資訊專欄INFORMATION COLUMN

摘要:本文討論了多個評估指標,并從多個方面對評估指標進行了實驗評估,包括距離分類器。鑒于定性評估的內在缺陷,恰當的定量評估指標對于的發展和更好模型的設計至關重要。鑒于評估非常有難度,評估評估指標則更加困難。
作者:Qiantong Xu、Gao Huang、Yang Yuan、Chuan Guo、Yu Sun、Felix Wu、Kilian Weinberger
生成對抗網絡的評估目前仍以定性評估和一些可靠性較差的指標為主,這阻礙了問題的細化,并具有誤導性的風險。本文討論了多個 GAN 評估指標,并從多個方面對評估指標進行了實驗評估,包括 Inception Score、Mode Score、Kernel MMD、Wasserstein 距離、Fréchet Inception Distance、1-NN 分類器。實驗得出了綜合性的結論,選出了兩個表現優越的指標,該研究在定量評估、對比、改進 GAN 的方向上邁出了重要的一步。
論文:An empirical study on evaluation metrics of generative adversarial networks

論文鏈接:https://arxiv.org/abs/1806.07755
摘要:評估生成對抗網絡(GAN)本質上非常有挑戰性。本論文重新討論了多個代表性的基于樣本的 GAN 評估指標,并解決了如何評估這些評估指標的問題。我們首先從一些使指標生成有意義得分的必要條件開始,比如區分真實對象和生成樣本,識別模式丟棄(mode dropping)和模式崩塌(mode collapsing),檢測過擬合。經過一系列精心設計的實驗,我們對現有的基于樣本的指標進行了綜合研究,并找出它們在實踐中的優缺點。基于這些結果,我們觀察到,核較大均值差異(Kernel MMD)和 1-最近鄰(1-NN)雙樣本檢驗似乎能夠滿足大部分所需特性,其中樣本之間的距離可以在合適的特征空間中計算。實驗結果還揭示了多個常用 GAN 模型行為的有趣特性,如它們是否記住訓練樣本、它們離學到目標分布還有多遠。
1 引言
生成對抗網絡(GAN)(Goodfellow et al., 2014)近年來得到了廣泛研究。除了生成驚人相似的圖像(Radford et al., 2015; Larsen et al., 2015; Karras et al., 2017; Arjovsky et al., 2017; Gulrajani et al., 2017),GAN 還創新性地應用于半監督學習(Odena, 2016; Makhzani et al., 2015)、圖像到圖像轉換(Isola et al., 2016; Zhu et al., 2017)和模擬圖像細化(Shrivastava et al., 2016)等領域中。然而,盡管可用的 GAN 模型非常多(Arjovsky et al., 2017; Qi, 2017; Zhao et al., 2016),但對它們的評估仍然主要是定性評估,通常需要借助人工檢驗生成圖像的視覺保真度來進行。此類評估非常耗時,且主觀性較強、具備一定誤導性。鑒于定性評估的內在缺陷,恰當的定量評估指標對于 GAN 的發展和更好模型的設計至關重要。
或許最流行的指標是 Inception Score(Salimans et al., 2016),它使用外部模型即谷歌 Inception 網絡(Szegedy et al., 2014)評估生成圖像的質量和多樣性,該模型在大規模 ImageNet 數據集上訓練。一些其他指標雖然應用沒有那么廣泛,但仍然非常有價值。Wu et al. (2016) 提出一種采樣方法來評估 GAN 模型的對數似然,該方法假設高斯觀測模型具備固定的方差。Bounliphone et al. (2015) 提出使用較大均值差異(MMD)進行 GAN 模型選擇。Lopez-Paz & Oquab (2016) 使用分類器雙樣本檢驗方法(一種統計學中得到充分研究的工具),來評估生成分布和目標分布之間的差異。
盡管這些評估指標在不同任務上有效,但目前尚不清楚它們的分數在哪些場景中是有意義的,在哪些場景中可能造成誤判。鑒于評估 GAN 非常有難度,評估評估指標則更加困難。大部分已有研究嘗試通過展示這些評估指標和人類評估之間的關聯性來證明它們的正當性。但是,人類評估有可能偏向生成樣本的視覺質量,忽視整體分布特征,而后者對于無監督學習來說非常重要。
這篇論文綜合回顧了有關基于樣本的 GAN 定量評估方法的文獻。我們通過精心設計的一系列實驗解決了評估評估指標的難題,我們希望借此回答以下問題:(1)目前基于樣本的 GAN 評估指標的行為合理特征是什么?(2)這些指標的優缺點有哪些,以及基于此我們應該優先選擇哪些指標?實驗觀察表明 MMD 和 1-NN 雙樣本檢驗是最合適的評估指標,它們能夠區分真實圖像和生成圖像,對模式丟棄和崩塌較為敏感,且節約算力。
最后,我們希望這篇論文能夠對在實踐環境中選擇、解釋和設計 GAN 評估指標構建合適的原則。所有實驗和已檢驗指標的源代碼均已公開,向社區提供現成工具來 debug 和改進他們的 GAN 算法。
源代碼地址:https://github.com/xuqiantong/GAN-Metrics

圖 1:基于樣本的典型 GAN 評估方法。
2.2 基于樣本的距離度量
我們主要關注于基于樣本的評估度量,這些度量方法都遵循圖 1 所示的一般設定。度量計算子是 GAN 中的關鍵因素,本論文簡要介紹了 5 種表征方法:Inception 分數(Salimans et al., 2016)、Mode 分數(Che et al., 2016)、Kernel MMD(Gretton et al., 2007)、Wasserstein 距離、Fréchet Inception 距離(FID,Heusel et al., 2017)與基于 1-最近鄰(1-NN)的雙樣本測試(Lopez-Paz & Oquab, 2016)。所有這些度量方法都不需要知道特定的模型,它只要求從生成器中獲取有限的樣本就能逼近真實距離。
Inception 分數可以說是文獻中采用最多的度量方法。它使用一個圖像分類模型 M 和在 ImageNet(Deng et al., 2009)上預訓練的 Inception 網絡(Szegedy et al., 2016),因而計算:
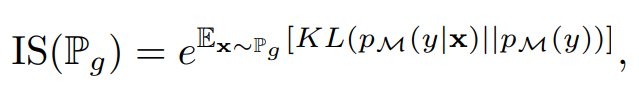
其中 p_M(y|x) 表示由模型 M 在給定樣本 x 下預測的標簽分布,
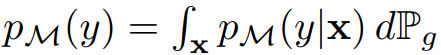
即邊緣分布 p_M(y|x) 在概率度量 P_g 上的積分。p_M(y|x) 上的期望和積分都可以通過從 P_g 中采樣的獨立同分布(i.i.d.)逼近。更高的 IS 表示 p_M(y|x) 接近于點密度,這只有在當 Inception 網絡非常確信圖像屬于某個特定的 ImageNet 類別時才會出現,且 p_M(y) 接近于均勻分布,即所有類別都能等價地表征。這表明生成模型既能生成高質量也能生成多樣性的圖像。Salimans et al. (2016) 表示 Inception 分數與人類對圖像質量的判斷有相關性。作者強調了 Inception 分數兩個具體的屬性:1)KL 散度兩邊的分布都依賴于 M;2)真實數據分布 P_r 甚至是其樣本的分布并不需要使用。
Mode 分數是 Inception 分數的改進版。正式地,它可以通過下式求出:

其中
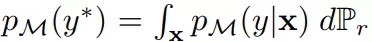
為在給定真實樣本下邊緣標注分布在真實數據分布上的積分。與 Inception 分數不同,它能通過 KL(p_M(y) || p_M(y*))散度度量真實分布 P_r 與生成分布 P_g 之間的差異。
Kernel MMD(核較大均值差異)可以定義為:

在給定一些固定的和函數 k 下,它度量了真實分布 P_r 與生成分布 P_g 之間的差異。給定分別從 P_r 與 P_g 中采樣的兩組樣本,兩個分布間的經驗性 MMD 可以通過有限樣本的期望逼近計算。較低的 MMD 表示 P_g 更接近與 P_r。Parzen window estimate (Gretton et al., 2007) 可以被視為 Kernel MMD 的特例。
P_r 與 P_g 分布之間的 Wasserstein 距離(推土機距離)可以定義為:
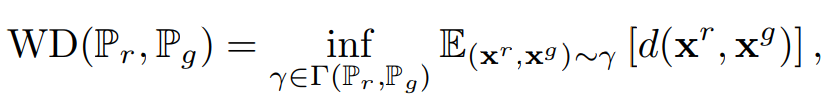
其中 Γ(Pr, Pg) 表示邊緣分布分別為 Pr 與 Pg 的所有聯合分布(即概率耦合)集合,且 d(x^r, x^g) 表示兩個樣本之間的基礎距離。對于密度為 pr 與 pg 的離散分布,Wasserstein 距離通常也被稱為推土機距離(EMD),它等價于解最優傳輸問題:

該式表示實踐中 WD(P_r, P_g) 的有限樣本逼近。與 MMD 相似,Wasserstein 距離越小,兩個分布就越相似。
Fréchet Inception 距離(FID)是最近由 Heusel et al. (2017) 引入并用來評估 GAN 的度量方法。對于適當的特征函數φ(默認為 Inception 網絡的卷積特征),FID 將 φ(P_r) 和 φ(P_g) 建模為高斯隨機變量,且其樣本均值為 μ_r 與 μ_g、樣本協方差為 C_r 與 C_g。兩個高斯分布的 Fréchet 距離(或等價于 Wasserstein-2 距離)可通過下式計算:
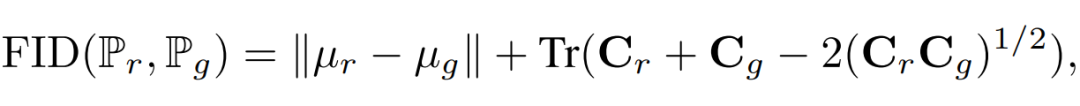
1-最近鄰分類器用于成對樣本檢驗以評估兩個分布是否相同。給定兩組樣本
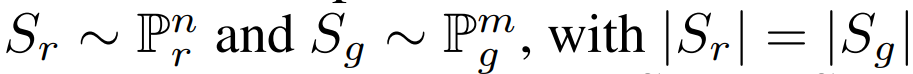
,我們可以計算在 S_r 和 S_g 上進行訓練的 1-NN 分類器的留一(LOO)準確率,其中 S_r 全部標注為正樣本、S_g 全部標注為負樣本。與常用的準確率不同,但|S_r|=|S_g|都非常大時,1-NN 分類器應該服從約為 50% 的 LOO 準確率,這在兩個分布相匹配時能夠達到。當 GAN 的生成分布過擬合真實采樣分布 Sr 時,LOO 準確度將低于 50%。在理論上的極端案例中,如果 GAN 記憶住 Sr 中的每一個樣本,并較精確地重新生成它,即在 S_g=S_r 時,準確率將為零。因為 Sr 中的每一個樣本都將有一個來自 S_g 的最近鄰樣本,它們之間的距離為零。1-NN 分類器成對樣本檢驗族,理論上任意二元分類器都能采用這種方法。我們只考慮 1-NN 分類器,因為它不需要特殊的訓練并只需要少量超參數調整。
Lopez-Paz & Oquab (2016) 認為 1-NN 準確率主要作為成對樣本檢驗的統計量。實際上,將其分為兩個類別來獨立地分析能獲得更多的信息。例如典型的 GAN 生成結果,由于 mode collapse 現象,真實和生成圖像的主要最近鄰都是生成圖像。在這種情況下,真實圖像 LOO 1-NN 準確率可能會相對較低(期望):真實分布的模式通常可由生成模型捕捉,所以 Sr 中的大多數真實樣本周圍都充滿著由 Sg 生成的樣本,這就導致了較低的 LOO 準確率;而生成圖像的 LOO 準確度非常高(不期望的):生成樣本傾向于聚集到少量的模式中心,而這些模式由相同類別的生成樣本包圍,因此會產生較高的 LOO 準確率。
3 GAN 評估指標實驗
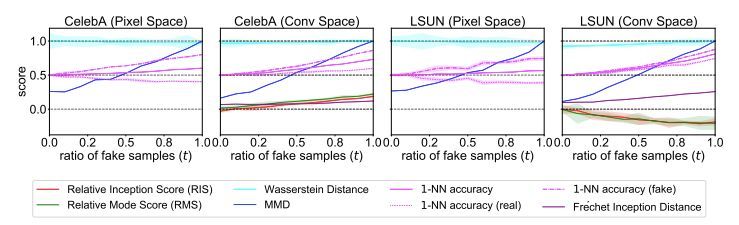
圖 2:從真實圖像和 GAN 生成圖像的混合集合中區分出真實圖像。對于有判別力的指標,其分數應該隨著混合集合中 GAN 生成樣本數量增加而增加。RIS 和 RMS 失敗了,因為在 LSUN 上它們的分數隨著 S_g 中的 GAN 生成樣本數量增加而減少。在像素空間中 Wasserstein 和 1-NN accuracy (real) 也失敗了,因為它們的分數沒有增加反而下降了。

圖 3:模擬模式崩塌實驗。指標分數應該增加,以反映隨著更多模式向聚類中心崩塌真實分布和生成分布之間的不匹配。所有指標在卷積空間中都作出了正確的響應。而在像素空間中,Wasserstein distance 和 1-NN accuracy (real) 失敗了,因為它們的分數沒有增加反而下降了。
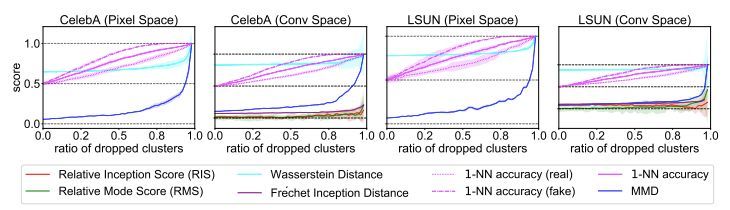
圖 4:模擬模式丟棄實驗。指標分數應該增加,以反映隨著更多模式丟棄真實分布和生成分布之間的不匹配。所有指標(除了 RIS 和 RMS)都作出了正確的響應,因為在幾乎所有模式都丟棄時它們仍然有輕微的上升。

圖 5:關于每個指標對小量變換(旋轉和平移)的魯棒性的實驗。所有指標應該對真實圖像和變換后的真實樣本保持不變,因為變換不會改變圖像語義。所有指標都在卷積空間中作出了正確的響應,但不是像素空間。該實驗證明像素空間中距離的不適應性。
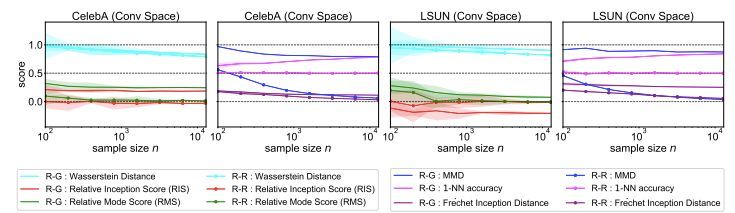
圖 6:不同指標在樣本數作為 x 軸的函數上的分數。完美指標應該帶來 real-real
和 real-fake
曲線之間的巨大差距,以利用盡可能少的樣本區分真實分布和偽分布。與 Wasserstein 距離相比,MMD 和 1-NN accuracy 判別真實圖像和生成圖像所需的樣本量更少,而 RIS 在 LSUN 上完全失敗,因為其在生成圖像上的分數甚至優于(低于)真實圖像。

圖 8:檢測生成樣本過擬合的實驗。隨著更多的生成樣本與訓練集中的真實樣本重疊,驗證得分和訓練得分之間的差距應該增加至信號過擬合(signal overfitting)。所有指標的行為都是正確的,除了 RIS 和 RMS,因為這兩個的分數不會隨著重疊樣本數量的增加而增加。
4 討論和結論
基于以上分析,我們可以總結這六個評估指標的優勢和本質缺陷,以及它們在什么條件下可以生成有意義的結果。使用部分指標,我們能夠研究過擬合問題(詳見 Appendix C)、在 GAN 模型上執行模型選擇,并基于精心挑選的樣本對比不同模型(詳見 Appendix D),無需使用人類評估。
Inception Score 展示出生成圖像的質量和多樣性之間的合理關聯,這解釋了其在實踐中廣泛應用的原因。但是,它在大部分情況下并不合適,因為它僅評估 P_g(作為圖像生成模型),而不是評估其與 P_r 的相似度。一些簡單的擾動(如混入來自完全不同分布的自然圖像)能夠徹底欺騙 Inception Score。因此,它可能會鼓勵模型只學習清晰和多樣化圖像(甚至一些對抗噪聲),而不是 P_r。這也適用于 Mode Score。此外,Inception Score 無法檢測過擬合,因為它無法使用留出驗證集。
Kernel MMD 在預訓練 ResNet 的特征空間中運行時,性能驚人地好。它總是能夠識別生成/噪聲圖像和真實圖像,且它的樣本復雜度和計算復雜度都比較低。鑒于這些優勢,即使 MMD 是有偏的,但我們仍推薦大家在實踐中使用它。
當距離在合適的特征空間中進行計算時,Wasserstein 距離的性能很好。但是,它的樣本復雜度很高,Arora 等人 2017 年也發現了這一事實。另一個主要缺陷是計算 Wasserstein 距離所需的實踐復雜度為 O(n^3),且隨著樣本數量的增加而更高。與其他方法相比,Wasserstein 距離在實踐中作為評估指標的吸引力較差。
Fréchet Inception Distance 在判別力、魯棒性和效率方面都表現良好。它是 GAN 的優秀評估指標,盡管它只能建模特征空間中分布的前兩個 moment。
1-NN 分類器幾乎是評估 GAN 的完美指標。它不僅具備其他指標的所有優勢,其輸出分數還在 [0, 1] 區間中,類似于分類問題中的準確率/誤差。當生成分布與真實分布完美匹配時,該指標可獲取完美分數(即 50% 的準確率)。從圖 2 中可以看到典型 GAN 模型對真實樣本(1-NN accuracy (real))的 LOO 準確率較低,而對生成樣本(1-NN accuracy (fake))的 LOO 準確率較高。這表明 GAN 能夠從訓練分布中捕捉模型,這樣分布在模式中心周圍的大部分訓練樣本的最近鄰來自于生成圖像集合,而大部分生成圖像的周圍仍然是生成圖像,因為它們一起崩塌。該觀測結果表明模式崩塌問題在典型 GAN 模型中很普遍。但是,我們還注意到這個問題無法通過人類評估或廣泛使用的 Inception Score 評估指標來有效檢測到。
總之,我們的實證研究表明選擇計算不同指標的特征空間至關重要。在 ImageNet 上預訓練 ResNet 的卷積空間中,MMD 和 1-NN accuracy 在判別力、魯棒性和效率方面都是優秀的指標。Wasserstein 距離的樣本效率較差,而 Inception Score 和 Mode Score 不適合與 ImageNet 差異較大的數據集。我們將發布所有這些指標的源代碼,向研究者提供現成的工具來對比和改進 GAN 算法。
基于這兩個主要指標 MMD 和 1-NN accuracy,我們研究了 DCGAN 和 WGAN(詳見 Appendix C)的過擬合問題。盡管人們廣泛認為 GAN 對訓練數據過擬合,但我們發現這只在訓練樣本很少的情況下才會發生。這提出了一個關于 GAN 泛化能力的有趣問題。我們希望未來的研究能夠幫助解釋這一現象。
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4788.html
摘要:在這項工作中,我們提出了自注意力生成對抗網絡,它將自注意力機制引入到卷積中。越高,表示圖像質量越好。表將所提出的與較先進模型進行比較,任務是上的類別條件圖像生成。 圖像合成(Image synthesis)是計算機視覺中的一個重要問題。隨著生成對抗網絡(GAN)的出現,這個方向取得了顯著進展。基于深度卷積網絡的GAN尤其成功。但是,通過仔細檢查這些模型生成的樣本,可以觀察到,在ImageNe...
摘要:例如,即插即用生成網絡通過優化結合了自動編碼器損失,損失,和通過與訓練的分類器定于的分類損失的目標函數,得到了較高水平的樣本。該論文中,作者提出了結合的原則性方法。 在機器學習研究領域,生成式對抗網絡(GAN)在學習生成模型方面占據著統治性的地位,在使用圖像數據進行訓練的時候,GAN能夠生成視覺上以假亂真的圖像樣本。但是這種靈活的算法也伴隨著優化的不穩定性,導致模式崩潰(mode colla...
摘要:的兩位研究者近日融合了兩種非對抗方法的優勢,并提出了一種名為的新方法。的缺陷讓研究者開始探索用非對抗式方案來訓練生成模型,和就是兩種這類方法。不幸的是,目前仍然在圖像生成方面顯著優于這些替代方法。 生成對抗網絡(GAN)在圖像生成方面已經得到了廣泛的應用,目前基本上是 GAN 一家獨大,其它如 VAE 和流模型等在應用上都有一些差距。盡管 wasserstein 距離極大地提升了 GAN 的...
摘要:近日,谷歌大腦發布了一篇全面梳理的論文,該研究從損失函數對抗架構正則化歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。他們首先定義了全景圖損失函數歸一化和正則化方案,以及最常用架構的集合。 近日,谷歌大腦發布了一篇全面梳理 GAN 的論文,該研究從損失函數、對抗架構、正則化、歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。作者們復現了當前較佳的模型并公平地對比與探索 GAN ...
摘要:是世界上最重要的研究者之一,他在谷歌大腦的競爭對手,由和創立工作過不長的一段時間,今年月重返,建立了一個探索生成模型的新研究團隊。機器學習系統可以在這些假的而非真實的醫療記錄進行訓練。今年月在推特上表示是的,我在月底離開,并回到谷歌大腦。 理查德·費曼去世后,他教室的黑板上留下這樣一句話:我不能創造的東西,我就不理解。(What I cannot create, I do not under...

閱讀 2451·2021-10-13 09:40
閱讀 3338·2019-08-30 13:46
閱讀 1125·2019-08-29 14:05
閱讀 2961·2019-08-29 12:48
閱讀 3657·2019-08-26 13:28
閱讀 2148·2019-08-26 11:34
閱讀 2284·2019-08-23 18:11
閱讀 1163·2019-08-23 12:26






