資訊專欄INFORMATION COLUMN

摘要:在本教程中,我會(huì)介紹如何只使用低級別的工具從零開始構(gòu)建卷積神經(jīng)網(wǎng)絡(luò),以及使用可視化我們的計(jì)算圖和網(wǎng)絡(luò)的表現(xiàn)。選擇模型接下來,我必須決定使用哪個(gè)卷積神經(jīng)網(wǎng)絡(luò)的模型。實(shí)質(zhì)上,大多數(shù)卷積神經(jīng)網(wǎng)絡(luò)都包含卷積和池化。
如果使用TensorFlow的所有較高級別的工具,例如tf.contrib.learn和Keras,你可以輕松地使用非常少量的代碼來構(gòu)建卷積神經(jīng)網(wǎng)絡(luò)。但是經(jīng)常使用這些較高級別的應(yīng)用,你就沒法看到它們內(nèi)部的代碼,從而缺失了對這些應(yīng)用背后所發(fā)生的事情的理解。
在本教程中,我會(huì)介紹如何只使用低級別的TensorFlow工具從零開始構(gòu)建卷積神經(jīng)網(wǎng)絡(luò),以及使用TensorBoard可視化我們的計(jì)算圖和網(wǎng)絡(luò)的表現(xiàn)。如果你還不了解全連接神經(jīng)網(wǎng)絡(luò)的一些基礎(chǔ)知識,我強(qiáng)烈建議你首先查看這篇《這不是另外一個(gè)使用TensorFlow來做MNIST數(shù)字圖像識別的教程》。在本文中我也會(huì)把卷積神經(jīng)網(wǎng)絡(luò)的每個(gè)步驟分解到基礎(chǔ)的程度,以便你可以完全了解計(jì)算圖中的每個(gè)步驟。通過從零開始構(gòu)建該模型,你可以輕松地將計(jì)算圖的各方面可視化,以便可以看到每層卷積并使用它們做出你自己的推斷。我會(huì)只強(qiáng)調(diào)主要代碼,如果想查看全部代碼,你可以在GitHub上找到相應(yīng)的Jupyter Notebook文件。
獲得一個(gè)數(shù)據(jù)集
一開始我需要決定要使用哪個(gè)圖像數(shù)據(jù)集。我決定用牛津大學(xué)視覺幾何團(tuán)隊(duì)的寵物數(shù)據(jù)集。我之所以選擇這個(gè)數(shù)據(jù)集,是因?yàn)樗芎唵吻矣泻芎玫臉?biāo)注,同時(shí)訓(xùn)練數(shù)據(jù)也足夠多,而且還有對象邊界區(qū)域標(biāo)注——如果我以后想訓(xùn)練一個(gè)對象檢測模型就可以使用該信息。另一個(gè)我認(rèn)為對于構(gòu)造第一個(gè)模型非常好的數(shù)據(jù)集是在Kaggle上發(fā)現(xiàn)的辛普森數(shù)據(jù)集,其中有很多可用于訓(xùn)練的簡單數(shù)據(jù)。
選擇模型
接下來,我必須決定使用哪個(gè)卷積神經(jīng)網(wǎng)絡(luò)的模型。非常流行的一些模型包括GoogLeNet或VGG16,它們都具有多個(gè)卷積層可用于檢測具有1000多個(gè)類別的ImageNet數(shù)據(jù)集。不過我要使用一個(gè)更簡單的四層卷積網(wǎng)絡(luò):

圖1 圖片由Justin Francis友情提供
我們分解一下這個(gè)模型。它從一張224x224x3的圖像開始,在三個(gè)通道上通過卷積得到32個(gè)特征圖。我們將這組32個(gè)特征圖一起卷積得到另外32個(gè)特征。 然后將其池化得到112x112x32的圖像,隨后兩次卷積得到64個(gè)特征,最后池化到56x56x64。然后將這個(gè)最終池化的層的每個(gè)單元全連接到512個(gè)神經(jīng)元上,并基于類別的數(shù)量最后連接到softmax層。
處理和構(gòu)建數(shù)據(jù)集
首先我們開始加載依賴項(xiàng),其中包括一組我所編寫的imFunctions函數(shù),它可以幫助來處理圖像數(shù)據(jù)。
import imFunctions as imf
import tensorflow as tf
import scipy.ndimage
from scipy.misc import imsave
import matplotlib.pyplot as plt
import numpy as np
然后,我們可以使用imFunctions下載和提取圖像。
imf.downloadImages(‘a(chǎn)nnotations.tar.gz’, 19173078)
imf.downloadImages(‘images.tar.gz’, 791918971)
imf.maybeExtract(‘a(chǎn)nnotations.tar.gz’)
imf.maybeExtract(‘images.tar.gz’)
我們可以將圖像分到不同的文件夾,包括訓(xùn)練和測試文件夾。 sortImages函數(shù)中的參數(shù)數(shù)值表示測試數(shù)據(jù)跟訓(xùn)練數(shù)據(jù)的百分比。
imf.sortImages(0.15)
接著使用一個(gè)相應(yīng)的one hot向量將我們的數(shù)據(jù)集構(gòu)建成一個(gè)numpy數(shù)組以表示我們的類別。它還也會(huì)從所有的訓(xùn)練和測試圖像中減去圖像的平均值,這是在構(gòu)建卷積網(wǎng)絡(luò)時(shí)的標(biāo)準(zhǔn)化動(dòng)作。該函數(shù)會(huì)詢問你要包括哪些類別——由于我有限的GPU 內(nèi)存(3GB),我選擇了一個(gè)非常小的數(shù)據(jù)集,試圖區(qū)分兩種狗:柴犬和薩摩耶犬。
train_x, train_y, test_x, test_y, classes, classLabels = imf.buildDataset()
卷積和池化是如何工作的
現(xiàn)在我們有了一個(gè)可用的數(shù)據(jù)集,不過讓我們先停一下,看看卷積的最底層是如何工作的。在跳到彩色卷積濾波器之前,讓我們來看一張灰度圖以確保能弄明白每個(gè)細(xì)節(jié)。讓我們編寫一個(gè)7×7的濾波器可用于四個(gè)不同的特征圖。TensorFlow的conv2d函數(shù)相當(dāng)簡單,它有四個(gè)變量:輸入、濾波器、步幅、填充方式。在TensorFlow網(wǎng)站上是這么描述conv2d函數(shù)的:
對于給定的4維輸入和濾波器張量計(jì)算一個(gè)2維卷積。
輸入是一個(gè)維度為[batch,in_height,in_width,in_channels]的一個(gè)張量,濾波器/核張量的維度是[filter_height,filter_width,in_channels,out_channels]。
因?yàn)槲覀冋谔幚砘叶葓D像,所以in_channels是1,而我們應(yīng)用了四個(gè)濾波器,所以out_channels將會(huì)是4。我們將圖2里所示的四個(gè)濾波器/核應(yīng)用到一張圖像或每批批次一張。

圖2 圖像由Justin Francis友情提供
讓我們來看下這個(gè)過濾器是如何影響我們輸入的灰度圖像的。
gray = np.mean(image,-1)
X = tf.placeholder(tf.float32, shape=(None, 224, 224, 1))
conv = tf.nn.conv2d(X, filters, [1,1,1,1], padding=”SAME”)
test = tf.Session()
test.run(tf.global_variables_initializer())
filteredImage = test.run(conv, feed_dict={X: gray.reshape(1,224,224,1)})
tf.reset_default_graph()
這會(huì)返回一個(gè)4維(1, 224, 224, 4)的張量,我們可以用來可視化這四個(gè)濾波器:

圖3 圖像由Justin Francis友情提供
很明顯可以看到濾波器內(nèi)核的卷積是非常強(qiáng)大的。將其分解,我們的7×7內(nèi)核每次以1的步幅覆蓋49個(gè)圖像像素,將每個(gè)像素的值乘以每個(gè)內(nèi)核值,然后將所有49個(gè)值加在一起以構(gòu)成一個(gè)像素。如果你對圖像濾波器內(nèi)核的思想仍然覺得沒有感覺,我強(qiáng)烈推薦這個(gè)網(wǎng)站——他們在內(nèi)核可視化方面做得非常出色。
實(shí)質(zhì)上,大多數(shù)卷積神經(jīng)網(wǎng)絡(luò)都包含卷積和池化。最常見的是,一個(gè)用于卷積的3×3內(nèi)核濾波器。特別是,以2×2的步幅和2×2內(nèi)核的較大值池化是基于內(nèi)核中的較大像素值來縮小圖像的一種激進(jìn)方式。下圖展示的是一個(gè)內(nèi)核為2X2和兩維上步幅都為2的簡單例子。
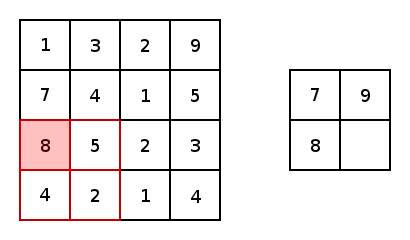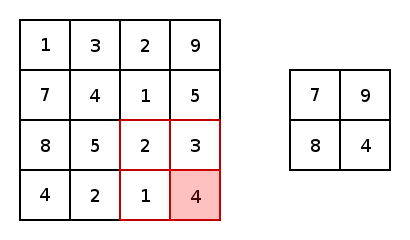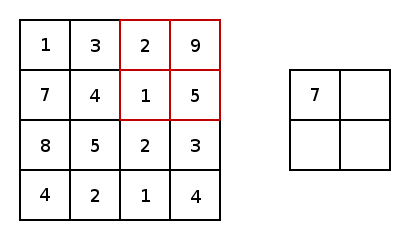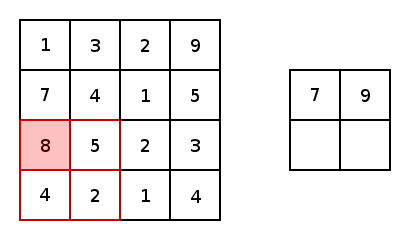
圖4 圖片由Justin Francis友情提供
對于conv2d和較大值池化,它們都有兩個(gè)填充選項(xiàng):“VALID”會(huì)縮小輸入圖像;“SAME”會(huì)通過在輸入圖像邊緣周圍添加零來保持輸入圖像大小。下圖是一個(gè)內(nèi)核為3×3步幅為1×1的最值大池化的示例,展示了不同的填充選項(xiàng)的結(jié)果:
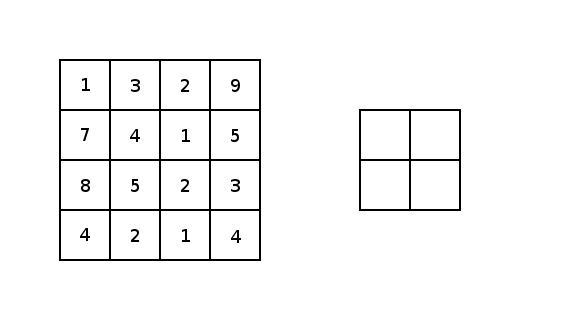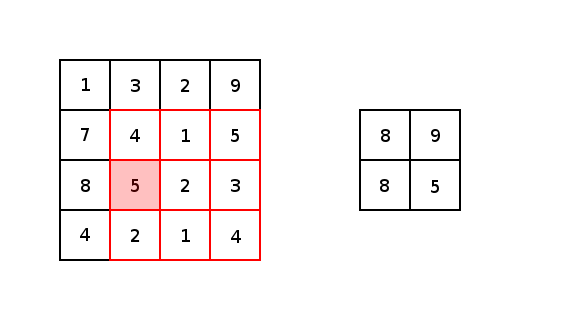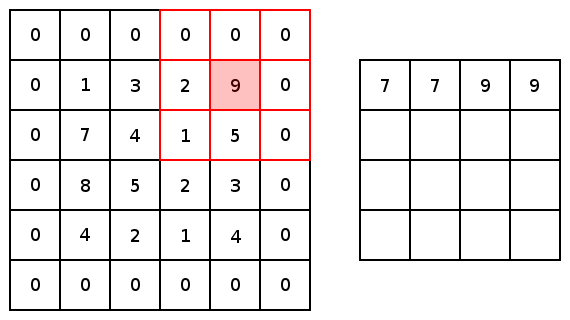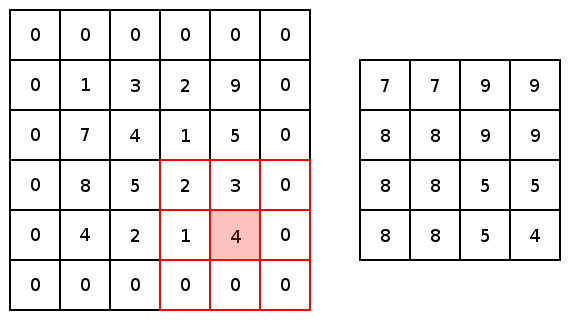
圖5 圖像由Justin Francis友情提供
構(gòu)建卷積神經(jīng)網(wǎng)
我們已經(jīng)介紹了基本知識,現(xiàn)在讓我們開始構(gòu)建我們的卷積神經(jīng)網(wǎng)絡(luò)模型。我們可以從占位符開始。 X是我們的輸入符,我們將把圖像輸入到X中,Y_是一組圖像的真實(shí)類別。
X = tf.placeholder(tf.float32, shape=(None, 224, 224, 3))
Y_ = tf.placeholder(tf.float32, [None, classes])
keepRate1 = tf.placeholder(tf.float32)
keepRate2 = tf.placeholder(tf.float32)
我們將在一個(gè)命名空間內(nèi)創(chuàng)建每個(gè)過程的所有部分。命名空間對以后在TensorBoard中可視化計(jì)算圖是非常有用的,因?yàn)樗鼈儗⑺袞|西都打包成一個(gè)可擴(kuò)展的對象。我們創(chuàng)建了第一組內(nèi)核大小為3×3的濾波器,需要三個(gè)通道分別輸出32個(gè)濾波器。這意味著32個(gè)濾波器中的每一個(gè)R、G和B通道都會(huì)有3×3的內(nèi)核權(quán)重。非常重要的是我們?yōu)V波器的權(quán)重值是使用截?cái)嗾植紒沓跏蓟模詴?huì)有多個(gè)隨機(jī)濾波器使TensorFlow能適用于我們的模型。
# CONVOLUTION 1 – 1
with tf.name_scope(‘conv1_1′):
filter1_1 = tf.Variable(tf.truncated_normal([3, 3, 3, 32], dtype=tf.float32, stddev=1e-1), name=’weights1_1′)
stride = [1,1,1,1]
conv = tf.nn.conv2d(X, filter1_1, stride, padding=’SAME’)
biases = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32), trainable=True, name=’biases1_1′)
out = tf.nn.bias_add(conv, biases)
conv1_1 = tf.nn.relu(out)
在第一層卷積的最后,conv1_1使用了relu函數(shù),它是將每個(gè)負(fù)數(shù)賦值為零的閾。然后我們將這32個(gè)特征跟另外的32個(gè)特征做卷積。你可以看到conv2d的輸入是第一個(gè)卷積層的輸出。
# CONVOLUTION 1 – 2
with tf.name_scope(‘conv1_2′):
filter1_2 = tf.Variable(tf.truncated_normal([3, 3, 32, 32], dtype=tf.float32,
stddev=1e-1), name=’weights1_2′)
conv = tf.nn.conv2d(conv1_1, filter1_2, [1,1,1,1], padding=’SAME’)
biases = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32),
trainable=True, name=’biases1_2′)
out = tf.nn.bias_add(conv, biases)
conv1_2 = tf.nn.relu(out)
然后進(jìn)行池化將圖像縮小一半。
# POOL 1
with tf.name_scope(‘pool1′):
pool1_1 = tf.nn.max_pool(conv1_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding=’SAME’,
name=’pool1_1′)
pool1_1_drop = tf.nn.dropout(pool1_1, keepRate1)
最后一部分涉及到在池化層上使用dropout(我們將在后面更詳細(xì)地介紹)。然后緊接著是使用64個(gè)特征的兩個(gè)卷積和另一個(gè)池化。請注意第一個(gè)卷積必須將先前的32個(gè)特征通道轉(zhuǎn)換為64。
# CONVOLUTION 2 – 1
with tf.name_scope(‘conv2_1′):
filter2_1 = tf.Variable(tf.truncated_normal([3, 3, 32, 64], dtype=tf.float32,
stddev=1e-1), name=’weights2_1′)
conv = tf.nn.conv2d(pool1_1_drop, filter2_1, [1, 1, 1, 1], padding=’SAME’)
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name=’biases2_1′)
out = tf.nn.bias_add(conv, biases)
conv2_1 = tf.nn.relu(out)
# CONVOLUTION 2 – 2
with tf.name_scope(‘conv2_2′):
filter2_2 = tf.Variable(tf.truncated_normal([3, 3, 64, 64], dtype=tf.float32,
stddev=1e-1), name=’weights2_2′)
conv = tf.nn.conv2d(conv2_1, filter2_2, [1, 1, 1, 1], padding=’SAME’)
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name=’biases2_2′)
out = tf.nn.bias_add(conv, biases)
conv2_2 = tf.nn.relu(out)
# POOL 2
with tf.name_scope(‘pool2′):
pool2_1 = tf.nn.max_pool(conv2_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding=’SAME’,
name=’pool2_1′)
pool2_1_drop = tf.nn.dropout(pool2_1, keepRate1)
接下來我們創(chuàng)建一個(gè)含有512個(gè)神經(jīng)元全連接的網(wǎng)絡(luò)層,它將與我們的大小為56x56x64的pool2_1層的每個(gè)像素建立一個(gè)權(quán)重連接。這會(huì)有超過1億個(gè)不同的權(quán)重值!為了計(jì)算全連接的網(wǎng)絡(luò),我們必須將輸入展開到一維,然后就可以乘以權(quán)重并加上偏置項(xiàng)。
#FULLY CONNECTED 1
with tf.name_scope(‘fc1′) as scope:
shape = int(np.prod(pool2_1_drop.get_shape()[1:]))
fc1w = tf.Variable(tf.truncated_normal([shape, 512], dtype=tf.float32,
stddev=1e-1), name=’weights3_1′)
fc1b = tf.Variable(tf.constant(1.0, shape=[512], dtype=tf.float32),
trainable=True, name=’biases3_1’)
pool2_flat = tf.reshape(pool2_1_drop, [-1, shape])
out = tf.nn.bias_add(tf.matmul(pool2_flat, fc1w), fc1b)
fc1 = tf.nn.relu(out)
fc1_drop = tf.nn.dropout(fc1, keepRate2)
然后是softmax及其相關(guān)的權(quán)重和偏置,最后是我們的輸出Y.
#FULLY CONNECTED 3 & SOFTMAX OUTPUT
with tf.name_scope(‘softmax’) as scope:
fc2w = tf.Variable(tf.truncated_normal([512, classes], dtype=tf.float32,
stddev=1e-1), name=’weights3_2′)
fc2b = tf.Variable(tf.constant(1.0, shape=[classes], dtype=tf.float32),
trainable=True, name=’biases3_2′)
Ylogits = tf.nn.bias_add(tf.matmul(fc1_drop, fc2w), fc2b)
Y = tf.nn.softmax(Ylogits)
創(chuàng)建損失函數(shù)和優(yōu)化器
現(xiàn)在可以開始訓(xùn)練我們的模型。首先必須決定批量大小,我不能使用批量大小超過10以防止耗盡GPU內(nèi)存。然后必須確定周期的數(shù)量,它是指算法循環(huán)遍歷所有分批的訓(xùn)練數(shù)據(jù)的次數(shù),最后是我們的學(xué)習(xí)速率α。
numEpochs = 400
batchSize = 10
alpha = 1e-5
然后我們?yōu)榻徊骒亍⒕葯z查器和反向傳播優(yōu)化器指定范圍。
with tf.name_scope(‘cross_entropy’):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=Ylogits, labels=Y_)
loss = tf.reduce_mean(cross_entropy)
with tf.name_scope(‘a(chǎn)ccuracy’):
correct_prediction = tf.equal(tf.argmax(Y, 1), tf.argmax(Y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.name_scope(‘train’):
train_step = tf.train.AdamOptimizer(learning_rate=alpha).minimize(loss)
接著就可以創(chuàng)建我們的會(huì)話和初始化我們所有的變量。
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
創(chuàng)建TensorBoard用的匯總
現(xiàn)在我們要使用TensorBoard,以便可以看到分類器工作的表現(xiàn)怎么樣。我們將創(chuàng)建兩個(gè)圖:一個(gè)用于我們的訓(xùn)練集,一個(gè)用于我們的測試集。我們可以通過使用add_graph函數(shù)來可視化我們的計(jì)算圖。我們將使用匯總標(biāo)量來衡量我們的總體損失和準(zhǔn)確性,并將我們的匯總合并到一起以便只需調(diào)用write_op來記錄標(biāo)量。
writer_1 = tf.summary.FileWriter(“/tmp/cnn/train”)
writer_2 = tf.summary.FileWriter(“/tmp/cnn/test”)
writer_1.add_graph(sess.graph)
tf.summary.Scalar(‘Loss’, loss)
tf.summary.scalar(‘Accuracy’, accuracy)
tf.summary.histogram(“weights1_1”, filter1_1)
write_op = tf.summary.merge_all()
訓(xùn)練模型
現(xiàn)在我們可以開始編寫進(jìn)行評估和訓(xùn)練的代碼。我們不希望每步的損失和準(zhǔn)確性都使用匯總記錄器來記錄,因?yàn)檫@會(huì)大大減慢分類器的訓(xùn)練速度。因此我們會(huì)每五步記錄一次。
steps = int(train_x.shape[0]/batchSize)
for i in range(numEpochs):
accHist = []
accHist2 = []
train_x, train_y = imf.shuffle(train_x, train_y)
for ii in range(steps):
#Calculate our current step
step = i * steps + ii
#Feed forward batch of train images into graph and log accuracy
acc = sess.run([accuracy], feed_dict={X: train_x[(ii*batchSize):((ii+1)*batchSize),:,:,:], Y_: train_y[(ii*batchSize):((ii+1)*batchSize)], keepRate1: 1, keepRate2: 1})
accHist.append(acc)
if step % 5 == 0:
# Get Train Summary for one batch and add summary to TensorBoard
summary = sess.run(write_op, feed_dict={X: train_x[(ii*batchSize):((ii+1)*batchSize),:,:,:], Y_: train_y[(ii*batchSize):((ii+1)*batchSize)], keepRate1: 1, keepRate2: 1})
writer_1.add_summary(summary, step)
writer_1.flush()
# Get Test Summary on random 10 test images and add summary to TensorBoard
test_x, test_y = imf.shuffle(test_x, test_y)
summary = sess.run(write_op, feed_dict={X: test_x[0:10,:,:,:], Y_: test_y[0:10], keepRate1: 1, keepRate2: 1})
writer_2.add_summary(summary, step)
writer_2.flush()
#Back propigate using adam optimizer to update weights and biases.
sess.run(train_step, feed_dict={X: train_x[(ii*batchSize):((ii+1)*batchSize),:,:,:], Y_: train_y[(ii*batchSize):((ii+1)*batchSize)], keepRate1: 0.2, keepRate2: 0.5})
print(‘Epoch number {} Training Accuracy: {}’.format(i+1, np.mean(accHist)))
#Feed forward all test images into graph and log accuracy
for iii in range(int(test_x.shape[0]/batchSize)):
acc = sess.run(accuracy, feed_dict={X: test_x[(iii*batchSize):((iii+1)*batchSize),:,:,:], Y_: test_y[(iii*batchSize):((iii+1)*batchSize)], keepRate1: 1, keepRate2: 1})
accHist2.append(acc)
print(“Test Set Accuracy: {}”.format(np.mean(accHist2)))
可視化計(jì)算圖
在訓(xùn)練過程中,讓我們通過在終端中激活TensorBoard來檢查運(yùn)行情況。
tensorboard –logdir=”/tmp/cnn/”
可以將Web瀏覽器指向默認(rèn)的TensorBoard地址http://0.0.0.0/6006。讓我們先來看看我們的計(jì)算圖模型。
正如你所看到的,通過使用命名空間屬性我們可以直觀地看到計(jì)算圖模型的一個(gè)相當(dāng)簡潔的版本。

圖6 圖片由Justin Francis友情提供
性能表現(xiàn)評估
讓我們看看準(zhǔn)確性和損失標(biāo)量隨時(shí)間變化的情況。
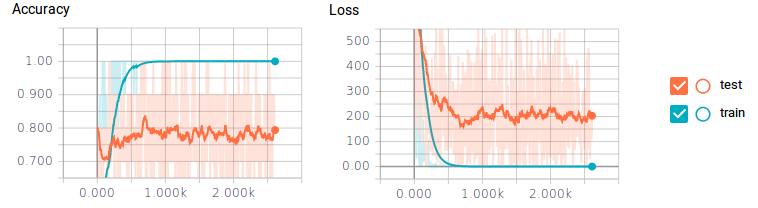
圖7 圖片由Justin Francis友情提供
你可能會(huì)看到這里出了一個(gè)很大的問題。對于訓(xùn)練數(shù)據(jù),分類器達(dá)到了100%的準(zhǔn)確度和0%的誤差損失,但是測試數(shù)據(jù)的準(zhǔn)確度最多只能達(dá)到80%而且還有很大的損失。這就是一個(gè)明顯的過擬合——一些典型的原因包括沒有足夠的訓(xùn)練數(shù)據(jù)或神經(jīng)元數(shù)量太多。
我們可以通過調(diào)整圖片大小、對它們進(jìn)行縮放和旋轉(zhuǎn)來創(chuàng)建更多的訓(xùn)練數(shù)據(jù),但更簡單的方法是將dropout添加到池化層和全連接層的輸出中。這會(huì)在每次訓(xùn)練中隨機(jī)切割或丟棄一個(gè)圖層中的部分神經(jīng)元。這將迫使我們的分類器一次只訓(xùn)練一部分神經(jīng)元,而不是所有神經(jīng)元。這允許神經(jīng)元專注于特定的任務(wù),而不是所有神經(jīng)元一起關(guān)注。丟棄80%的卷積層和50%全連接層的神經(jīng)元會(huì)產(chǎn)生驚人的效果。
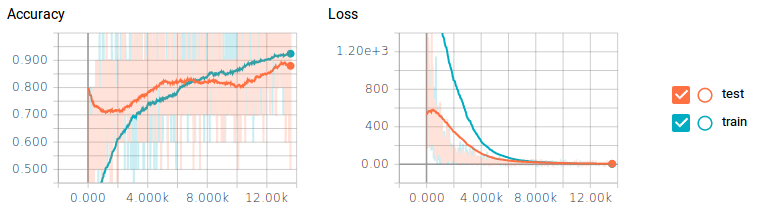
圖8 圖片由Justin Francis友情提供
僅僅通過丟棄神經(jīng)元,測試數(shù)據(jù)的準(zhǔn)確度就幾乎能達(dá)到90%——性能幾乎提高了10%!但代價(jià)是分類器花了大約6倍的時(shí)間才完成訓(xùn)練。
可視化不斷進(jìn)化的濾波器
為了增加樂趣,我讓一個(gè)過濾器每訓(xùn)練50個(gè)步就產(chǎn)生一張圖片,并制作了一個(gè)隨濾波器權(quán)重進(jìn)化的gif圖像。這帶來了非常酷的效果,并能很好地幫助理解卷積網(wǎng)絡(luò)的是如何工作的。以下是來自conv1_2的兩個(gè)濾波器:
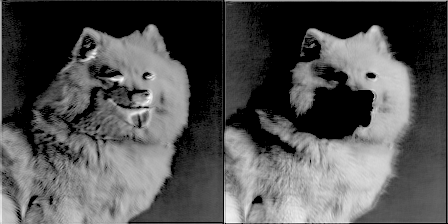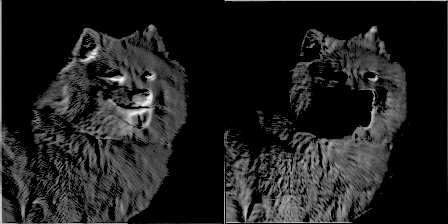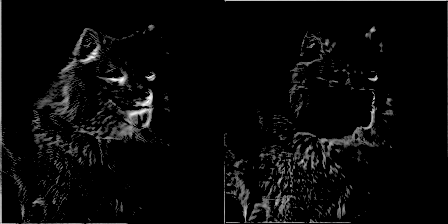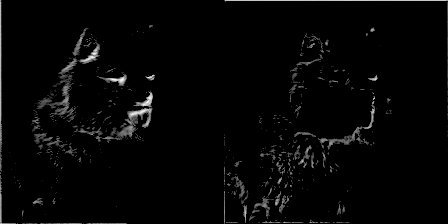
圖9 圖片由Justin Francis友情提供
你可以看到最初的權(quán)重初始化顯示了圖像的大部分,但隨著時(shí)間推移權(quán)重不斷更新,它們變得更加專注于檢測某些邊緣。令我驚訝的是,我發(fā)現(xiàn)第一個(gè)卷積核心filter1_1幾乎沒有改變。似乎初始權(quán)重本身已經(jīng)足夠好了。繼續(xù)深入到網(wǎng)絡(luò)層conv2_2,你可以看到它開始檢測更抽象的廣義特征。

圖10 圖片由Justin Francis友情提供
總而言之,使用了不到400個(gè)訓(xùn)練圖像訓(xùn)練了一個(gè)幾乎可以達(dá)到90%準(zhǔn)確率的模型,這給我留下了深刻的印象。我相信如果有更多的訓(xùn)練數(shù)據(jù)和進(jìn)行更多的超參數(shù)調(diào)整,我可以取得更好的結(jié)果。
行文到此,我們介紹了如何使用TensorFlow從零開始創(chuàng)建卷積神經(jīng)網(wǎng)絡(luò)、如何從TensorBoard中得出推論以及如何可視化濾波器。重要的是記住使用少量數(shù)據(jù)來訓(xùn)練分類器時(shí),更容易的方法是選取一個(gè)已經(jīng)使用多個(gè)GPU在大型數(shù)據(jù)集上訓(xùn)練好的模型和權(quán)重(如GoogLeNet或VGG16),并截?cái)嘧詈笠粚佑米约旱念悇e替換它們。然后所有分類器要做的就是學(xué)習(xí)最后一層的權(quán)重,并使用已存在的訓(xùn)練好的濾波器權(quán)重。所以,我希望你從這篇文章中獲得一些東西,然后繼續(xù)探索,從中得到樂趣,不斷實(shí)驗(yàn)學(xué)習(xí),再秀一些酷的東西!
Justin Francis
Justin居住在加拿大西海岸的一個(gè)小農(nóng)場。這個(gè)農(nóng)場專注于樸門道德和設(shè)計(jì)的農(nóng)藝。在此之前,他是一個(gè)非營利性社區(qū)合作社自行車商店的創(chuàng)始人和教育者。在過去的兩年中,他住在一艘帆船上,全職探索和體驗(yàn)加拿大的喬治亞海峽。但現(xiàn)在他的主要精力都放在了學(xué)習(xí)機(jī)器學(xué)習(xí)上。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4682.html
摘要:深度學(xué)習(xí)在過去的幾年里取得了許多驚人的成果,均與息息相關(guān)。機(jī)器學(xué)習(xí)進(jìn)階筆記之一安裝與入門是基于進(jìn)行研發(fā)的第二代人工智能學(xué)習(xí)系統(tǒng),被廣泛用于語音識別或圖像識別等多項(xiàng)機(jī)器深度學(xué)習(xí)領(lǐng)域。零基礎(chǔ)入門深度學(xué)習(xí)長短時(shí)記憶網(wǎng)絡(luò)。 多圖|入門必看:萬字長文帶你輕松了解LSTM全貌 作者 | Edwin Chen編譯 | AI100第一次接觸長短期記憶神經(jīng)網(wǎng)絡(luò)(LSTM)時(shí),我驚呆了。原來,LSTM是神...

閱讀 3026·2021-11-12 10:36
閱讀 4753·2021-09-22 10:57
閱讀 1569·2021-09-22 10:53
閱讀 2657·2019-08-30 15:55
閱讀 3497·2019-08-29 17:00
閱讀 3355·2019-08-29 16:36
閱讀 2470·2019-08-29 13:46
閱讀 1351·2019-08-26 11:45


