資訊專欄INFORMATION COLUMN

摘要:在實踐中,幾乎總是通過向梯度增加來實現(xiàn)算法,而不是真正改變損失函數(shù)。顯然這是兩種不同的方法。那么,權(quán)重衰減是不是總比的正則化更好呢我們還沒發(fā)現(xiàn)明顯更糟的情況,但無論是遷移學(xué)習(xí)問題例如斯坦福汽車數(shù)據(jù)集上的的微調(diào)還是
跌宕起伏的 Adam
縱觀 Adam 優(yōu)化器的發(fā)展歷程,就像過山車一樣。它于 2014 年在論文 Adam: A Method for Stochastic Optimization(https://arxiv.org/abs/1412.6980 )中首次提出,其核心是一個簡單而直觀的想法:既然我們明確地知道某些參數(shù)需要移動得更快、更遠(yuǎn),那為什么每個參數(shù)還要遵循相同的學(xué)習(xí)率呢?因為最近梯度的平方告訴我們每增加一個權(quán)重可以得到多少個信號,所以我們可以除以它來確保即使是最緩慢的權(quán)重也能獲得“發(fā)光”的機會。Adam 接受了這個想法,在過程中增加了標(biāo)準(zhǔn)方法,Adam 優(yōu)化器就這樣誕生了。它需要稍微調(diào)整來避免早期批出現(xiàn)偏差。
當(dāng)論文首次發(fā)布時,原論文中的一些圖表(如下圖所示)讓深度學(xué)習(xí)社區(qū)感到興奮不已:

Adam 和其他優(yōu)化器的對比
訓(xùn)練速度加快了 200%!
“總體來看,我們發(fā)現(xiàn) Adam 非常強大,非常適用于時下機器學(xué)習(xí)領(lǐng)域中的各種非凸優(yōu)化問題。”論文如此總結(jié)道。那是三年前深度學(xué)習(xí)最輝煌的時候。但事情后來并沒有像我們所期望的那樣發(fā)展,很少見到有研究文章使用 Adam 來訓(xùn)練模型,新的研究也開始明顯地不鼓勵使用 Adam(如論文 The Marginal Value of Adaptive Gradient Methods in Machine Learning,https://arxiv.org/abs/1705.08292 ),并通過幾個實驗結(jié)果表明,普通的 SGD+Momentum 可能比復(fù)雜的 Adam 表現(xiàn)更好。在 2018 年 fast.ai 的課程中,可憐的 Adam 就被從早期課程中剔除了。
但在 2017 年底,Adam 似乎獲得了重生。Ilya Loshchilov 和 Frank Hutter 在他們的論文 Fixing Weight Decay Regularization in Adam(https://arxiv.org/abs/1711.05101 )中指出,在每個庫中在 Adam 上實施的權(quán)重衰減似乎都是錯誤的,并提出了一種簡單的方法(他們稱之為 AdamW)來修復(fù)這個問題。雖然他們的結(jié)果略有不同,但是他們確實給出了一些令人鼓舞的圖表,如下圖所示:
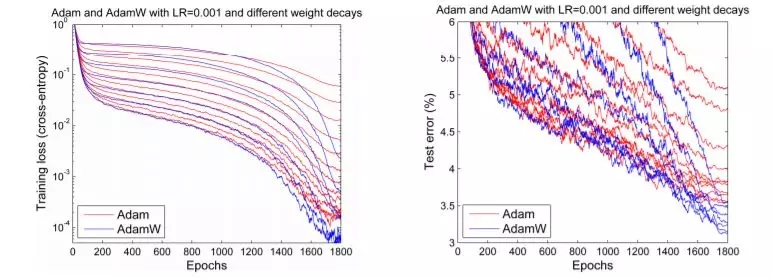
Adam 和 AdamW 對比
我們期待人們能夠?qū)?Adam 重燃熱情,因為它的一些早期結(jié)果似乎已經(jīng)可以重現(xiàn)。但事實并非如此。應(yīng)用它的一個深度學(xué)習(xí)框架是 fastai,使用的是 Sylvain 編寫的代碼。但因為缺乏可用的通用框架,日常實踐者就被又舊又難用的 Adam 所困。
但這并不是問題,前方還有更多的障礙。有兩篇論文分別指出了 Adam 在收斂性證明方面存在明顯的問題。盡管其中一篇論文提出了解決方案(并在久負(fù)盛名的 ICLR 大會上獲得了“較佳論文”獎),他們稱之為_AMSGrad_。但是,如果要說我們從這段充滿戲劇化的生活(至少按照優(yōu)化器的標(biāo)準(zhǔn)而言是戲劇化的)中學(xué)到了什么,那就是,沒有什么是表面看到的那樣。事實上,博士生 Jeremy Bernstein 在博文 On the Convergence of Adam and Beyond(https://openreview.net/forum?id=ryQu7f-RZ?eId=B1PDZUChG )中指出,所謂的收斂問題實際上只是超參數(shù)選擇不當(dāng),也許 AMSGrad 并不能解決問題。另一名博士生 Filip Korzeniowski 在論文 Experiments with AMSGrad(https://fdlm.github.io/post/amsgrad/ ) 中展示了一些早期研究成果,似乎也證明了這個令人沮喪的觀點。
Adam 到底怎么樣?
對于那些只想快速訓(xùn)練較精確模型的人,我們該做些什么呢?讓我們用數(shù)百年來解決科學(xué)辯論的方式來解決這一爭議:做實驗!
我們將在本文稍后闡述所有的細(xì)節(jié),但先讓我們看一下大致結(jié)果:
適當(dāng)調(diào)參之后,Adam 真的是能用的!我們在各種任務(wù)上獲得了訓(xùn)練時間方面的結(jié)果如下:
在含有測試時間增加的 18 個 epoch 或 30 個 epoch 訓(xùn)練 CIFAR10,使其準(zhǔn)確率超過 94%,如 DAWNBech 競賽;
只需 60 個 epoch 即可對 Resnet50 進行調(diào)參,使其在斯坦福汽車數(shù)據(jù)集的準(zhǔn)確率達到 90%,據(jù)報告稱,之前要達到相同的準(zhǔn)確率需 600 個 epoch;
從零開始訓(xùn)練 AWD LSTM 或 QRNN(見論文 Regularizing and Optimizing LSTM Language Models,https://arxiv.org/abs/1708.02182 ),需 90 個 epoch(或在單個 GPU 上訓(xùn)練一個半小時),其困惑度在 Wikitext-2 達到當(dāng)前最優(yōu)水平,據(jù)之前報告稱,LSTM 需要 750 個 epoch,QRNN 需要 500 個 epoch。
這意味著我們已經(jīng)看到了使用 Adam 的超收斂!(參見論文 Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates,https://arxiv.org/abs/1708.07120 )超收斂是訓(xùn)練學(xué)習(xí)率高的神經(jīng)網(wǎng)絡(luò)時出現(xiàn)的一種現(xiàn)象,表示節(jié)約了一半的訓(xùn)練時間。在人們了解 AdamW 之前,人們訓(xùn)練 CIFAR10 使其準(zhǔn)確率達到 94% 需要大約 100 個 epoch。
與之前的工作相比,我們發(fā)現(xiàn)只要調(diào)整得當(dāng),Adam 在嘗試過的每一個 CNN 圖像問題上都能獲得與 SGD+Momentum 一樣的準(zhǔn)確率,而且,幾乎總是快一點。
至于有人認(rèn)為 AMSGrad 是一個槽糕的“解決方案”,這種看法是正確的。我們一直發(fā)現(xiàn),AMSGrad 的準(zhǔn)確率(或其他相關(guān)指標(biāo))并沒有獲得比普通的 Adam/AdamW 更高的增益。
如果你聽到人們說 Adam 的泛化性能不如 SGD+Momentum 時,你基本就會發(fā)現(xiàn)他們?yōu)樽约旱哪P瓦x擇的超參數(shù)其實蠻糟糕的。通常情況下,Adam 需要比 SGD 更多的正則化,因此,當(dāng)從 SGD 轉(zhuǎn)向到 Adam 時,一定要確保調(diào)整正則化超參數(shù)。
AdamW
理解 AdamW:權(quán)重衰減與 L2 正則化
L2 正則化是減少過擬合的經(jīng)典方法,它向損失函數(shù)添加模型的所有權(quán)重的平方和組成的懲罰項,乘以特定的超參數(shù)來控制懲罰力度(在本文中,所有的方程式均使用 Python、NumPy 和 PyTorch 表示法):
final_loss = loss + wd * all_weights.pow(2).sum() / 2
其中,wd是我們設(shè)置的超參數(shù),也可稱為權(quán)重衰減,因為運用 vanilla SGD 時,它相當(dāng)于使用如下方程式更新權(quán)重:
w = w - lr * w.grad - lr * wd * w
其中,lr表示學(xué)習(xí)率,w2表示損失函數(shù)對w的導(dǎo)數(shù),wd*w表示懲罰項對w的求導(dǎo)結(jié)果。在這個方程式中,我們可以看到每一次更新都會減去一小部分權(quán)重,因此這就是命名為“衰減”的原因。
我們注意到所有的庫都使用了第一種形式。在實踐中,幾乎總是通過向梯度增加wd*d來實現(xiàn)算法,而不是真正改變損失函數(shù)。因為我們不希望還有其他更簡單的方法的情況下,增加額外的計算量來修正損失。
如果這兩個概念是一樣的話,那為什么還要區(qū)分這兩種概念呢?答案就是,它們對于 vanilla SGD 來說是等價的,一旦我們添加動量,或者使用像 Adam 那樣復(fù)雜的最優(yōu)化器,那么 L2 正則化(第一個方程式)和權(quán)重衰減(第二個方程式)就會變得不同。在本文其余部分中,我們討論的權(quán)重衰減都是指第二個方程式(權(quán)重將會衰減一點),而我們討論經(jīng)典方法時就會討論 L2 正則化。
讓我們來看看帶動量的 SGD。使用 L2 正則化會在梯度上添加wd*d(正如我們前面所述),但梯度并不是直接從權(quán)重中減去。首先我們要計算一個移動均值:
moving_avg = alpha * moving_avg + (1-alpha) * (w.grad + wd*w)
這個移動均值乘以學(xué)習(xí)率,再減去w得到權(quán)重的更新,因此w與正則化相關(guān)的部分是lr*(1-alpha)*wd*d加上已經(jīng)在moving_avg中前面權(quán)重的結(jié)合。
因此,權(quán)重衰減的更新方式可以如下表示:
moving_avg = alpha * moving_avg + (1-alpha) * w.grad?
w = w - lr * moving_avg - lr * wd * w
我們可以看到,從w連接到正則化的部分在兩種方法是不一樣的。在使用 Adam 優(yōu)化器時,權(quán)重衰減的部分可能相差很大:在 L2 正則化的情況下,我們將這個wd*d添加到梯度中,然后分別計算梯度機器平方的移動均值,然后再更新權(quán)重。然而權(quán)重衰減方法只是簡單地更新權(quán)重,然后每次從權(quán)重中減去一點。
顯然這是兩種不同的方法。在進行實驗之后,Ilya Loshchilov 和 Frank Hutter 在論文中建議我們應(yīng)該使用 Adam 的權(quán)重衰減方法,而不是像經(jīng)典深度學(xué)習(xí)庫中實現(xiàn)的 L2 正則化方法。
實現(xiàn) AdamW
那我們要怎么做才能實現(xiàn) AdamW 呢?如果你在使用 fastai 庫,那么在使用 fit 函數(shù)時只需添加參數(shù)use_wd_sched=True就能簡單地實現(xiàn)了:
learn.fit(lr, 1, wds=1e-4, use_wd_sched=True)
如果你更青睞新的訓(xùn)練 API,那你可以在每個訓(xùn)練階段中使用參數(shù)wd_loss=False(用于在衰減過程中沒有計算的權(quán)重衰減):
phases = [TrainingPhase(1, optim.Adam, lr, wds=1-e4, wd_loss=False)]
learn.fit_opt_sched(phases)
以下是我們在 fastai 中如何實現(xiàn) AdamW 的簡要總結(jié)。在優(yōu)化器中的階躍函數(shù)(step function)中,只需使用梯度修正參數(shù),根本不使用參數(shù)本身的值(除了權(quán)重衰減,我們將在外部處理)。我們可以在最優(yōu)化器步驟之前通過簡單的實現(xiàn)權(quán)重衰減,但這仍然需要在計算梯度之后才能完成,否則會影響梯度值。因此在訓(xùn)練循環(huán)中,我們必須確定計算權(quán)重衰減的位置。
loss.backward()
#Do the weight decay here!
optimizer.step()
當(dāng)然,最優(yōu)化器應(yīng)該設(shè)定為 wd=0,否則它還會做一些 L2 正則化,這也是我們不希望看到的。現(xiàn)在在權(quán)重衰減的位置中,我們可以在所有參數(shù)上進行循環(huán),并依次采用權(quán)重衰減的更新。我們的參數(shù)應(yīng)該存儲在優(yōu)化器的字典param_groups中,因此這個循環(huán)應(yīng)該如下段代碼所示那樣的:
loss.backward()
for group in optimizer.param_groups():
? ?for param in group["params"]:
? ? ? ?param.data = param.data.add(-wd * group["lr"], param.data)
optimizer.step()
AdamW 實驗結(jié)果:是否有效?
我們先在計算機視覺問題上進行了測試,結(jié)果令人鼓舞。具體來說,我們使用 Adam 和 L2 正則化在 30 個 epoch(這是 SGD 在 1cycle 策略(詳見 https://sgugger.github.io/the-1cycle-policy.html)中達到 94% 準(zhǔn)確率的必要時間)獲得的準(zhǔn)確率平均為 93.36%,在兩次中有一次超過了 94%。當(dāng)使用 Adam 和權(quán)重衰減方法時,我們始終得到的是 94%~94.25% 的準(zhǔn)確率。為此,我們發(fā)現(xiàn)使用 1cycle 策略時,beta2 的最優(yōu)值為 0.99。我們將 beta1 參數(shù)作為 SGD 的動量,也就是說,隨著學(xué)習(xí)率的增長,它從 0.95 降到 0.85,然后隨著學(xué)習(xí)率的降低又升到 0.95。

L2 正則化或權(quán)重衰減準(zhǔn)確率
更令人印象深刻的是,使用測試時間增加(即對測試集的一個圖像和它的四個數(shù)據(jù)增強版本進行預(yù)測的平均值),我們可以在僅僅 18 個 epoch 內(nèi)達到 94% 的準(zhǔn)確率(平均 93.98%)!使用簡單的 Adam 和 L2 正則化的話,每嘗試 20 個 epoch 就會出現(xiàn)一次超過 94% 的情況。
在這些比較中需要考慮的一件事是,改變正則化的方式會改變權(quán)重衰減或?qū)W習(xí)率的較佳值。在我們進行的測試中,L2 正則化的較佳學(xué)習(xí)率為 1e-6(較大學(xué)習(xí)率為 1e-3),而 0.3 是權(quán)重衰減的較佳值(學(xué)習(xí)率為 3e-3)。在我們的測試中,數(shù)量級的差異都是非常一致的,主要是因為 L2 正則化被梯度的平均范數(shù)(相當(dāng)?shù)停┯行У貏澐郑⑶?Adam 的學(xué)習(xí)率相當(dāng)小(所以權(quán)重衰減的更新需要更強的系數(shù))。
那么,權(quán)重衰減是不是總比 Adam 的 L2 正則化更好呢?我們還沒發(fā)現(xiàn)明顯更糟的情況,但無論是遷移學(xué)習(xí)問題(例如斯坦福汽車數(shù)據(jù)集上的 Resnet50 的微調(diào))還是 RNN,它都沒有給出更好的結(jié)果。
AMSGrad
理解 AMSGrad
AMSGrad 是由 Sashank J. Reddi、Satyen Kale 和 Sanjiv Kumar 在最近的一篇文章 On the Convergence of Adam and Beyond(https://openreview.net/forum?id=ryQu7f-RZ )中介紹的。通過分析 Adam 優(yōu)化器的收斂性證明,他們發(fā)現(xiàn)了更新規(guī)則中的一個錯誤,該錯誤可能導(dǎo)致算法收斂到次優(yōu)點。他們設(shè)計了理論實驗,展示了 Adam 失敗的情形,并提出了一個簡單的解決方案。
為了更好地理解錯誤和解決方案,讓我們看一下 Adam 的更新規(guī)則:
avg_grads = beta1 * avg_grads + (1-beta1) * w.grad
avg_squared = beta2 * (avg_squared) + (1-beta2) * (w.grad ** 2)
w = w - lr * avg_grads / sqrt(avg_squared)
我們剛剛跳過了偏差修正(這對訓(xùn)練的開始很有用) 來關(guān)注重點。作者發(fā)現(xiàn)的 Adam 收斂性證明中的錯誤之處在于它需要數(shù)量。
lr / sqrt(avg_squared)
這是我們朝著平均梯度方向邁出的一步,在訓(xùn)練中逐漸減少。由于學(xué)習(xí)率通常是常量或遞減的(除了像我們這樣瘋狂的人試圖獲得超收斂之外),作者提出的解決方案是通過添加另一個變量來跟蹤它們的較大值來迫使avg_square量增加。
實現(xiàn) AMSGrad
相關(guān)文章在 ICLR 2018 中獲得了一項大獎,并已經(jīng)在兩個主要的深度學(xué)習(xí)庫——PyTorch 和 Keras 中實現(xiàn)了。所以我們只要傳入?yún)?shù)amsgrad=True就萬事大吉了。
前一節(jié)中的權(quán)重更新代碼更改為如下內(nèi)容:
avg_grads = beta1 * avg_grads + (1-beta1) * w.grad
avg_squared = beta2 * (avg_squared) + (1-beta2) * (w.grad ** 2)
max_squared = max(avg_squared, max_squared)
w = w - lr * avg_grads / sqrt(max_squared)
AMSGrad 實驗結(jié)果:大量毫無意義的噪音
AMSGrad 的表現(xiàn)令人失望。我們發(fā)現(xiàn),在所有的實驗中,它一點用都沒有。即使 AMSGrad 發(fā)現(xiàn)的最小值確實有時比 Adam 達到的最小值略低(在損失方面),其度量(準(zhǔn)確率、f1 分?jǐn)?shù)等)最終總是更槽糕(請訪問此網(wǎng)址參閱更多表格和示例:https://fdlm.github.io/post/amsgrad/ )
Adam 優(yōu)化器在深度學(xué)習(xí)中收斂的證明(因為它是針對凸問題的)和他們在其中發(fā)現(xiàn)的錯誤對于與現(xiàn)實問題無關(guān)的合成實驗很重要。實際的測試表明,當(dāng)那些avg_squared梯度想要減少時,這樣做能得到較好的結(jié)果。
這表明,即使對理論的關(guān)注對獲得一些新想法很有用,也沒有什么能代替實驗(以及大量的實驗),以確保這些想法能夠幫助實踐者訓(xùn)練更好的模型。
附錄: 全部結(jié)果
從零開始訓(xùn)練 CIFAR10(模型是一個 WideResnet 22,如下表所示為五個模型的測試集中平均誤差結(jié)果):

使用 fastai 庫引入的標(biāo)準(zhǔn)頭對斯坦福汽車數(shù)據(jù)集上的 Resnet50 進行微調(diào)(在解凍前對頭進行 20 個 epoch 的訓(xùn)練,并用不同的學(xué)習(xí)率訓(xùn)練 40 個 epoch):

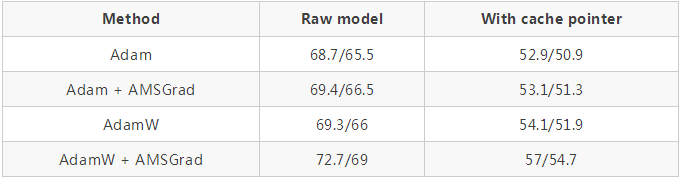
使用 github repo 中的超參數(shù)(https://github.com/salesforce/awd-lstm-lm )對 AWD LSTM 進行訓(xùn)練(結(jié)果顯示在有無緩存指針的情況下驗證 / 測試集的困惑度):
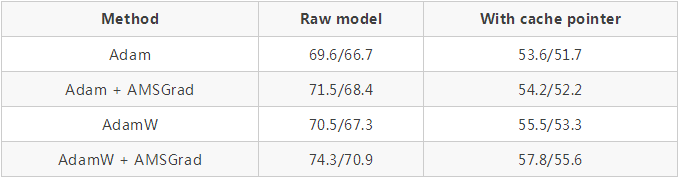
QRNNs 代替 LSTMs 也一樣:
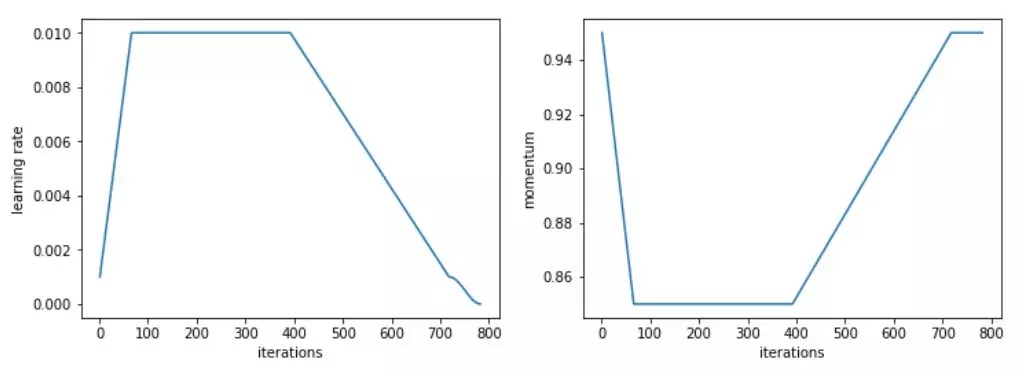
對于這個特定的任務(wù),我們使用了一個改進版本的 1cycle 策略,加快了學(xué)習(xí)速度,之后長時間保持較高的恒定學(xué)習(xí)速度,然后再次下降。
Adam 和其他優(yōu)化器之間的對比
所有相關(guān)超參數(shù)的值以及用于生成這些結(jié)果的代碼可訪問此網(wǎng)址來獲得:
https://github.com/sgugger/Adam-experiments
原文鏈接:
AdamW and Super-convergence is now the fastest way to train neural nets
http://www.fast.ai/2018/07/02/adam-weight-decay/
聲明:文章收集于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4810.html
摘要:二階動量的出現(xiàn),才意味著自適應(yīng)學(xué)習(xí)率優(yōu)化算法時代的到來。自適應(yīng)學(xué)習(xí)率類優(yōu)化算法為每個參數(shù)設(shè)定了不同的學(xué)習(xí)率,在不同維度上設(shè)定不同步長,因此其下降方向是縮放過的一階動量方向。 說到優(yōu)化算法,入門級必從SGD學(xué)起,老司機則會告訴你更好的還有AdaGrad / AdaDelta,或者直接無腦用Adam。可是看看學(xué)術(shù)界的paper,卻發(fā)現(xiàn)一眾大神還在用著入門級的SGD,最多加個Moment或者Nes...
摘要:近來在深度學(xué)習(xí)中,卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)等深度模型在各種復(fù)雜的任務(wù)中表現(xiàn)十分優(yōu)秀。機器學(xué)習(xí)中最常用的正則化方法是對權(quán)重施加范數(shù)約束。 近來在深度學(xué)習(xí)中,卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)等深度模型在各種復(fù)雜的任務(wù)中表現(xiàn)十分優(yōu)秀。例如卷積神經(jīng)網(wǎng)絡(luò)(CNN)這種由生物啟發(fā)而誕生的網(wǎng)絡(luò),它基于數(shù)學(xué)的卷積運算而能檢測大量的圖像特征,因此可用于解決多種圖像視覺應(yīng)用、目標(biāo)分類和語音識別等問題。但是,深層網(wǎng)絡(luò)...
摘要:前言標(biāo)題不能再中二了本文僅對一些常見的優(yōu)化方法進行直觀介紹和簡單的比較,各種優(yōu)化方法的詳細(xì)內(nèi)容及公式只好去認(rèn)真啃論文了,在此我就不贅述了。就是每一次迭代計算的梯度,然后對參數(shù)進行更新,是最常見的優(yōu)化方法了。 前言(標(biāo)題不能再中二了)本文僅對一些常見的優(yōu)化方法進行直觀介紹和簡單的比較,各種優(yōu)化方法的詳細(xì)內(nèi)容及公式只好去認(rèn)真啃論文了,在此我就不贅述了。SGD此處的SGD指mini-batch g...
摘要:本圖中的數(shù)據(jù)收集自利用數(shù)據(jù)集在英偉達上對進行訓(xùn)練的實際流程。據(jù)我所知,人們之前還無法有效利用諸如神威太湖之光的超級計算機完成神經(jīng)網(wǎng)絡(luò)訓(xùn)練。最終,我們用分鐘完成了的訓(xùn)練據(jù)我們所知,這是使用進行訓(xùn)練的世界最快紀(jì)錄。 圖 1,Google Brain 科學(xué)家 Jonathan Hseu 闡述加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練的重要意義近年來,深度學(xué)習(xí)的一個瓶頸主要體現(xiàn)在計算上。比如,在一個英偉達的 M40 GPU ...

閱讀 3715·2021-11-17 09:33
閱讀 2725·2021-09-22 15:12
閱讀 3344·2021-08-12 13:24
閱讀 2439·2019-08-30 11:14
閱讀 1733·2019-08-29 14:09
閱讀 1326·2019-08-26 14:01
閱讀 3061·2019-08-26 13:49
閱讀 1775·2019-08-26 12:16





