資訊專欄INFORMATION COLUMN

摘要:年月日,機器之心曾經推出文章為你的深度學習任務挑選最合適從性能到價格的全方位指南。如果你想要學習深度學習,這也具有心理上的重要性。如果你想快速學習深度學習,多個廉價的也很好。目前還沒有適合顯卡的深度學習庫所以,只能選擇英偉達了。
文章作者 Tim Dettmers 系瑞士盧加諾大學信息學碩士,熱衷于開發自己的 GPU 集群和算法來加速深度學習。這篇博文最早版本發布于 2014 年 8 月,之后隨著相關技術的發展和硬件的更新,Dettmers 也在不斷對本文進行修正。2016 年 7 月 18 日,機器之心曾經推出文章為你的深度學習任務挑選最合適 GPU:從性能到價格的全方位指南 。當時,機器之心呈現的文章是其 2016 年 6 月 25 日的更新(之前已經有五次更新)。接著,2016 年 7 月 23 日以及 2017 年 3 月 19 日,作者又分別根據硬件發展情況兩度更新博文:2016 年 7 月 23 日主要添加了 Titan X Pascal 以及 GTX 1060 并更新了相應推薦;2017 年 3 月 19 日添加了 GTX 1080 Ti 并對博客進行了較大調整。本文依據的是 3 月 19 日更新后的版本。另外,除了 GPU 之外,深度學習還需要其它一些硬件基礎,詳情可參閱機器之心之前的文章《深度 | 史上最全面的深度學習硬件指南》。
深度學習是一個計算密集型領域,而 GPU 的選擇將從根本上決定你的深度學習實驗。沒有 GPU,一個實驗也許花費數月才能完成,或者實驗運行一天卻只關閉了被選擇的參數;而一個良好穩定的 GPU 可讓你在深度學習網絡中快速迭代,在數天、數小時、數分鐘內完成實驗,而不是數月、數天、數小時。所以,購買 GPU 時正確的選擇很關鍵。那么,如何選擇一個適合你的 GPU 呢?這正是本篇博文探討的問題,幫助你做出正確選擇。
對于深度學習初學者來說,擁有一個快速 GPU 非常重要,因為它可以使你迅速獲得有助于構建專業知識的實踐經驗,這些專業知識可以幫助你將深度學習應用到新問題上。沒有這種迅速反饋,從錯誤中汲取經驗將會花費太多時間,在繼續深度學習過程中也會感到受挫和沮喪。在 GPU 的幫助下,我很快就學會了如何在一系列 Kaggle 競賽中應用深度學習,并且在 Partly Sunny with a Chance of Hashtags Kaggle 競賽上獲得了第二名,競賽內容是通過一個給定推文預測氣象評分。比賽中,我使用了一個相當大的兩層深度神經網絡(帶有兩個修正線性單元和 dropout,用于正則化),差點就沒辦法把這個深度網絡塞進我的 6G GPU 內存。
應該使用多個 GPU 嗎?
在 GPU 的幫助下,深度學習可以完成很多事情,這讓我感到興奮。我投身到多 GPU 的領域之中,用 InfiniBand 40Gbit/s 互連組裝了小型 GPU 集群。我瘋狂地想要知道多個 GPU 能否獲得更好的結果。我很快發現,不僅很難在多個 GPU 上并行神經網絡。而且對普通的密集神經網絡來說,加速效果也很一般。小型神經網絡可以并行并且有效地利用數據并行性,但對于大一點的神經網絡來說,例如我在 Partly Sunny with a Chance of Hashtags Kaggle 比賽中使用的,幾乎沒有加速效果。
隨后,我進一步試驗,對比 32 位方法,我開發了帶有模型并行性的新型 8 位壓縮技術,該技術能更有效地并行處理密集或全連接神經網絡層。
然而,我也發現,并行化也會讓人沮喪得發狂。針對一系列問題,我天真地優化了并行算法,結果發現:考慮到你投入的精力,即使使用優化過的自定義代碼,多個 GPU 上的并行注意的效果也并不好。你需要非常留意你的硬件及其與深度學習算法交互的方式,這樣你一開始就能衡量你是否可以受益于并行化。

我的計算機主機設置:你可以看到 3 個 GXT Titan 和一個 InfiniBand 卡。對于深度學習來說,這是一個好的設置嗎?
自那時起,GPU 的并行性支持越來越普遍,但距離全面可用和有效還差的很遠。目前,在 GPU 和計算機中實現有效算法的深度學習庫是 CNTK,它使用微軟的 1 比特量子化(有效)和 block momentum(很有效)的特殊并行化算法。通過 CNTK 和一個包含 96 塊 GPU 的聚類,你可以擁有一個大約 90x-95x 的新線性速度。Pytorch 也許是跨機器支持有效并行化的庫,但是,庫目前還不存在。如果你想要在一臺機器上做并行,那么,CNTK、Torch 和 Pytorch 是你的主要選擇,這些庫具備良好的加速(3.6x-3.8x),并在一臺包含 4 至 8 塊 GPU 的機器之中預定義了并行化算法。也有其他支持并行化的庫,但它們不是慢(比如 2x-3x 的 TensorFlow)就是難于用于多 GPU (Theano),或者兼而有之。
如果你重視并行,我建議你使用 Pytorch 或 CNTK。
使用多 GPU 而無并行
使用多 GPU 的另外一個好處是:即使沒有并行算法,你也可以分別在每個 GPU 上運行多個算法或實驗。速度沒有變快,但是你能一次性通過使用不同算法或參數得到更多關于性能信息。如果你的主要目標是盡快獲得深度學習經驗,這是非常有用的,而且對于想同時嘗試新算法不同版本的研究人員來說,這也非常有用。
如果你想要學習深度學習,這也具有心理上的重要性。執行任務的間隔以及得到反饋信息的時間越短,大腦越能將相關記憶片段整合成連貫畫面。如果你在小數據集上使用獨立的 GPU 訓練兩個卷積網絡,你就能更快地知道什么對于性能優良來說是重要的;你將更容易地檢測到交叉驗證誤差中的模式并正確地解釋它們。你也會發現暗示需要添加、移除或調整哪些參數與層的模式。
所以總體而言,幾乎對于所有任務來說,一個 GPU 已經足夠了,但是加速深度學習模型,多個 GPU 會變得越來越重要。如果你想快速學習深度學習,多個廉價的 GPU 也很好。我個人寧愿使用多個小的 GPU,而不是一個大的 GPU,即使是出于研究實驗的沒目的。
那么,我該選擇哪類加速器呢?英偉達 GPU、AMD GUP 還是英特爾的 Xeon Phi?
英偉達的標準庫使得在 CUDA 中建立第一個深度學習庫很容易,但沒有適合 AMD 的 OpenCL 那樣強大的標準庫。目前還沒有適合 AMD 顯卡的深度學習庫——所以,只能選擇英偉達了。即使未來一些 OpenCL 庫可用,我仍會堅持使用英偉達:因為對于 CUDA 來說,GPU 計算或者 GPGPU 社區是很大的,對于 OpenCL 來說,則相對較小。因此,在 CUDA 社區,有現成的好的開源解決方案和為編程提供可靠建議。
此外,英偉達現在為深度學習賭上一切,即使深度學習還只是處于嬰兒期。押注獲得了回報。盡管現在其他公司也往深度學習投入了錢和精力,但由于開始的晚,目前依然很落后。目前,除了 NVIDIA-CUDA,其他任何用于深度學習的軟硬結合的選擇都會讓你受挫。
至于英特爾的 Xeon Phi,廣告宣稱你能夠使用標準 C 代碼,還能將代碼輕松轉換成加速過的 Xeon Phi 代碼。聽起來很有趣,因為你可能認為可以依靠龐大的 C 代碼資源。但事實上,其只支持非常一小部分 C 代碼,因此,這一功能并不真正有用,大部分 C 運行起來會很慢。
我曾研究過 500 多個 Xeon Phi 集群,遭遇了無止盡的挫折。我不能運行我的單元測試(unit test),因為 Xeon Phi 的 MKL(數學核心函數庫)并不兼容 NumPy;我不得不重寫大部分代碼,因為英特爾 Xeon Phi 編譯器無法讓模板做出適當約簡。例如,switch 語句,我不得不改變我的 C 接口,因為英特爾 Xeon Phi 編譯器不支持 C++ 11 的一些特性。這一切迫使你在沒有單元測試的情況下來執行代碼的重構,實在讓人沮喪。這花了很長時間。真是地獄啊。
隨后,執行我的代碼時,一切都運行得很慢。是有 bug(?)或者僅僅是線程調度器(thread scheduler)里的問題?如果作為運行基礎的向量大小連續變化,哪個問題會影響性能表現?比如,如果你有大小不同的全連接層,或者 dropout 層,Xeon Phi 會比 CPU 還慢。我在一個獨立的矩陣乘法(matrix-matrix multiplication)實例中復制了這一行為,并把它發給了英特爾,但從沒收到回信。所以,如果你想做深度學習,遠離 Xeon Phi!
給定預算下的最快 GPU
你的第一個問題也許是:用于深度學習的快速 GPU 性能的最重要特征是什么?是 cuda 內核、時鐘速度還是 RAM 的大小?
以上都不是。最重要的特征是內存帶寬。
簡言之,GPU 通過犧牲內存訪問時間(延遲)而優化了內存帶寬; 而 CPU 的設計恰恰相反。如果只占用了少量內存,例如幾個數相乘(3*6*9),CPU 可以做快速計算,但是,對于像矩陣相乘(A*B*C)這樣占用大量內存的操作,CPU 運行很慢。由于其內存帶寬,GPU 擅長處理占用大量內存的問題。當然 GPU 和 CPU 之間還存在其他更復雜的差異。
如果你想購買一個快速 GPU,第一等重要的就是看看它的帶寬。
根據內存帶寬評估 GPU
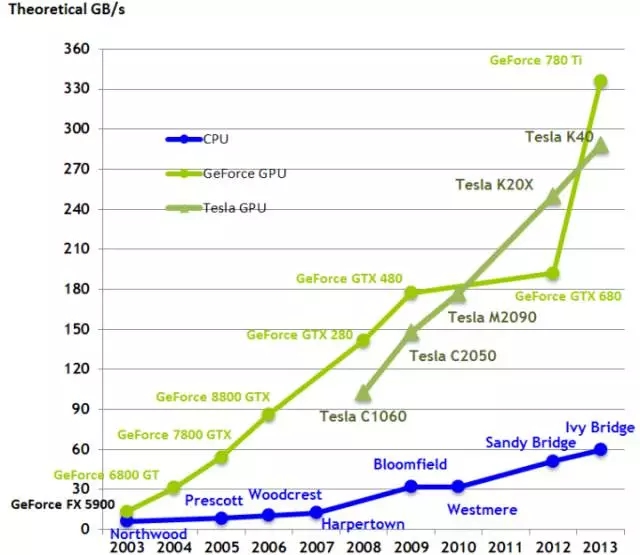
隨著時間的推移,比較 CPU 以及 GPU 的帶寬。為什么 GPU 計算速度會比 CPU 快?主要原因之一就是帶寬。
帶寬可直接在一個架構內進行比較,例如, 比較 Pascal 顯卡 GTX 1080 與 GTX 1070 的性能;也可通過只查看其內存帶寬而直接比較。例如,GTX 1080 (320GB/s) 大約比 GTX 1070 (256 GB/s) 快 25%。然而, 在多個架構之間,例如 Pascal 對于 Maxwell 就像 GTX 1080 對于 GTX Titan X 一樣,不能進行直接比較,因為加工過程不同的架構使用了不同的給定內存帶寬。這一切看起來有點狡猾,但是,只看總帶寬就可對 GPU 的大致速度有一個很好的全局了解。在給定預算的情況下選擇一塊最快的 GPU,你可以使用這一維基百科頁面(List of Nvidia graphics processing units),查看 GB/s 中的帶寬;對于更新的顯卡(900 和 1000 系列)來說,列表中的價格相當較精確,但是,老舊的顯卡相比于列舉的價格會便宜很多,尤其是在 eBay 上購買這些顯卡時。例如,一個普通的 GTX Titan X 在 eBay 上的價格大約是 550 美元。
然而,另一個需要考慮的重要因素是,并非所有架構都與 cuDNN 兼容。由于幾乎所有的深度學習庫都使用 cuDNN 做卷積運算,這就限制了對于 Kepler GPU 或更好 GPU 的選擇,即 GTX 600 系列或以上版本。最主要的是 Kepler GPU 通常會很慢。因此這意味著你應該選擇 900 或 1000 系列 GPU 來獲得好的性能。
為了大致搞清楚深度學習任務中的顯卡性能比較情況,我創建了一個簡單的 GPU 等價表。如何閱讀它呢?例如,GTX 980 的速度相當于 0.35 個 Titan X Pascal,或是 Titan X Pascal 的速度幾乎三倍快于 GTX 980。
請注意我沒有所有這些顯卡,也沒有在所有這些顯卡上跑過深度學習基準。這些對比源于顯卡規格以及計算基準(有些加密貨幣挖掘任務需要比肩深度學習的計算能力)的比較。因此只是粗略的比較。真實數字會有點區別,但是一般說來,誤差會是最小的,顯卡的排序也沒問題。
也請注意,沒有充分利用 GPU 的小型網絡會讓更大 GPU 看起來不那么帥。比如,一個 GTX 1080 Ti 上的小型 LSTM(128 個隱藏單元;batch 大小大于 64)不會比在 GTX 1070 上運行速度明顯快很多。為了實現表格中的性能差異,你需要運行更大的網絡,比如 帶有 1024 個隱藏單元(而且 batch 大小大于 64)的 LSTM。當選擇適合自己的 GPU 時,記住這一點很重要。
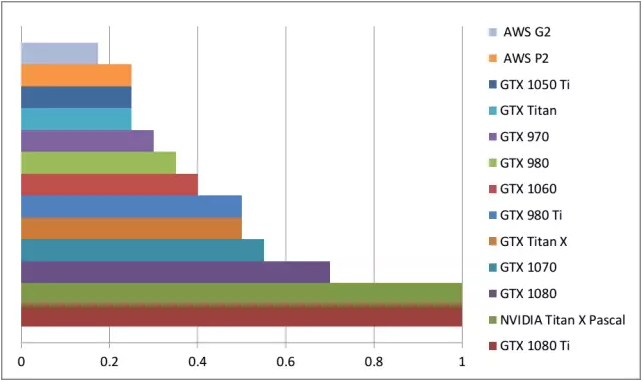
粗略的比較用于大型深度學習網絡 的 GPU 性能。
總的來說,我會推薦 GTX 1080 Ti 或者 GTX 1070。它們都是優秀的顯卡,如果你有錢買得起 GTX 1080 Ti 那么就入手吧。GTX 1070 更加便宜點,但是仍然比普通的 GTX Titan X (Maxwell) 要快一些。較之 GTX 980 Ti,這兩者都是更佳選擇,考慮到增加的 11 G 以及 8G 的內存(而不是 6G)。
8G 的內存看起來有點小,但是對于許多任務來說,綽綽有余。比如,Kaggle 比賽,很多圖像數據集、深度風格以及自然語言理解任務上,你遇到的麻煩會少很多。
GTX 1060 是較好的入門 GPU,如果你是首次嘗試深度學習或者有時想要使用它來參加 Kaggle 比賽。我不會推薦 GTX 1060 帶有 3G 內存的變體產品,既然其他 6G 內存產品的能力已經十分有限了。不過,對于很多應用來說,6G 內存足夠了。GTX 1060 要比普通版本的 Titan X 慢一些,但是,在性能和價格方面(eBay 上)都可比肩 GTX980。
如果要說物有所值呢,10 系列設計真的很贊。GTX 1060、GTX 1070 和 GTX 1080 Ti 上都很出色。GTX 1060 適合初學者,GTX 1070 是某些產業和研究部門以及創業公司的好選擇,GTX 1080 Ti 通殺高端選擇。
一般說來,我不會推薦英偉達 Titan X (Pascal),就其性能而言,價格死貴了。繼續使用 GTX 1080 Ti 吧。不過,英偉達 Titan X (Pascal) 在計算機視覺研究人員當中,還是有它的地位的,這些研究人員通常要研究大型數據集或者視頻集。在這些領域里,每 1G 內存都不會浪費,英偉達 Titan X 比 GTX 1080 Ti 多 1G 的內存也會帶來更多的處理優勢。不過,就物有所值而言,這里推薦 eBay 上的 GTX Titan X(Maxwell)——有點慢,不過 12G 的內存哦。
不過,絕大多數研究人員使用 GTX 1080 Ti 就可以了。對于絕大多數研究和應用來說,額外 1G 內存其實是不必要的。
我個人會使用多個 GTX 1070 進行研究。我寧可多跑幾個測試,哪怕速度比僅跑一個測試(這樣速度會快些)慢一些。在自然語言處理任務中,內存限制并不像計算機視覺研究中那么明顯。因此,GTX 1070 就夠用了。我的研究任務以及運行實驗的方式決定了最適合我的選擇就是 GTX 1070。
當你挑選自己的 GPU 時,也應該如法炮制,進行甄選。考慮你的任務以及運行實驗的方式,然后找個滿足所有這些需求的 GPU。
現在,對于那些手頭很緊又要買 GPU 的人來說,選擇更少了。AWS 的 GPU 實例很貴而且現在也慢,不再是一個好的選擇,如果你的預算很少的話。我不推薦 GTX 970,因為速度慢還死貴,即使在 eBay 上入二手(150 刀),而且還有存儲及顯卡啟動問題。相反,多弄點錢買一個 GTX 1060,速度會快得多,存儲也更大,還沒有這方面的問題。如果你只是買不起 GTX 1060,我推薦 4GB RAM 的 GTX 1050 Ti。4GB 會有限,但是你可以玩轉深度學習了,如果你調一下模型,就能獲得良好的性能。GTX 1050 適合絕大多數 kaggle 競賽,盡管可能會在一些比賽中限制你的競爭力。
亞馬遜網絡服務(AWS)中的 GPU 實例
在這篇博文的前一個版本中,我推薦了 AWS GPU 的現貨實例,但現在我不會再推薦它了。目前 AWS 上的 GPU 相當慢(一個 GTX 1080 的速度是 AWS GPU 的 4 倍)并且其價格在過去的幾個月里急劇上升。現在看起來購買自己的 GPU 又似乎更為明智了。
總結
運用這篇文章里的所有信息,你應該能通過平衡內存大小的需要、帶寬速度 GB/s 以及 GPU 的價格來找到合適的 GPU 了,這些推理在未來許多年中都會是可靠的。但是,現在我所推薦的是 GTX 1080 Ti 或 GTX 1070,只要價格可以接受就行;如果你剛開始涉足深度學習或者手頭緊,那么 GTX 1060 或許適合你。如果你的錢不多,就買 GTX 1050 Ti 吧;如果你是一位計算機視覺研究人員,或許該入手 Titan X Pascal(或者就用現有的 GTX Titan Xs)。
總結性建議
總的說來較好的 GPU:Titan X Pascal 以及 GTX 1080 Ti
有成本效益但價格高的:GTX 1080 Ti, GTX 1070
有成本效益而且便宜:GTX 1060
用來處理大于 250G 數據集:常規 GTX Titan X 或者 Titan X Pascal
我錢不多:GTX 1060
我幾乎沒錢:GTX 1050 Ti
我參加 Kaggle 比賽: 用于任何常規比賽,GTX 1060 , 如果是深度學習比賽,GTX 1080Ti?
我是一名有競爭力的計算機視覺研究人員: Titan X Pascal 或常規 GTX Titan X
我是一名研究人員:GTX 1080 Ti. 有些情況下,比如自然語言處理任務,GTX 1070 或許是可靠的選擇——看一下你當前模型的存儲要求。
想建立一個 GPU 集群:這真的很復雜,你可以從這里得到一些思路:https://timdettmers.wordpress.com/2014/09/21/how-to-build-and-use-a-multi-gpu-system-for-deep-learning/
我剛開始進行深度學習,并且我是認真的:開始用 GTX 1060。根據你下一步的情況(創業?Kaggle 比賽?研究還是應用深度學習)賣掉你的 GTX 1060 然后買更適合使用目的的。?
原文地址:http://timdettmers.com/2017/03/19/which-gpu-for-deep-learning/
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4488.html
摘要:文章翻譯自深度學習是一個計算需求強烈的領域,的選擇將從根本上決定你的深度學習研究過程體驗。因此,今天就談談如何選擇一款合適的來進行深度學習的研究。此外,即使深度學習剛剛起步,仍然在持續深入的發展。例如,一個普通的在上的售價約為美元。 文章翻譯自:Which GPU(s) to Get for Deep Learning(http://t.cn/R6sZh27)深度學習是一個計算需求強烈的領域...
摘要:很明顯這臺機器受到了英偉達的部分啟發至少機箱是這樣,但價格差不多只有的一半。這篇個文章將幫助你安裝英偉達驅動,以及我青睞的一些深度學習工具與庫。 本文作者 Roelof Pieters 是瑞典皇家理工學院 Institute of Technology & Consultant for Graph-Technologies 研究深度學習的一位在讀博士,他同時也運營著自己的面向客戶的深度學習產...
摘要:幸運的是,這些正是深度學習所需的計算類型。幾乎可以肯定,英偉達是目前執行深度學習任務較好的選擇。今年夏天,發布了平臺提供深度學習支持。該工具適用于主流深度學習庫如和。因為的簡潔和強大的軟件包擴展體系,它目前是深度學習中最常見的語言。 深度學習初學者經常會問到這些問題:開發深度學習系統,我們需要什么樣的計算機?為什么絕大多數人會推薦英偉達 GPU?對于初學者而言哪種深度學習框架是較好的?如何將...
摘要:在兩個平臺三個平臺下,比較這五個深度學習庫在三類流行深度神經網絡上的性能表現。深度學習的成功,歸因于許多層人工神經元對輸入數據的高表征能力。在年月,官方報道了一個基準性能測試結果,針對一個層全連接神經網絡,與和對比,速度要快上倍。 在2016年推出深度學習工具評測的褚曉文團隊,趕在猴年最后一天,在arXiv.org上發布了的評測版本。這份評測的初版,通過國內AI自媒體的傳播,在國內業界影響很...
摘要:在本節中,我們將看到一些最流行和最常用的庫,用于機器學習和深度學習是用于數據挖掘,分析和機器學習的最流行的庫。愿碼提示網址是一個基于的框架,用于使用多個或進行有效的機器學習和深度學習。 showImg(https://segmentfault.com/img/remote/1460000018961827?w=999&h=562); 來源 | 愿碼(ChainDesk.CN)內容編輯...
閱讀 1377·2021-09-26 09:55
閱讀 1917·2019-08-30 12:45
閱讀 1055·2019-08-29 11:20
閱讀 3554·2019-08-26 11:33
閱讀 3411·2019-08-26 10:55
閱讀 1685·2019-08-23 17:54
閱讀 2381·2019-08-23 15:55
閱讀 2341·2019-08-23 14:23






