hadoop托管SEARCH AGGREGATION


回答:Hadoop是目前被廣泛使用的大數(shù)據(jù)平臺,Hadoop平臺主要有Hadoop Common、HDFS、Hadoop Yarn、Hadoop MapReduce和Hadoop Ozone。Hadoop平臺目前被行業(yè)使用多年,有健全的生態(tài)和大量的應(yīng)用案例,同時Hadoop對硬件的要求比較低,非常適合初學(xué)者自學(xué)。目前很多商用大數(shù)據(jù)平臺也是基于Hadoop構(gòu)建的,所以Hadoop是大數(shù)據(jù)開發(fā)的一個重要內(nèi)容...
 wizChen
|
1278人閱讀
wizChen
|
1278人閱讀
回答:Hadoop生態(tài)Apache?Hadoop?項目開發(fā)了用于可靠,可擴(kuò)展的分布式計算的開源軟件。Apache Hadoop軟件庫是一個框架,該框架允許使用簡單的編程模型跨計算機(jī)集群對大型數(shù)據(jù)集進(jìn)行分布式處理。 它旨在從單個服務(wù)器擴(kuò)展到數(shù)千臺機(jī)器,每臺機(jī)器都提供本地計算和存儲。 庫本身不是設(shè)計用來依靠硬件來提供高可用性,而是設(shè)計為在應(yīng)用程序?qū)訖z測和處理故障,因此可以在計算機(jī)集群的頂部提供高可用性服務(wù),...
 娣辯孩
|
1494人閱讀
娣辯孩
|
1494人閱讀
回答:1998年9月4日,Google公司在美國硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。無獨有偶,一位名叫Doug?Cutting的美國工程師,也迷上了搜索引擎。他做了一個用于文本搜索的函數(shù)庫(姑且理解為軟件的功能組件),命名為Lucene。左為Doug Cutting,右為Lucene的LOGOLucene是用JAVA寫成的,目標(biāo)是為各種中小型應(yīng)用軟件加入全文檢索功能。因為好用而且開源(...
 ctriptech
|
850人閱讀
ctriptech
|
850人閱讀
回答:hive 我感悟是這樣的,hive類似于mysql和 mapreduce的結(jié)合品。1hive的語法 和mysql很像,但hive因為是依賴hdfs文件系統(tǒng)的,所以他有自己獨有的語法體系,比如 1 建表時它有分隔符的概念,2 插入時他有覆蓋的概念,3插入它不支持部分插入,只支持整體插入,4.不支持更新和刪除只支持查找,在查詢語法和mysql很像,但計算引擎和mysql完全不一樣。所以學(xué)習(xí)hive首先...
 ckllj
|
915人閱讀
ckllj
|
915人閱讀

...手本篇目錄創(chuàng)建集群提交任務(wù)本文檔將帶領(lǐng)您如何創(chuàng)建UHadoop集群,并使用UHadoop集群完成數(shù)據(jù)處理任務(wù)。創(chuàng)建集群本章簡單介紹了用戶使用UHadoop服務(wù)時如何快速創(chuàng)建集群,如已創(chuàng)建完畢,請?zhí)恋诙虏榭慈绾翁峤蝗蝿?wù)。1、進(jìn)...
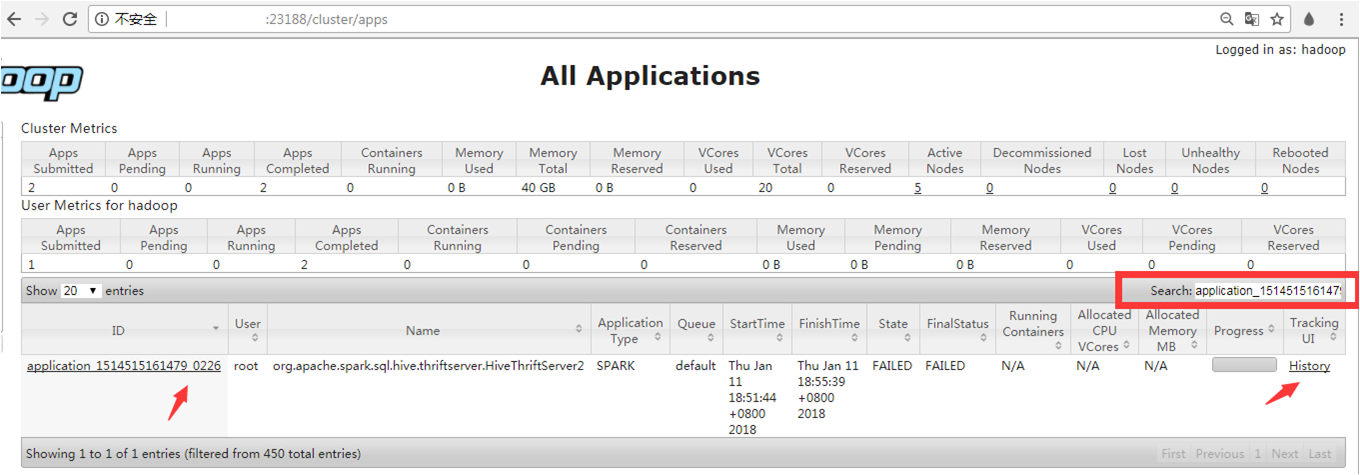
...用的Web接口查看日志配置NFS掛載hdfs到本地應(yīng)用的Web接口Hadoop 提供了基于 Web 的用戶界面,可通過它查看您的 Hadoop 集群。Web 服務(wù)會在主節(jié)點上運行(Active NameNode或者Active ResourceManager),綁定外網(wǎng)IP,開放對應(yīng)應(yīng)用防火墻端口后可...

...怎么辦?Hive執(zhí)行sql任務(wù)太慢,是否可以支持hive on spark?UHadoop暫時未支持hive on spark,但可通過使用Spark-sql代替,或者啟用Spark-thriftserver,通過beeline進(jìn)行連接。執(zhí)行SQL語句時,map/reduce任務(wù)內(nèi)存不足怎么辦?如果在日志文件中看到...
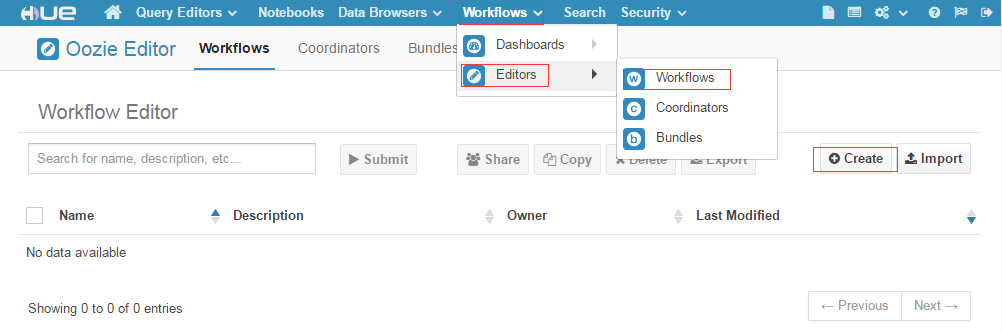
...指南本篇目錄1. 配置工作流2. Hue頁面權(quán)限控制Hue是面向 Hadoop 的開源用戶界面,可以讓您更輕松地運行和開發(fā) Hive 查詢、管理 HDFS 中的文件、運行和開發(fā) Pig 腳本以及管理表。服務(wù)默認(rèn)已經(jīng)啟動,用戶只需要配置外網(wǎng)IP,在防火墻...
據(jù)均衡.png?v=1644489545)
...在節(jié)點提交均衡命令是判斷集群是否平衡的目標(biāo)參數(shù)。 Hadoop本篇目錄訪問HDFS數(shù)據(jù)提示Operation category READ is not supported in state standby?為什么HDFS實際可用空間比配置的小?為什么/home/hadoop/etc/hadoop/slaves沒有指定其他節(jié)點IP,只配置...
...增大任務(wù)參數(shù)--driver-memory; b.降低任務(wù)并行度,修改/home/hadoop/spark/conf/spark-defaults.conf,添加spark.default.parallelism 40java.lang.ClassNotFoundException原因:提交任務(wù)時缺少相關(guān)jar包,具體可根據(jù)java.lang.ClassNotFoundException后面...
...境變量是否有做修改。3.檢查日志通常提交的任務(wù)可以在hadoop-yarn的界面可以看到,如無法查看任務(wù)通常有以下幾種情況:- spark任務(wù)用本地模式提交 - hive任務(wù)用本地提交(hive-server2默認(rèn)會將一些小任務(wù)用本地模式跑)集群運行速...
...交應(yīng)用程序。該隊列的管理員列表。 隊列管理本篇目錄Hadoop配置隊列Hadoop配置隊列用戶可于 控制臺-服務(wù)管理 進(jìn)行隊列配置,具體可參考基本操作。由于Fair Scheduler比Capacity Scheduler 支持的功能豐富,這里只介紹前者。修改/home/ha...
...如下,其他可用區(qū)價格請咨詢技術(shù)支持。 產(chǎn)品價格托管 Hadoop 集群價格根據(jù)節(jié)點類型及配置不同 ,北京、上海、廣州、香港可用區(qū)詳細(xì)價格如下,其他可用區(qū)價格請咨詢技術(shù)支持。 節(jié)點類型機(jī)型名稱CPU內(nèi)存(G)硬盤(G)華北一E價格...
.png?v=1644489545)
元數(shù)據(jù)管理本篇目錄介紹產(chǎn)品架構(gòu)元數(shù)據(jù)管理介紹UHadoop 支持將 Hive-Metastore 的數(shù)據(jù)庫獨立于 Hadoop 集群部署,也支持多個集群訪問同一個 Hive 元數(shù)據(jù)庫,可在控制臺對其做管理。產(chǎn)品架構(gòu)Hive 元數(shù)據(jù)存儲于 UCloud UDB MySQL 中。元數(shù)...
端口配置 配置名UHadoop默認(rèn)配置yarn.resourcemanager.zk-addresslocalhost:2181yarn.resourcemanager.address.rm1master1:23140yarn.resourcemanager.address.rm2master2:23140yarn.resourcemanager.scheduler.address.rm1mast...
Python如何為Python安裝新的庫?1.yum安裝可以使用yum search命令來查找具體的包名稱 請確認(rèn)ucloud源上的版本是否和預(yù)期的版本一致 2.pip安裝如果本地源上面沒有,yum和pip都可以通過設(shè)置代理來通過有外網(wǎng)權(quán)限的機(jī)器來下載參考yum設(shè)...
摘要:如果頻繁遇到這個問題可能是的參數(shù)或者其他方面設(shè)置的不合理,需要調(diào)整一下。 HBase本篇目錄HBase某一個表數(shù)據(jù)無法寫入,也無法讀取,從WebUI界面查看到有多個Region狀態(tài)為region in transaction是因為?讀取、寫入數(shù)據(jù)時,...
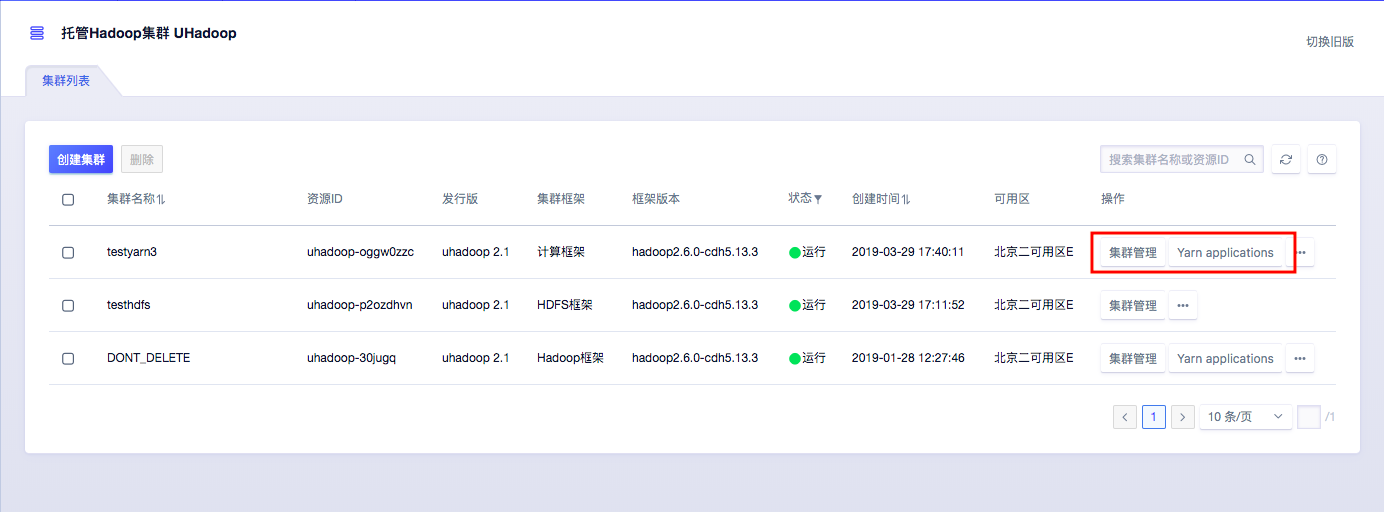
...均衡Yarn Application跟蹤集群管理1、進(jìn)入集群管理頁面通過UHadoop集群列表頁面進(jìn)入集群管理頁面:2、獲取當(dāng)前節(jié)點配置信息本例中,Master 節(jié)點數(shù)量 2,機(jī)型為 C1-large;Core 節(jié)點數(shù)量為 2,機(jī)型為 F1-large。3、添加節(jié)點點擊添加節(jié)點后...
ChatGPT和Sora等AI大模型應(yīng)用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓(xùn)練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關(guān)性能圖表。同時根據(jù)訓(xùn)練、推理能力由高到低做了...




 dmlllll
dmlllll 鄒立鵬
鄒立鵬





