資訊專欄INFORMATION COLUMN

摘要:近來在深度學(xué)習(xí)中,卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)等深度模型在各種復(fù)雜的任務(wù)中表現(xiàn)十分優(yōu)秀。機器學(xué)習(xí)中最常用的正則化方法是對權(quán)重施加范數(shù)約束。
近來在深度學(xué)習(xí)中,卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)等深度模型在各種復(fù)雜的任務(wù)中表現(xiàn)十分優(yōu)秀。例如卷積神經(jīng)網(wǎng)絡(luò)(CNN)這種由生物啟發(fā)而誕生的網(wǎng)絡(luò),它基于數(shù)學(xué)的卷積運算而能檢測大量的圖像特征,因此可用于解決多種圖像視覺應(yīng)用、目標分類和語音識別等問題。
但是,深層網(wǎng)絡(luò)架構(gòu)的學(xué)習(xí)要求大量數(shù)據(jù),對計算能力的要求很高。神經(jīng)元和參數(shù)之間的大量連接需要通過梯度下降及其變體以迭代的方式不斷調(diào)整。此外,有些架構(gòu)可能因為強大的表征力而產(chǎn)生測試數(shù)據(jù)過擬合等現(xiàn)象。這時我們可以使用正則化和優(yōu)化技術(shù)來解決這兩個問題。
梯度下降是一種優(yōu)化技術(shù),它通過最小化代價函數(shù)的誤差而決定參數(shù)的最優(yōu)值,進而提升網(wǎng)絡(luò)的性能。盡管梯度下降是參數(shù)優(yōu)化的自然選擇,但它在處理高度非凸函數(shù)和搜索全局最小值時也存在很多局限性。
正則化技術(shù)令參數(shù)數(shù)量多于輸入數(shù)據(jù)量的網(wǎng)絡(luò)避免產(chǎn)生過擬合現(xiàn)象。正則化通過避免訓(xùn)練完美擬合數(shù)據(jù)樣本的系數(shù)而有助于算法的泛化。為了防止過擬合,增加訓(xùn)練樣本是一個好的解決方案。此外,還可使用數(shù)據(jù)增強、L1 正則化、L2 正則化、Dropout、DropConnect 和早停(Early stopping)法等。
增加輸入數(shù)據(jù)、數(shù)據(jù)增強、早停、dropout 及其變體是深度神經(jīng)網(wǎng)絡(luò)中常用的調(diào)整方法。本論文作為之前文章《徒手實現(xiàn) CNN:綜述論文詳解卷積網(wǎng)絡(luò)的數(shù)學(xué)本質(zhì) 》的補充,旨在介紹開發(fā)典型卷積神經(jīng)網(wǎng)絡(luò)框架時最常用的正則化和優(yōu)化策略。
主體論文:Regularization and Optimization strategies in Deep Convolutional Neural Network
論文地址:https://arxiv.org/pdf/1712.04711.pdf
摘要:卷積神經(jīng)網(wǎng)絡(luò)(ConvNet)在一些復(fù)雜的機器學(xué)習(xí)任務(wù)中性能表現(xiàn)非常好。ConvNet 架構(gòu)需要大量數(shù)據(jù)和參數(shù),因此其學(xué)習(xí)過程需要消耗大量算力,向全局最小值的收斂過程較慢,容易掉入局部極小值的陷阱導(dǎo)致預(yù)測結(jié)果不好。在一些案例中,ConvNet 架構(gòu)與數(shù)據(jù)產(chǎn)生過擬合,致使架構(gòu)難以泛化至新樣本。為了解決這些問題,近年來研究者開發(fā)了多種正則化和優(yōu)化策略。此外,研究顯示這些技術(shù)能夠大幅提升網(wǎng)絡(luò)性能,同時減少算力消耗。使用這些技術(shù)的前提是全面了解該技術(shù)提升網(wǎng)絡(luò)表達能力的理論原理,本論文旨在介紹開發(fā) ConvNet 架構(gòu)最常用策略的理論概念和數(shù)學(xué)公式。
正則化技術(shù)
正則化技術(shù)是保證算法泛化能力的有效工具,因此算法正則化的研究成為機器學(xué)習(xí)中主要的研究主題 [9] [10]。此外,正則化還是訓(xùn)練參數(shù)數(shù)量大于訓(xùn)練數(shù)據(jù)集的深度學(xué)習(xí)模型的關(guān)鍵步驟。正則化可以避免算法過擬合,過擬合通常發(fā)生在算法學(xué)習(xí)的輸入數(shù)據(jù)無法反應(yīng)真實的分布且存在一些噪聲的情況。過去數(shù)年,研究者提出和開發(fā)了多種適合機器學(xué)習(xí)算法的正則化方法,如數(shù)據(jù)增強、L2 正則化(權(quán)重衰減)、L1 正則化、Dropout、Drop Connect、隨機池化和早停等。
除了泛化原因,奧卡姆剃刀原理和貝葉斯估計也都支持著正則化。根據(jù)奧卡姆剃刀原理,在所有可能選擇的模型中,能很好解釋已知數(shù)據(jù),并且十分簡單的模型才是較好的模型。而從貝葉斯估計的角度來看,正則化項對應(yīng)于模型的先驗概率。
4.1 數(shù)據(jù)增強
數(shù)據(jù)增強是提升算法性能、滿足深度學(xué)習(xí)模型對大量數(shù)據(jù)的需求的重要工具。數(shù)據(jù)增強通過向訓(xùn)練數(shù)據(jù)添加轉(zhuǎn)換或擾動來人工增加訓(xùn)練數(shù)據(jù)集。數(shù)據(jù)增強技術(shù)如水平或垂直翻轉(zhuǎn)圖像、裁剪、色彩變換、擴展和旋轉(zhuǎn)通常應(yīng)用在視覺表象和圖像分類中。
4.2 L1 和 L2 正則化
L1 和 L2 正則化是最常用的正則化方法。L1 正則化向目標函數(shù)添加正則化項,以減少參數(shù)的值總和;而 L2 正則化中,添加正則化項的目的在于減少參數(shù)平方的總和。根據(jù)之前的研究,L1 正則化中的很多參數(shù)向量是稀疏向量,因為很多模型導(dǎo)致參數(shù)趨近于 0,因此它常用于特征選擇設(shè)置中。機器學(xué)習(xí)中最常用的正則化方法是對權(quán)重施加 L2 范數(shù)約束。
標準正則化代價函數(shù)如下:
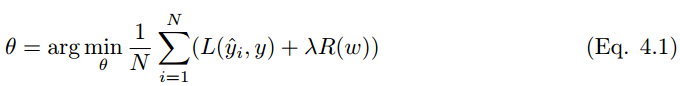
其中正則化項 R(w) 是:

另一種懲罰權(quán)重的值總和的方法是 L1 正則化:

L1 正則化在零點不可微,因此權(quán)重以趨近于零的常數(shù)因子增長。很多神經(jīng)網(wǎng)絡(luò)在權(quán)重衰減公式中使用一階步驟來解決非凸 L1 正則化問題 [19]。L1 范數(shù)的近似變體是:

另一個正則化方法是混合 L1 和 L2 正則化,即彈性網(wǎng)絡(luò)罰項 [20]。
在《深度學(xué)習(xí)》一書中,參數(shù)范數(shù)懲罰 L2 正則化能讓深度學(xué)習(xí)算法「感知」到具有較高方差的輸入 x,因此與輸出目標的協(xié)方差較小(相對增加方差)的特征權(quán)重將會收縮。而 L1 正則化會因為在方向 i 上 J(w; X, y) 對 J(w; X, y) hat 的貢獻被抵消而使 w_i 的值變?yōu)?0(J(w; X, y) hat 為 J(w; X, y) 加上 L1 正則項)。此外,參數(shù)的范數(shù)正則化也可以作為約束條件。對于 L2 范數(shù)來說,權(quán)重會被約束在一個 L2 范數(shù)的球體中,而對于 L1 范數(shù),權(quán)重將被限制在 L1 所確定的范圍內(nèi)。
4.3 Dropout
Bagging 是通過結(jié)合多個模型降低泛化誤差的技術(shù),主要的做法是分別訓(xùn)練幾個不同的模型,然后讓所有模型表決測試樣例的輸出。而 Dropout 可以被認為是集成了大量深層神經(jīng)網(wǎng)絡(luò)的 Bagging 方法,因此它提供了一種廉價的 Bagging 集成近似方法,能夠訓(xùn)練和評估值數(shù)據(jù)數(shù)量的神經(jīng)網(wǎng)絡(luò)。
Dropout 指暫時丟棄一部分神經(jīng)元及其連接。隨機丟棄神經(jīng)元可以防止過擬合,同時指數(shù)級、高效地連接不同網(wǎng)絡(luò)架構(gòu)。神經(jīng)元被丟棄的概率為 1 ? p,減少神經(jīng)元之間的共適應(yīng)。隱藏層通常以 0.5 的概率丟棄神經(jīng)元。使用完整網(wǎng)絡(luò)(每個節(jié)點的輸出權(quán)重為 p)對所有 2^n 個 dropout 神經(jīng)元的樣本平均值進行近似計算。Dropout 顯著降低了過擬合,同時通過避免在訓(xùn)練數(shù)據(jù)上的訓(xùn)練節(jié)點提高了算法的學(xué)習(xí)速度。
4.4 Drop Connect
Drop Connect 是另一種減少算法過擬合的正則化策略,是 Dropout 的一般化。在 Drop Connect 的過程中需要將網(wǎng)絡(luò)架構(gòu)權(quán)重的一個隨機選擇子集設(shè)置為零,取代了在 Dropout 中對每個層隨機選擇激活函數(shù)的子集設(shè)置為零的做法。由于每個單元接收來自過去層單元的隨機子集的輸入,Drop Connect 和 Dropout 都可以獲得有限的泛化性能 [22]。Drop Connect 和 Dropout 相似的地方在于它涉及在模型中引入稀疏性,不同之處在于它引入的是權(quán)重的稀疏性而不是層的輸出向量的稀疏性。
4.5 早停法
早停法可以限制模型最小化代價函數(shù)所需的訓(xùn)練迭代次數(shù)。早停法通常用于防止訓(xùn)練中過度表達的模型泛化性能差。如果迭代次數(shù)太少,算法容易欠擬合(方差較小,偏差較大),而迭代次數(shù)太多,算法容易過擬合(方差較大,偏差較小)。早停法通過確定迭代次數(shù)解決這個問題,不需要對特定值進行手動設(shè)置。
優(yōu)化技術(shù)
5.1 動量(Momentum)
隨機梯度下降和小批量梯度下降是機器學(xué)習(xí)中最常見的優(yōu)化技術(shù),然而在大規(guī)模應(yīng)用和復(fù)雜模型中,算法學(xué)習(xí)的效率是非常低的。而動量策略旨在加速學(xué)習(xí)過程,特別是在具有較高曲率的情況下。動量算法利用先前梯度的指數(shù)衰減滑動平均值在該方向上進行回退 [26]。該算法引入了變量 v 作為參數(shù)在參數(shù)空間中持續(xù)移動的速度向量,速度一般可以設(shè)置為負梯度的指數(shù)衰減滑動平均值。對于一個給定需要最小化的代價函數(shù),動量可以表達為:

其中 α 為學(xué)習(xí)率,γ ∈ (0, 1] 為動量系數(shù),v 是速度向量,θ是保持和速度向量方向相同的參數(shù)。一般來說,梯度下降算法下降的方向為局部最速的方向(數(shù)學(xué)上稱為最速下降法),它的下降方向在每一個下降點一定與對應(yīng)等高線的切線垂直,因此這也就導(dǎo)致了 GD 算法的鋸齒現(xiàn)象。雖然 SGD 算法收斂較慢,但動量法是令梯度直接指向最優(yōu)解的策略之一。在實踐中,γ初始設(shè)置為 0.5,并在初始學(xué)習(xí)穩(wěn)定后增加到 0.9。同樣,α 一般也設(shè)置地非常小,因為梯度的量級通常是比較大的。
5.2 Nesterov 加速梯度(NAG)
Nesterov 加速梯度(NAG)和經(jīng)典動量算法非常相似,它是一種一階優(yōu)化算法,但在梯度評估方面有所不同。在 NAG 中,梯度的評估是通過速度的實現(xiàn)而完成的。NAG 根據(jù)參數(shù)進行更新,和動量算法一樣,不過 NAG 的收斂速度更好。在批量梯度下降中,與平滑的凸函數(shù)相比,NAG 的收斂速度超出 1/k 到 1/(k^2) [27]。但是,在 SGD 中,NAG 無法提高收斂速度。NAG 的更新如下:
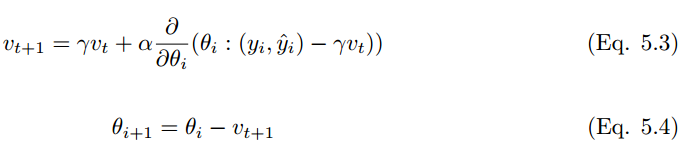
動量系數(shù)設(shè)置為 0.9。經(jīng)典的動量算法先計算當(dāng)前梯度,再轉(zhuǎn)向更新累積梯度。相反,在 NAG 中,先轉(zhuǎn)向更新累積梯度,再進行校正。其結(jié)果是防止算法速度過快,且增加了反應(yīng)性(responsiveness)。
5.3 Adagrad
Adagrad 亦稱為自適應(yīng)梯度(adaptive gradient),允許學(xué)習(xí)率基于參數(shù)進行調(diào)整,而不需要在學(xué)習(xí)過程中人為調(diào)整學(xué)習(xí)率。Adagrad 根據(jù)不常用的參數(shù)進行較大幅度的學(xué)習(xí)率更新,根據(jù)常用的參數(shù)進行較小幅度的學(xué)習(xí)率更新。因此,Adagrad 成了稀疏數(shù)據(jù)如圖像識別和 NLP 的天然選擇。然而 Adagrad 的較大問題在于,在某些案例中,學(xué)習(xí)率變得太小,學(xué)習(xí)率單調(diào)下降使得網(wǎng)絡(luò)停止學(xué)習(xí)過程。在經(jīng)典的動量算法和 Nesterov 中,加速梯度參數(shù)更新是對所有參數(shù)進行的,并且學(xué)習(xí)過程中的學(xué)習(xí)率保持不變。在 Adagrad 中,每次迭代中每個參數(shù)使用的都是不同的學(xué)習(xí)率。
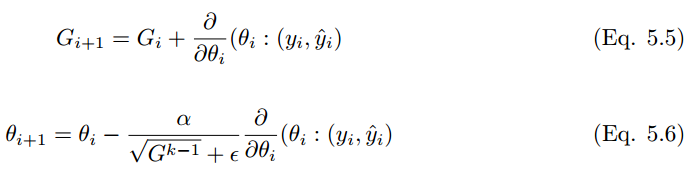
5.4 AdaDelta
AdaDelta 使用最近歷史梯度值縮放學(xué)習(xí)率,并且和經(jīng)典的動量算法相似,累積歷史的更新以加速學(xué)習(xí)。AdaDelta 可以有效地克服 Adagrad 學(xué)習(xí)率收斂至零的缺點。AdaDelta 將累積過去平方梯度的范圍限制在固定窗口 w 內(nèi),取代了經(jīng)典動量算法累積所有歷史梯度值的做法。在時間 t 運行的平均值計算 E[g^2](t) 依賴于過去的平均值和當(dāng)前的梯度值。因此,該平均值計算可以表示為:
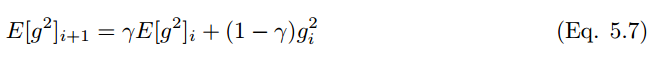
其中 γ 和動量項相同。實踐中,該值通常設(shè)為 0.9 左右。根據(jù)等式 3.13,SGD 更新的等式為:
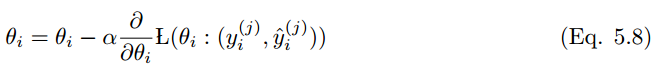
根據(jù)等式 5.6,Adagrad 的更新為:
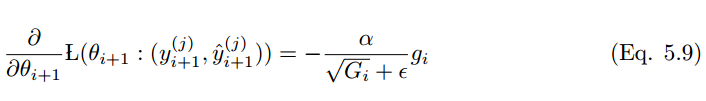
使用過往的平方梯度 ?替換對角矩陣 G_i,得到

其中分母是梯度的平方根誤差,
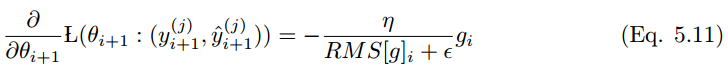
用 ?替換先前更新規(guī)則中的學(xué)習(xí)率 α,得到

5.5 RMS prop
RMS prop 類似于 Adadelta 的較早的更新向量,
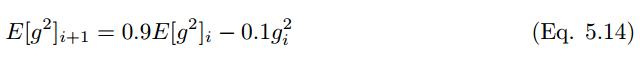
RMS prop 的更新規(guī)則如下:
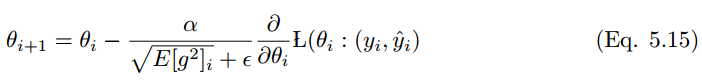
在 RMS prop 中,學(xué)習(xí)率除以平方梯度的指數(shù)衰減平均值。
5.6 Adam?
1.Adam 優(yōu)化算法的基本機制
Adam 算法和傳統(tǒng)的隨機梯度下降不同。隨機梯度下降保持單一的學(xué)習(xí)率(即 alpha)更新所有的權(quán)重,學(xué)習(xí)率在訓(xùn)練過程中并不會改變。而 Adam 通過計算梯度的一階矩估計和二階矩估計而為不同的參數(shù)設(shè)計獨立的自適應(yīng)性學(xué)習(xí)率。
Adam 算法的提出者描述其為兩種隨機梯度下降擴展式的優(yōu)點集合,即:
適應(yīng)性梯度算法(AdaGrad)為每一個參數(shù)保留一個學(xué)習(xí)率以提升在稀疏梯度(即自然語言和計算機視覺問題)上的性能。
均方根傳播(RMSProp)基于權(quán)重梯度最近量級的均值為每一個參數(shù)適應(yīng)性地保留學(xué)習(xí)率。這意味著算法在非穩(wěn)態(tài)和在線問題上有很有優(yōu)秀的性能。
Adam 算法同時獲得了 AdaGrad 和 RMSProp 算法的優(yōu)點。Adam 不僅如 RMSProp 算法那樣基于一階矩均值計算適應(yīng)性參數(shù)學(xué)習(xí)率,它同時還充分利用了梯度的二階矩均值(即有偏方差/uncentered variance)。具體來說,算法計算了梯度的指數(shù)移動均值(exponential moving average),超參數(shù) beta1 和 beta2 控制了這些移動均值的衰減率。
移動均值的初始值和 beta1、beta2 值接近于 1(推薦值),因此矩估計的偏差接近于 0。該偏差通過首先計算帶偏差的估計而后計算偏差修正后的估計而得到提升。
2.Adam算法

Adam論文地址:https://arxiv.org/abs/1412.6980
如上算法所述,在確定了參數(shù)α、β_1、β_2 和隨機目標函數(shù) f(θ) 之后,我們需要初始化參數(shù)向量、一階矩向量、二階矩向量和時間步。然后當(dāng)參數(shù) θ 沒有收斂時,循環(huán)迭代地更新各個部分。即時間步 t 加 1、更新目標函數(shù)在該時間步上對參數(shù)θ所求的梯度、更新偏差的一階矩估計和二階原始矩估計,再計算偏差修正的一階矩估計和偏差修正的二階矩估計,然后再用以上計算出來的值更新模型的參數(shù)θ。

該算法更新梯度的指數(shù)移動均值(mt)和平方梯度(vt),而參數(shù) β_1、β_2 ∈ [0, 1) 控制了這些移動均值(moving average)指數(shù)衰減率。移動均值本身使用梯度的一階矩(均值)和二階原始矩(有偏方差)進行估計。然而因為這些移動均值初始化為 0 向量,所以矩估計值會偏差向 0,特別是在初始時間步中和衰減率非常小(即β接近于 1)的情況下是這樣的。但好消息是,初始化偏差很容易抵消,因此我們可以得到偏差修正(bias-corrected)的估計 m_t hat 和 v_t hat。
注意算法的效率可以通過改變計算順序而得到提升,例如將偽代碼最后三行循環(huán)語句替代為以下兩個:
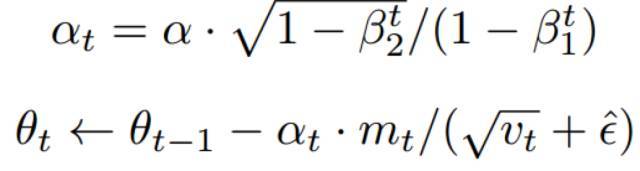
3. Adam 的更新規(guī)則


4. 初始化偏差修正
正如本論文第二部分算法所述,Adam 利用了初始化偏差修正項。本部分將由二階矩估計推導(dǎo)出這一偏差修正項,一階矩估計的推導(dǎo)完全是相似的。首先我們可以求得隨機目標函數(shù) f 的梯度,然后我們希望能使用平方梯度(squared gradient)的指數(shù)移動均值和衰減率 β_2 來估計它的二階原始矩(有偏方差)。令 g1, ..., gT 為時間步序列上的梯度,其中每個梯度都服從一個潛在的梯度分布 gt ~ p(gt)。現(xiàn)在我們初始化指數(shù)移動均值 v0=0(零向量),而指數(shù)移動均值在時間步 t 的更新可表示為: 其中 gt^2 表示 Hadamard 積 gt⊙gt,即對應(yīng)元素之間的乘積。同樣我們可以將其改寫為在前面所有時間步上只包含梯度和衰減率的函數(shù),即消去 v:?

我們希望知道時間步 t 上指數(shù)移動均值的期望值 E[vt] 如何與真實的二階矩 ?相關(guān)聯(lián),所以我們可以對這兩個量之間的偏差進行修正。下面我們同時對表達式(1)的左邊和右邊去期望,即如下所示:

如果真實二階矩 E[g^2] 是靜態(tài)的(stationary),那么ζ = 0。否則 ζ 可以保留一個很小的值,這是因為我們應(yīng)該選擇指數(shù)衰減率 β1 以令指數(shù)移動均值分配很小的權(quán)重給梯度。所以初始化均值為零向量就造成了只留下了 (1 ? βt^2 ) 項。我們因此在算法 1 中除以了ζ項以修正初始化偏差。
在稀疏矩陣中,為了獲得一個可靠的二階矩估計,我們需要選擇一個很小的 β2 而在許多梯度上取均值。然而正好是這種小β2 值的情況導(dǎo)致了初始化偏差修正的缺乏,因此也就令初始化步長過大。
5.7 Nadam
Nadam 是 NAG 和 Adam 優(yōu)化器的結(jié)合 [28]。如果過往歷史平方梯度的指數(shù)衰減平均值為 v_t,而過往歷史梯度的指數(shù)衰減平均值為 m_t,那么經(jīng)典動量更新規(guī)則如下:
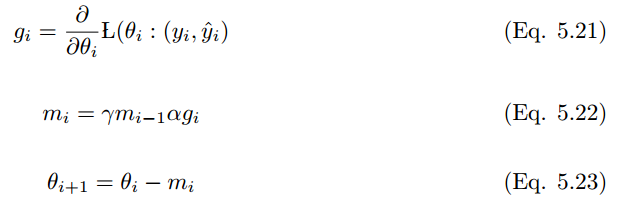
我們需要修改動量規(guī)則以獲得 Nadam 優(yōu)化器。因此將上述公式擴展為:

NAG 的修改如下:
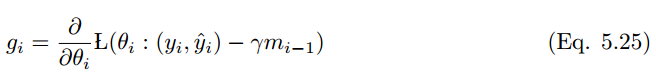

可以通過更新梯度 g_t 時(第一次)和更新參數(shù) θ_t+1(第二次)修改 NAG,而不是兩次更新動量。因此動量向量直接更新參數(shù)可以表述如下:

為了添加 NAG 到 Adam,需要使用當(dāng)前的動態(tài)向量替換先前的動態(tài)向量。因此,通過 m hat 和 m_t 擴展上述公式,Adam 更新規(guī)則如下:
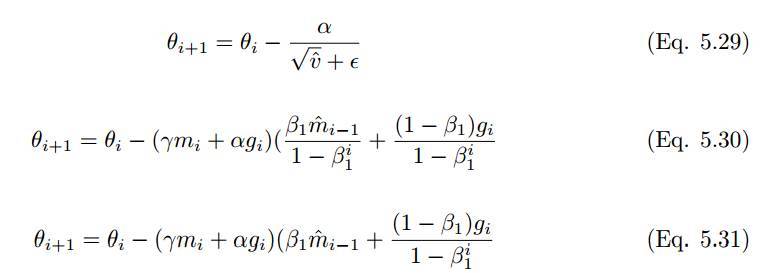
利用先前時間步動量向量的偏差修正估計更新 Nadam 優(yōu)化器的規(guī)則,如下:
 歡迎加入本站公開興趣群
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4703.html
摘要:在學(xué)習(xí)過程中,神經(jīng)網(wǎng)絡(luò)的突觸權(quán)重會以一種有序的方式進行修改,從而實現(xiàn)所需的目標。中間單元的數(shù)量被稱為網(wǎng)絡(luò)所用的片的數(shù)量。 隨著神經(jīng)網(wǎng)絡(luò)的進化,許多過去曾被認為不可想象的任務(wù)現(xiàn)在也能夠被完成了。圖像識別、語音識別、尋找數(shù)據(jù)集中的深度關(guān)系等任務(wù)現(xiàn)在已經(jīng)變得遠遠更加簡單了。在此向這一領(lǐng)域的杰出的研究者致以真誠的謝意,正是他們的發(fā)現(xiàn)和成果幫助我們利用上了神經(jīng)網(wǎng)絡(luò)的真正力量。如果你真正對追求機器學(xué)習(xí)這...
摘要:在計算機視覺領(lǐng)域,對卷積神經(jīng)網(wǎng)絡(luò)簡稱為的研究和應(yīng)用都取得了顯著的成果。文章討論了在卷積神經(jīng)網(wǎng)絡(luò)中,該如何調(diào)整超參數(shù)以及可視化卷積層。卷積神經(jīng)網(wǎng)絡(luò)可以完成這項任務(wù)。 在深度學(xué)習(xí)中,有許多不同的深度網(wǎng)絡(luò)結(jié)構(gòu),包括卷積神經(jīng)網(wǎng)絡(luò)(CNN或convnet)、長短期記憶網(wǎng)絡(luò)(LSTM)和生成對抗網(wǎng)絡(luò)(GAN)等。在計算機視覺領(lǐng)域,對卷積神經(jīng)網(wǎng)絡(luò)(簡稱為CNN)的研究和應(yīng)用都取得了顯著的成果。CNN網(wǎng)絡(luò)最...
摘要:為了使的思想更具體化,現(xiàn)在我們來看一下在深度神經(jīng)網(wǎng)絡(luò)中執(zhí)行多任務(wù)學(xué)習(xí)的兩種最常用的方法。圖深度神經(jīng)網(wǎng)絡(luò)多任務(wù)學(xué)習(xí)的參數(shù)共享共享參數(shù)大大降低了過擬合的風(fēng)險。 目錄1.介紹2.動機3.兩種深度學(xué)習(xí) MTL 方法Hard 參數(shù)共享Soft 參數(shù)共享4.為什么 MTL 有效隱式數(shù)據(jù)增加注意力機制竊聽表征偏置正則化5.非神經(jīng)模型中的 MTL塊稀疏正則化學(xué)習(xí)任務(wù)的關(guān)系6.最近 MTL 的深度學(xué)習(xí)研究深度...
摘要:在實踐中,幾乎總是通過向梯度增加來實現(xiàn)算法,而不是真正改變損失函數(shù)。顯然這是兩種不同的方法。那么,權(quán)重衰減是不是總比的正則化更好呢我們還沒發(fā)現(xiàn)明顯更糟的情況,但無論是遷移學(xué)習(xí)問題例如斯坦福汽車數(shù)據(jù)集上的的微調(diào)還是 跌宕起伏的 Adam縱觀 Adam 優(yōu)化器的發(fā)展歷程,就像過山車一樣。它于 2014 年在論文 Adam: A Method for Stochastic Optimization...

閱讀 3952·2021-11-11 10:58
閱讀 3321·2021-09-26 09:46
閱讀 1912·2019-08-30 15:55
閱讀 976·2019-08-30 13:52
閱讀 1943·2019-08-29 13:11
閱讀 3024·2019-08-29 11:27
閱讀 1517·2019-08-26 18:18
閱讀 2618·2019-08-23 14:17





