資訊專欄INFORMATION COLUMN

摘要:生成式對抗網絡簡稱將成為深度學習的下一個熱點,它將改變我們認知世界的方式。配圖針對三年級學生的對抗式訓練屬于你的最嚴厲的批評家五年前,我在哥倫比亞大學舉行的一場橄欖球比賽中傷到了自己的頭部,導致我右半身腰部以上癱瘓。
本文作者 Nikolai Yakovenko 畢業(yè)于哥倫比亞大學,目前是 Google 的工程師,致力于構建人工智能系統,專注于語言處理、文本分類、解析與生成。
生成式對抗網絡—簡稱GANs—將成為深度學習的下一個熱點,它將改變我們認知世界的方式。
準確來講,對抗式訓練為指導人工智能完成復雜任務提供了一個全新的思路,某種意義上他們(人工智能)將學習如何成為一個專家。
舉個對抗式訓練的例子,當你試圖通過模仿別人完成某項工作時,如果專家都無法分辨這項工作是你完成的還是你的模仿對象完成的,說明你已經完全掌握了該工作的所需的技巧。對于像寫論文這樣復雜的工作,這個例子可能不適用,畢竟每個人的最終成果多少有些不同,但對于中等難度的任務,比如造句或寫一段話,對抗式訓練大有用武之地,事實上它現在已經是計算機生成真實圖像的關鍵所在了。
GANs解決問題的方式是用不同的目標分別訓練兩種不同的網絡。
? ? 一種網絡創(chuàng)造答案(生成方)
? ?另一種網絡分辨前者創(chuàng)造的答案與真實答案的區(qū)別(對抗方)
GANs的訣竅是這樣的:訓練兩種網絡進行競爭,一段時間后,兩種網絡都無法在對抗中取得進步,或者生成方變得非常厲害以至于即使給定足夠的線索和時間,其對抗網絡也無法分辨它給的答案是真實的還是合成的。
這其中有很多有趣的細節(jié),但我們暫時先忽略這些細節(jié)。GANs 可以在給定繪制圖像類別和隨機種子(random seed)的條件下,自主完成圖像的繪制:
“給我畫一只啄木鳥,并且它不能是我之前給你看過的那些啄木鳥。”

配圖:StackGAN繪制的合成鳥。
在數學方面, 谷歌研究中心的科學家們用GANs創(chuàng)造了一種編碼協議。GANs的生成方 Alice向Bob傳遞通過卷積神經網絡編碼的信息以及密鑰。Eve則扮演對抗方,即可以拿到編碼的信息,但沒有密鑰。Eve訓練網絡來分辨信息中的噪音和有價值的部分,然而對抗方失敗了,無法將上述兩個部分區(qū)分開來。
在這一網絡結構興起的早期,以及現在,我還從未聽說哪個基于GAN的公開demo(演示程序)可以在完成某句話這一任務上媲美前饋LSTM。雖然前饋LSTM(比如Karpathy特征循環(huán)神經網絡)僅僅是一個基準(baseline),但可以想象遲早有一天,有人會創(chuàng)造出一個可以根據亞馬遜購物網站的商品打分來撰寫評論的GAN 來。
人類通過直接反饋來學習
對我來說,相比強化學習(RL)而言,對抗式學習更接近人類的學習方式。也許因為我是一個喜歡自己找自己麻煩的人吧。
RL通過較大化(平均)最終獎勵來達到訓練目的。當前的狀態(tài)也許與獎勵無關,但最終的結局一定會由“獎勵函數”給出。我已經做過RL領域的一些工作,并且它也極大地促進了我們研究領域的發(fā)展,但是除非你是在玩游戲,否則很難寫出一個獎勵函數來較精確衡量來自周邊環(huán)境的反饋。
二十世紀90年代,強化學習在十五子棋游戲中取得巨大突破,它是DeepMind創(chuàng)造的AlphaGo的一個重要組成部分,DeepMind團隊甚至用RL來節(jié)省谷歌的數據中心的冷卻費用。
可以想象RL能在谷歌數據中心這一環(huán)境中,算得到一個最優(yōu)結果,因為獎勵函數(在防止溫度高于限定值的條件下盡可能省錢)可以很好地定義。這是真實世界可以像游戲一樣被參數化的例子,這樣的例子通常只能在好萊塢電影中見到。
對于那些更實際的問題,獎勵函數是什么呢?即使是類似游戲中的任務如駕駛,其目標既不是盡快達到目的地,也并非始終待在道路邊界線內。我們可以很容易地找到一個負獎勵(比如撞壞車輛,使乘客受傷,不合理地加速)但卻很難找到一個可以規(guī)范駕駛行為的正獎勵。
邊觀察,邊學習
我們是如何學習寫字的?除非你念的是要求很嚴格的小學,否則學習寫字的過程很難說是較大化某個與書寫字母有關的函數。最可能的情況是你模仿老師在黑板上的書寫筆順,然后內化這一過程 。
你的生成網絡書寫字母,而你的識別網絡(對抗方)觀察你的字體和教科書中理想字體的區(qū)別。?

配圖:針對三年級學生的對抗式訓練
屬于你的最嚴厲的批評家
五年前,我在哥倫比亞大學舉行的一場橄欖球比賽中傷到了自己的頭部,導致我右半身腰部以上癱瘓。受傷兩周后我出了重癥監(jiān)護病房,開始教自己學習如何寫字。那時我住在布魯克林的公寓里。

配圖:再次學習如何寫字, 五月
我的左腦受到了嚴重的創(chuàng)傷,因此我失去了控制我右胳膊的能力。然而,我大腦的其余部分完好無損,因此我仍能夠識別正確的書寫方式。換句話說,我的文字生成網絡壞了,而識別網絡功能正常。
?
說句玩笑話,我很有可能因為這一過程學會一種新的(或更好的)書寫方式。然而結果是雖然我很快地教會了我自己如何書寫,但書寫筆跡和我受傷前的沒什么兩樣
?
我不知道我們的大腦是如何使用“行為人-批評家”的模式來學習的,我也不知道這種說法是事實還是僅僅是一個生動的比喻,但是可以確定的是在有一個專家即時反饋的條件下,我們可以更有效率地學習新東西。
?
當學習編程或攀巖時,如果你一直接收某個專家的“beta(反饋建議)”,則可以進步得更快。在你獲得足夠的經驗能夠自我反饋批評之前,有一個外部的批評家來糾正你每一小步的錯誤可以更容易訓練你大腦的生成網絡。即使有一個內部批評家在監(jiān)督你,學習一個有效的生成網絡仍然需要認真的練習。我們總不能把我們大腦的生成器換成亞馬遜推出的GPU實例吧。

擺脫糾結,勇往直前?
實際中,GANs 被用于解決這樣一些問題:為生成器生成的圖片添加一些真實的效果如銳化邊緣。盡管在這樣的圖片中,不一定每個動物都只有一個腦袋。
讓生成網絡與合適的對抗方競爭能迫使其做出取舍。正如我的一位同事所說,你面臨一個選擇,既可以畫一只綠色的鸚鵡,也可以畫一只藍色的鸚鵡,但是你畫的必須是其中之一。一個沒有對抗方的監(jiān)督網絡接受了真實鸚鵡的識別訓練,會傾向于畫出某種摻雜藍色或綠色的平均色,導致其線條模糊不清。而一個對抗式網絡則可以畫出藍色或綠色的鸚鵡,也可以在利用鸚鵡的{藍,綠}概率分布隨機地選擇一種顏色。但它絕不會畫出某種自然鸚鵡不存在的中間色,當然這種顏色也可能存在于已經滅絕的鸚鵡上。
?
我的同事最近理清了關于GANs的思路,其中包括對GANs的收斂性和可推廣性的悲觀態(tài)度。
?
某種程度上,這是由于這種蹺蹺板式的訓練方法——一會兒訓練生成方,一會兒訓練識別方,如此反復——并不能保證收斂于一個穩(wěn)定解,更別提一個最優(yōu)解了。如下圖Alex J Champandard的一則Twitter 所示:
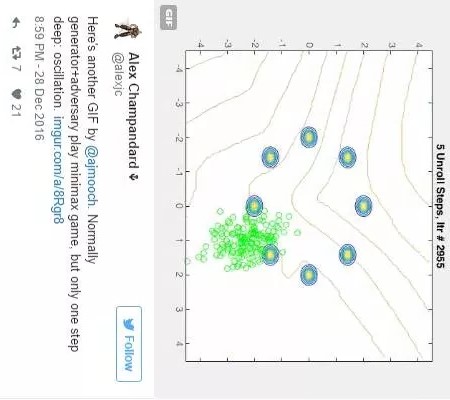
配圖在twitter上是一個GIF圖片,通常情況生成方和對抗方在玩一個極限博弈游戲,但只要再走一步,其將陷入震蕩
但是讓我們忽略這些細節(jié),做一些美好的想象吧。若LSTM模型能寫出調理清楚的產品評論、圖片標題、或者在唐納德競選總統時代替他在twitter上發(fā)聲(反正競選前夜他會保持沉默),那稍微聰明一點的識別器應該都能提高這些任務的表現吧。
?
假設LSTM是隨機生成這些結果的,我們可以利用既有的生成器生成相應的結果,再讓識別器從生成結果中較好的20個中選出最合適的。這不正是DeepDrumpf背后的運營團隊所做的事情嗎?
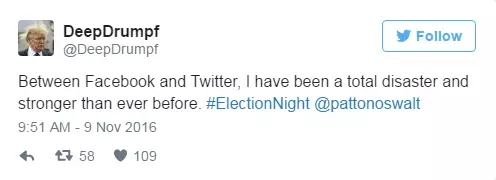
twitter中文字:對于facebook和twitter而言,我一直是一個完全的災難,而且現在比以往更加嚴重了
生成器和識別器,誰更聰明?
一個問題自然而然地出現了——到底哪種網絡能夠真正理解所面臨問題,是生成器還是識別器?或者說究竟誰更會寫字,是寫字的學生,還是教寫字的老師?
?
現實世界通常是老師更會寫字,但在之前的例子中,我想應該是學生更會寫字。因為一個用于識別產品評論的識別器只需知道一些常見的語法錯誤,就能投入使用。正如一個人像米開朗基羅一樣畫畫,一個人僅僅是抬頭看看西斯廷大教堂的天花板(上面有米開朗基羅的畫),誰需要更多的技巧呢?
?
正如我所理解的,手機圖像軟件Prisma在有對抗方的框架下,訓練生成網絡,進行不同風格的創(chuàng)作。大多數風格正是通過這種方式生成了那些曲折的線條。我希望他們能增加訓練GAN的時間,這樣GAN不僅能認出照片中的陰影,并給其涂上不同的顏色,還可能以一個印象派藝術家的風格完成這些任務。當它偶爾可以正確地區(qū)分光線和陰影的時候,那么它就是令人驚嘆的。

順著這條思路想下去可以得出一個很自然的結論,生成式對抗方法,可以讓人工智能有能力做實驗和A/B測試。一個人工智能模型給出了一個很好的解決方案,然后它搜集反饋來了解這個生成方案和標準答案是否相符,或與其他它正在學習或已經內化的人工智能模型比較,觀察得出的結果是否相符。在這一過程中,你沒必要去設計一個損失函數,因為雖然可能會花上一點時間,但這個人工智能模型終將找到自己的評判標準。
適可而止,見好就收
我寫了這整篇文章,卻還沒有親身嘗試一下對抗式網絡。本著模仿的心態(tài),我期望其他人能夠在GANs上取得進步,較好是在文字生成領域取得突破。我預計很快就會有合適的技術,能夠良好運行并得到令人信服的結果。我們這個領域正是這樣,通過積累前人的經驗而進步的。
?
與其去預測我沒有參與過的事,我更應該花時間去優(yōu)化我的“撲克牌卷積神經網絡”(PokerCNN)無限額德州撲克AI,為今年的年度計算機撲克大賽作準備。其代碼將在2017年1月13日前完成。
?
在明年的比賽中我計劃添加一些對抗式訓練。不難想象對抗式訓練能夠幫助AI學習更好的撲克技巧。特別是當對手也是很強大的黑箱AI時,這個方法更為有用。
?
既然是科學為目的,并且我的撲克牌AI代碼已經開源了(在你看到這里時,我應該已經清理了代碼倉庫,并且添加了一個的readme幫助文檔,所以應該可以更容易著手),所以請隨意拿去嘗試吧。
鏈接:向后看,向先看
如果沒有點出2016年深度學習領域中我最喜歡的幾大進步,那我就太怠惰了。以下列出了幾個我最愛的進步:
?
? ?2016年深度學習的主要進步: GANs, 非監(jiān)督學習領域的進步, 超分辨率,以及其他種種突破
? ?“我在神經信息處理大會上學到的50樣東西” 作者Andreas Stuhlmller
?
? ?以上幾條中我最喜歡的想法是:用不同的時期間隔來訓練LSTM記憶單元,這樣可以迫使某些記憶單元記住長期信息,而其它的記憶單元可以更加關注短期記憶。這種方法更符合直覺,也避免了過多的超參數調優(yōu)
?
? ?大公司和有足夠資金的創(chuàng)業(yè)公司是否都在貪婪地尋找優(yōu)質的深度學習數據?也許有專利的數據庫并不是所有人工智能的關鍵問題所在。并且維基百科也列出了一大堆免費的數據庫,包括前文提到的亞馬遜的商品評論。隨著很多公司繼續(xù)提供其擁有的大部分數據用于研究,以后將會涌現更多的數據。
歡迎加入本站公開興趣群商業(yè)智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4444.html
摘要:自年提出生成對抗網絡的概念后,生成對抗網絡變成為了學術界的一個火熱的研究熱點,更是稱之為過去十年間機器學習領域最讓人激動的點子。 自2014年Ian Goodfellow提出生成對抗網絡(GAN)的概念后,生成對抗網絡變成為了學術界的一個火熱的研究熱點,Yann LeCun更是稱之為過去十年間機器學習領域最讓人激動的點子。生成對抗網絡的簡單介紹如下,訓練一個生成器(Generator,簡稱G...
摘要:但年在機器學習的較高級大會上,蘋果團隊的負責人宣布,公司已經允許自己的研發(fā)人員對外公布論文成果。蘋果第一篇論文一經投放,便在年月日,斬獲較佳論文。這項技術由的和開發(fā),使用了生成對抗網絡的機器學習方法。 GANs「對抗生成網絡之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演講是聊他的代表作生成對抗網絡(GAN/Generative Adversarial ...
摘要:我仍然用了一些時間才從神經科學轉向機器學習。當我到了該讀博的時候,我很難在的神經科學和的機器學習之間做出選擇。 1.你學習機器學習的歷程是什么?在學習機器學習時你最喜歡的書是什么?你遇到過什么死胡同嗎?我學習機器學習的道路是漫長而曲折的。讀高中時,我興趣廣泛,大部分和數學或科學沒有太多關系。我用語音字母表編造了我自己的語言,我參加了很多創(chuàng)意寫作和文學課程。高中畢業(yè)后,我進了大學,盡管我不想去...
摘要:實現這一應用的基本思想方法是將圖像的每一列用向量來表示,計算每一個的平均值,從而得到一個向量。標準加強學習模型通常要求建立一個獎勵函數,用于向代理機器反饋符合預期的行為。來源更多信息自學成才讓好奇驅動計算機學習在很多 還記得《射雕英雄傳》中老頑童發(fā)明的左右互搏術嗎??表面上看,左手與右手互為敵手,斗得不可開交。實際上,老頑童卻憑借此練就了一門絕世武功。?這樣的故事似乎只能發(fā)生在小說中。然而,...
摘要:但是在傳統的機器學習中,特征和算法都是人工定義的。傳統的深度學習中,是由人來決定要解決什么問題,人來決定用什么目標函數做評估。 隨著柯潔與AlphaGo結束以后,大家是不是對人工智能的底層奧秘越來越有興趣?深度學習已經在圖像分類、檢測等諸多領域取得了突破性的成績。但是它也存在一些問題。首先,它與傳統的機器學習方法一樣,通常假設訓練數據與測試數據服從同樣的分布,或者是在訓練數據上的預測結果與在...

閱讀 1979·2021-09-26 10:19
閱讀 3249·2021-09-24 10:25
閱讀 1622·2019-12-27 11:39
閱讀 1918·2019-08-30 15:43
閱讀 662·2019-08-29 16:08
閱讀 3503·2019-08-29 16:07
閱讀 901·2019-08-26 11:30
閱讀 1269·2019-08-26 10:41






