資訊專欄INFORMATION COLUMN

摘要:今天推出了一個名叫的開源工具,用深度神經網絡來從測序數據中快速較精確識別堿基變異位點。今天,團隊,聯合同屬于旗下的生命科學兄弟公司,用了兩年多時間,研發出了一個名叫的開源工具,專門用深度神經網絡來識別結果中測序數據里這些堿基變異位點。
Google今天推出了一個名叫DeepVariant的開源工具,用深度神經網絡來從DNA測序數據中快速較精確識別堿基變異位點。
學科研究的革命性進展,特別是基因學上,需要依賴于新技術的出現。比如桑格發明了測序法之后,才實現了人類基因組的測序。
再比如DNA(微陣列)芯片技術的誕生,使得大規模的基因測序成為可能。這些技術讓我們能夠獲得大量遺傳信息,可以更廣泛地應用于健康、農業和生態上。
基因測序領域里,最革命性的技術當屬2000年初首次商用的高通量測序(縮寫為HTS)了。HTS可以大規模、低成本、快速地獲得任何生物的基因序列。
不過,HTS有個致命的問題在于,測序出來的結果不是完整的,而是碎片化的片段信息。
比如測的是人的基因序列的話(也就是說,信息量級為23對染色體上的30億對堿基排序),那么得到的測序結果是不到10億個短序列片段,一般每個短序列片段我們稱為讀取單位(reads)。
每個讀取單位含有100個堿基對(不同讀取單位的信息需要重疊,才能最后拼全),而每個堿基的錯誤率范圍是0.1%到10%。所以,一直以來,對于HTS來說,較大的挑戰是把碎片化的結果信息拼成一整段完整的序列信息。
瓶中基因組聯盟Genome in a Bottle Consortium(GIAB),和精準FDA平臺(美國藥監局做的基因組信息學社區和共享數據平臺)一樣,致力于提高基于HTS基因測序結果。他們能提供高精度的人體基準基因組序列信息。
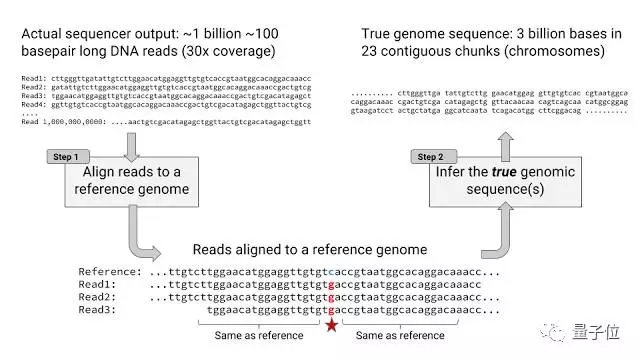
把測序結果與基準基因序列一比對,就可以得到很多個堿基變異位點(就是上圖打星的地方),這些位點,可能是SNP單核苷酸多態性導致的,也可能是測序過程中復制出錯造成的。
今天,Google Brain團隊,聯合同屬于Alphabet旗下的生命科學兄弟公司Verily,用了兩年多時間,研發出了一個名叫DeepVariant的開源工具,專門用深度神經網絡來識別HTS結果中DNA測序數據里這些堿基變異位點。這個工具在準確率上和較精確度上,比傳統的比對拼接方法都高出一大截。
DeepVariant,把工作量巨大的拼接問題(HTS碎片化的結果拼接成完整的基因序列),轉變成了一個典型的圖像分類問題。而圖像分類正是谷歌擅長的技術。
2016年,DeepVarient還在PrecisionFDA Truth Challenge中贏得了較高SNP性能獎(Highest SNP Performance)。在那之后,Google Brain團隊又將錯誤率降低了50%。
下面的四幅圖,分別代表實際測序的片段和基準序列的比對結果。

?A:單核苷酸多態性造成的堿基變異位點;
B:一條染色體上少了一個堿基;
C:兩條染色體上都少了一個堿基;
D:復制錯了的堿基變異位點。
在比對過程中,要回答的一個關鍵的問題是,怎么判斷比對后得到的堿基變異位點,是存在于兩條染色體中,還是只在一條里,還是都沒有。造成堿基變異位點的原因不只一種,最常見的三種可能是單核苷酸多態性,或多插了一個堿基,或少復制了一個堿基。
這些變異位點如果用視覺識別的算法就能快速找出來。大大提高HTS后的比對拼接的效率。
因為瓶中基因組聯盟Genome in a Bottle Consortium(GIAB)提供的人體基準基因組序列信息是高精度可信的,或者更嚴謹地說,是最接近真實序列的信息。
通過這個基準序列得到的復制數據,谷歌團隊可以拿它們來訓練基于Tensor Flow的圖像分類模型,所得到的DeepVariant,最后可以區別真實序列數據和復制數據。
盡管DeepVariant根本不懂什么是基因組序列,也不懂HTS,但是只用了一年,就已經贏得了PrecisionFDA Truth Challenge中的較高SNP性能獎(Highest SNP Performance)。而且到目前為止,把已有最優異的方法拼接錯誤率降低了50%多。
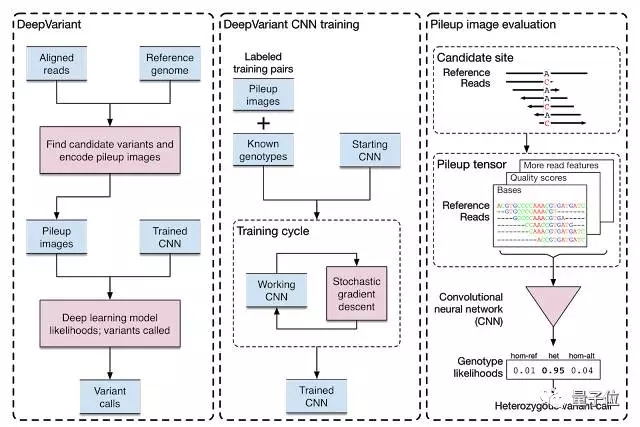
在發布開源代碼的同時,Google Brain還發布Google Cloud上的DeepVarient工作流,方便開發者用它來處理大型數據集。
最后,附上相關鏈接:
Google Research Blog介紹:
https://research.googleblog.com/2017/12/deepvariant-highly-accurate-genomes.html
開源代碼:
https://github.com/google/deepvariant
Google Cloud版:
https://cloud.google.com/genomics/deepvariant
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4683.html
摘要:今年,發布了面向開發者的全新機器學習框架。今年,圍繞,谷歌同樣做出了幾項重大宣布發布新的官方博客與頻道面向開發者的全新機器學習框架發布一系列新的庫與工具例如等。提供了多種適用于張量的線性代數和機器學習運算的。 當時時間 3 月 30 日,谷歌 TenosrFlow 開發者峰會 2018 在美國加州石景山開幕,來自全球的機器學習用戶圍繞 TensorFlow 展開技術演講與演示。去年的 Ten...
摘要:阿里云基因數據服務不斷提升極致彈性的計算能力,和大規模并行處理能力,以及海量高速存儲來幫助基因公司快速自動化處理每天幾十上百的下機數據,并產通過標準產出高質量的變異數據。 摘要:?一家大型基因測序功能公司每日會產生 10TB 到 100TB 的下機數據,大數據生信分析平臺需要達到 PB 級別的數據處理能力。這背后是生物科技和計算機科技的雙向支撐:測序應用從科研逐步走向臨床應用,計算模...
摘要:被稱為亞馬遜的新服務提供了強大的功能,如圖像分析,文本到語音轉換和自然語言處理。換句話說,其任務是將谷歌的機器學習功能產品化。亞馬遜平臺推出的這些新服務中的第一個是名為的圖像識別服務。 亞馬遜一直在其零售業務中使用深度學習和人工智能來提高客戶體驗。該公司聲稱,它有數千名工程師專門從事人工智能相關開發,以改善搜索、物流、產品推薦和庫存管理。亞馬遜現在正在將相同的專業知識帶給云,展示了開發人員可...

閱讀 1599·2021-11-22 09:34
閱讀 1690·2019-08-29 16:36
閱讀 2668·2019-08-29 15:43
閱讀 3113·2019-08-29 13:57
閱讀 1297·2019-08-28 18:05
閱讀 1874·2019-08-26 18:26
閱讀 3242·2019-08-26 10:39
閱讀 3453·2019-08-23 18:40




