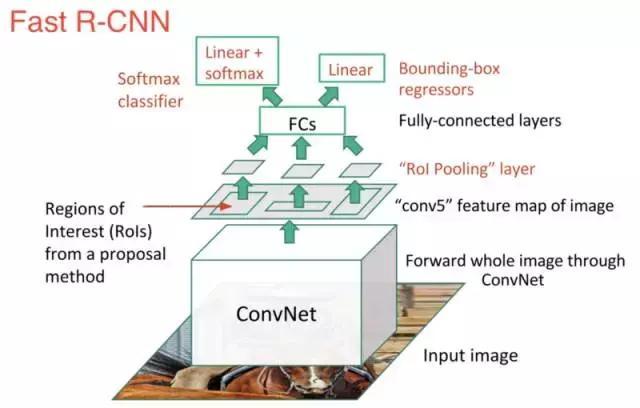
正如我們從圖像中看到的那樣,我們現(xiàn)在正在根據(jù)網(wǎng)絡(luò)的最后一個(gè)特征映射,而不是從原始圖像本身生成區(qū)域提案。因此,我們可以為整個(gè)圖像訓(xùn)練一個(gè)CNN。
此外,代替訓(xùn)練許多不同的SVM來對每個(gè)目標(biāo)類進(jìn)行分類的方法是,有一個(gè)多帶帶的softmax層可以直接輸出類概率。現(xiàn)在我們只有一個(gè)神經(jīng)網(wǎng)需要訓(xùn)練,而不是一個(gè)神經(jīng)網(wǎng)絡(luò)和許多SVM。
Fast-R-CNN在速度方面表現(xiàn)更好,只剩下一個(gè)大瓶頸:用于生成區(qū)域提案的選擇性搜索算法。
Faster R-CNN
在這一點(diǎn)上,我們回到了原來的目標(biāo):Faster R-CNN,F(xiàn)aster R-CNN的主要特點(diǎn)是用快速神經(jīng)網(wǎng)絡(luò)來代替慢速的選擇性搜索算法。具體來說,介紹了區(qū)域提議網(wǎng)絡(luò)(RPN)。
以下是RPN的工作原理:
?在初始CNN的最后一層,3x3滑動(dòng)窗口移動(dòng)到特征映射上,并將其映射到較低維度(例如256-d)。
?對于每個(gè)滑動(dòng)窗口位置,它基于k個(gè)固定比例錨定框(默認(rèn)邊界框)生成多個(gè)可能的區(qū)域。
?每個(gè)區(qū)域提議包括a)該區(qū)域的“目標(biāo)”得分,以及b)表示該區(qū)域邊界框的4個(gè)坐標(biāo)。
換句話說,我們來看看最后特征映射中的每一個(gè)位置,并考慮圍繞它的k個(gè)不同的框:一個(gè)高框,一個(gè)寬框,一個(gè)大框等。對于每個(gè)框,我們要考慮的是它是否包含一個(gè)目標(biāo),以及該框的坐標(biāo)是什么。這就是它在一個(gè)滑動(dòng)窗口位置的樣子:
?
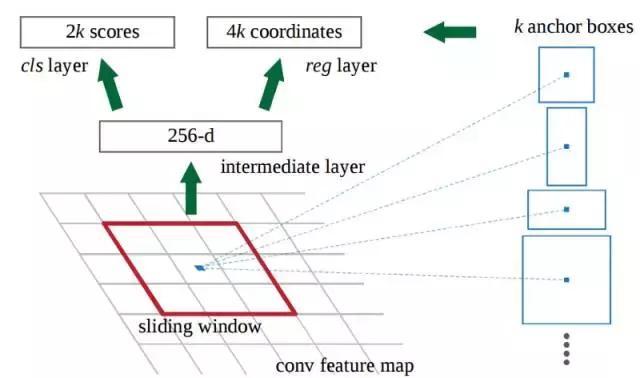
2k分?jǐn)?shù)表示每個(gè)k邊界框在“目標(biāo)”上的softmax概率。請注意,雖然RPN輸出的是邊界框坐標(biāo),但它并沒有嘗試對任何潛在目標(biāo)進(jìn)行分類:其的工作仍然是提出目標(biāo)區(qū)域。 如果錨箱(anchor box)的“對象”得分高于某個(gè)閾值,則該框的坐標(biāo)將作為區(qū)域提議向前傳遞。
一旦我們有了區(qū)域提議,我們將把它們直接饋送到一個(gè)本質(zhì)上是Fast R-CNN的網(wǎng)絡(luò)中。我們添加一個(gè)池化層,一些完全連接層,最后添加一個(gè)softmax分類層和邊界盒回歸(bounding box regressor)。在某種意義上,F(xiàn)aster R-CNN = RPN + Fast R-CNN。
?
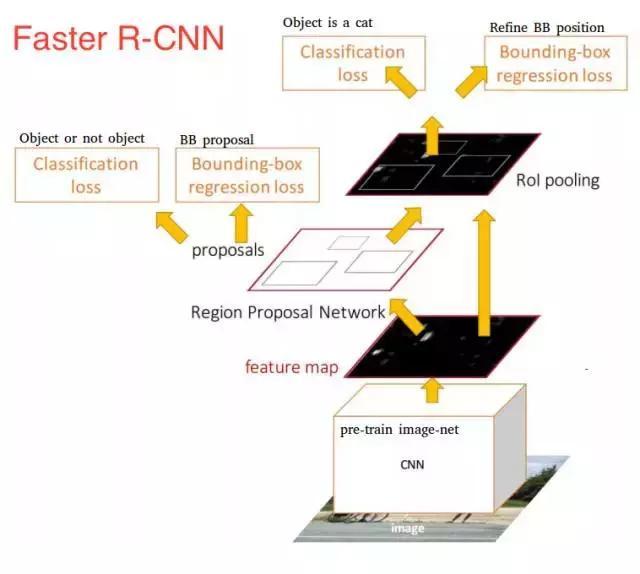
總而言之,F(xiàn)aster R-CNN取得了更好的速度和較先進(jìn)的精度。值得注意的是,盡管未來的模型確實(shí)提高了檢測速度,但是很少有模型能夠能夠以顯著的優(yōu)勢戰(zhàn)勝Faster R-CNN。換句話說,F(xiàn)aster R-CNN可能不是目標(biāo)檢測的最簡單或最快的方法,但它仍然是性能較好的方法之一。例如,具有Inception ResNet的Tensorflow的Faster R-CNN是他們最慢但最準(zhǔn)確的模型。
最后要說的是,F(xiàn)aster R-CNN可能看起來很復(fù)雜,但其核心設(shè)計(jì)與原始R-CNN相同:假設(shè)目標(biāo)區(qū)域,然后對其進(jìn)行分類。現(xiàn)在這是許多目標(biāo)檢測模型中的主要流水線,當(dāng)然也包括下一個(gè)我們要介紹的。
R-FCN
還記得Fast R-CNN是如何通過在所有區(qū)域提議中共享單個(gè)CNN計(jì)算,以可以提高原始檢測速度的嗎?這種想法也是R-FCN背后的動(dòng)機(jī):通過較大化共享計(jì)算來提高速度。
R-FCN或基于區(qū)域的完全卷積網(wǎng)絡(luò),在每個(gè)單個(gè)輸出中共享100%的計(jì)算。它是一個(gè)完全卷積,在模型設(shè)計(jì)中遇到了一個(gè)獨(dú)特的問題。
一方面,當(dāng)對目標(biāo)進(jìn)行分類時(shí),我們想在模型中學(xué)習(xí)位置不變性:不管貓出現(xiàn)在圖像中的什么位置,我們都希望的是將其分類為貓。另一方面,當(dāng)執(zhí)行目標(biāo)象的檢測時(shí),我們想要學(xué)習(xí)位置方差:如果貓?jiān)谧笊辖牵覀円谧笊辖抢L制一個(gè)框。那么,如果我們試圖在100%的網(wǎng)絡(luò)中共享卷積計(jì)算,那么我們?nèi)绾卧谖恢貌蛔冃院臀恢梅讲钪g進(jìn)行妥協(xié)呢?
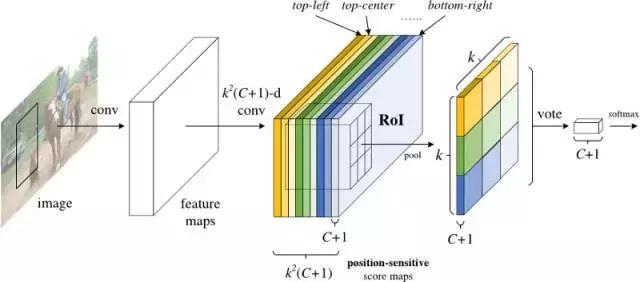
R-FCN的解決方案:位置敏感分?jǐn)?shù)圖(position-sensitive score maps)
每個(gè)位置敏感分?jǐn)?shù)圖表示一個(gè)目標(biāo)類的一個(gè)相對位置。例如,一個(gè)分?jǐn)?shù)圖可以激活它檢測到的貓的右上角的任何位置,另一個(gè)得分圖可能會激活它看到一輛汽車的底部。現(xiàn)在你明白了吧,本質(zhì)上說,這些分?jǐn)?shù)圖是經(jīng)過訓(xùn)練以識別每個(gè)目標(biāo)的某些部分的卷積特征圖。
現(xiàn)在,R-FCN的工作原理如下:
1. 在輸入圖像上運(yùn)行CNN(在這種情況下,應(yīng)為ResNet)。
2.添加一個(gè)完整的卷積層以產(chǎn)生上述“位置敏感分?jǐn)?shù)圖”的分?jǐn)?shù)庫。應(yīng)該有k2(C + 1)個(gè)分?jǐn)?shù)圖,其中k ^2表示用于劃分目標(biāo)的相對位置數(shù)(例如,3^2表示 3×3網(wǎng)格),C + 1表示類加上背景的數(shù)量。
3.運(yùn)行完全卷積區(qū)域提議網(wǎng)絡(luò)(RPN)來生成感興趣的區(qū)域(RoI)。
4.對于每個(gè)RoI,將其劃分為與分?jǐn)?shù)圖相同的k2個(gè)“bin”或子區(qū)域。
5.對于每個(gè)bin,請檢查分?jǐn)?shù)庫,以查看該bin是否與某個(gè)目標(biāo)的相應(yīng)位置相匹配。例如,如果我在“左上角”bin,我將抓住與目標(biāo)的“左上角”對應(yīng)的得分圖,并平均RoI區(qū)域中的這些值。每個(gè)類都要重復(fù)此過程。
6.一旦k2個(gè)bin中的每一個(gè)都有一個(gè)與每個(gè)類相對應(yīng)的“目標(biāo)匹配”值,那么,每個(gè)類就可以平均每個(gè)bin以得到一個(gè)單一的分?jǐn)?shù)。
7.在剩余的C + 1維向量上用softmax對RoI進(jìn)行分類。
總而言之,R-FCN看起來像這樣,RPN產(chǎn)生了RoI的內(nèi)容:
?
即使有了解釋和圖像,你可能仍然對此模型的工作原理有些困惑。老實(shí)說,當(dāng)你可以想象它在做什么時(shí),R-FCN可能就更容易理解了。這又一個(gè)用R-FCN進(jìn)行實(shí)踐的例子,檢測一個(gè)嬰兒:

簡單地說,R-FCN考慮到每個(gè)區(qū)域的建議,將其劃分為子區(qū)域,并在子區(qū)域內(nèi)進(jìn)行迭代,問:“這樣看起來像嬰兒的左上角嗎?”,“這樣看起來像嬰兒的正上方嗎?”“這樣看起來像一個(gè)嬰兒的右上角嗎?”等等。它重復(fù)了所有可能的類。如果有足夠多的子區(qū)域說“是的,我和寶寶的那一部分匹配”,那么在對所有類進(jìn)行softmax之后,RoI被歸類為一個(gè)寶寶。
通過這種設(shè)置,R-FCN能夠通過提出不同的目標(biāo)區(qū)域來解決位置方差,并且通過使每個(gè)區(qū)域提議返回到相同的分?jǐn)?shù)圖,來同時(shí)解決位置不變性。這些分?jǐn)?shù)圖應(yīng)該學(xué)會將貓分類為貓,而不管貓出現(xiàn)在哪里。最重要的是,它是完全卷積的,意味著所有的計(jì)算都在整個(gè)網(wǎng)絡(luò)中共享。
因此,R-FCN比Faster R-CNN快幾倍,并且具有可觀的準(zhǔn)確性。
SSD
我們的最終模型是SSD,它表示Single-Shot Detector。像R-FCN一樣,它提供了比Faster R-CNN更快的速度,但是是以一種截然不同的方式。
我們的前兩個(gè)模型分別在兩個(gè)不同的步驟中進(jìn)行區(qū)域建議和區(qū)域分類。首先,他們使用區(qū)域提議網(wǎng)絡(luò)來產(chǎn)生感興趣的區(qū)域;接下來,他們使用完全連接層或位置敏感卷積層來對這些區(qū)域進(jìn)行分類。而SSD在“single shot”中將兩者同時(shí)進(jìn)行,在處理圖像時(shí),同時(shí)預(yù)測邊框和類。
具體來說,給定一個(gè)輸入圖像和一組地面真相標(biāo)簽,SSD將執(zhí)行以下操作:
1.通過一系列卷積層傳遞圖像,在不同的尺度上產(chǎn)生幾個(gè)不同的特征映射(例如10×10,然后6×6,然后3×3等)。
2.對于每個(gè)這些特征映射中的每個(gè)位置,使用3x3的卷積濾波器來評估一小組默認(rèn)邊界框。這些默認(rèn)邊界框本質(zhì)上等同于Faster R-CNN的錨箱。
3.對于每個(gè)框,同時(shí)預(yù)測a)邊界框偏移量和b)類概率。
4.在訓(xùn)練過程中,將地面真相框與基于IoU的預(yù)測方框進(jìn)行匹配。較好的預(yù)測框?qū)⒈粯?biāo)記為“positive”,以及其他所有具有實(shí)際值> 0.5的IoU框。
SSD聽起來很簡單,但訓(xùn)練起來卻有一個(gè)獨(dú)特的挑戰(zhàn)。在前兩種模型中,區(qū)域提議網(wǎng)絡(luò)確保了我們試圖分類的所有東西都有一個(gè)成為“目標(biāo)”的最小可能性。但是,使用SSD,我們跳過了該過濾步驟。我們使用多種不同的形狀,以幾種不同的尺度,對圖像中的每個(gè)單個(gè)位置進(jìn)行分類和繪制邊界框。因此,我們可能會產(chǎn)生比其他模型更多的邊界框,而幾乎所有這些都是負(fù)面的樣本。
為了解決這個(gè)不平衡問題,SSD做了兩件事情。首先,它使用非較大抑制將高度重疊的邊框組合在一個(gè)邊框中。換句話說,如果有四個(gè)具有相同形狀和尺寸等因素的邊框包含著同樣一只狗,則NMS將保持具有較高置信度的那一個(gè),而將其余的丟棄。其次,該模型在訓(xùn)練期間使用一種稱為難分樣本挖掘(hard negative mining to balance classes)的技術(shù)來平衡類。在難分樣本挖掘中,在訓(xùn)練的每次迭代中僅使用具有較高訓(xùn)練損失(即假陽性)的負(fù)面樣本的一部分子集。SSD的負(fù)和正比例為3:1。
它的架構(gòu)如下所示:
?
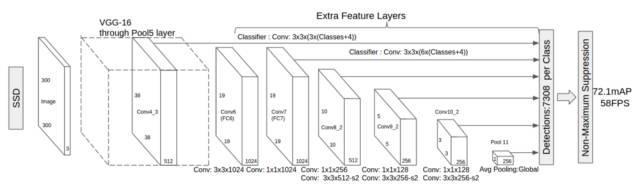
正如我上面提到的那樣,“額外的特征層”在最后尺寸將縮小。這些不同大小的特征映射有助于捕獲不同大小的目標(biāo)。例如,以下是SSD的操作:
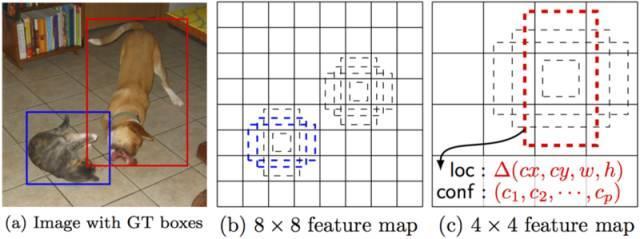
在較小的特征映射(例如4×4)中,每個(gè)單元覆蓋圖像種的較大區(qū)域,使得它們能夠檢測較大的目標(biāo)。區(qū)域提議和分類同時(shí)執(zhí)行:給定p目標(biāo)類,每個(gè)邊界框都與一個(gè)(4+p)的空間向量相關(guān)聯(lián),輸出4個(gè)方框偏移坐標(biāo)和p類的概率。在最后一步中,softmax再次被用于對目標(biāo)進(jìn)行分類。
最終,SSD與前兩個(gè)模型并沒有太大差別。它只是跳過“區(qū)域提議”這個(gè)步驟,而是考慮圖像種每個(gè)位置的每個(gè)單個(gè)邊界框,同時(shí)進(jìn)行分類。因?yàn)镾SD能夠一次性完成所有操作,所以它是這三個(gè)模型中速度最快的,而且執(zhí)行性能具有一定的可觀性。
結(jié)論
Faster R-CNN,R-FCN和SSD是目前市面上較好和最廣泛使用的三個(gè)目標(biāo)檢測模型。而其他受歡迎的模型往往與這三個(gè)模型非常相似,所有這些都依賴于深度CNN的知識(參見:ResNet,Inception等)來完成最初的繁重工作,并且大部分遵循相同的提議/分類流程。
在這一點(diǎn)上,想要使用這些模型的話,你只需要知道Tensorflow的API。Tensorflow有一個(gè)關(guān)于使用這些模型的一個(gè)入門教程,點(diǎn)擊此處鏈接獲得教程。(https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb)
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4639.html
摘要:值得一提的是每篇文章都是我用心整理的,編者一貫堅(jiān)持使用通俗形象的語言給我的讀者朋友們講解機(jī)器學(xué)習(xí)深度學(xué)習(xí)的各個(gè)知識點(diǎn)。今天,紅色石頭特此將以前所有的原創(chuàng)文章整理出來,組成一個(gè)比較合理完整的機(jī)器學(xué)習(xí)深度學(xué)習(xí)的學(xué)習(xí)路線圖,希望能夠幫助到大家。 一年多來,公眾號【AI有道】已經(jīng)發(fā)布了 140+ 的原創(chuàng)文章了。內(nèi)容涉及林軒田機(jī)器學(xué)習(xí)課程筆記、吳恩達(dá) deeplearning.ai 課程筆記、機(jī)...
摘要:是你學(xué)習(xí)從入門到專家必備的學(xué)習(xí)路線和優(yōu)質(zhì)學(xué)習(xí)資源。的數(shù)學(xué)基礎(chǔ)最主要是高等數(shù)學(xué)線性代數(shù)概率論與數(shù)理統(tǒng)計(jì)三門課程,這三門課程是本科必修的。其作為機(jī)器學(xué)習(xí)的入門和進(jìn)階資料非常適合。書籍介紹深度學(xué)習(xí)通常又被稱為花書,深度學(xué)習(xí)領(lǐng)域最經(jīng)典的暢銷書。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【導(dǎo)讀】本文由知名開源平...
摘要:本屆會議共收到論文篇,創(chuàng)下歷史記錄有效篇。會議接收論文篇接收率。大會共有位主旨演講人。同樣,本屆較佳學(xué)生論文斯坦福大學(xué)的,也是使用深度學(xué)習(xí)做圖像識別。深度學(xué)習(xí)選擇深度學(xué)習(xí)選擇不過,也有人對此表示了擔(dān)心。指出,這并不是做學(xué)術(shù)研究的方法。 2016年的計(jì)算機(jī)視覺領(lǐng)域國際頂尖會議 Computer Vision and Pattern Recognition conference(CVPR2016...
摘要:通過利用一系列利用視頻局部性的優(yōu)化,顯著降低了在每個(gè)幀上的計(jì)算量,同時(shí)仍保持常規(guī)檢索的高精度。的差異檢測器目前是使用逐幀計(jì)算的邏輯回歸模型實(shí)現(xiàn)的。這些檢測器在上的運(yùn)行速度非常快,每秒超過萬幀。也就是說,每秒處理的視頻幀數(shù)超過幀。 視頻數(shù)據(jù)正在爆炸性地增長——僅英國就有超過400萬個(gè)CCTV監(jiān)控?cái)z像頭,用戶每分鐘上傳到 YouTube 上的視頻超過300小時(shí)。深度學(xué)習(xí)的進(jìn)展已經(jīng)能夠自動(dòng)分析這些...

閱讀 3486·2021-10-18 13:30
閱讀 2940·2021-10-09 09:44
閱讀 1964·2019-08-30 11:26
閱讀 2287·2019-08-29 13:17
閱讀 757·2019-08-29 12:17
閱讀 2246·2019-08-26 18:42
閱讀 471·2019-08-26 13:24
閱讀 2951·2019-08-26 11:39





