資訊專欄INFORMATION COLUMN

摘要:二是精度查全率和得分,用來衡量判別式模型的質量。精度查全率和團隊還用他們的三角形數據集,測試了樣本量為時,大范圍搜索超參數來進行計算的精度和查全率。
從2014年誕生至今,生成對抗網絡(GAN)熱度只增不減,各種各樣的變體層出不窮。有位名叫Avinash Hindupur的國際友人建立了一個GAN Zoo,他的“動物園”里目前已經收集了多達214種有名有姓的GAN。
DeepMind研究員們甚至將自己提出的一種變體命名為α-GAN,然后在論文中吐槽說,之所以用希臘字母做前綴,是因為拉丁字母幾乎都被占了……

這還不是最匪夷所思的名字,在即將召開的NIPS 2017上,杜克大學還有個Δ-GAN要發(fā)表。
就是這么火爆!
那么問題來了:這么多變體,有什么區(qū)別?哪個好用?
于是,Google Brain的幾位研究員(不包括原版GAN的爸爸Ian Goodfellow)對各種GAN做一次“中立、多方面、大規(guī)模的”評測,得出了一個有點喪的結論:
No evidence that any of the tested algorithms consistently outperforms the original one.
量子位非常不嚴謹地翻譯一下:
都差不多……都跟原版差不多……

比什么?
這篇論文集中探討的是無條件生成對抗網絡,也就是說,只有無標簽數據可用于學習。選取了如下GAN變體:
MM GAN
NS GAN
WGAN
WGAN GP
LS GAN
DRAGAN
BEGAN
其中MM GAN和NS GAN分別表示用minimax損失函數和用non-saturating損失函數的原版GAN。

除此之外,他們還在比較中加入了另一個熱門生成模型VAE(Variational Autoencoder,變分自編碼器)。
對于各種GAN的性能,Google Brain團隊選了兩組維度來進行比較。
一是FID(Fréchet Inception Distance),FID的值和生成圖像的質量負相關。
測試FID時用了4個數據集:MNIST、Fashion MNIST、CIFAR-10和CELEBA。這幾個數據集的復雜程度從簡單到中等,能快速進行多次實驗,是測試生成模型的常見選擇。
二是精度(precision、)、查全率(recall)和F1得分,用來衡量判別式模型的質量。其中F1是精度和查全率的調和平均數。
這項測試所用的,是Google Brain研究員們自創(chuàng)的一個數據集,由各種角度的三角形灰度圖像組成。

精度和查全率都高、高精度低查全率、低精度高查全率、精度和查全率都低的模型的樣本
對比結果
Google Brain團隊從FID和F1兩個方面對上面提到的模型進行比較,得出了以下結果。
FID
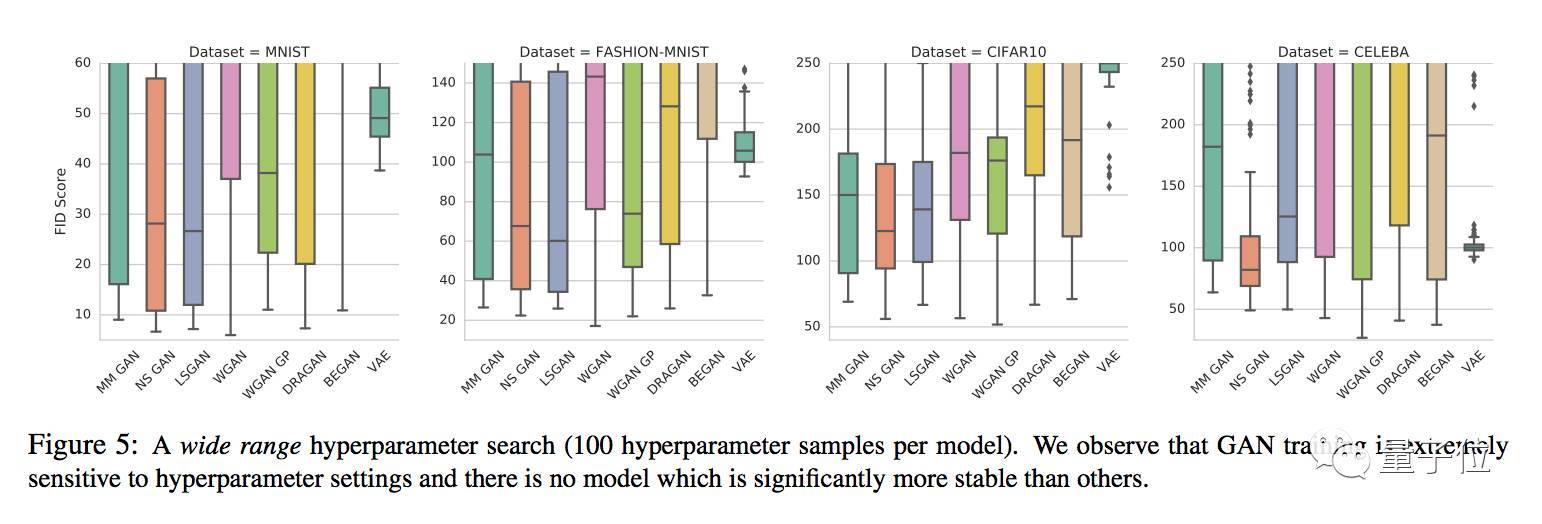
通過對每個模型100組超參數的大范圍搜索,得出的結論是GAN在訓練中都對于超參數設置非常敏感,沒有哪個變體能夠幸免,也就說,哪個GAN也沒能比競品們更穩(wěn)定。
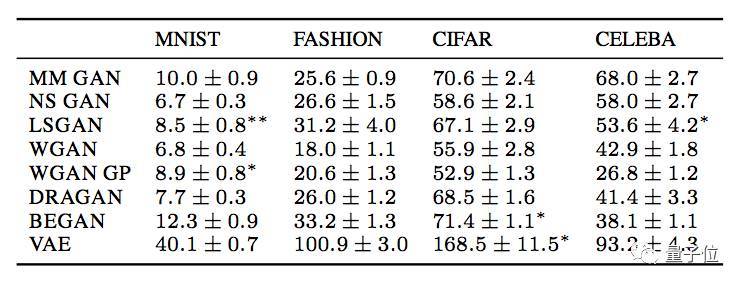
從結果來看,每個模型的性能擅長處理的數據集不太一樣,沒有在所有數據集上都明顯優(yōu)于同類的。不過,VAE相比之下是最弱的,它所生成出的圖像最模糊。
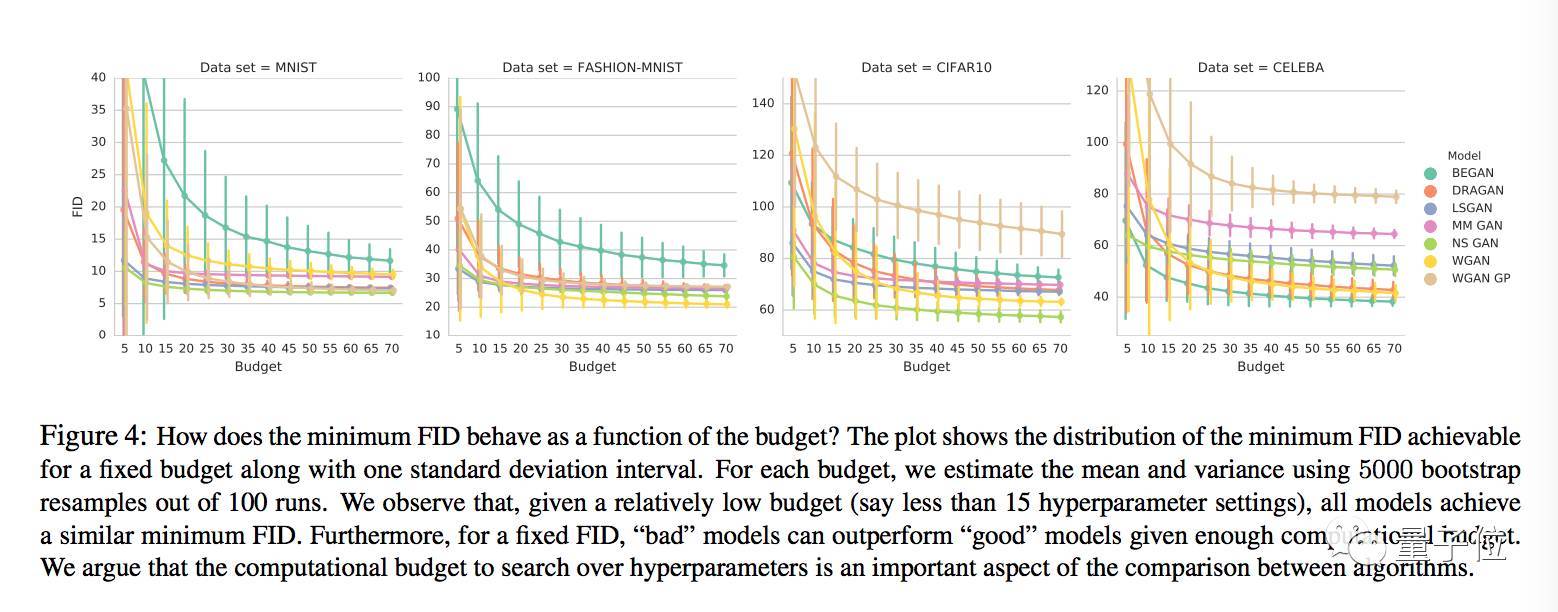
測試還顯示,隨著計算資源配置的提高,最小FID有降低的趨勢。
如果設定一個FID范圍,用比較多計算資源訓練的“壞”模型,可能表現得比用較少計算資源訓練的“好”模型要更好。
另外,當計算資源配置相對比較低的時候,所有模型的最小FID都差不多,也就是說,如果嚴格限制預算,就比較不出這些模型之間具有統(tǒng)計意義的顯著區(qū)別。
他們經過比較得出的結論是,用能達到的最小FID來對模型進行比較是沒有意義的,要比較固定計算資源配置下的FID分布。
FID之間的比較也表明,隨著計算力的增加,較先進的GAN模型之間體現不出算法上的優(yōu)劣差別。
精度、查全率和F1
Google Brain團隊還用他們的三角形數據集,測試了樣本量為1024時,大范圍搜索超參數來進行計算的精度和查全率。
對于特定的模型和超參數設置,較高F1得分會隨著計算資源配置的不同而不同,如下圖所示:
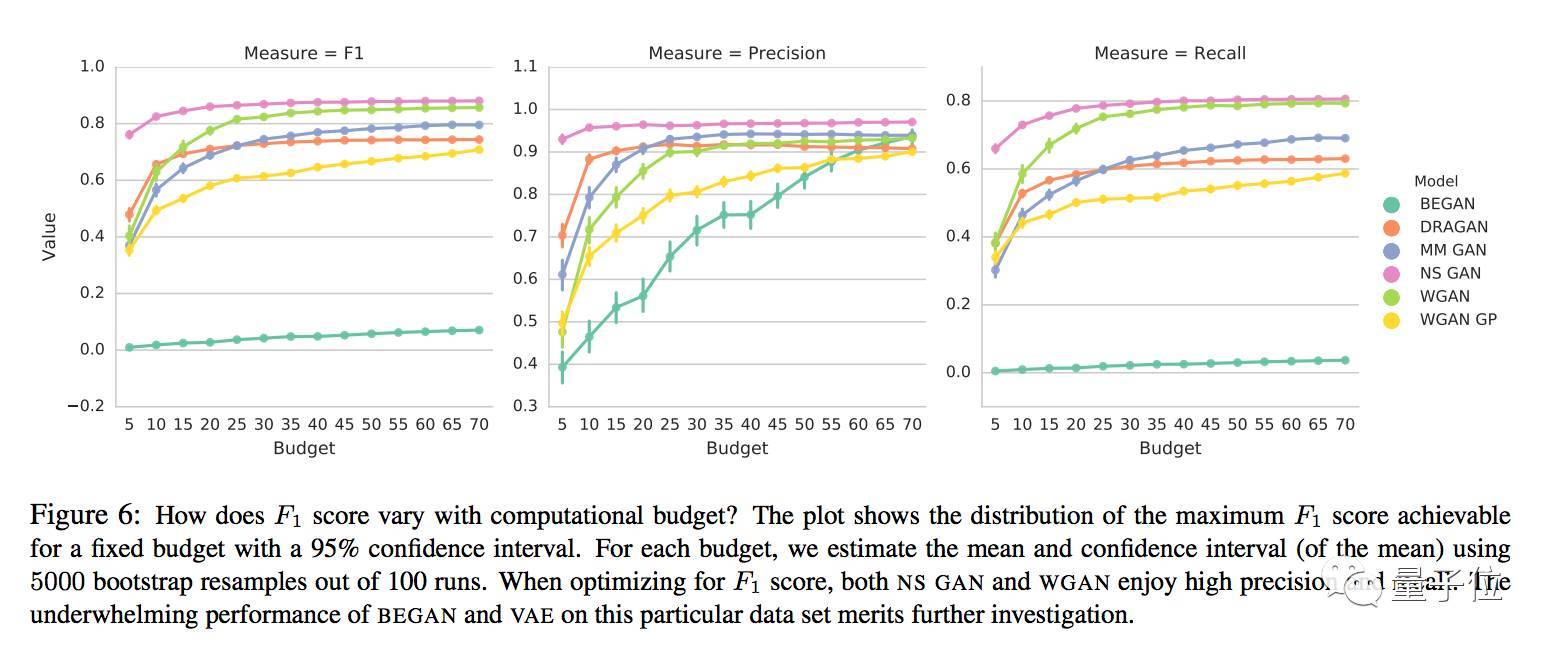
不同計算資源配置下各模型的F1、精度和查全率
論文作者們說,即使是一個這么簡單的任務,很多模型的F1也并不高。當針對F1進行優(yōu)化時,NS GAN和WGAN的精度和查全率都比較高。
和原版GAN相比
Google Brain團隊還將這些變體和原版GAN做了對比。他們得出的結論是,沒有實證證據能證明這些GAN變體在所有數據集上明顯優(yōu)于原版。
實際上,NS GAN水平和其他模型持平,在MNIST上的FID總體水平較好,F1也比其他模型要高。
相關鏈接
要詳細了解這項研究,還是得讀論文:
Are GANs Created Equal? A Large-Scale Study
Mario Lucic, Karol Kurach, Marcin Michalski, Sylvain Gelly, Olivier Bousquet
https://arxiv.org/abs/1711.10337
查找某種GAN變體,可以去文章開頭提到的GAN Zoo:
https://github.com/hindupuravinash/the-gan-zoo
歡迎加入本站公開興趣群商業(yè)智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4684.html
摘要:近日,谷歌大腦發(fā)布了一篇全面梳理的論文,該研究從損失函數對抗架構正則化歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。他們首先定義了全景圖損失函數歸一化和正則化方案,以及最常用架構的集合。 近日,谷歌大腦發(fā)布了一篇全面梳理 GAN 的論文,該研究從損失函數、對抗架構、正則化、歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。作者們復現了當前較佳的模型并公平地對比與探索 GAN ...
摘要:我仍然用了一些時間才從神經科學轉向機器學習。當我到了該讀博的時候,我很難在的神經科學和的機器學習之間做出選擇。 1.你學習機器學習的歷程是什么?在學習機器學習時你最喜歡的書是什么?你遇到過什么死胡同嗎?我學習機器學習的道路是漫長而曲折的。讀高中時,我興趣廣泛,大部分和數學或科學沒有太多關系。我用語音字母表編造了我自己的語言,我參加了很多創(chuàng)意寫作和文學課程。高中畢業(yè)后,我進了大學,盡管我不想去...
摘要:是世界上最重要的研究者之一,他在谷歌大腦的競爭對手,由和創(chuàng)立工作過不長的一段時間,今年月重返,建立了一個探索生成模型的新研究團隊。機器學習系統(tǒng)可以在這些假的而非真實的醫(yī)療記錄進行訓練。今年月在推特上表示是的,我在月底離開,并回到谷歌大腦。 理查德·費曼去世后,他教室的黑板上留下這樣一句話:我不能創(chuàng)造的東西,我就不理解。(What I cannot create, I do not under...
摘要:生成式對抗網絡簡稱將成為深度學習的下一個熱點,它將改變我們認知世界的方式。配圖針對三年級學生的對抗式訓練屬于你的最嚴厲的批評家五年前,我在哥倫比亞大學舉行的一場橄欖球比賽中傷到了自己的頭部,導致我右半身腰部以上癱瘓。 本文作者 Nikolai Yakovenko 畢業(yè)于哥倫比亞大學,目前是 Google 的工程師,致力于構建人工智能系統(tǒng),專注于語言處理、文本分類、解析與生成。生成式對抗網絡—...

閱讀 841·2021-11-16 11:56
閱讀 1653·2021-11-16 11:45
閱讀 3109·2021-10-08 10:13
閱讀 4094·2021-09-22 15:27
閱讀 727·2019-08-30 11:03
閱讀 642·2019-08-30 10:56
閱讀 945·2019-08-29 15:18
閱讀 1737·2019-08-29 14:05






