資訊專欄INFORMATION COLUMN

摘要:在機器學習中,設計正確的文件架構并不簡單。當你在進行機器學習項目時,模型通過你使用的框架共享了許多相似之處。因為與機器學習研究交互的主要結束點就是你使用任何工具的外殼,程序外殼是你實驗的基石。
在機器學習中,設計正確的文件架構并不簡單。我自己在幾個項目上糾結過此問題之后,我開始尋找簡單的模式,并希望其能覆蓋大部分在讀代碼或自己編代碼時遇到的使用案例。
在此文章中,我會分享我自己的發現。
聲明:該文章更像是建議,而非明確的指導,但我感覺挺成功的。該文章意在為初學者提供起點,可能會引發一些討論。因為一開始我想要為自己的工作設計文件架構,我想我能分享下這方面的內容。如果你有更好的文件架構理論,可以留言分享。
總需要得到什么?
想下在你做機器學習的時候,你必須要做的是什么?
需要編寫一個模型
該模型(至少)有兩個不同的階段:訓練階段和推論階段(成果)
需要為該模型輸入數據集(訓練階段)
可能也需要為它輸入單個元素(推論階段)
需要調整它的超參數
精調超參數,需要模型是可配置的,并創造一個類似「API」的存在,至少能讓你推動配置的運行
訓練結果需要好的文件夾(folder)架構(以便于瀏覽并輕易的記住每個實驗)
需要用圖表示一些指標,比如損失或準確率(在訓練以及成果階段)
想要這些圖能夠輕易地被搜索到
想要能夠復制所做的任何實驗
甚至在訓練階段希望跳回前面,以檢查模型
在構造文件和文件夾時,很容易就會忘記以上這些。此外,可能還有其他需求我并未列出。下面,讓我們尋找一些較好的實踐。
整體文件夾架構
一圖勝千言:
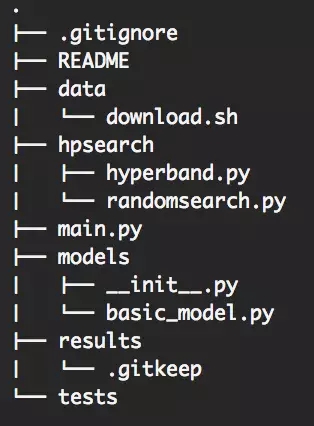
文件架構
README 文件:大部分人可能使用 Github,所以請花費些時間,寫一個至少包含以下選項的好的 markdown:安裝、使用、測試、有用的鏈接,來記錄要直接放進 repository 的大型文件。
main.py 文件:獨特的 endpoint,簡單。下面會有更詳細的介紹。你也可以用兩個文檔做為變形(train.py/infer.py)。但在我看來不必要,它通常用來為每個文件建立兩個 API。
數據文件夾:創造一個文件夾,并放進一個腳本來下載數據集。如果需要,讓腳本很好地適配數據文件夾,例如:如果沒有的話,腳本可以創造 trian/val/test 子文件夾。
模型文件夾:該文件夾用來放模型文件。我認為不只有一種方式可處理這個文件夾,你可以為每個模型或每個模型類別寫個文件,甚至可以有一個子文件夾。只要保持一致就行。
__init__ file:下面我會對該文件介紹更多,但它是一個 python 助手(helper),能讓你更容易找到模型,且簡化了模型文件夾的復雜度。
basic_model.py 文件:下面也會對此有所詳介。我認為 TensorFlow 中的大部分模型能共享一個通用架構,后文我會解釋自己的選擇以及原因。
hysearch 文件夾:該文件夾用來存放任何做自定義超參數搜索的助手。如果你使用函數庫,可能就不需要它,但大多時候你總需要自定義些東西。保持這些功能的純粹與多帶帶性,以便于能簡單地進行測試。
測試文件夾:測試文件夾,當然是用來測試的。你會測試它們,對吧?
結果文件夾:很明顯,該文件夾是用來放結果的。TensorFlow 中更多有關如何提供 TensorBorad 的子文件夾架構的信息,下面很有所介紹。
注釋:請在結果文件夾中添加一個「.gitkeep」文件和為「.gitignore」文件添加一個文件夾。因為你也許不希望將所有試驗都放到 Github 上,并需要避免代碼在首次安裝時因為文件夾丟失而中斷。
這些都是十分基礎的。當然,也許還需要添加其他文件夾,但那些都能歸結到這一基本集中。
通過將良好的 README 和其他 bash 腳本作為輔助。任何人希望使用你的資源庫(repository)都可以通過「Install」命令和「Usage」命令復制你的研究。
基本模型
正如我所說的,我最終意識到模型中的模式是通過 TF 工程化的東西。這一點引領著我我設計了一個非常簡單的類(class),其可以由我未來的模型所擴展。
我并不是繼承類別(class inheritance)的熱衷者,但我也不是永遠清晰復寫一段相同代碼的熱衷者。當你在進行機器學習項目時,模型通過你使用的框架共享了許多相似之處。
所以我試圖找到一個避免繼承的(inheritance)已知香蕉問題(banana problem)的實現,這是通過讓一個繼承盡可能地深而達到。
要完全清楚,我們需要將這一類別作為以后模型的頂部父級類別(top parent),令你模型的構建在一行使用一個變元(one argument):配置(the configuration)。
為了更進一步理解,我們將為你直接展示注釋文件(commented file):
import os, copy
import tensorflow as tf
class BasicAgent(object):
? ? # To build your model, you only to pass a "configuration" which is a dictionary
? ? def __init__(self, config):
? ? ? ? # I like to keep the best HP found so far inside the model itself
? ? ? ? # This is a mechanism to load the best HP and override the configuration
? ? ? ? if config["best"]:
? ? ? ? ? ? config.update(self.get_best_config(config["env_name"]))
? ? ? ? ? ??
? ? ? ? # I make a `deepcopy` of the configuration before using it
? ? ? ? # to avoid any potential mutation when I iterate asynchronously over configurations
? ? ? ? self.config = copy.deepcopy(config)
? ? ? ? if config["debug"]: # This is a personal check i like to do
? ? ? ? ? ? print("config", self.config)
? ? ? ? # When working with NN, one usually initialize randomly
? ? ? ? # and you want to be able to reproduce your initialization so make sure
? ? ? ? # you store the random seed and actually use it in your TF graph (tf.set_random_seed() for example)
? ? ? ? self.random_seed = self.config["random_seed"]
? ? ? ? # All models share some basics hyper parameters, this is the section where we
? ? ? ? # copy them into the model
? ? ? ? self.result_dir = self.config["result_dir"]
? ? ? ? self.max_iter = self.config["max_iter"]
? ? ? ? self.lr = self.config["lr"]
? ? ? ? self.nb_units = self.config["nb_units"]
? ? ? ? # etc.
? ? ? ??
? ? ? ? # Now the child Model needs some custom parameters, to avoid any
? ? ? ? # inheritance hell with the __init__ function, the model?
? ? ? ? # will override this function completely
? ? ? ? self.set_agent_props()
? ? ? ? # Again, child Model should provide its own build_grap function
? ? ? ? self.graph = self.build_graph(tf.Graph())
? ? ? ? # Any operations that should be in the graph but are common to all models
? ? ? ? # can be added this way, here
? ? ? ? with self.graph.as_default():
? ? ? ? ? ? self.saver = tf.train.Saver(
? ? ? ? ? ? ? ? max_to_keep=50,
? ? ? ? ? ? )
? ? ? ??
? ? ? ? # Add all the other common code for the initialization here
? ? ? ? gpu_options = tf.GPUOptions(allow_growth=True)
? ? ? ? sessConfig = tf.ConfigProto(gpu_options=gpu_options)
? ? ? ? self.sess = tf.Session(config=sessConfig, graph=self.graph)
? ? ? ? self.sw = tf.summary.FileWriter(self.result_dir, self.sess.graph)
? ? ? ??
? ? ? ? # This function is not always common to all models, that"s why it"s again
? ? ? ? # separated from the __init__ one
? ? ? ? self.init()
? ? ? ? # At the end of this function, you want your model to be ready!
? ? def set_agent_props(self):
? ? ? ? # This function is here to be overriden completely.
? ? ? ? # When you look at your model, you want to know exactly which custom options it needs.
? ? ? ? pass
? ? def get_best_config(self):
? ? ? ? # This function is here to be overriden completely.
? ? ? ? # It returns a dictionary used to update the initial configuration (see __init__)
? ? ? ? return {}?
? ? @staticmethod
? ? def get_random_config(fixed_params={}):
? ? ? ? # Why static? Because you want to be able to pass this function to other processes
? ? ? ? # so they can independently generate random configuration of the current model
? ? ? ? raise Exception("The get_random_config function must be overriden by the agent")
? ? def build_graph(self, graph):
? ? ? ? raise Exception("The build_graph function must be overriden by the agent")
? ? def infer(self):
? ? ? ? raise Exception("The infer function must be overriden by the agent")
? ? def learn_from_epoch(self):
? ? ? ? # I like to separate the function to train per epoch and the function to train globally
? ? ? ? raise Exception("The learn_from_epoch function must be overriden by the agent")
? ? def train(self, save_every=1):
? ? ? ? # This function is usually common to all your models, Here is an example:
? ? ? ? for epoch_id in range(0, self.max_iter):
? ? ? ? ? ? self.learn_from_epoch()
? ? ? ? ? ? # If you don"t want to save during training, you can just pass a negative number
? ? ? ? ? ? if save_every > 0 and epoch_id % save_every == 0:
? ? ? ? ? ? ? ? self.save()
? ? def save(self):
? ? ? ? # This function is usually common to all your models, Here is an example:
? ? ? ? global_step_t = tf.train.get_global_step(self.graph)
? ? ? ? global_step, episode_id = self.sess.run([global_step_t, self.episode_id])
? ? ? ? if self.config["debug"]:
? ? ? ? ? ? print("Saving to %s with global_step %d" % (self.result_dir, global_step))
? ? ? ? self.saver.save(self.sess, self.result_dir + "/agent-ep_" + str(episode_id), global_step)
? ? ? ? # I always keep the configuration that
? ? ? ? if not os.path.isfile(self.result_dir + "/config.json"):
? ? ? ? ? ? config = self.config
? ? ? ? ? ? if "phi" in config:
? ? ? ? ? ? ? ? del config["phi"]
? ? ? ? ? ? with open(self.result_dir + "/config.json", "w") as f:
? ? ? ? ? ? ? ? json.dump(self.config, f)
? ? def init(self):
? ? ? ? # This function is usually common to all your models
? ? ? ? # but making separate than the __init__ function allows it to be overidden cleanly
? ? ? ? # this is an example of such a function
? ? ? ? checkpoint = tf.train.get_checkpoint_state(self.result_dir)
? ? ? ? if checkpoint is None:
? ? ? ? ? ? self.sess.run(self.init_op)
? ? ? ? else:
? ? ? ? ? ? if self.config["debug"]:
? ? ? ? ? ? ? ? print("Loading the model from folder: %s" % self.result_dir)
? ? ? ? ? ? self.saver.restore(self.sess, checkpoint.model_checkpoint_path)
? ? def infer(self):
? ? ? ? # This function is usually common to all your models
? ? ? ? pass ? ? ? ?
基本模型文件
一些注釋:
關于我配置的「較佳」屬性:人們通常在沒有模型最優超參數的情況下傳送代碼,有人知道為什么嗎?
隨機函數是靜態的,因為你不想實例化(instantiate)你的模型以訪問它,但為什么要將其添加到模型本身呢?因為它通常與模型自定義參數綁定。注意,這個函數必須是純粹的(pure),這樣才能根據需要復雜化。
示例 init 函數是最簡單的版本,它會加載現存文件夾或(如果 result_dir 為空)使用 init_op 隨機初始化。
The __init__ script
你能在文件夾結構看到初始化腳本(The __init__ script),其和機器學習并沒有什么關聯。但該腳本是令你的代碼對你或其他人更加易讀的簡單方式。
該腳本通過添加幾行代碼令任何模型類別都能從命名空間 models 直接可讀取:所以你能在代碼任一處輸入:from models import MyModel,該代碼行能導入模型而不用管模型的文件夾路徑有多么深。
這里有一個腳本案例來實現這一任務:
from models.basic_model import BasicModel
from agents.other_model import SomeOtherModel
__all__ = [
? ? "BasicModel",
? ? "SomeOtherModel"
]
def make_model(config, env):
? ? if config["model_name"] in __all__:
? ? ? ? return globals()[config["model_name"]](config, env)
? ? else:
? ? ? ? raise Exception("The model name %s does not exist" % config["model_name"])
def get_model_class(config):
? ? if config["model_name"] in __all__:
? ? ? ? return globals()[config["model_name"]]
? ? else:
? ? ? ? raise Exception("The model name %s does not exist" % config["model_name"])
這并沒有多高端,但我發現這一腳本十分有用,所以我把它加到本文中了。
API 外殼(The shell API)
我們有一個全局一致的文件夾架構和一個很好的基礎類別來構建我們的模型,一個好的 python 腳本很容易加載我們的類(class),但是設計「shell API」,特別是其默認值是同樣重要的。
因為與機器學習研究交互的主要結束點就是你使用任何工具的外殼(shell),程序外殼是你實驗的基石。
你想要做的最后一件事就是調整你代碼中的硬編碼值來迭代這些實驗,所以你需要從外殼中直接訪問所有的超參數。同樣你還需要訪問所有其他參數,就像結果索引或 stage (HP search/Training/inferring) 等那樣。
同樣為了更進一步理解,我們將為你直接展示注釋文件(commented file):
import os, json
import tensorflow as tf
# See the __init__ script in the models folder
# `make_models` is a helper function to load any models you have
from models import make_models?
from hpsearch import hyperband, randomsearch
# I personally always like to make my paths absolute
# to be independent from where the python binary is called
dir = os.path.dirname(os.path.realpath(__file__))
# I won"t dig into TF interaction with the shell, feel free to explore the documentation
flags = tf.app.flags
# Hyper-parameters search configuration
flags.DEFINE_boolean("fullsearch", False, "Perform a full search of hyperparameter space ex:(hyperband -> lr search -> hyperband with best lr)")
flags.DEFINE_boolean("dry_run", False, "Perform a dry_run (testing purpose)")
flags.DEFINE_integer("nb_process", 4, "Number of parallel process to perform a HP search")
# fixed_params is a trick I use to be able to fix some parameters inside the model random function
# For example, one might want to explore different models fixing the learning rate, see the basic_model get_random_config function
flags.DEFINE_string("fixed_params", "{}", "JSON inputs to fix some params in a HP search, ex: "{"lr": 0.001}"")
# Agent configuration
flags.DEFINE_string("model_name", "DQNAgent", "Unique name of the model")
flags.DEFINE_boolean("best", False, "Force to use the best known configuration")
flags.DEFINE_float("initial_mean", 0., "Initial mean for NN")
flags.DEFINE_float("initial_stddev", 1e-2, "Initial standard deviation for NN")
flags.DEFINE_float("lr", 1e-3, "The learning rate of SGD")
flags.DEFINE_float("nb_units", 20, "Number of hidden units in Deep learning agents")
# Environment configuration
flags.DEFINE_boolean("debug", False, "Debug mode")
flags.DEFINE_integer("max_iter", 2000, "Number of training step")
flags.DEFINE_boolean("infer", False, "Load an agent for playing")
# This is very important for TensorBoard
# each model will end up in its own unique folder using time module
# Obviously one can also choose to name the output folder
flags.DEFINE_string("result_dir", dir + "/results/" + flags.FLAGS.model_name + "/" + str(int(time.time())), "Name of the directory to store/log the model (if it exists, the model will be loaded from it)")
# Another important point, you must provide an access to the random seed
# to be able to fully reproduce an experiment
flags.DEFINE_integer("random_seed", random.randint(0, sys.maxsize), "Value of random seed")
def main(_):
? ? config = flags.FLAGS.__flags.copy()
? ? # fixed_params must be a string to be passed in the shell, let"s use JSON
? ? config["fixed_params"] = json.loads(config["fixed_params"])
? ? if config["fullsearch"]:
? ? ? ? # Some code for HP search ...
? ? else:
? ? ? ? model = make_model(config)
? ? ? ? if config["infer"]:
? ? ? ? ? ? # Some code for inference ...
? ? ? ? else:
? ? ? ? ? ? # Some code for training ...
if __name__ == "__main__":
? tf.app.run()
以上就是本文想要描述的,我們希望它能幫助新入門者輔助研究,我們同樣也歡迎自由評論或提問。
原文鏈接:https://blog.metaflow.fr/tensorflow-a-proposal-of-good-practices-for-files-folders-and-models-architecture-f23171501ae3
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4540.html
摘要:年月日,機器之心曾經推出文章為你的深度學習任務挑選最合適從性能到價格的全方位指南。如果你想要學習深度學習,這也具有心理上的重要性。如果你想快速學習深度學習,多個廉價的也很好。目前還沒有適合顯卡的深度學習庫所以,只能選擇英偉達了。 文章作者 Tim Dettmers 系瑞士盧加諾大學信息學碩士,熱衷于開發自己的 GPU 集群和算法來加速深度學習。這篇博文最早版本發布于 2014 年 8 月,之...
摘要:本報告面向的讀者是想要進入機器學習領域的學生和正在尋找新框架的專家。其輸入需要重塑為包含個元素的一維向量以滿足神經網絡。卷積神經網絡目前代表著用于圖像分類任務的較先進算法,并構成了深度學習中的主要架構。 初學者在學習神經網絡的時候往往會有不知道從何處入手的困難,甚至可能不知道選擇什么工具入手才合適。近日,來自意大利的四位研究者發布了一篇題為《神經網絡初學者:在 MATLAB、Torch 和 ...

閱讀 2459·2021-11-22 09:34
閱讀 3066·2021-10-25 09:43
閱讀 1981·2021-10-11 10:59
閱讀 3381·2021-09-22 15:13
閱讀 2330·2021-09-04 16:40
閱讀 423·2019-08-30 15:53
閱讀 3189·2019-08-30 11:13
閱讀 2607·2019-08-29 17:30