資訊專欄INFORMATION COLUMN

摘要:文章翻譯自深度學習是一個計算需求強烈的領域,的選擇將從根本上決定你的深度學習研究過程體驗。因此,今天就談談如何選擇一款合適的來進行深度學習的研究。此外,即使深度學習剛剛起步,仍然在持續深入的發展。例如,一個普通的在上的售價約為美元。
文章翻譯自:
Which GPU(s) to Get for Deep Learning(http://t.cn/R6sZh27)
深度學習是一個計算需求強烈的領域,GPU的選擇將從根本上決定你的深度學習研究過程體驗。在沒有GPU的情況下,等待一個實驗完成往往需要很長時間,可能是運行一天,幾天,幾個月或更長的時間。因此,選擇一個好的,合適的GPU,研究人員可以快速開始迭代深度學習網絡,幾個月的實驗可以在幾天之內跑完,幾天的實驗可以在幾個小時之內跑完。因此,在購買GPU時,正確的選擇至關重要。那么應該如何選擇適合的GPU呢?今天我們將深入探討這個問題,并會給出一些合適的建議,幫助你做出適合的選擇。
擁有高速GPU是開始學習深度學習的一個非常重要的方面,因為這可以幫助你快速獲得實踐經驗,這是搭建專業知識的關鍵,有足夠的時間將深度學習應用于解決新問題。如果沒有這種快速的反饋,就需要花費太多的時間從錯誤中學習。因此,今天就談談如何選擇一款合適的GPU來進行深度學習的研究。
首先給出一些總體的建議
較好的GPU整體(小幅度):Titan Xp
綜合性價比高,但略貴:GTX 1080 Ti,GTX 1070,GTX 1080
性價比還不錯且便宜:GTX 1060(6GB)
當使用數據集> 250GB:GTX Titan X(Maxwell) ,NVIDIA Titan X Pascal或NVIDIA Titan Xp
沒有足夠的錢:GTX 1060(6GB)
幾乎沒有錢:GTX 1050 Ti(4GB)
做Kaggle比賽:GTX 1060(6GB)適用于任何“正常”比賽,或GTX 1080 Ti用于“深度學習競賽”
計算機視覺研究員:NVIDIA Titan Xp;不要買現在新出的Titan X(Pascal或Maxwell)
一名研究員人員:GTX 1080 Ti。在某些情況下,如自然語言處理,一個GTX 1070或GTX 1080已經足夠了-檢查你現在模型的內存需求
搭建一個GPU集群:這個優點復雜,另做探討。
剛開始進行深度學習研究:從GTX 1060(6GB)開始。根據你下一步興趣(入門,Kaggle比賽,研究,應用深度學習)等等,在進行選擇。目前,GTX 1060更合適。
想嘗試下深度學習,但沒有過多要求:GTX 1050 ti(4或2GB)
應該選擇什么樣的GPU?NVIDIA GPU,AMD GPU或Intel Xeon Phi?
NVIDIA的標準庫使得基于CUDA來建立第一個深度學習庫變得非常容易,而AMD的OpenCL則沒有這樣強大的標準庫。現在,AMD卡沒有像這樣好的深度學習庫,所以就只有NVIDIA。即使未來有一些OpenCL庫可能也可用,但我也會堅持使用NVIDIA,因為GPU計算能力或GPGPU社區非常強大,可以持續促進CUDA的發展,而OpenCL則相對有限。因此,在CUDA社區中,很容易獲得不錯的開源解決方案和可靠的建議。
此外,即使深度學習剛剛起步,NVIDIA仍然在持續深入的發展。這個選擇得到了回報。而其他公司現在把錢和精力放在深度學習上,由于起步較晚,現在還是相對落后。目前,除NVIDIA-CUDA之外,其他很多軟硬件結合的深度學習方案都會遇到或多或少的問題。
至于英特爾的Xeon Phi處理方案,官方廣告宣稱編程者可以使用標準的C代碼進行開發,并很容易將代碼輕松轉換為經過加速的Xeon Phi代碼。這個特性聽起來很有趣,因為我們可以依靠豐富的C代碼資源。但是,實際上只有很小部分的C代碼是被支持的,所以這個特性目前并不是很有用,而且能夠運行的大部分C代碼都很慢。
給定預算下如何選擇最快的GPU
在選擇GPU時,首先要考慮的第一個GPU性能問題是什么呢:是否為cuda核心?時鐘速度多大?內存大小多少?
這些都不是,對于深度學習性能而言,最重要的特征是內存帶寬(memory bandwidth)。
簡而言之:GPU針對內存帶寬進行了優化,但同時犧牲了內存訪問時間(延遲)。CPU的設計恰恰相反:如果涉及少量內存(例如幾個數字相乘(3 * 6 * 9)),CPU可以快速計算,但是對于大量內存(如矩陣乘法(A * B * C)則很慢。由于內存帶寬的限制,當涉及大量內存的問題時,GPU快速計算的優勢往往會受到限制。當然,GPU和CPU之間還有更復雜的區別,關于為何GPU如此適用于處理深度學習問題,另做探討。
所以如果你想購買一個快速的GPU,首先要關注的是GPU的帶寬(bandwidth)。
通過內存帶寬評估GPU的性能
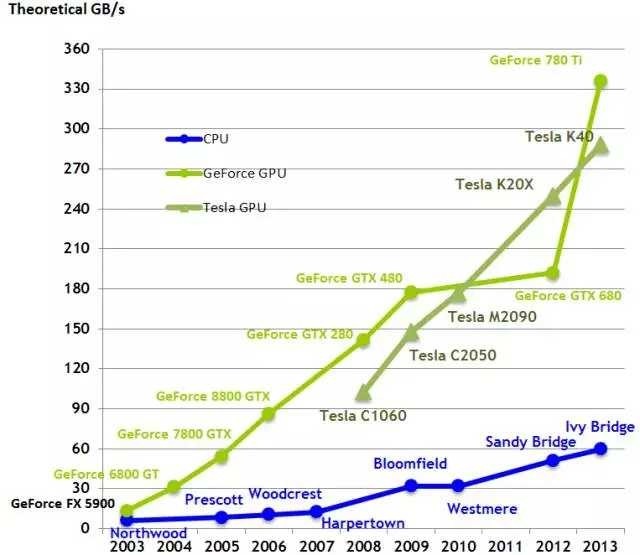
隨著時間的變化,CPU和GPU的帶寬比較:帶寬是GPU比CPU更快的主要原因之一。
帶寬可以直接在芯片的體系結構上進行比較,例如像GTX 1080和GTX 1070這樣的Pascal卡,其性能可以直接通過多帶帶查看內存帶寬進行比較。例如,GTX 1080(320GB / s)比GTX 1070(256 GB / s)快25%(320/256)。然而,不同的結構,例如像GTX 1080與GTX Titan X之類的Pascal與Maxwell不能直接比較,因為不同制造工藝(以納米為單位),導致不同的架構對于如何利用給定的內存帶寬的方式不同。這使得一切都有點棘手,但僅僅基于整體帶寬就能讓我們很好地評價GPU的速度到底有多快。為了確定在一個給定的條件下,一款GPU最快能多快,可以查看這個維基百科頁面,以GB / s為單位查看帶寬;這里列出的關于這些新卡(900和1000系列)的價格是相當準確,但較舊的卡明顯比較便宜 - 特別是如果你通過eBay購買這些卡。例如,一個普通的GTX Titan X在eBay上的售價約為550美元。
另一個需要考慮的重要因素是,并不是所有的架構都與cuDNN兼容。由于幾乎所有深度學習庫都使用cuDNN進行卷積運算,這就限制GPU的選擇只能是Kepler GPU或更高的版本,即GTX 600系列或更高版本。最重要的是,Kepler GPU一般都很慢。所以這意味著應該選擇GTX 900或1000系列的GPU,以獲得更好的性能。
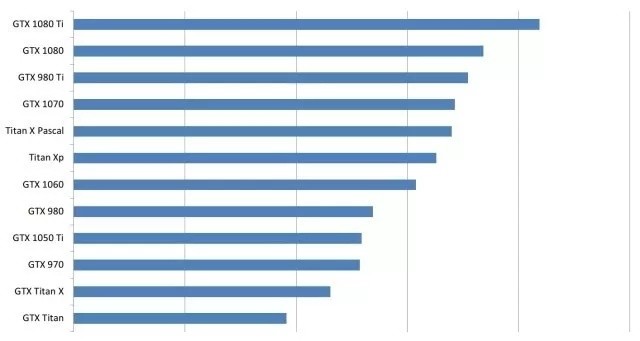
為了粗略地估計一下這些卡在深度學習任務上的表現,我構建了一個簡單的GPU等值圖。如何閱讀這個?例如,一個GTX 980與0.35 Titan X Pascal一樣快,或者換句話說,Titan X Pascal幾乎是GTX 980的三倍。
請注意,我自己并沒有所有的這些卡,我并沒有在所有這些卡上運行然后得到深度學習的benchemarks。比較的結果通過卡片規格以及一些可得到的計算benchmarks(一些用于加密貨幣挖掘的情況,這一性能在深度學習相關的計算能力上是可比較的)得出的。所以這些結果粗略的估計。實際的數字可能會有所不同,但通常錯誤應該是比較小的,卡的順序應該是正確的。另外請注意,那些不足以充分利用GPU性能的小型網絡會讓GPU的性能看上去不好。例如,GTX 1080 Ti上的小型LSTM(128個隱藏單元;批量大小> 64)不會比在GTX 1070上運行速度快很多。為了獲得圖下表中顯示的性能差異,需要運行更大的網絡,比如具有1024個隱單元的LSTM(批量大小> 64)。
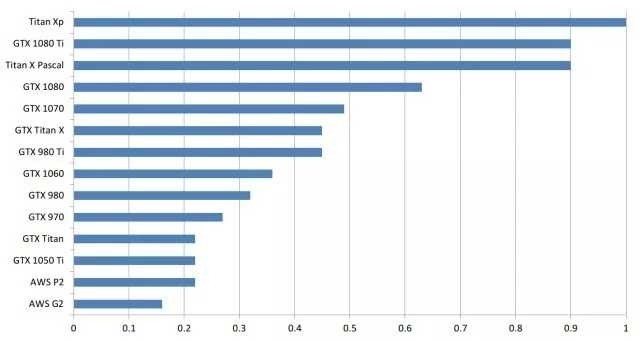
GPU之間粗略的性能比較。此比較建立于充分利用GPU性能情況下。
性價比分析
基于上面繪制的性能比較圖,除以它們對應的價格,得到下圖的基于成本的排名,越長代表性價比越高,該圖某種程度上反映了不同卡之間的性價比差異。
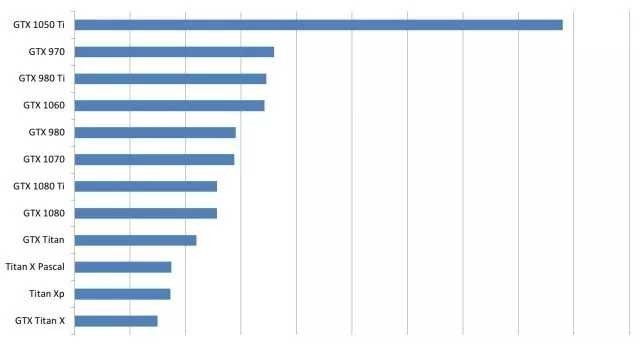
成本效益對比圖。請注意,這個數字在很多方面都有偏差,例如它沒有考慮到內存。
但請注意,這種對GPU排名的衡量標準考慮并不全面。首先,沒有考慮GPU的內存大小。從上面的圖看,GTX 1050 Ti性價比較高,但當實際應用中你說需要的內存超過了1050 Ti所能提供的內存時,也不能用。類似地,使用4個小的GPU比僅使用1個大得GPU要復雜的多,因此小型GPU也有很多不足之處。此外,不能通過購買16 GTX 1050 Ti來獲得4 GTX 1080 Ti的性能,因為還需要購買3臺額外的昂貴的電腦。如果考慮這最后一點,即GPU的內存大小,得到下圖所示性價比分析圖。
綜合考慮其他硬件的價格(比如搭載GPU的電腦價格),對GPU的性價比進行標準化。在這里,比較了一臺完整的機器,包含4個GPU,配置價值約1500美元的其他高端硬件(CPU,主板等)條件下。
因此,在這種情況下,如果您想要購買更多的GPU,毫無疑問,內存越大的GPU性價比越高,因為相同內存需求條件下,不需要買更多的機器。但是,這種對GPU選擇方法仍然存在缺陷。如果你預算金額有限,沒有辦法無法負擔4 GTX 1080 Ti機器的價格,這種對比就毫無意義。因此,實際情況是,基于你有限的預算下,你可以購買到的哪種系統性能是較好的?同時,你還必須處理其他問題,例如:每天使用此GPU的時間有多長?想在幾年內升級GPU或整個計算機?想在未來多長一段時間內賣掉當前的GPU,并購買新的更好的GPU?等等
所以你可以看到,做出正確的選擇并不容易。但是,如果你對所有這些問題平衡的看待,就會得出類似于以下的這些結論。
一般的GPU選擇建議
一般來說,我會推薦GTX 1080 Ti,GTX 1080或GTX 1070.他們都是優秀的顯卡,如果你有錢,應該購買GTX 1080 Ti。GTX 1070比普通的GTX Titan X(Maxwell)便宜一些。GTX 1080的性價比比GTX 1070低一些,但是自GTX 1080 Ti推出以來,價格大幅下滑,現在GTX 1080的性價比已經能夠與GTX 1070比擬。所有這三款顯卡應該比GTX 980 Ti要好,因為它們具有11GB和8GB(而不是6GB)的內存。
8GB的內存可能看起來有點小,但是對于許多任務來說這已經足夠了。例如對于Kaggle比賽,大多數圖像數據,deep style和自然語言理解任務,這些你可能會遇到幾個問題。
對于入門級的人來或是偶爾想用GPU來參加類似Kaggle比賽的人,GTX 1060是一個不錯的選擇。我不推薦內存只有3GB的GTX 1060 variant產品,因為6G的內存就已經很有限了。但是,對于許多應用來說,6GB就足夠了。GTX 1060比普通的Titan X慢,但與GTX 980具有可比的性價比。
就綜合性價比而言,10系列設計得非常好。GTX 1050 Ti,GTX 1060,GTX 1070,GTX 1080和GTX 1080 Ti都非常出色。GTX 1060和GTX 1050 Ti適用于初學者,GTX 1070和GTX 1080是適合于初創公司,部分研究和工業部門,而性能突出的GTX 1080 Ti,對于以上應用都合適。
不推薦NVIDIA Titan Xp,因為它的性價比太昂貴了。可以用GTX 1080 Ti代替。然而,NVIDIA Titan Xp在計算機視覺研究領域中仍然有一定的使用,用于處理大數據集或視頻數據。在這些領域中,按照每GB的內存數量計算,NVIDIA Titan Xp只比GTX 1080 Ti多1GB,但在這種情況下也具有一定的優勢。不推薦NVIDIA Titan X(Pascal),因為NVIDIA Titan Xp速度更快,但價格幾乎相同。但由于市場上這些GPU的稀缺性,如果你找不到NVIDIA Titan Xp,也可以購買Titan X(Pascal)。
如果你已經有了GTX Titan X(Maxwell)GPU,那么升級到NVIDIA Titan X(Pascal)或NVIDIA Titan Xp就沒有必要了。
如果你缺錢,但是你需要12GB內存來開展你的研究,那么GTX Titan X(Maxwell)也是一個很好的選擇。
對于大多數研究人員來說,GTX 1080 Ti已經完全夠用了。大多數研究和大多數應用,GTX 1080 Ti的內存完全夠用。
在NLP中,內存限制并不像計算機視覺領域那么嚴格,所以GTX 1070 / GTX 1080也是不錯的選擇。通常是,需要解決什么樣的任務以及如何進行試驗,決定了需要選擇哪一款GPU,無論是GTX 1070還是GTX 1080。當你選擇GPU時,應該按照類似的方式推理。考慮一下你在做什么任務,如何運行你的實驗,然后嘗試找到適合這些要求的GPU。
對于預算有限的人來說,選擇條件則更加有限。亞馬遜網絡服務上的GPU相當昂貴和緩慢,如果只有少量的資金,也是一個不錯的選擇。我不推薦GTX 970,因為它很慢,即使在某些限制條件下也是相當昂貴的(在eBay上150美元),并且存在與卡啟動相關的內存問題。相反,建議花更多一點的錢購買更快,有更大的內存,沒有內存問題的GTX 1060。如果實在買不起GTX 1060,我建議選擇配備4GB內存的GTX 1050 Ti。4GB內存可能有限,但至少可以開展進行你的研究,只是需要你對模型進行一些調整,也可以得到良好的性能。
GTX 1050 Ti一般來說也是一個不錯的選擇,如果你只是想嘗試一下深度學習,而沒有其他更多的需求。
結論
有了這篇文章中提供的所有信息,你應該能夠考慮選擇哪一種合適的GPU,綜合考慮所需的內存大小,帶寬(GB/s)大小和GPU的價格,這一思路在未來很久也適用。最后,如果有足夠的資金,建議購買GTX 1080 Ti,GTX 1070或者GTX 1080。如果剛剛開始研究深度學習,或者資金有限,可以購買GTX 1060。如果資金實在有限,可以購買GTX 1050 ti;如果想要從事計算機視覺研究,可以購買Titan Xp。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4650.html
摘要:年月日,機器之心曾經推出文章為你的深度學習任務挑選最合適從性能到價格的全方位指南。如果你想要學習深度學習,這也具有心理上的重要性。如果你想快速學習深度學習,多個廉價的也很好。目前還沒有適合顯卡的深度學習庫所以,只能選擇英偉達了。 文章作者 Tim Dettmers 系瑞士盧加諾大學信息學碩士,熱衷于開發自己的 GPU 集群和算法來加速深度學習。這篇博文最早版本發布于 2014 年 8 月,之...
摘要:在兩個平臺三個平臺下,比較這五個深度學習庫在三類流行深度神經網絡上的性能表現。深度學習的成功,歸因于許多層人工神經元對輸入數據的高表征能力。在年月,官方報道了一個基準性能測試結果,針對一個層全連接神經網絡,與和對比,速度要快上倍。 在2016年推出深度學習工具評測的褚曉文團隊,趕在猴年最后一天,在arXiv.org上發布了的評測版本。這份評測的初版,通過國內AI自媒體的傳播,在國內業界影響很...
摘要:深度學習是一個對算力要求很高的領域。這一早期優勢與英偉達強大的社區支持相結合,迅速增加了社區的規模。對他們的深度學習軟件投入很少,因此不能指望英偉達和之間的軟件差距將在未來縮小。 深度學習是一個對算力要求很高的領域。GPU的選擇將從根本上決定你的深度學習體驗。一個好的GPU可以讓你快速獲得實踐經驗,而這些經驗是正是建立專業知識的關鍵。如果沒有這種快速的反饋,你會花費過多時間,從錯誤中吸取教訓...
摘要:而道器相融,在我看來,那煉丹就需要一個好的丹爐了,也就是一個優秀的機器學習平臺。因此,一個機器學習平臺要取得成功,最好具備如下五個特點精辟的核心抽象一個機器學習平臺,必須有其靈魂,也就是它的核心抽象。 *本文首發于 AI前線 ,歡迎轉載,并請注明出處。 摘要 2017年6月,騰訊正式開源面向機器學習的第三代高性能計算平臺 Angel,在GitHub上備受關注;2017年10月19日,騰...

閱讀 1829·2021-11-11 16:54
閱讀 2055·2019-08-30 15:56
閱讀 2364·2019-08-30 15:44
閱讀 1280·2019-08-30 15:43
閱讀 1855·2019-08-30 11:07
閱讀 812·2019-08-29 17:11
閱讀 1464·2019-08-29 15:23
閱讀 3006·2019-08-29 13:01