資訊專欄INFORMATION COLUMN

摘要:但年在機器學習的較高級大會上,蘋果團隊的負責人宣布,公司已經允許自己的研發人員對外公布論文成果。蘋果第一篇論文一經投放,便在年月日,斬獲較佳論文。這項技術由的和開發,使用了生成對抗網絡的機器學習方法。
GANs
「對抗生成網絡之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演講是聊他的代表作生成對抗網絡(GAN/Generative Adversarial Networks),這幾年,他每到大會就會講 GAN,畢竟對抗生成網絡之父的頭銜在呢,這塊也是這幾年機器學習、計算機視覺等方向的研究熱點之一。

Ian Goodfellow 是世界上最重要的 AI 研究者之一,他在 OpenAI(谷歌大腦的競爭對手,由 Elon Must 和 Sam Altman 創立)工作過不長的一段時間,今年3月重返 Google Brain, 加入Google Brain,其正在建立了一個探索“生成模型”(generative models)的新研究團隊。

生成模型的概念大家應該都很熟悉,大概有兩種玩法:
密度(概率)估計:就是說在不了解事件概率分布的情況下,先假設隨機分布,然后通過數據觀測來確定真正的概率密度是怎樣的。
樣本生成:這個就更好理解了,就是手上有一把訓練樣本數據,通過訓練后的模型來生成類似的「樣本」。
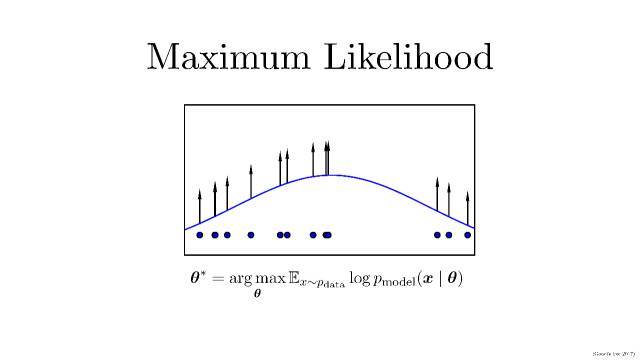
在生成模型這一過程中,首先需要提到概率領域一個方法:較大似然估計,
現實生活中,我們可能并不知道每個 P(概率分布模型)到底是什么,我們已知的是我們可以觀測到的源數據。所以,較大似然估計就是這種給定了觀察數據以評估模型參數(也就是估計出分布模型應該是怎樣的)的方法。
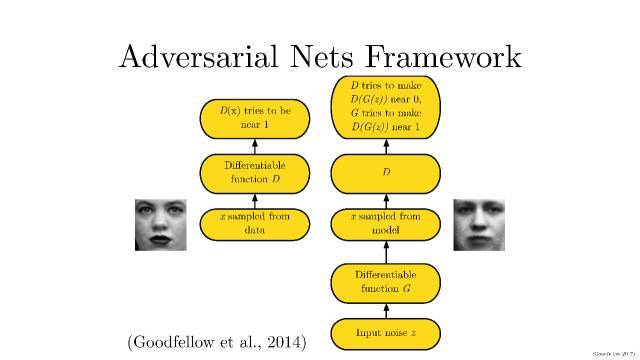
我們在理解生成對抗模型(GAN),首先要知道生成對抗模型拆開來是兩個東西:一個是判別模型,一個是生成模型。就需要提及Ian Goodfellow在2014發表的文章。文章標題:Generative Adversarial Networks。文章鏈接:https://arxiv.org/abs/1406.2661。
具體如下:
簡單打個比方就是:兩個人比賽,看是 A 的矛厲害,還是 B 的盾厲害。比如,我們有一些真實數據,同時也有一把亂七八糟的假數據。A 拼命地把隨手拿過來的假數據模仿成真實數據,并揉進真實數據里。B 則拼命地想把真實數據和假數據區分開。
這里,A 就是一個生成模型,類似于賣假貨的,一個勁兒地學習如何騙過 B。而 B 則是一個判別模型,類似于警察叔叔,一個勁兒地學習如何分辨出 A 的騙人技巧。
如此這般,隨著 B 的鑒別技巧的越來越牛,A 的騙人技巧也是越來越純熟。
一個造假一流的 A,就是我們想要的生成模型!

我們現在能使用GANs做什么,這幾年各種圍繞關于GANs的研究應用很多很多。
學習訓練數據的分布;
在更多的情況是,我們會面臨缺乏數據的情況,我們可以通過生成模型來補足。比如,用在半監督學習中;
多標簽預測(同時完成real/fake, 樣本類別等的預測);
根據環境需要生成相應數據(比如,看到一個美女的背影,猜她正面是否會讓你失望……)
可以模擬預測未來數據(用于具有時序關系的圖像)
解決模型推斷問題
學習不錯的embedding(特征表示)信息

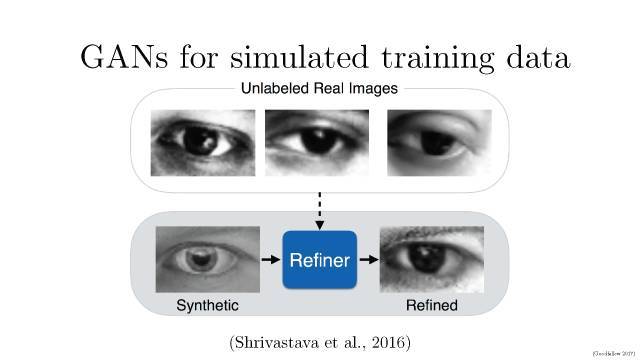
以保密為文化傳統的蘋果一貫不喜歡對外公布自己的研究成果。但2016年在機器學習的較高級大會NIPS上,蘋果AI團隊的負責人RussSalakhutdinov宣布,公司已經允許自己的AI研發人員對外公布論文成果。這則消息剛剛宣布沒多久,蘋果就發表了自己的第一篇論文,題目叫做《通過對抗訓練從模擬與無監督圖像中學習》,論文描述了如何利用計算機生成的圖像而不是真實圖像改進算法識別圖像能力的訓練。此舉一方面可以提高蘋果在AI界的存在感,同時如果其研究成果出色的話,也能在學術界贏得同行認可,并吸引到AI方面的人才。蘋果第一篇AI論文一經投放,便在2017年7月22日,斬獲CVPR 2017較佳論文。

谷歌新論文使用生成對抗網絡的無監督像素級域適應, 發表在CVPR 2017
Unsupervised Pixel-Level Domain Adaptation WithGenerative Adversarial Networks
對于許多任務而言,收集標注良好的數據集去訓練現代的機器學習算法是極其昂貴
的。渲染合成數據倒是一個吸引人的選擇,本文的方法能以無監督的方式學習一個像素空間中從一個域到另一個域的變換。基于生成對抗網絡(GAN)的方法能夠使源域(source-domain)圖像看起來就像是來自目標域(target domain)的一樣。這個模型不僅能生成看似可信的樣本,而且表現還極大超越了許多當前較佳的無監督域適應情況。

開始介紹面臨缺乏數據的情況,我們可以通過生成模型來補足。

內容識別填充(: Content-aware fill ,是 photoshop 的一個功能)是一個強大的工具,設計師和攝影師可以用它來填充圖片中不想要的部分或者缺失的部分。在填充圖片的缺失或損壞的部分時,圖像補全和修復是兩種密切相關的技術。有很多方法可以實現內容識別填充,圖像補全和修復。在這篇博客中,我會介紹 RaymondYeh 和 Chen Chen 等人的一篇論文,“基于感知和語境損失的圖像語義修補(Semantic Image Inpainting with Perceptual and ContextualLosses)”。論文在2016年7月26號發布于 arXiv 上,介紹了如何使用 DCGAN 網絡來進行圖像補全。

體驗一下半監督學習。

將產生式對抗網絡(GAN)拓展到半監督學習,通過強制判別器來輸出類別標簽。我們在一個數據集上訓練一個產生式模型 G 以及 一個判別器 D,輸入是N類當中的一個。在訓練的時候,D被用于預測輸入是屬于 N+1的哪一個,這個+1是對應了G的輸出。這種方法可以用于創造更加有效的分類器,并且可以比普通的GAN 產生更加高質量的樣本。
文章標題:Semi-Supervised Learning with Generative Adversarial Networks;文章鏈接:https://arxiv.org/abs/1606.01583。
文章標題:Improved Techniques for Training GANs
文章鏈接:https://arxiv.org/abs/1606.03498

開始介紹多標簽預測(同時完成real/fake, 樣本類別等的預測);

Next video frame prediction(未來幀預測) 主要完成的任務是根據視頻中已有幀的相關數據預測某一幀所對應的下一幀數據,例如圖中所示的人物頭像數據(文章主要利用大量未標注數據)。通過GAN對其之前數據規律的學習,合成其未發生的下一幀數據。這可以使我們通過海量數據的學習,達到預測未來未發生事件的效果。
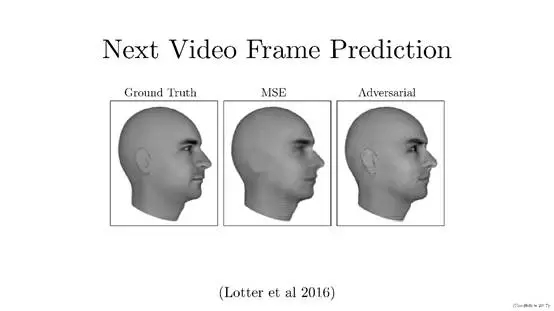
圖中所示3張人物頭像數據,圖1為原始圖像,圖2是通過傳統圖像合成方式所得圖像,圖3為通過GAN生成的圖像。通過圖2和圖3的對比可以發現通過GAN合成的圖像邊緣模糊情況大大減輕,圖像分辨率有所提高,紋理與原圖也更接近。這是Lotter 等人在2016年提出了一種新穎的“PredNet”結構。文章標題:Deep Predictive CodingNetworks for Video Prediction and Unsupervised Learning。 網址鏈接:https://arxiv.org/abs/1605.08104。

這個工作是Yann LeCun組的Michael Mathieu等人 2015年提出的,文章標題:Deep multi-scale videoprediction beyond mean square error。網址鏈接:https://arxiv.org/abs/1511.06434。
主要是用對抗式訓練進行視頻預測的,研究解決了一個非常重要的問題,那就是,當你訓練一個神經網絡(或者其他任何模型)來預測未來,如果要預測的東西有多種可能性時,一個網絡以傳統的方式進行預測(比如,用最小平方),將會預測出所有可能性的平均值。在視頻的例子中,有很多模糊的混亂。對抗式訓練能讓系統產出其想要的任何東西,只要是在鑒別器喜歡的任何數據庫內就可以,這解決了在不確定條件下進行預測的“模糊”難題。

下面介紹根據環境需要生成相應數據。

在自動生成任務中,在線時尚科技公司 Vue.ai 開發了一種或將取代模特的自動生成試裝照片的系統,該系統使用GAN技術,可以控制所需模特照片的體型、膚色、身高、鞋子等等,不僅是模特,攝影師和工作室都可以不需要了,對于電商和零售業來說是好消息。這項技術由 Vue.ai 的 Anand Chandrasekaran 和 Costa Colbert 開發,使用了生成對抗網絡(GAN)的機器學習方法。這個系統由兩個AI組成:一個生成器(generative)和一個評論家(critic),生成器試圖生成一張看起來很好的圖像,而批評家則決定這張圖像是否看起來足夠好。

跳過兩部分,直接講如何得到數據的embedding(特征表示)信息。

在特征表示學習這塊,Radford 等人在2015年提出了DCGAN,文章標題是:Unsupervised Representation Learning with DeepConvolutional Generative Adversarial Networks,網址鏈接:https://arxiv.org/abs/1511.06434。
這篇文章,主要是想從大量無標簽數據集中學習可重復使用的特征表示。在計算機視覺的背景下,實際上,可以利用不限數量的無標簽圖像和視頻來學習一個好的中間表示,這個表示可以用在大量有監督的學習任務上,例如圖像分類。提出一種方法,可以建立好的圖像表示,通過訓練對抗生成網絡(GAN),并且反復利用生產網絡和辨別網絡的一部分作為有監督任務的特征提取。熟悉卷積神經網絡(CNN)的同學對此應該不會陌生,這其實就是一個反向的 CNN。
熟悉NLP 的同學可能發現了,這就很像 word2vec 里面的:king- man + woman = queen。做個向量/矩陣加減并不難,難的是把加減后得到的向量/矩陣還原成「圖義」上代表的圖片。在 NLP 中,word2vec 是把向量對應到有意義的詞。在這里,DCGAN 是把矩陣對應到有意義的圖片。即:戴墨鏡的男人 - 不戴墨鏡的男人 + 不戴墨鏡的女人= 戴墨鏡的女人

在樣本生成這一過程,生成對抗網絡實現這些需要多久?

Odena等人在2016年提出了Auxiliary Classifier GANs(AC-GANs),文章名字是:Conditional Image Synthesis with Auxiliary Classifier GANs。網址鏈接:https://arxiv.org/abs/1610.09585。
主要提出AC-GAN模型,在D又新加了分類器,在輸出樣本真假的同時輸出類別,在D的輸出部分添加一個輔助的分類器來提高條件GAN的性能。針對任務,提出這種新的Inception Accuracy的評價方法,并引入了MS-SSIM用于判斷模型生成圖片的多樣性。
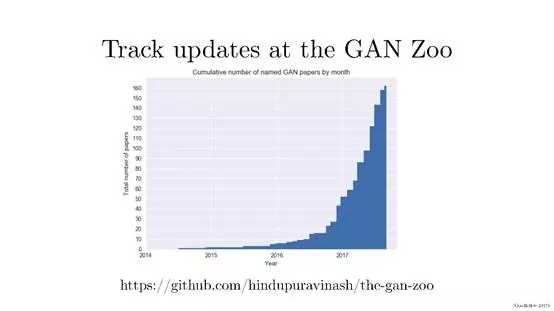
這是Github上的關于Gan方法的相關list,https://github.com/hindupuravinash/the-gan-zoo。
我們能看到每周都會有新的GAN論文出來,很難跟蹤所有的文章,更不用說研究人員使用一些令人難以置信的創造性的方式來命名這些生成對抗性網絡!由這個圖,我們知道這兩年特別是2017年相關GAN命名的文章增長很迅速。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4663.html
摘要:據報道,生成對抗網絡的創造者,前谷歌大腦著名科學家剛剛正式宣布加盟蘋果。他將在蘋果公司領導一個機器學習特殊項目組。在加盟蘋果后會帶來哪些新的技術突破或許我們很快就會看到了。 據 CNBC 報道,生成對抗網絡(GAN)的創造者,前谷歌大腦著名科學家 Ian Goodfellow 剛剛正式宣布加盟蘋果。他將在蘋果公司領導一個「機器學習特殊項目組」。雖然蘋果此前已經縮小了自動駕駛汽車研究的規模,但...
摘要:的研究興趣涵蓋大多數深度學習主題,特別是生成模型以及機器學習的安全和隱私。與以及教授一起造就了年始的深度學習復興。目前他是僅存的幾個仍然全身心投入在學術界的深度學習教授之一。 Andrej Karpathy特斯拉 AI 主管Andrej Karpathy 擁有斯坦福大學計算機視覺博士學位,讀博期間師從現任 Google AI 首席科學家李飛飛,研究卷積神經網絡在計算機視覺、自然語言處理上的應...
摘要:陳啟峰認為,這種技術前途大好,最終可以用于創造真正模擬現實世界的游戲場景。小學時,陳啟峰先后獲得全國作文競賽二等獎和奧數競賽一等獎。年,歲的陳啟峰發表論文,提出數據結構。 『凡所有相,皆是虛妄』上面這張德國街道圖片,乍一看像是行車記錄儀拍的,又好像谷歌街景照片加了復古濾鏡。實際上,這是一張合成圖片。在谷歌地圖上,根本找不到這樣的街道。一個神經網絡,根據自己在訓練過程中見過的真實街道,生成了它...
摘要:文本谷歌神經機器翻譯去年,谷歌宣布上線的新模型,并詳細介紹了所使用的網絡架構循環神經網絡。目前唇讀的準確度已經超過了人類。在該技術的發展過程中,谷歌還給出了新的,它包含了大量的復雜案例。谷歌收集該數據集的目的是教神經網絡畫畫。 1. 文本1.1 谷歌神經機器翻譯去年,谷歌宣布上線 Google Translate 的新模型,并詳細介紹了所使用的網絡架構——循環神經網絡(RNN)。關鍵結果:與...

閱讀 576·2023-04-26 01:42
閱讀 3222·2021-11-22 11:56
閱讀 2392·2021-10-08 10:04
閱讀 836·2021-09-24 10:37
閱讀 3125·2019-08-30 15:52
閱讀 1732·2019-08-29 13:44
閱讀 472·2019-08-28 17:51
閱讀 2141·2019-08-26 18:26





