資訊專欄INFORMATION COLUMN

摘要:近日,谷歌大腦發(fā)布了一篇全面梳理的論文,該研究從損失函數(shù)對(duì)抗架構(gòu)正則化歸一化和度量方法等幾大方向整理生成對(duì)抗網(wǎng)絡(luò)的特性與變體。他們首先定義了全景圖損失函數(shù)歸一化和正則化方案,以及最常用架構(gòu)的集合。
近日,谷歌大腦發(fā)布了一篇全面梳理 GAN 的論文,該研究從損失函數(shù)、對(duì)抗架構(gòu)、正則化、歸一化和度量方法等幾大方向整理生成對(duì)抗網(wǎng)絡(luò)的特性與變體。作者們復(fù)現(xiàn)了當(dāng)前較佳的模型并公平地對(duì)比與探索 GAN 的整個(gè)研究圖景,此外研究者在 TensorFlow Hub 和 GitHub 也分別提供了預(yù)訓(xùn)練模型與對(duì)比結(jié)果。
深度生成模型可以應(yīng)用到學(xué)習(xí)目標(biāo)分布的任務(wù)上。它們近期在多種應(yīng)用中發(fā)揮作用,展示了在自然圖像處理上的巨大潛力。生成對(duì)抗網(wǎng)絡(luò)(GAN)是主要的以無監(jiān)督方式學(xué)習(xí)此類模型的方法之一。GAN 框架可以看作是一個(gè)兩人博弈,其中第一個(gè)玩家生成器學(xué)習(xí)變換某些簡單的輸入分布(通常是標(biāo)準(zhǔn)的多變量正態(tài)分布或均勻分布)到圖像空間上的分布,使得第二個(gè)玩家判別器無法確定樣本術(shù)語真實(shí)分布或合成分布。雙方都試圖最小化各自的損失,博弈的最終解是納什均衡,其中沒有任何玩家能單方面地優(yōu)化損失。GAN 框架一般可以通過最小化模型分布和真實(shí)分布之間的統(tǒng)計(jì)差異導(dǎo)出。
訓(xùn)練 GAN 需要在生成器和判別器的參數(shù)上求解一個(gè)極小極大問題。由于生成器和判別器通常被參數(shù)化為深度卷積神經(jīng)網(wǎng)絡(luò),這個(gè)極小極大問題在實(shí)踐中非常困難。結(jié)果,人們提出了過多的損失函數(shù)、正則化方法、歸一化方案和神經(jīng)架構(gòu)。某些方法基于理論洞察導(dǎo)出,其它的由實(shí)踐考慮所啟發(fā)。
在本文中谷歌大腦提供了對(duì)這些方法的全面的經(jīng)驗(yàn)分析,作為研究員和從業(yè)者在這個(gè)領(lǐng)域的引導(dǎo)。他們首先定義了 GAN 全景圖(GAN landscape):損失函數(shù)、歸一化和正則化方案,以及最常用架構(gòu)的集合。他們?cè)诙鄠€(gè)現(xiàn)代大規(guī)模數(shù)據(jù)集上通過超參數(shù)優(yōu)化探索了這個(gè)搜索空間,考慮了文獻(xiàn)中報(bào)告的「好」超參集合,以及由高斯過程回歸得到的超參集合。通過分析損失函數(shù)的影響,他們總結(jié)出非飽和損失 [9] 在各種數(shù)據(jù)集、架構(gòu)和超參上足夠穩(wěn)定。接著,研究者分析了不同歸一化和正則化方案,以及不同架構(gòu)的影響。結(jié)果表明梯度懲罰 [10] 以及譜歸一化 [20] 在高深度架構(gòu)中都很有用。然后他們證實(shí)我們可以同時(shí)使用正則化和歸一化來改善模型。最后,他們討論了常見陷阱、復(fù)現(xiàn)問題和實(shí)踐考慮。研究者提供了所有參考實(shí)現(xiàn),包括 GitHub 上的訓(xùn)練和評(píng)估代碼,并在 TensorFlow Hub 上提供了預(yù)訓(xùn)練模型。
Github:http://www.github.com/google/compare_gan
TensorFlow Hub:http://www.tensorflow.org/hub
論文:The GAN Landscape: Losses, Architectures, Regularization, and Normalization

論文地址:https://arxiv.org/abs/1807.04720
摘要:生成對(duì)抗網(wǎng)絡(luò)(GAN)是一類以無監(jiān)督方式學(xué)習(xí)目標(biāo)分布的深度生成模型。雖然它們已成功應(yīng)用到很多問題上,但訓(xùn)練 GAN 是很困難的并需要大量的超參數(shù)調(diào)整、神經(jīng)架構(gòu)工程和很多的「技巧」。在許多實(shí)際應(yīng)用中的成功伴隨著量化度量 GAN 失敗模式的缺失,導(dǎo)致提出了過多的損失函數(shù)、正則化方法、歸一化方案以及神經(jīng)架構(gòu)。在這篇論文中我們將從實(shí)踐的角度清醒地認(rèn)識(shí)當(dāng)前的 GAN 研究現(xiàn)狀。我們復(fù)現(xiàn)了當(dāng)前較佳的模型并公平地探索 GAN 的整個(gè)研究圖景。我們討論了常見的陷阱和復(fù)現(xiàn)問題,在 GitHub 開源了我們的項(xiàng)目,并在 TensorFlow Hub 上提供了我們的預(yù)訓(xùn)練模型。
2 GAN 全景圖
在這一章節(jié)中,作者主要總結(jié)了 GAN 的各種變體與技術(shù),詳細(xì)內(nèi)容可參考該論文與各種 GAN 變體的原論文。作者主要從損失函數(shù)、判別器的正則化與歸一化、生成器與判別器的架構(gòu)、評(píng)估度量與數(shù)據(jù)集等 5 個(gè)方面討論了各種不同的技術(shù)。
其中在損失函數(shù)中,作者討論了原版 GAN 的 JS 距離、WGAN 的 Wasserstein 距離和最小二乘等損失函數(shù)。而判別器的正則化主要為梯度范數(shù)罰項(xiàng),例如在 WGAN 中,這種梯度范數(shù)懲罰主要體現(xiàn)在對(duì)違反 1-Lipschitzness 平滑的軟懲罰。此外,模型還能根據(jù)數(shù)據(jù)流形評(píng)估梯度范數(shù)懲罰,并鼓勵(lì)判別器在該數(shù)據(jù)流形上成分段線性。判別器的歸一化主要體現(xiàn)在最優(yōu)化與表征上,即歸一化能獲得更高效的梯度流與更穩(wěn)點(diǎn)的優(yōu)化過程,以及修正各權(quán)重矩陣的譜結(jié)構(gòu)而獲得更更豐富的層級(jí)特征。
研究者主要探討了兩種生成器與判別器架構(gòu),包括深度卷積生成對(duì)抗網(wǎng)絡(luò)與殘差網(wǎng)絡(luò)。其中深度卷積生成對(duì)抗網(wǎng)絡(luò)的生成器與判別器分別包含 5 個(gè)卷積層,且?guī)в凶V歸一化的變體稱為 SNDCGAN。而 ResNet19 的生成器包含 5 個(gè)殘差模塊,判別器包含 6 個(gè)殘差模塊。
隨后的評(píng)估度量則主要包含四種,包括 Inception Score (IS)、Frechet Inception Distance (FID) 和 Kernel Inception distance (KID) 等,它們都提供生成樣本質(zhì)量的定量分析。最后研究者考慮了三種數(shù)據(jù)集,并在上面測試各種 GAN 的生成效果。這些數(shù)據(jù)集包括 CIFAR10、CELEBA-HQ-128 和 LSUN-BEDROOM。
GAN 的搜索空間可能非常巨大:探索所有包含各種損失函數(shù)、正則化和歸一化策略以及架構(gòu)的組合超出了能力范圍,因此在這一項(xiàng)研究中,研究者在幾個(gè)數(shù)據(jù)集上分析了其中一些重要的組合。
作者在表 1a 中總結(jié)了近來在各項(xiàng)研究中展示「比較好」的參數(shù)。并且為了提供一個(gè)相對(duì)公平的對(duì)比,我們?cè)诒?1b 展示的超參數(shù)上執(zhí)行高斯過程優(yōu)化。
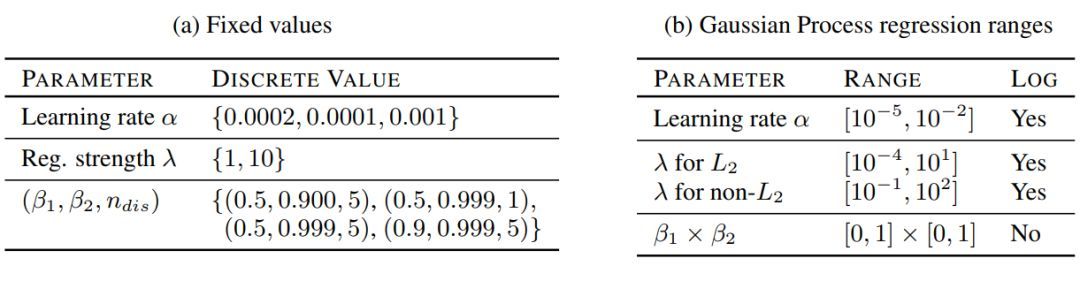
表 1:本研究中使用的超參數(shù)范圍。固定值的笛卡爾乘積足夠復(fù)現(xiàn)已有的結(jié)果。在 bandit setting[27] 中的高斯過程優(yōu)化用于從特定范圍中選擇好的超參數(shù)集合。
3 結(jié)果和討論
由于每個(gè)數(shù)據(jù)集都有四個(gè)主要成分(損失、架構(gòu)、正則化、歸一化)需要分析,探索完整的全景圖是不可行的。因此,研究者選擇了一個(gè)更加實(shí)際的方案:保持某些維度為固定值,并變化其它維度的值。在每個(gè)實(shí)驗(yàn)中重點(diǎn)關(guān)注三個(gè)方面:(1)top5% 已訓(xùn)練模型的 FID 分布;(2)對(duì)應(yīng)的樣本多樣性分?jǐn)?shù);以及(3)計(jì)算開銷(即訓(xùn)練的模型數(shù)量)和模型質(zhì)量(FID 度量)之間的權(quán)衡。來自固定種子集的每個(gè)模型使用不同的隨機(jī)種子訓(xùn)練 5 次,并報(bào)告中位數(shù)分?jǐn)?shù)。由高斯過程回歸得到的種子方差已經(jīng)隱含地得到了處理,因此每個(gè)模型只需要訓(xùn)練一次。
3.1 損失函數(shù)的影響
這里損失函數(shù)是非飽和損失(NS),或者最小二乘損失(LS)[19],或者 Wasserstein 損失(WGAN)[2]。研究者使用了 ResNet19 作為生成器和判別器架構(gòu),架構(gòu)細(xì)節(jié)在表 3a 中。本研究中考慮了最主要的歸一化和正則化方法:梯度懲罰 [10] 和譜歸一化 [20]。兩項(xiàng)研究都使用了表 1a 中的超參數(shù)設(shè)置,并在 CELEBA-HQ-128 和 LSUN-BEDROOM 數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)。
結(jié)果如圖 2 所示。可以觀察到,非飽和損失在兩個(gè)數(shù)據(jù)集上都是穩(wěn)定的。譜歸一化在兩個(gè)數(shù)據(jù)集上都提高了模型質(zhì)量。類似地,梯度懲罰可以幫助提高模型質(zhì)量,但尋找好的正則化權(quán)衡比較困難,需要大量的計(jì)算開銷。使用 GP 懲罰的模型對(duì)判別器和生成器更新有改善的比例是 5:1,正如文獻(xiàn) [10] 所提到的。

圖 1:非飽和損失在兩個(gè)數(shù)據(jù)集上都是穩(wěn)定的。梯度懲罰和譜歸一化改善了模型質(zhì)量。從計(jì)算開銷的角度(即需要訓(xùn)練多少個(gè)模型已達(dá)到特定的 FID),譜歸一化和梯度懲罰相比基線方法的表現(xiàn)更好,但前者更加高效。
3.2 正則化與歸一化的影響
該研究的目的是對(duì)比文獻(xiàn)中提到的各種正則化與歸一化方法的表現(xiàn)。最終,研究者考慮批歸一化(BN)、層歸一化(LN)、譜歸一化(SN)、梯度懲罰(GP)、Dragan 懲罰(DR)或者 L2 正則化。
這些方法的結(jié)果展示在圖 2 中。可以觀察到向判別器添加批歸一化會(huì)損害最終表現(xiàn)。其次,梯度懲罰有所幫助,但訓(xùn)練不穩(wěn)定。
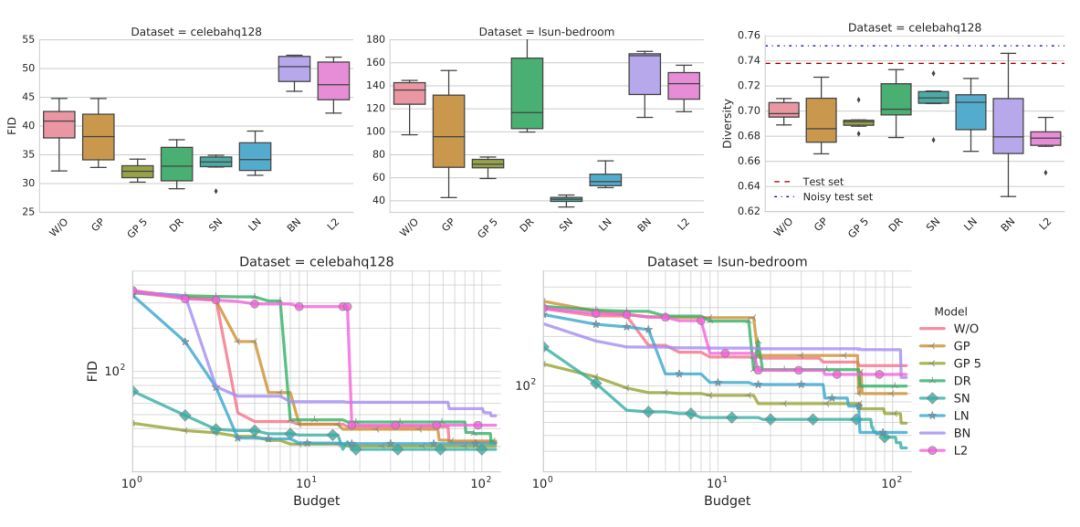
圖 2:梯度懲罰和譜歸一化表現(xiàn)都很好,也應(yīng)被視為可行的方法。此外,后者的計(jì)算成本更低一些。不幸的是,兩者都不能完全解決穩(wěn)定性問題。
同時(shí)使用正則化和歸一化的影響:
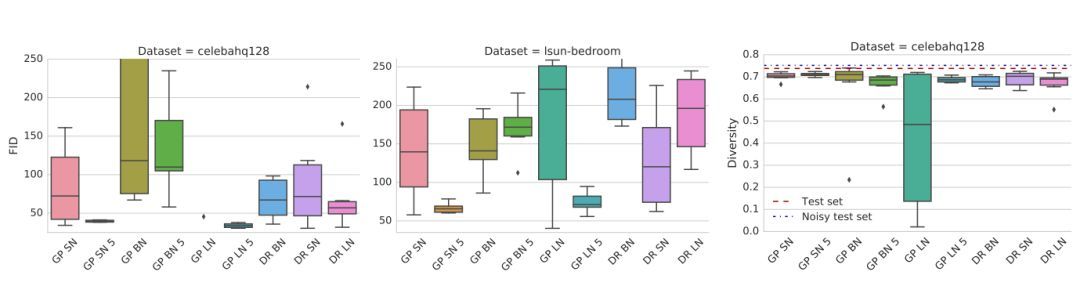
圖 3:梯度懲罰配合譜歸一化(SN)或者層歸一化(LN)方法,能夠極大地改進(jìn)其表現(xiàn)。
3.3 生成器和判別器架構(gòu)的影響
一個(gè)有趣的實(shí)際問題是:本研究的發(fā)現(xiàn)在不同的模型容量上是否一致。為了驗(yàn)證此問題,研究者選擇了 DCGAN 類型的架構(gòu)。在非飽和 GAN 損失、梯度懲罰和譜歸一化下,同樣完成了該研究。
結(jié)果如下圖 4,可以觀察到得益于正則化和歸一化,兩種架構(gòu)都得到了相當(dāng)好的結(jié)果。在兩種架構(gòu)上,使用譜歸一化極大地超越了基線標(biāo)準(zhǔn)。

圖 4:判別器和生成器架構(gòu)對(duì)非飽和 GAN 損失的影響。頻譜歸一化與梯度懲罰都能改進(jìn)非正則化基線模型的表現(xiàn)。
聲明:文章收集于網(wǎng)絡(luò),如有侵權(quán),請(qǐng)聯(lián)系小編及時(shí)處理,謝謝!
商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4787.html
摘要:是世界上最重要的研究者之一,他在谷歌大腦的競爭對(duì)手,由和創(chuàng)立工作過不長的一段時(shí)間,今年月重返,建立了一個(gè)探索生成模型的新研究團(tuán)隊(duì)。機(jī)器學(xué)習(xí)系統(tǒng)可以在這些假的而非真實(shí)的醫(yī)療記錄進(jìn)行訓(xùn)練。今年月在推特上表示是的,我在月底離開,并回到谷歌大腦。 理查德·費(fèi)曼去世后,他教室的黑板上留下這樣一句話:我不能創(chuàng)造的東西,我就不理解。(What I cannot create, I do not under...
摘要:我仍然用了一些時(shí)間才從神經(jīng)科學(xué)轉(zhuǎn)向機(jī)器學(xué)習(xí)。當(dāng)我到了該讀博的時(shí)候,我很難在的神經(jīng)科學(xué)和的機(jī)器學(xué)習(xí)之間做出選擇。 1.你學(xué)習(xí)機(jī)器學(xué)習(xí)的歷程是什么?在學(xué)習(xí)機(jī)器學(xué)習(xí)時(shí)你最喜歡的書是什么?你遇到過什么死胡同嗎?我學(xué)習(xí)機(jī)器學(xué)習(xí)的道路是漫長而曲折的。讀高中時(shí),我興趣廣泛,大部分和數(shù)學(xué)或科學(xué)沒有太多關(guān)系。我用語音字母表編造了我自己的語言,我參加了很多創(chuàng)意寫作和文學(xué)課程。高中畢業(yè)后,我進(jìn)了大學(xué),盡管我不想去...
摘要:二是精度查全率和得分,用來衡量判別式模型的質(zhì)量。精度查全率和團(tuán)隊(duì)還用他們的三角形數(shù)據(jù)集,測試了樣本量為時(shí),大范圍搜索超參數(shù)來進(jìn)行計(jì)算的精度和查全率。 從2014年誕生至今,生成對(duì)抗網(wǎng)絡(luò)(GAN)熱度只增不減,各種各樣的變體層出不窮。有位名叫Avinash Hindupur的國際友人建立了一個(gè)GAN Zoo,他的動(dòng)物園里目前已經(jīng)收集了多達(dá)214種有名有姓的GAN。DeepMind研究員們甚至將...
摘要:據(jù)報(bào)道,生成對(duì)抗網(wǎng)絡(luò)的創(chuàng)造者,前谷歌大腦著名科學(xué)家剛剛正式宣布加盟蘋果。他將在蘋果公司領(lǐng)導(dǎo)一個(gè)機(jī)器學(xué)習(xí)特殊項(xiàng)目組。在加盟蘋果后會(huì)帶來哪些新的技術(shù)突破或許我們很快就會(huì)看到了。 據(jù) CNBC 報(bào)道,生成對(duì)抗網(wǎng)絡(luò)(GAN)的創(chuàng)造者,前谷歌大腦著名科學(xué)家 Ian Goodfellow 剛剛正式宣布加盟蘋果。他將在蘋果公司領(lǐng)導(dǎo)一個(gè)「機(jī)器學(xué)習(xí)特殊項(xiàng)目組」。雖然蘋果此前已經(jīng)縮小了自動(dòng)駕駛汽車研究的規(guī)模,但...
摘要:生成式對(duì)抗網(wǎng)絡(luò)簡稱將成為深度學(xué)習(xí)的下一個(gè)熱點(diǎn),它將改變我們認(rèn)知世界的方式。配圖針對(duì)三年級(jí)學(xué)生的對(duì)抗式訓(xùn)練屬于你的最嚴(yán)厲的批評(píng)家五年前,我在哥倫比亞大學(xué)舉行的一場橄欖球比賽中傷到了自己的頭部,導(dǎo)致我右半身腰部以上癱瘓。 本文作者 Nikolai Yakovenko 畢業(yè)于哥倫比亞大學(xué),目前是 Google 的工程師,致力于構(gòu)建人工智能系統(tǒng),專注于語言處理、文本分類、解析與生成。生成式對(duì)抗網(wǎng)絡(luò)—...

閱讀 3118·2021-11-15 18:14
閱讀 1773·2021-09-22 10:51
閱讀 3283·2021-09-09 09:34
閱讀 3505·2021-09-06 15:02
閱讀 1013·2021-09-01 11:40
閱讀 3186·2019-08-30 13:58
閱讀 2523·2019-08-30 11:04
閱讀 1081·2019-08-28 18:31






