資訊專欄INFORMATION COLUMN

摘要:一個簡單的解釋是,在論文和論文中,恒等映射的輸出被添加到下一個模塊,如果兩個層的特征映射有著非常不同的分布,那么這可能會阻礙信息流。
在 AlexNet [1] 取得 LSVRC 2012 分類競賽冠軍之后,深度殘差網絡(Residual Network, 下文簡寫為 ResNet)[2] 可以說是過去幾年中計算機視覺和深度學習領域最具開創性的工作。ResNet 使訓練數百甚至數千層成為可能,且在這種情況下仍能展現出優越的性能。
因其強大的表征能力,除圖像分類以外,包括目標檢測和人臉識別在內的許多計算機視覺應用都得到了性能提升。
自從 2015 年 ResNet 讓人們刮目相看,研究界的許多人在深入探索所其成功的秘密,許多文獻中對該模型做了一些改進。本文分為兩部分,第一部分為不熟悉 ResNet 的人提供一些背景知識,第二部分將介紹我最近閱讀的一些論文,關于 ResNet 的不同變體和對 ResNet 架構的理解。
重新審視 ResNet
根據泛逼近定理(universal approximation theorem),只要給定足夠的容量,單層的前饋網絡也足以表示任何函數。但是,該層可能非常龐大,網絡和數據易出現過擬合。因此,研究界普遍認為網絡架構需要更多層。
自 AlexNet 以來,較先進的 CNN 架構已經越來越深。AlexNet 只有 5 個卷積層,而之后的 VGG 網絡 [3] 和 GoogleNet(代號 Inception_v1)[4] 分別有 19 層和 22 層。
但是,網絡的深度提升不能通過層與層的簡單堆疊來實現。由于臭名昭著的梯度消失問題,深層網絡很難訓練。因為梯度反向傳播到前面的層,重復相乘可能使梯度無窮小。結果就是,隨著網絡的層數更深,其性能趨于飽和,甚至開始迅速下降。
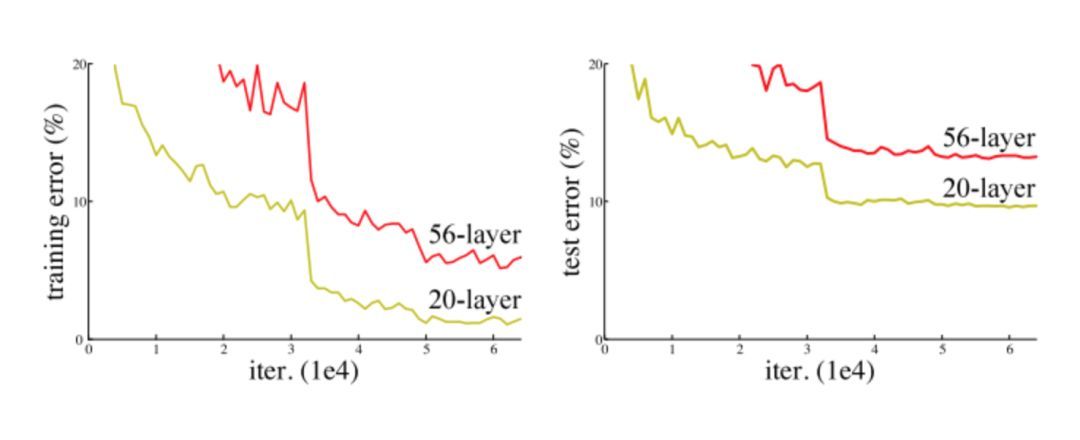
增加網絡深度導致性能下降
在 ResNet 出現之前有幾種方法來應對梯度消失問題,例如 [4] 在中間層添加了一個輔助損失作為額外的監督,但其中沒有一種方法真正解決了這個問題。
ResNet 的核心思想是引入一個所謂的「恒等快捷連接」(identity shortcut connection),直接跳過一個或多個層,如下圖所示:
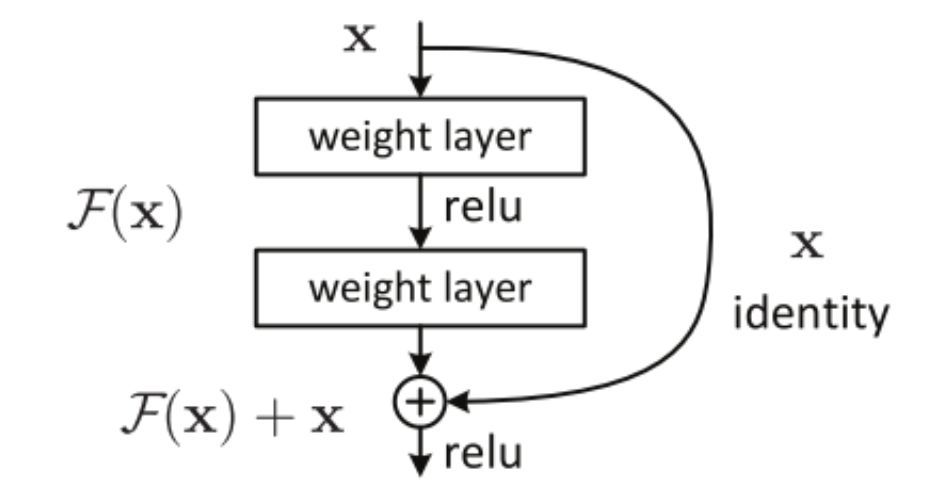
殘差塊
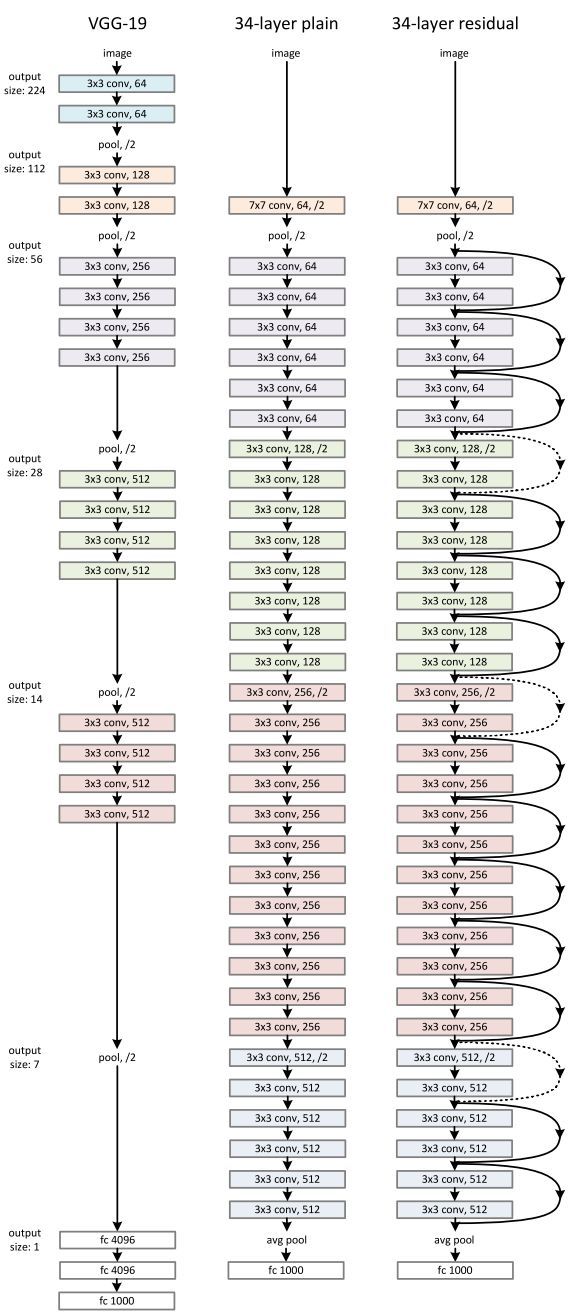
ResNet 架構
[2] 的作者認為,堆疊層不應降低網絡性能,因為我們可以簡單地在當前網絡上堆疊恒等映射(該層不做任何事情),得到的架構將執行相同的操作。這表明較深的模型所產生的訓練誤差不應該比較淺的模型高。他們假設讓堆疊層適應殘差映射比使它們直接適應所需的底層映射要容易一些。上圖中的殘差塊明確表明,它可以做到這一點。
事實上,ResNet 并不是第一個利用快捷連接的模型,Highway Networks [5] 就引入了門控快捷連接。這些參數化的門控制流經捷徑(shortcut)的信息量。類似的想法可以在長短期記憶網絡(LSTM)[6] 單元中找到,它使用參數化的遺忘門控制流向下一個時間步的信息量。ResNet 可以被認為是 Highway Network 的一種特殊情況。
然而,實驗結果表明 Highway Network 的性能并不比 ResNet 好,這有點奇怪。Highway Network 的解空間包含 ResNet,因此它的性能至少應該和 ResNet 一樣好。這表明,保持這些「梯度高速路」(gradient highway)的暢通比獲取更大的解空間更為重要。
按照這種思路,[2] 的作者改進了殘差塊,并提出了一種殘差塊的預激活變體 [7],梯度可以在該模型中暢通無阻地通過快速連接到達之前的任意一層。事實上,使用 [2] 中的原始殘差塊訓練一個 1202 層的 ResNet,其性能比 110 層的模型要差。
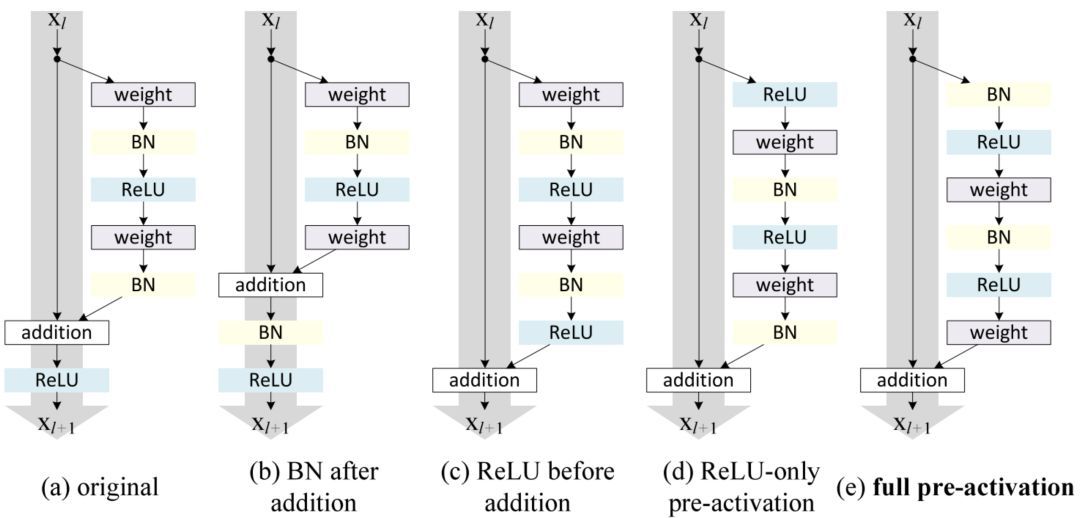
殘差塊的變體
[7] 的作者在其論文中通過實驗表明,他們可以訓練出 1001 層的深度 ResNet,且性能超越較淺層的模型。他們的訓練成果卓有成效,因而 ResNet 迅速成為多種計算機視覺任務中最流行的網絡架構之一。
ResNet 的變體以及解讀
隨著 ResNet 在研究界的不斷普及,關于其架構的研究也在不斷深入。本節首先介紹幾種基于 ResNet 的新架構,然后介紹一篇論文,從 ResNet 作為小型網絡集合的角度進行解讀。
ResNeXt
Xie et al. [8] 提出 ResNet 的一種變體 ResNeXt,它具備以下構建塊:
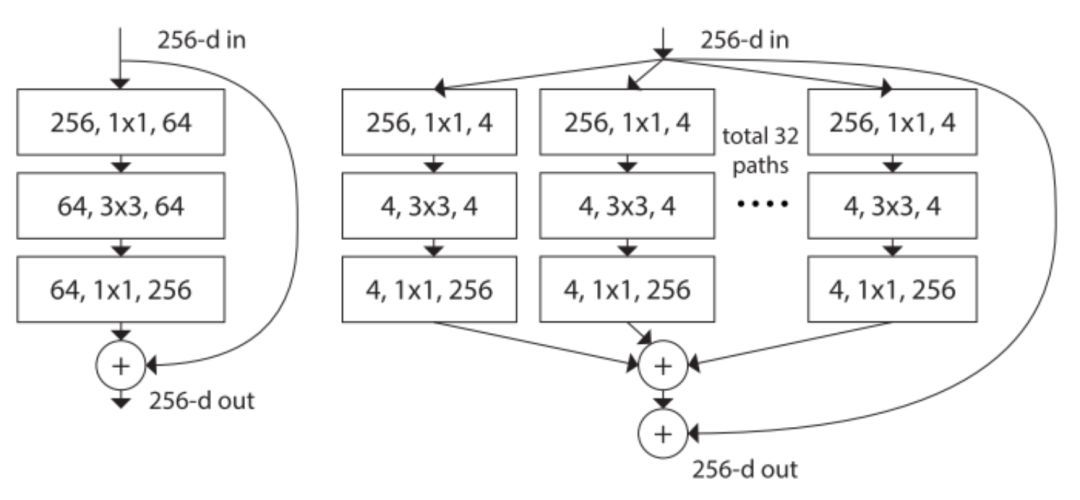
左:[2] 中 ResNet 的構建塊;右:ResNeXt 的構建塊,基數=32
ResNext 看起來和 [4] 中的 Inception 模塊非常相似,它們都遵循了「分割-轉換-合并」的范式。不過在 ResNext 中,不同路徑的輸出通過相加合并,而在 [4] 中它們是深度級聯(depth concatenated)的。另外一個區別是,[4] 中的每一個路徑互不相同(1x1、3x3 和 5x5 卷積),而在 ResNeXt 架構中,所有的路徑都遵循相同的拓撲結構。
作者在論文中引入了一個叫作「基數」(cardinality)的超參數,指獨立路徑的數量,這提供了一種調整模型容量的新思路。實驗表明,通過擴大基數值(而不是深度或寬度),準確率得到了高效提升。作者表示,與 Inception 相比,這個全新的架構更容易適應新的數據集或任務,因為它只有一個簡單的范式和一個需要調整的超參數,而 Inception 需要調整很多超參數(比如每個路徑的卷積層內核大小)。
這個全新的結構有三種等價形式:
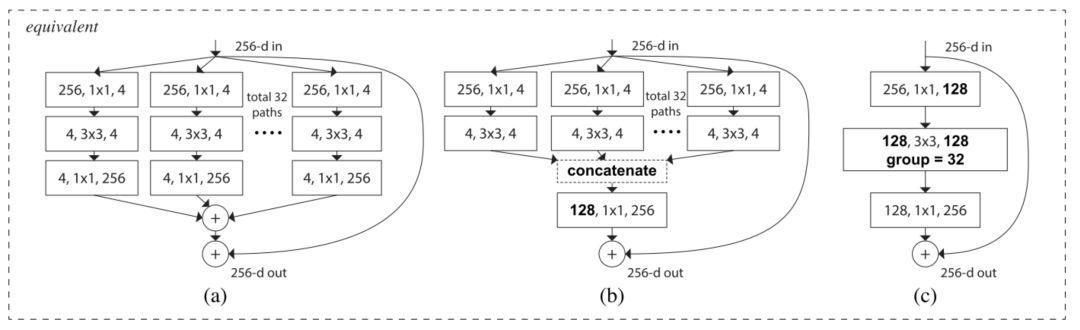
在實際操作中,「分割-變換-合并」范式通常通過「逐點分組卷積層」來完成,這個卷積層將輸入的特征映射分成幾組,并分別執行正常的卷積操作,其輸出被深度級聯,然后饋送到一個 1x1 卷積層中。
密集連接卷積神經網絡
Huang 等人在論文 [9] 中提出一種新架構 DenseNet,進一步利用快捷連接,將所有層直接連接在一起。在這種新型架構中,每層的輸入由所有之前層的特征映射組成,其輸出將傳輸給每個后續層。這些特征映射通過深度級聯聚合。
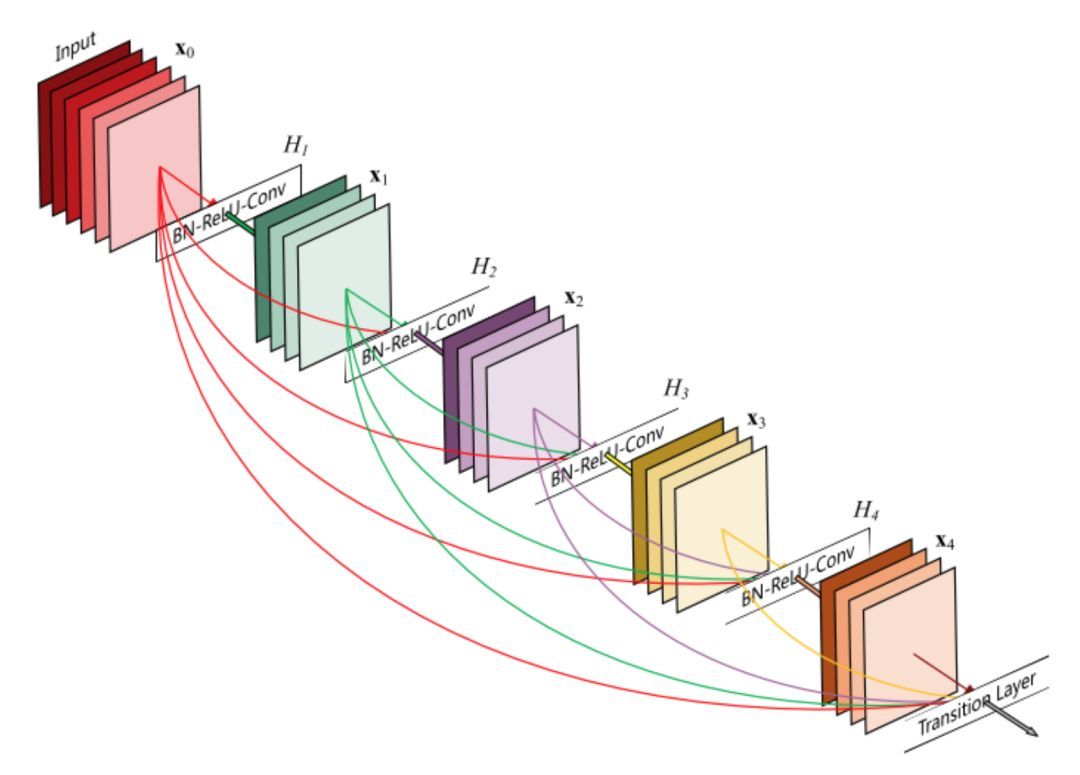
除了解決梯度消失問題,[8] 的作者稱這個架構還支持特征重用,使得網絡具備更高的參數效率。一個簡單的解釋是,在論文 [2] 和論文 [7] 中,恒等映射的輸出被添加到下一個模塊,如果兩個層的特征映射有著非常不同的分布,那么這可能會阻礙信息流。因此,級聯特征映射可以保留所有特征映射并增加輸出的方差,從而促進特征重用。

遵循該范式,我們知道第 l 層將具有 k *(l-1)+ k_0 個輸入特征映射,其中 k_0 是輸入圖像的通道數目。作者使用一個叫作「增長率」的超參數 (k) 防止網絡過寬,他們還用了一個 1*1 的卷積瓶頸層,在昂貴的 3*3 卷積前減少特征映射的數量。整體架構如下表所示:
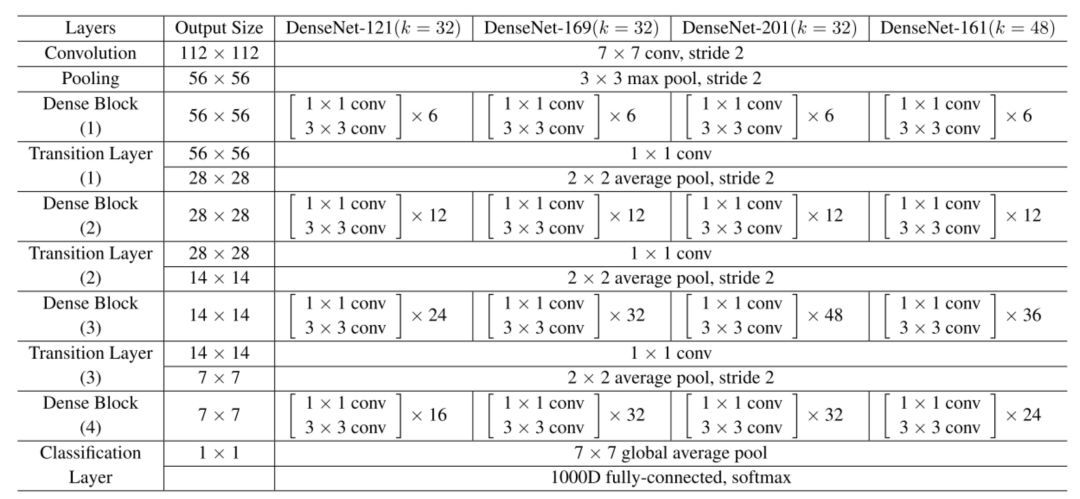
用于 ImageNet 的 DenseNet 架構
深度隨機的深度網絡
盡管 ResNet 的強大性能在很多應用中已經得到了證實,但它存在一個顯著缺點:深層網絡通常需要進行數周的訓練時間。因此,把它應用在實際場景的成本非常高。為了解決這個問題,G. Huang 等作者在論文 [10] 中引入了一種反直覺的方法,即在訓練過程中隨機丟棄一些層,測試中使用完整的網絡。
作者使用殘差塊作為他們網絡的構建塊。因此在訓練期間,當特定的殘差塊被啟用,它的輸入就會同時流經恒等快捷連接和權重層;否則,就只流過恒等快捷連接。訓練時,每層都有一個「生存概率」,每層都有可能被隨機丟棄。在測試時間內,所有的塊都保持被激活狀態,并根據其生存概率進行重新校準。
從形式上來看,H_l 是第 l 個殘差塊的輸出結果,f_l 是由第 l 個殘差塊的加權映射所決定的映射,b_l 是一個伯努利隨機變量(用 1 或 0 反映該塊是否被激活)。在訓練中:
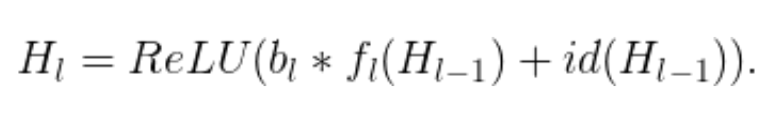
當 b_l=1 時,該塊為正常的殘差塊;當 b_l=0 時,上述公式為:
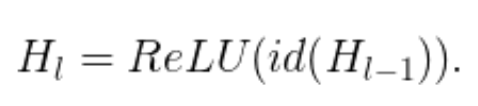
既然我們已經知道了 H_(l-1) 是 ReLU 的輸出,而且這個輸出結果已經是非負的,所以上述方程可簡化為將輸入傳遞到下一層的 identity 層:

令 p_l 表示是第 l 層在訓練中的生存概率,在測試過程中,我們得到:
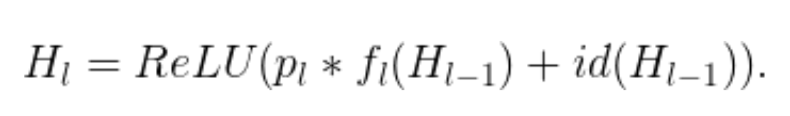
作者將線性衰減規律應用于每一層的生存概率,他們表示,由于較早的層提取的低級特征會被后面的層使用,所以不應頻繁丟棄較早的層。這樣,規則就變成:
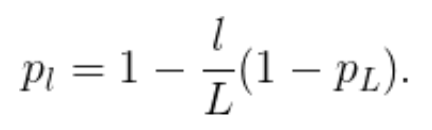
其中 L 表示塊的總數,因此 p_L 就是最后一個殘差塊的生存概率,在整個實驗中 p_L 恒為 0.5。請注意,在該設置中,輸入被視為第一層 (l=0),所以第一層永遠不會被丟棄。隨機深度訓練的整體框架如下圖所示:
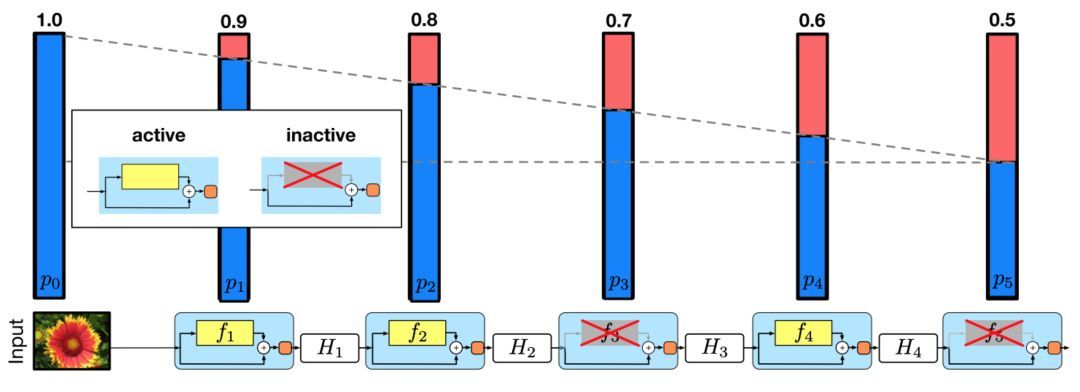
訓練過程中,每一層都有一個生存概率
與 Dropout [11] 類似,訓練隨機深度的深度網絡可被視為訓練許多較小 ResNet 的集合。不同之處在于,上述方法隨機丟棄一個層,而 Dropout 在訓練中只丟棄一層中的部分隱藏單元。
實驗表明,同樣是訓練一個 110 層的 ResNet,隨機深度訓練出的網絡比固定深度的性能要好,同時大大減少了訓練時間。這意味著 ResNet 中的一些層(路徑)可能是冗余的。
作為小型網絡集合的 ResNet
[10] 提出一種反直覺的方法,即在訓練中隨機丟棄網絡層,并在測試中使用完整的網絡。[14] 介紹了一種更加反直覺的方法:我們實際上可以刪除已訓練 ResNet 的部分層,但仍然保持相對不錯的性能。[14] 還用同樣的方式移除 VGG 網絡的部分層,其性能顯著降低,這使得 ResNet 架構更加有趣。
[14] 首先介紹了一個 ResNet 的分解圖來使討論更加清晰。在我們展開網絡架構之后,很明顯發現,一個有著 i 個殘差塊的 ResNet 架構有 2**i 個不同路徑(因為每個殘差塊提供兩個獨立路徑)。
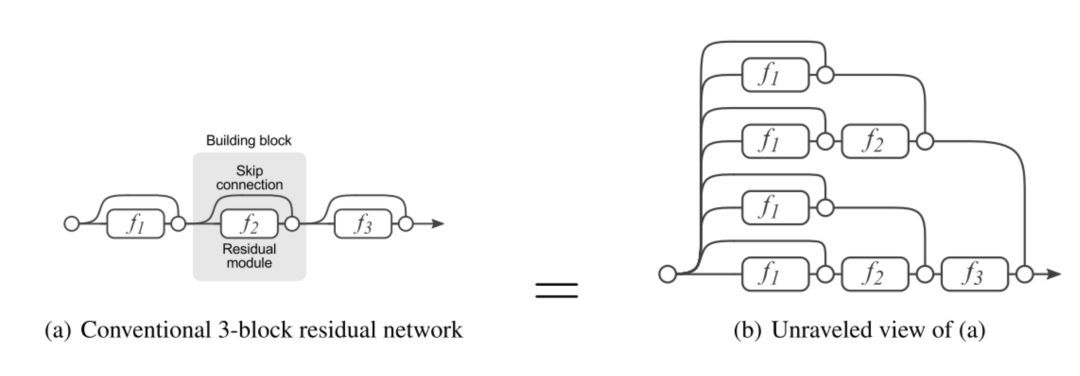
根據上述發現,顯然移除 ResNet 架構中的部分層對其性能影響不大,因為架構具備許多獨立有效的路徑,在移除了部分層之后大部分路徑仍然保持完整無損。相反,VGG 網絡只有一條有效路徑,因此移除一個層會對該層的路徑產生影響。(如 [14] 中的實驗所揭示的。)
作者的另一個實驗表明,ResNet 中不同路徑的集合有類似集成的行為。他們在測試時刪除不同數量的層,測試網絡性能與刪除層的數量是否平滑相關。結果表明,網絡行為確實類似集成,如下圖所示:

當被刪除的層數增加時,誤差值隨之增長
最終,作者研究了 ResNet 中路徑的特征:
很明顯,路徑的可能長度分布遵循二項分布,如下圖 (a) 所示。大多數路徑流經 19 到 35 個殘差塊。
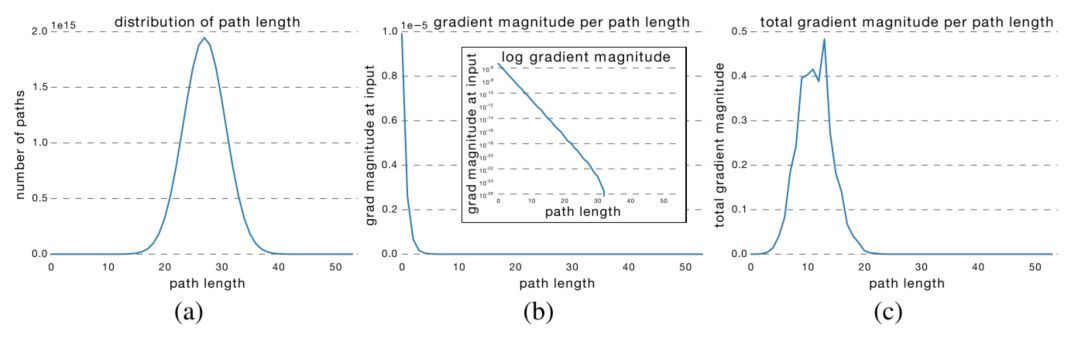
為了研究路徑長度與經過路徑的梯度大小之間的關系,得到長度為 k 的路徑的梯度大小,作者首先向網絡輸入了一批數據,并隨機采樣 k 個殘差塊。當梯度被反向傳播時,它們在采樣殘差塊中僅通過權重層進行傳播。(b) 表明隨著路徑長度的增加,梯度大小迅速下降。
現在將每個路徑長度的頻率與其期望的梯度大小相乘,以了解每個長度的路徑在訓練中起到多大作用,如圖 (c) 所示。令人驚訝的是,大多數貢獻來自于長度為 9 到 18 的路徑,但它們只占所有路徑的一小部分,如 (a) 所示。這是一個非常有趣的發現,它表明 ResNet 并沒有解決長路徑的梯度消失問題,而是通過縮短有效路徑的長度訓練非常深層的 ResNet 網絡。
結論
本文主要介紹了 ResNet 架構,簡要闡述了其近期成功的原因,并介紹了幾篇論文,它們敘述了一些有趣的 ResNet 變體,或提供了富有洞察力的解釋。希望這篇文章有助于大家理解這項開創性的工作。
本文所有的圖表均來自于參考文獻中的原始論文。
References:
[1]. A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems,pages1097–1105,2012.
[2]. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[3]. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556,2014.
[4]. C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 1–9,2015.
[5]. R. Srivastava, K. Greff and J. Schmidhuber. Training Very Deep Networks. arXiv preprint arXiv:1507.06228v2,2015.
[6]. S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, Nov. 1997.
[7]. K. He, X. Zhang, S. Ren, and J. Sun. Identity Mappings in Deep Residual Networks. arXiv preprint arXiv:1603.05027v3,2016.
[8]. S. Xie, R. Girshick, P. Dollar, Z. Tu and K. He. Aggregated Residual Transformations for Deep Neural Networks. arXiv preprint arXiv:1611.05431v1,2016.
[9]. G. Huang, Z. Liu, K. Q. Weinberger and L. Maaten. Densely Connected Convolutional Networks. arXiv:1608.06993v3,2016.
[10]. G. Huang, Y. Sun, Z. Liu, D. Sedra and K. Q. Weinberger. Deep Networks with Stochastic Depth. arXiv:1603.09382v3,2016.
[11]. N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever and R. Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. The Journal of Machine Learning Research 15(1) (2014) 1929–1958.
[12]. A. Veit, M. Wilber and S. Belongie. Residual Networks Behave Like Ensembles of Relatively Shallow Networks. arXiv:1605.06431v2,2016.
原文鏈接:https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4740.html
摘要:通過兩年的發展,今天我們可以肯定地說放棄你的和有證據表明,谷歌,,等企業正在越來越多地使用基于注意力模型的網絡。 摘要: 隨著技術的發展,作者覺得是時候放棄LSTM和RNN了!到底為什么呢?來看看吧~ showImg(https://segmentfault.com/img/bV8ZS0?w=800&h=533); 遞歸神經網絡(RNN),長期短期記憶(LSTM)及其所有變體: 現在是...
摘要:近來在深度學習中,卷積神經網絡和循環神經網絡等深度模型在各種復雜的任務中表現十分優秀。機器學習中最常用的正則化方法是對權重施加范數約束。 近來在深度學習中,卷積神經網絡和循環神經網絡等深度模型在各種復雜的任務中表現十分優秀。例如卷積神經網絡(CNN)這種由生物啟發而誕生的網絡,它基于數學的卷積運算而能檢測大量的圖像特征,因此可用于解決多種圖像視覺應用、目標分類和語音識別等問題。但是,深層網絡...
摘要:大神何愷明受到了質疑。今天,上一位用戶對何愷明的提出質疑,他認為何愷明年的原始殘差網絡的結果沒有被復現,甚至何愷明本人也沒有。我認為,的可復現性經受住了時間的考驗。 大神何愷明受到了質疑。今天,Reddit 上一位用戶對何愷明的ResNet提出質疑,他認為:何愷明 2015 年的原始殘差網絡的結果沒有被復現,甚至何愷明本人也沒有。網友稱,他沒有發現任何一篇論文復現了原始 ResNet 網絡的...
摘要:近日,谷歌大腦發布了一篇全面梳理的論文,該研究從損失函數對抗架構正則化歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。他們首先定義了全景圖損失函數歸一化和正則化方案,以及最常用架構的集合。 近日,谷歌大腦發布了一篇全面梳理 GAN 的論文,該研究從損失函數、對抗架構、正則化、歸一化和度量方法等幾大方向整理生成對抗網絡的特性與變體。作者們復現了當前較佳的模型并公平地對比與探索 GAN ...
摘要:潘新鋼等發現,和的核心區別在于,學習到的是不隨著顏色風格虛擬性現實性等外觀變化而改變的特征,而要保留與內容相關的信息,就要用到。 大把時間、大把GPU喂進去,訓練好了神經網絡。接下來,你可能會迎來傷心一刻:同學,測試數據和訓練數據,色調、亮度不太一樣。同學,你還要去搞定一個新的數據集。是重新搭一個模型呢,還是拿來新數據重新調參,在這個已經訓練好的模型上搞遷移學習呢?香港中文大學-商湯聯合實驗...

閱讀 2621·2021-11-25 09:43
閱讀 2724·2021-11-04 16:09
閱讀 1634·2021-10-12 10:13
閱讀 880·2021-09-29 09:35
閱讀 880·2021-08-03 14:03
閱讀 1777·2019-08-30 15:55
閱讀 2989·2019-08-28 18:14
閱讀 3489·2019-08-26 13:43






