4090算力SEARCH AGGREGATION


...ng: 0.034em; text-align: justify; font-size: 16px;>RTX 4090在FP16算力上達到了330 TFlops,在FP32算力上達到了83 FPlops,這些數值表明該顯卡在處理復雜的算法和大規模數據集時具有極高的效率。RTX 4090在FP32模式下的算力雖然低于FP16,但仍...

...關于價格以下是市面上一家算力共享平臺的4090以及4090D云服務器的價格,其中我們可以看到,在內存更小,總存儲小地多且性能低10%的情況下,4090D的價格竟然是比性能更強且規格更大的4090貴出不少...
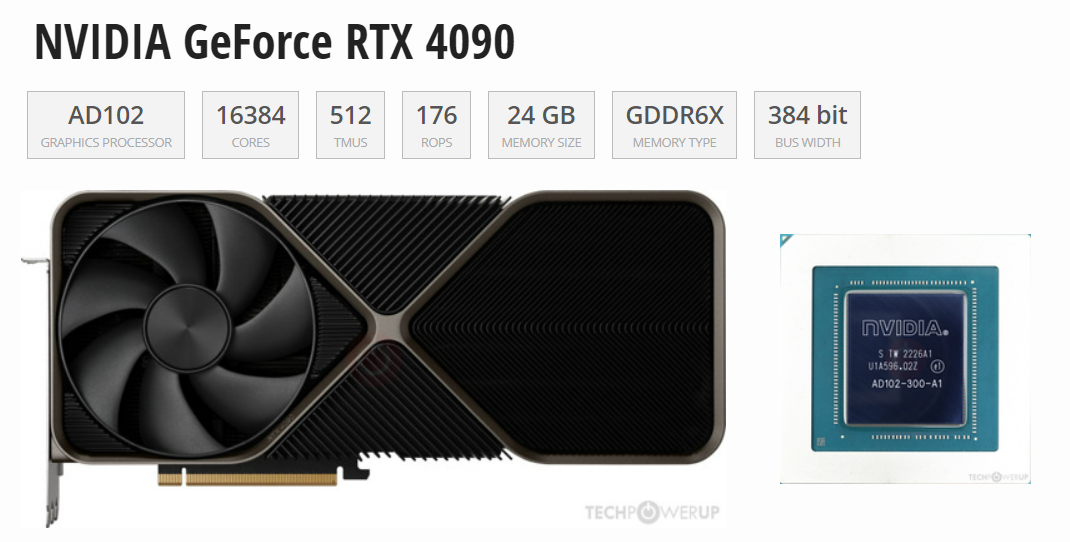
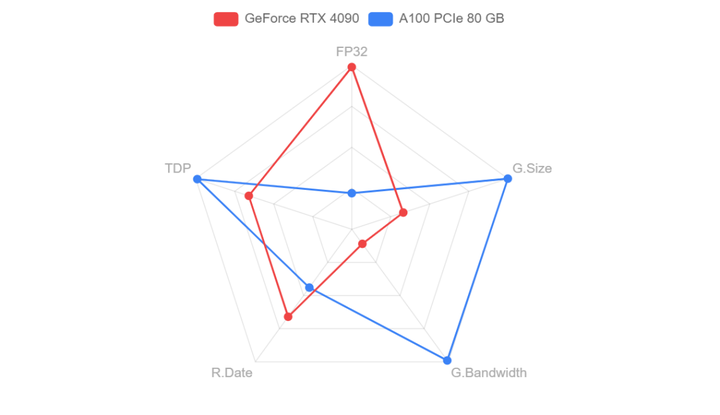
...但在和A100的PK中,4090與A100除了在顯存和通信上有差異,算力差異與顯存相比并不大,而4090是A100價格的1/10,因此如果用在模型推理場景下,4090性價比完勝!(尾部附參數源文件)
...前代產品,盡管其性能稍遜一籌,但其312 Tflops的Tensor FP16算力和156 Tflops的Tensor FP32算力仍然十分強勁。與H100相同的80 GB顯存和900 GB/s通信帶寬使得它在很多應用場景中依舊具有很高的性價比。

Compshare是一個專注于提供高性價比算力資源的平臺,它為AI訓練、深度學習、科研計算等場景提供強大的支持。平臺的核心優勢在于其高效的GPU算力資源,用戶可以根據自己的需求,靈活選擇不同的GPU配置,實現一鍵部署和即算...

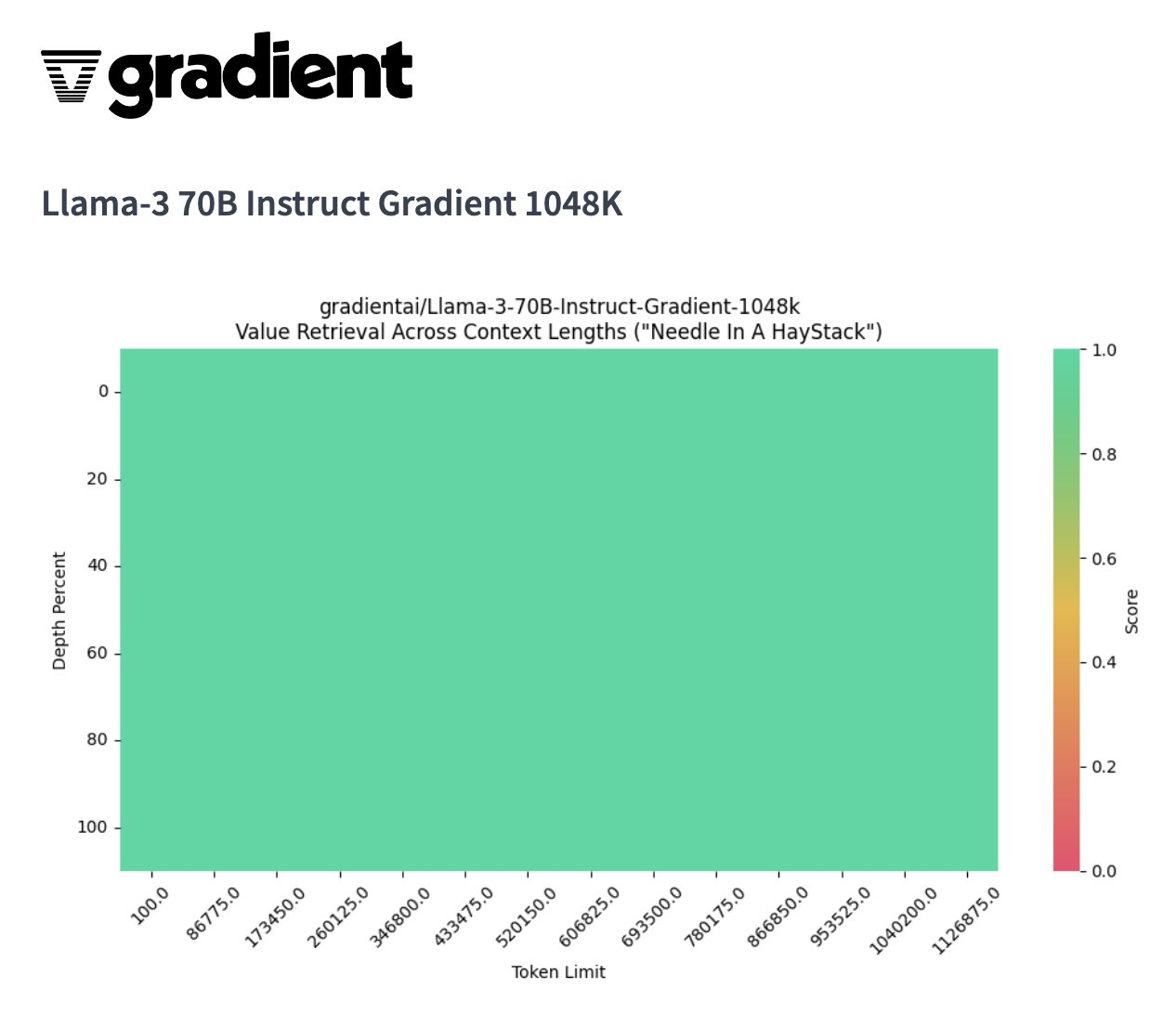
...70B 模型的參數是 140 GB,不管 A100/H100 還是 4090 都是單卡放不下的。那么 2 張 H100 夠嗎?看起來 160 GB 是夠了,但是剩下的 20 GB 如果用來放 KV Cache,要么把 batch size 壓縮一半,要么把 token 最大長度壓縮一半,聽起來...
.../specialneedsforspecialkids.com/site/active/gpu.html?ytag=seocompshare算力共享平臺,高性價比4090顯卡,配備獨立IP,支持按時、按天、按月靈活計費。適合AI推理、微調用戶場景使用。https://www.compshare.cn/?ytag=seo&...

Llama3 中文聊天項目綜合資源庫,該文檔集合了與Lama3 模型相關的各種中文資料,包括微調版本、有趣的權重、訓練、推理、評測和部署的教程視頻與文檔。1. 多版本支持與創新:該倉庫提供了多個版本的Lama3 模型,包括基于不...

隨著大型模型技術的持續發展,視頻生成技術正逐步走向成熟。以Sora、Gen-3等閉源視頻生成模型為代表的技術,正在重新定義行業的未來格局。而近幾個月,國產的AI視頻生成模型也是層出不窮,像是快手可...

...隊。人工智能憑什么能夠戰勝人類?答案是AI背后的超級算力。AI通過算力處理大量的相關數據,并以神經網絡不斷學習成長,最終獲得技能,戰勝人類選手。算力經濟,算力時代,算力改變世界,算力驅動未來,算力……現在...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
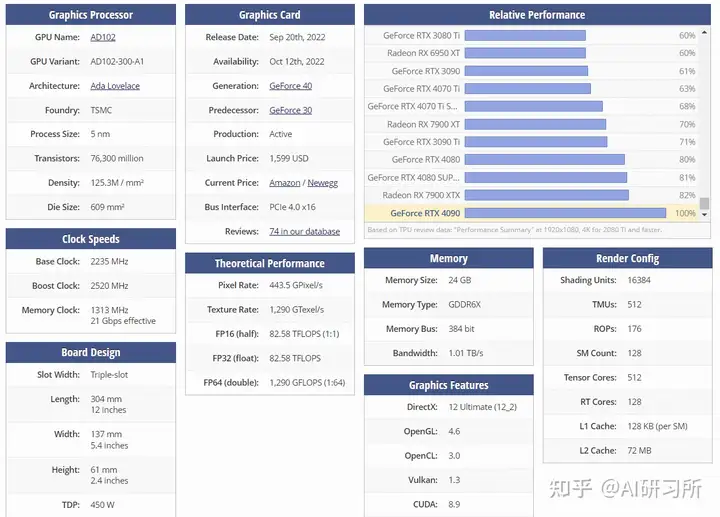
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...








