資訊專欄INFORMATION COLUMN

摘要:前面兩個期望的采樣我們都熟悉,第一個期望是從真樣本集里面采,第二個期望是從生成器的噪聲輸入分布采樣后,再由生成器映射到樣本空間。
Wasserstein GAN進(jìn)展:從weight clipping到gradient penalty,更加先進(jìn)的Lipschitz限制手法
前段時間,Wasserstein ?GAN以其精巧的理論分析、簡單至極的算法實現(xiàn)、出色的實驗效果,在GAN研究圈內(nèi)掀起了一陣熱潮(對WGAN不熟悉的讀者,可以參考我之前寫的介紹文章:令人拍案叫絕的Wasserstein GAN - 知乎專欄)。但是很多人(包括我們實驗室的同學(xué))到了上手跑實驗的時候,卻發(fā)現(xiàn)WGAN實際上沒那么完美,反而存在著訓(xùn)練困難、收斂速度慢等問題。其實,WGAN的作者M(jìn)artin Arjovsky不久后就在reddit上表示他也意識到了這個問題,認(rèn)為關(guān)鍵在于原設(shè)計中Lipschitz限制的施加方式不對,并在新論文中提出了相應(yīng)的改進(jìn)方案:
論文:[1704.00028] Improved Training of Wasserstein GANs
Tensorflow實現(xiàn):igul222/improved_wgan_training
首先回顧一下WGAN的關(guān)鍵部分——Lipschitz限制是什么。WGAN中,判別器D和生成器G的loss函數(shù)分別是:

直觀上解釋,就是當(dāng)輸入的樣本稍微變化后,判別器給出的分?jǐn)?shù)不能發(fā)生太過劇烈的變化。在原來的論文中,這個限制具體是通過weight clipping的方式實現(xiàn)的:每當(dāng)更新完一次判別器的參數(shù)之后,就檢查判別器的所有參數(shù)的值有沒有超過一個閾值,比如0.01,有的話就把這些參數(shù)clip回 [-0.01, 0.01] 范圍內(nèi)。通過在訓(xùn)練過程中保證判別器的所有參數(shù)有界,就保證了判別器不能對兩個略微不同的樣本給出天差地別的分?jǐn)?shù)值,從而間接實現(xiàn)了Lipschitz限制。
然而weight clipping的實現(xiàn)方式存在兩個嚴(yán)重問題:
第一,如公式1所言,判別器loss希望盡可能拉大真假樣本的分?jǐn)?shù)差,然而weight clipping獨(dú)立地限制每一個網(wǎng)絡(luò)參數(shù)的取值范圍,在這種情況下我們可以想象,最優(yōu)的策略就是盡可能讓所有參數(shù)走極端,要么取較大值(如0.01)要么取最小值(如-0.01)!為了驗證這一點(diǎn),作者統(tǒng)計了經(jīng)過充分訓(xùn)練的判別器中所有網(wǎng)絡(luò)參數(shù)的數(shù)值分布,發(fā)現(xiàn)真的集中在較大和最小兩個極端上:
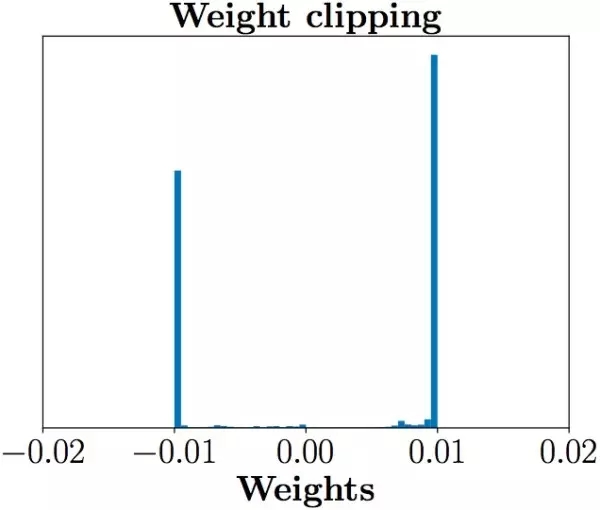
這樣帶來的結(jié)果就是,判別器會非常傾向于學(xué)習(xí)一個簡單的映射函數(shù)(想想看,幾乎所有參數(shù)都是正負(fù)0.01,都已經(jīng)可以直接視為一個二值神經(jīng)網(wǎng)絡(luò)了,太簡單了)。而作為一個深層神經(jīng)網(wǎng)絡(luò)來說,這實在是對自身強(qiáng)大擬合能力的巨大浪費(fèi)!判別器沒能充分利用自身的模型能力,經(jīng)過它回傳給生成器的梯度也會跟著變差。
在正式介紹gradient penalty之前,我們可以先看看在它的指導(dǎo)下,同樣充分訓(xùn)練判別器之后,參數(shù)的數(shù)值分布就合理得多了,判別器也能夠充分利用自身模型的擬合能力:
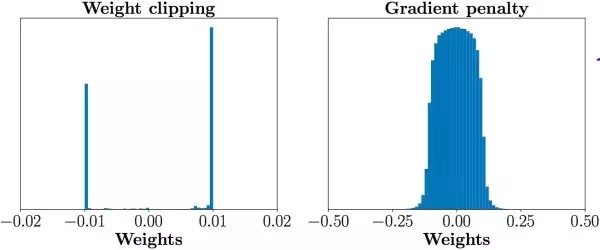
第二個問題,weight clipping會導(dǎo)致很容易一不小心就梯度消失或者梯度爆炸。原因是判別器是一個多層網(wǎng)絡(luò),如果我們把clipping threshold設(shè)得稍微小了一點(diǎn),每經(jīng)過一層網(wǎng)絡(luò),梯度就變小一點(diǎn)點(diǎn),多層之后就會指數(shù)衰減;反之,如果設(shè)得稍微大了一點(diǎn),每經(jīng)過一層網(wǎng)絡(luò),梯度變大一點(diǎn)點(diǎn),多層之后就會指數(shù)爆炸。只有設(shè)得不大不小,才能讓生成器獲得恰到好處的回傳梯度,然而在實際應(yīng)用中這個平衡區(qū)域可能很狹窄,就會給調(diào)參工作帶來麻煩。相比之下,gradient penalty就可以讓梯度在后向傳播的過程中保持平穩(wěn)。論文通過下圖體現(xiàn)了這一點(diǎn),其中橫軸代表判別器從低到高第幾層,縱軸代表梯度回傳到這一層之后的尺度大小(注意縱軸是對數(shù)刻度),c是clipping threshold:
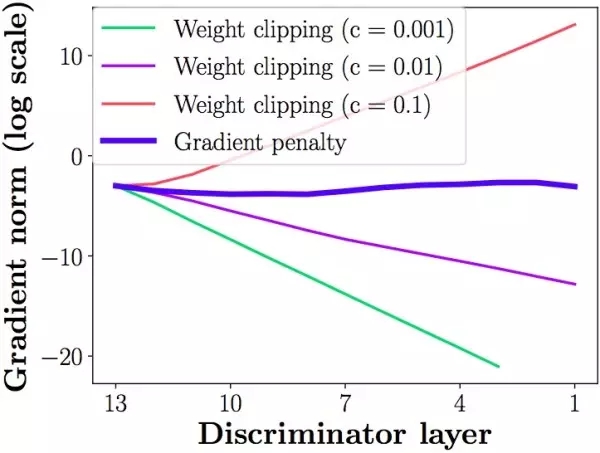
說了這么多,gradient penalty到底是什么?
前面提到,Lipschitz限制是要求判別器的梯度不超過K,那我們何不直接設(shè)置一個額外的loss項來體現(xiàn)這一點(diǎn)呢?比如說:

這就是所謂的gradient penalty了嗎?還沒完。公式6有兩個問題,首先是loss函數(shù)中存在梯度項,那么優(yōu)化這個loss豈不是要算梯度的梯度?一些讀者可能對此存在疑惑,不過這屬于實現(xiàn)上的問題,放到后面說。
其次,3個loss項都是期望的形式,落到實現(xiàn)上肯定得變成采樣的形式。前面兩個期望的采樣我們都熟悉,第一個期望是從真樣本集里面采,第二個期望是從生成器的噪聲輸入分布采樣后,再由生成器映射到樣本空間。可是第三個分布要求我們在整個樣本空間 ?上采樣,這完全不科學(xué)!由于所謂的維度災(zāi)難問題,如果要通過采樣的方式在圖片或自然語言這樣的高維樣本空間中估計期望值,所需樣本量是指數(shù)級的,實際上沒法做到。
所以,論文作者就非常機(jī)智地提出,我們其實沒必要在整個樣本空間上施加Lipschitz限制,只要重點(diǎn)抓住生成樣本集中區(qū)域、真實樣本集中區(qū)域以及夾在它們中間的區(qū)域就行了。具體來說,我們先隨機(jī)采一對真假樣本,還有一個0-1的隨機(jī)數(shù):

這就是新論文所采用的gradient penalty方法,相應(yīng)的新WGAN模型簡稱為WGAN-GP。我們可以做一個對比:
weight clipping是對樣本空間全局生效,但因為是間接限制判別器的梯度norm,會導(dǎo)致一不小心就梯度消失或者梯度爆炸;
gradient penalty只對真假樣本集中區(qū)域、及其中間的過渡地帶生效,但因為是直接把判別器的梯度norm限制在1附近,所以梯度可控性非常強(qiáng),容易調(diào)整到合適的尺度大小。
論文還講了一些使用gradient penalty時需要注意的配套事項,這里只提一點(diǎn):由于我們是對每個樣本獨(dú)立地施加梯度懲罰,所以判別器的模型架構(gòu)中不能使用Batch Normalization,因為它會引入同個batch中不同樣本的相互依賴關(guān)系。如果需要的話,可以選擇其他normalization方法,如Layer Normalization、Weight Normalization和Instance Normalization,這些方法就不會引入樣本之間的依賴。論文推薦的是Layer Normalization。
實驗表明,gradient penalty能夠顯著提高訓(xùn)練速度,解決了原始WGAN收斂緩慢的問題:

雖然還是比不過DCGAN,但是因為WGAN不存在平衡判別器與生成器的問題,所以會比DCGAN更穩(wěn)定,還是很有優(yōu)勢的。不過,作者憑什么能這么說?因為下面的實驗體現(xiàn)出,在各種不同的網(wǎng)絡(luò)架構(gòu)下,其他GAN變種能不能訓(xùn)練好,可以說是一件相當(dāng)看人品的事情,但是WGAN-GP全都能夠訓(xùn)練好,尤其是最下面一行所對應(yīng)的101層殘差神經(jīng)網(wǎng)絡(luò):

剩下的實驗結(jié)果中,比較厲害的是第一次成功做到了“純粹的”的文本GAN訓(xùn)練!我們知道在圖像上訓(xùn)練GAN是不需要額外的有監(jiān)督信息的,但是之前就沒有人能夠像訓(xùn)練圖像GAN一樣訓(xùn)練好一個文本GAN,要么依賴于預(yù)訓(xùn)練一個語言模型,要么就是利用已有的有監(jiān)督ground truth提供指導(dǎo)信息。而現(xiàn)在WGAN-GP終于在無需任何有監(jiān)督信息的情況下,生成出下圖所示的英文字符序列:

它是怎么做到的呢?我認(rèn)為關(guān)鍵之處是對樣本形式的更改。以前我們一般會把文本這樣的離散序列樣本表示為sequence of index,但是它把文本表示成sequence of probability vector。對于生成樣本來說,我們可以取網(wǎng)絡(luò)softmax層輸出的詞典概率分布向量,作為序列中每一個位置的內(nèi)容;而對于真實樣本來說,每個probability vector實際上就蛻化為我們熟悉的onehot vector。
但是如果按照傳統(tǒng)GAN的思路來分析,這不是作死嗎?一邊是hard onehot vector,另一邊是soft probability vector,判別器一下子就能夠區(qū)分它們,生成器還怎么學(xué)習(xí)?沒關(guān)系,對于WGAN來說,真假樣本好不好區(qū)分并不是問題,WGAN只是拉近兩個分布之間的Wasserstein距離,就算是一邊是hard onehot另一邊是soft probability也可以拉近,在訓(xùn)練過程中,概率向量中的有些項可能會慢慢變成0.8、0.9到接近1,整個向量也會接近onehot,最后我們要真正輸出sequence of index形式的樣本時,只需要對這些概率向量取argmax得到較大概率的index就行了。
新的樣本表示形式+WGAN的分布拉近能力是一個“黃金組合”,但除此之外,還有其他因素幫助論文作者跑出上圖的效果,包括:
文本粒度為英文字符,而非英文單詞,所以字典大小才二三十,大大減小了搜索空間
文本長度也才32
生成器用的不是常見的LSTM架構(gòu),而是多層反卷積網(wǎng)絡(luò),輸入一個高斯噪聲向量,直接一次性轉(zhuǎn)換出所有32個字符
上面第三點(diǎn)非常有趣,因為它讓我聯(lián)想到前段時間挺火的語言學(xué)科幻電影《降臨》:

里面的外星人“七肢怪”所使用的語言跟人類不同,人類使用的是線性的、串行的語言,而“七肢怪”使用的是非線性的、并行的語言。“七肢怪”在跟主角交流的時候,都是一次性同時給出所有的語義單元的,所以說它們其實是一些多層反卷積網(wǎng)絡(luò)進(jìn)化出來的人工智能生命嗎?

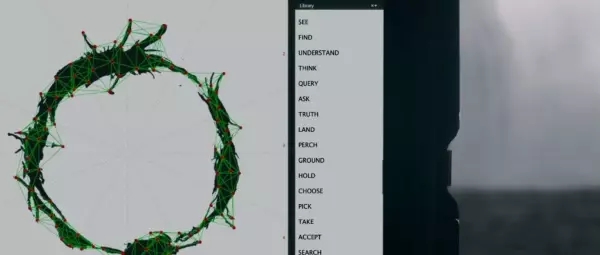
開完腦洞,我們回過頭看,不得不承認(rèn)這個實驗的setup實在過于簡化了,能否擴(kuò)展到更加實際的復(fù)雜場景,也會是一個問題。但是不管怎樣,生成出來的結(jié)果仍然是突破性的。
最后說回gradient penalty的實現(xiàn)問題。loss中本身包含梯度,優(yōu)化loss就需要求梯度的梯度,這個功能并不是現(xiàn)在所有深度學(xué)習(xí)框架的標(biāo)配功能,不過好在Tensorflow就有提供這個接口——tf.gradients。開頭鏈接的GitHub源碼中就是這么寫的:
# interpolates就是隨機(jī)插值采樣得到的圖像,gradients就是loss中的梯度懲罰項
gradients = tf.gradients(Discriminator(interpolates), [interpolates])[0]
對于我這樣的PyTorch黨就非常不幸了,高階梯度的功能還在開發(fā),感興趣的PyTorch黨可以訂閱這個GitHub的pull request:Autograd refactor,如果它被merged了話就可以在版中使用高階梯度的功能實現(xiàn)gradient penalty了。 但是除了等待我們就沒有別的辦法了嗎?其實可能是有的,我想到了一種近似方法來實現(xiàn)gradient penalty,只需要把微分換成差分:
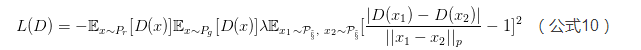
也就是說,我們?nèi)匀皇窃诜植??上隨機(jī)采樣,但是一次采兩個,然后要求它們的連線斜率要接近1,這樣理論上也可以起到跟公式9一樣的效果,我自己在MNIST+MLP上簡單驗證過有作用,PyTorch黨甚至Tensorflow黨都可以嘗試用一下。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4539.html
摘要:但是在傳統(tǒng)的機(jī)器學(xué)習(xí)中,特征和算法都是人工定義的。傳統(tǒng)的深度學(xué)習(xí)中,是由人來決定要解決什么問題,人來決定用什么目標(biāo)函數(shù)做評估。 隨著柯潔與AlphaGo結(jié)束以后,大家是不是對人工智能的底層奧秘越來越有興趣?深度學(xué)習(xí)已經(jīng)在圖像分類、檢測等諸多領(lǐng)域取得了突破性的成績。但是它也存在一些問題。首先,它與傳統(tǒng)的機(jī)器學(xué)習(xí)方法一樣,通常假設(shè)訓(xùn)練數(shù)據(jù)與測試數(shù)據(jù)服從同樣的分布,或者是在訓(xùn)練數(shù)據(jù)上的預(yù)測結(jié)果與在...
摘要:直接把應(yīng)用到領(lǐng)域主要是生成序列,有兩方面的問題最開始是設(shè)計用于生成連續(xù)數(shù)據(jù),但是自然語言處理中我們要用來生成離散的序列。如圖,針對第一個問題,首先是將的輸出作為,然后用來訓(xùn)練。 我來答一答自然語言處理方面GAN的應(yīng)用。直接把GAN應(yīng)用到NLP領(lǐng)域(主要是生成序列),有兩方面的問題:1. GAN最開始是設(shè)計用于生成連續(xù)數(shù)據(jù),但是自然語言處理中我們要用來生成離散tokens的序列。因為生成器(G...
摘要:另外,在損失函數(shù)中加入感知正則化則在一定程度上可緩解該問題。替代損失函數(shù)修復(fù)缺陷的最流行的補(bǔ)丁是。的作者認(rèn)為傳統(tǒng)損失函數(shù)并不會使收集的數(shù)據(jù)分布接近于真實數(shù)據(jù)分布。原來損失函數(shù)中的對數(shù)損失并不影響生成數(shù)據(jù)與決策邊界的距離。 盡管 GAN 領(lǐng)域的進(jìn)步令人印象深刻,但其在應(yīng)用過程中仍然存在一些困難。本文梳理了 GAN 在應(yīng)用過程中存在的一些難題,并提出了的解決方法。使用 GAN 的缺陷眾所周知,G...
摘要:如果你對算法實戰(zhàn)感興趣,請快快關(guān)注我們吧。加入實戰(zhàn)微信群,實戰(zhàn)群,算法微信群,算法群。 作者:chen_h微信號 & QQ:862251340微信公眾號:coderpai簡書地址:https://www.jianshu.com/p/b5c... 介紹一些人工智能技術(shù)的術(shù)語,如果你還有術(shù)語補(bǔ)充,請訪問 Github English Terminology 中文術(shù)語 neur...
摘要:實驗基礎(chǔ)其實實現(xiàn)該功能的主要步驟還是需要計算出網(wǎng)絡(luò)的損失函數(shù)以及其偏導(dǎo)數(shù),具體的公式可以參考前面的博文八。生成均勻分布的偽隨機(jī)數(shù)。 前言: 現(xiàn)在來進(jìn)入sparse autoencoder的一個實例練習(xí),參考Ng的網(wǎng)頁教程:Exercise:Sparse Autoencoder。 這個例子所要實現(xiàn)的內(nèi)容大概如下:從給定的很多張自然圖片中截取出大小為8*8的小patches圖片共10000張...

閱讀 648·2021-09-24 09:48
閱讀 2498·2021-08-26 14:14
閱讀 522·2019-08-30 13:08
閱讀 1449·2019-08-29 15:22
閱讀 3080·2019-08-29 11:06
閱讀 1009·2019-08-26 18:26
閱讀 1051·2019-08-26 13:53
閱讀 2532·2019-08-26 12:21






