資訊專欄INFORMATION COLUMN

摘要:在最近的一次人工智能會議上,表示自己對于反向傳播非常懷疑,并提出應該拋棄它并重新開始。在人工智能多年的發(fā)展過程中,反向傳播已經(jīng)成為了深度學習不可或缺的一部分。最后,我們會將這些規(guī)則組合成可用于任意神經(jīng)網(wǎng)絡(luò)的反向傳播算法。
現(xiàn)在的深度學習發(fā)展似乎已經(jīng)陷入了大型化、深度化的怪圈,我們設(shè)計的模型容易被對抗樣本欺騙,同時又需要大量的訓練數(shù)據(jù)——在無監(jiān)督學習上我們?nèi)〉玫耐黄七€很少。作為反向傳播這一深度學習核心技術(shù)的提出者之一,Geoffrey Hinton 很早就意識到反向傳播并不是自然界生物大腦中存在的機制。那么,在技術(shù)上,反向傳播還有哪些值得懷疑的地方?
反向傳播的可疑之處
Geoffrey Hinton 對人工智能的未來非常擔憂。在最近的一次人工智能會議上,Hinton 表示自己對于反向傳播「非常懷疑」,并提出「應該拋棄它并重新開始」。
在人工智能多年的發(fā)展過程中,反向傳播已經(jīng)成為了深度學習不可或缺的一部分。研究人員發(fā)現(xiàn),只要層是可微分的,我們就可以在求解時使用任何計算層。換句話說,層的梯度是可以被計算的。更為清楚地說,在尋物游戲中,準確表現(xiàn)出被蒙住眼睛的玩家與他的目標之間的距離。
在反向傳播上,存在著幾個問題:第一個是計算出來的梯度是否真的是學習的正確方向。這在直觀上是可疑的。人們總是可以尋找到某些看起來可行的方向,但這并不總是意味著它最終通向問題的解。所以,忽略梯度或許也可以讓我們找到解決方案(當然,我們也不能永遠忽略梯度)。適應性方法和優(yōu)化方法之間存在著很多不同。
現(xiàn)在,讓我們回顧一下反向傳播思想的起源。歷史上,機器學習起源于曲線擬合的整體思路。在線性回歸的具體情況下(如對一條線進行擬合預測),計算梯度是求解最小二乘問題。在優(yōu)化領(lǐng)域,除了使用梯度找到最優(yōu)解之外,還有許多其他方法。不過,事實上,隨機梯度下降可能是最基本的優(yōu)化方法之一。所以它只是我們能想到的很多方法中更為簡單的一個,雖然也非常好用。
大多數(shù)研究優(yōu)化的學者很長一段時間以來都認為深度學習的高維空間需要非凸解,因此非常難以優(yōu)化。但是,由于一些難以解釋的原因。深度學習使用隨機梯度下降(SGD)的效果卻非常好。許多研究人員對于為什么深度學習用 SGD 優(yōu)化如此簡單提出了不同解釋,其中最具說服力的說法是這種方法傾向于找到真正的鞍點——而不是小范圍內(nèi)的谷地。使用這種方法的情況下,總是有足夠的維度讓我們找到最優(yōu)解。
一張指導圖,防止迷失
DeepMind 研究的合成梯度是一種解耦層方法,以便于我們不總是需要反向傳播,或者梯度計算可推遲。這種方法同樣非常有效。這一發(fā)現(xiàn)可能也是一種暗示,正在產(chǎn)生更通用的方法。好像關(guān)于這個方向的任何升級都是有益的(隨意提了一下合成梯度),不管效果是不是一樣。
還有一個使用目標函數(shù)的典型問題:反向傳播是相對于目標函數(shù)計算的。通常,目標函數(shù)是預測分布與實際分布之間差異的量度。通常,它是從 Kullback-Liebler 散度衍生出來的,或者是像 Wassertsein 這樣的其他相似性分布數(shù)值。但是,在這些相似性計算中,「標簽」是監(jiān)督訓練必不可少的一部分。在 Hinton 拋出反向傳播言論的同時,他也對于監(jiān)督學習發(fā)表了自己的看法:「我認為這意味著放棄反向傳播……我們確實不需要所有數(shù)據(jù)都有標簽。」
簡而言之,沒有目標函數(shù)就無法進行反向傳播。如果你無法評估預測值和標簽(實際或訓練數(shù)據(jù))的 value 值,你就沒有目標函數(shù)。因此,為了實現(xiàn)「無監(jiān)督學習」,你需要拋棄計算梯度的能力。
但是,在我們把這一重要能力丟掉之前,先從更通用的角度看一下目標函數(shù)的目的。目標函數(shù)是對自動化內(nèi)部模型預測所處環(huán)境的準確率的評估。任何智能自動化的目的都是構(gòu)建準確率高的內(nèi)部模型。但是,模型和它一直或持續(xù)所處的環(huán)境之間不需要任何評估。也就是說,自動化不需要執(zhí)行反向傳播進行學習。自動化可以通過其他途徑改善其內(nèi)部模型。
其他途徑就是「想象力」(imagination)或「做夢」(dreaming),不用立刻把預測與事實對比然后更新參數(shù)。今天最接近的體現(xiàn)就是生成對抗網(wǎng)絡(luò)(GAN)。GAN 包括兩個網(wǎng)絡(luò):生成器和鑒別器。你可以把鑒別器當作使用目標函數(shù)的神經(jīng)網(wǎng)絡(luò),即它可以用現(xiàn)實驗證內(nèi)部生成器網(wǎng)絡(luò)。生成器自動化創(chuàng)造近似現(xiàn)實。GAN 網(wǎng)絡(luò)使用反向傳播,執(zhí)行無監(jiān)督學習。因此,無監(jiān)督學習可能不需要目標函數(shù),但它或許仍然需要反向傳播。
看待無監(jiān)督學習的另一種方式是,某種程度上,它是一種元學習。系統(tǒng)不需要監(jiān)督訓練數(shù)據(jù)的一種可能原因是學習算法已經(jīng)開發(fā)出自己的較佳內(nèi)部模型。也就是說,仍然存在一定程度的監(jiān)督,只不過在學習算法中更加隱晦。學習算法如何具備這種能力尚不可知。
總之,現(xiàn)在判斷我們是否可以拋棄反向傳播還為時尚早。我們當然可以使用沒有那么嚴格的反向傳播(即合成梯度或其他啟發(fā))。但是,逐步學習(或稱爬山法)仍然是必要的。我當然對找到駁斥逐步學習或爬山法的研究很感興趣。這實際上可以類比為宇宙的運行,具體來說就是熱力學的第二定律。再具體點就是熵一直在提高。信息引擎將降低熵,以交換所處環(huán)境中的熵提高。因此,沒有一種方法可以完全避免梯度,除非存在「永動信息機器」(perpetual motion information machine)。
Hinton 與他的谷歌同事 Sara Sabour 和 Nicholas Frosst 共同完成的論文《Dynamic Routing Between Capsules》已被 NIPS 2017 大會接收,他們在研究中提出的 capsule 概念正是 Hinton 對于未來人工智能形態(tài)的探索。不可否認的是,在無監(jiān)督學習的道路上,我們還有很長的一段路要走。
反向傳播的推導過程
神經(jīng)網(wǎng)絡(luò)在權(quán)重的變化和目標函數(shù)的變化之間不再是線性關(guān)系。在特定層級的任何擾動(perturbation)將會在連續(xù)層級中進一步變化。那么,我們該如何計算神經(jīng)網(wǎng)絡(luò)中所有權(quán)重的梯度,從而進一步使用梯度下降法(最速下降法)呢?這也就是我們?yōu)槭裁匆褂梅聪騻鞑ニ惴ǖ牡胤健7聪騻鞑ニ惴ǖ暮诵募磳φ麄€網(wǎng)絡(luò)所有可能的路徑重復使用鏈式法則。反向傳播算法真正強大的地方在于它是動態(tài)規(guī)劃的,我們可以重復使用中間結(jié)果計算梯度下降。因為它是通過神經(jīng)網(wǎng)絡(luò)由后向前傳播誤差,并優(yōu)化每一個神經(jīng)節(jié)點之間的權(quán)重,所以這種算法就稱之為反向傳播算法(backpropagation algorithm)。實際上神經(jīng)網(wǎng)絡(luò)反向傳播與前向傳播有緊密的聯(lián)系,只不過反向傳播算法不是通過神經(jīng)網(wǎng)絡(luò)由前向后傳播數(shù)據(jù),而是由后向前傳播誤差。
大多數(shù)反向傳播算法的解釋都是直接從一般理論推導開始,但是如果從手動計算梯度開始,那么就能很自然地推導出反向傳播算法本身。雖然下面的推導部分較長,但我們認為從數(shù)學基本理論開始是較好的方式來了解反向傳播算法。
下文由單路徑神經(jīng)網(wǎng)絡(luò)開始,進而推廣到存在多層和多個神經(jīng)元的神經(jīng)網(wǎng)絡(luò),最后再推導出一般的反向傳播算法。
反向傳播算法的基本原則
我們訓練神經(jīng)網(wǎng)絡(luò)的最終目標是尋找損失函數(shù)關(guān)于每一個權(quán)重的梯度:
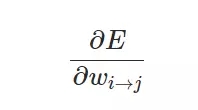
當我們計算出偏導數(shù)時就能進一步使用隨機梯度下降或小批量梯度下降更新每一層神經(jīng)網(wǎng)絡(luò)的權(quán)重:
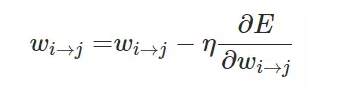
通常在一般神經(jīng)網(wǎng)絡(luò)的每一個單元會存在以下幾種情況:
該神經(jīng)元有且僅有一個輸入和一個輸出
該神經(jīng)元有多個輸入
該神經(jīng)元有多個輸出
該神經(jīng)元有多個輸入和輸出
因為多輸入與多輸出是獨立的,我們能自由組合輸入與輸出神經(jīng)元的數(shù)量。
這一部分將從相對簡單的結(jié)構(gòu)到多層神經(jīng)網(wǎng)絡(luò),并在這個過程中推導出用于反向傳播的一般規(guī)則。最后,我們會將這些規(guī)則組合成可用于任意神經(jīng)網(wǎng)絡(luò)的反向傳播算法。
單一輸入與單一輸出的神經(jīng)元
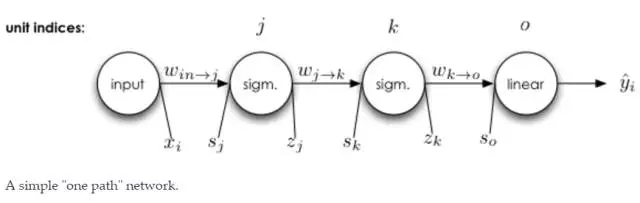
在上面的神經(jīng)網(wǎng)絡(luò)中,每一個變量都能夠準確地寫出來。
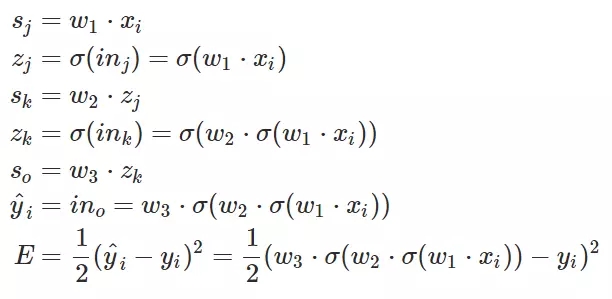
注意,上面方程式中 x 是輸入,w 是權(quán)重,Sigamm 是神經(jīng)元的激活函數(shù)。s 是前一個神經(jīng)元通過權(quán)重傳遞到后一個神經(jīng)元的數(shù)據(jù),它等于前一個神經(jīng)元的輸出乘以兩個神經(jīng)元的連接強度,即權(quán)重 w。z 是神經(jīng)元輸入經(jīng)過激活函數(shù) Sigamma 計算后得到的輸出。

E 就相當于系統(tǒng)做出的判斷與正確標注之間的損失。E 對權(quán)重 w 求偏導并最小化,即在損失函數(shù) E 最小的情況下求得權(quán)重 w,上述方程式表明需要求得 k 神經(jīng)元到 o 神經(jīng)元之間最優(yōu)權(quán)重 w。
那么從 j 到 k 和從 i 到 j 的權(quán)重更新都是相同的步驟了。
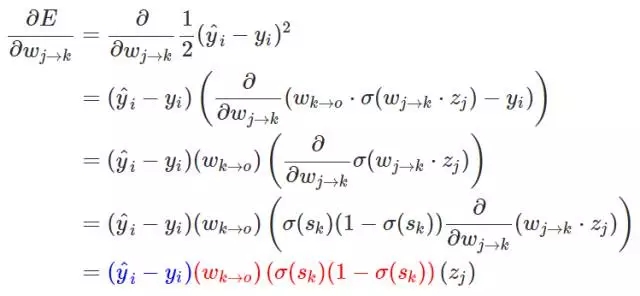
上面的推導表達式展示了損失函數(shù)對第 j 層和第 k 層之間權(quán)重的偏導數(shù),而下面的推導表達式則展示了損失函數(shù)對第 i 層和第 j 層之間權(quán)重的偏導數(shù):
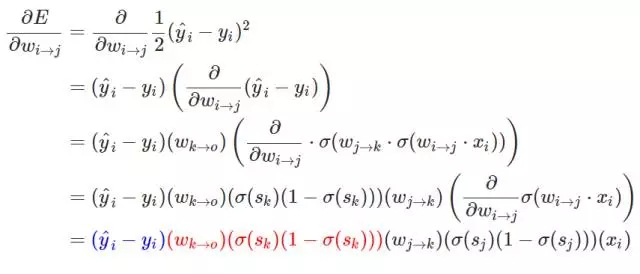
現(xiàn)在也許我們能總結(jié)一個可以使用反向傳播算法的權(quán)重更新模式。當我們計算神經(jīng)網(wǎng)絡(luò)前面層級的權(quán)重更新時,我們重復使用了多個數(shù)值。具體來說,我們觀察到的就是神經(jīng)網(wǎng)絡(luò)損失函數(shù)的偏導數(shù),上面三個推導表達式可以總結(jié)為:
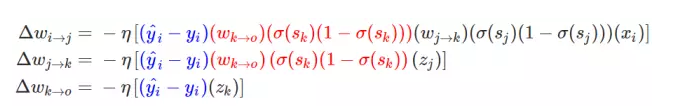
在上述方程式中由后一個神經(jīng)元向前推導,最后一層的權(quán)重更新梯度最簡單,而前面層級的更新梯度則需要向前推導,這一推導的過程或者方式就是根據(jù)求導的鏈式法則。
多個輸入
可以思考一下稍微復雜一點的神經(jīng)網(wǎng)絡(luò),即一個神經(jīng)元將有多個輸入:
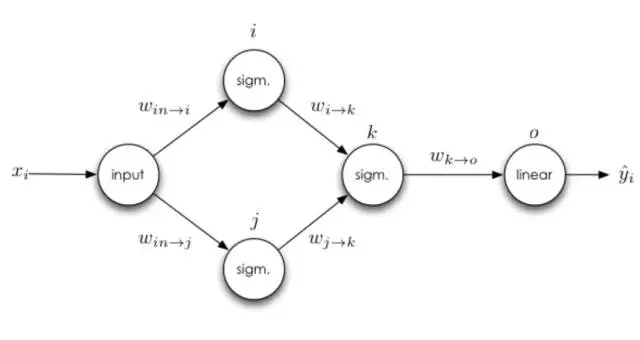
如果一個神經(jīng)元有多個輸入端怎么辦,從 j 到 k 的權(quán)重更新規(guī)則會不會影響從 i 到 k 的權(quán)重更新規(guī)則?為了弄清這個問題,我們可以對 i 到 k 的權(quán)重手動求導。

我們可以從上面看到從 i 到 k 的權(quán)重更新是不依賴于從 j 到 k 權(quán)重的導數(shù)的,因此第一條準測就是損失函數(shù)對權(quán)重的導數(shù)不依賴于同層級神經(jīng)網(wǎng)絡(luò)上的其他任何權(quán)重的導數(shù),所以神經(jīng)網(wǎng)絡(luò)同層級的權(quán)重可以獨立地更新。同時該法則還存在更新的自然順序,這種自然順序僅僅只依賴于神經(jīng)網(wǎng)絡(luò)同一層級其他權(quán)重的值,這種排序是反向傳播算法的計算基礎(chǔ)。
多個輸出
接下來我們可以思考下有多個輸出的隱藏層神經(jīng)元。
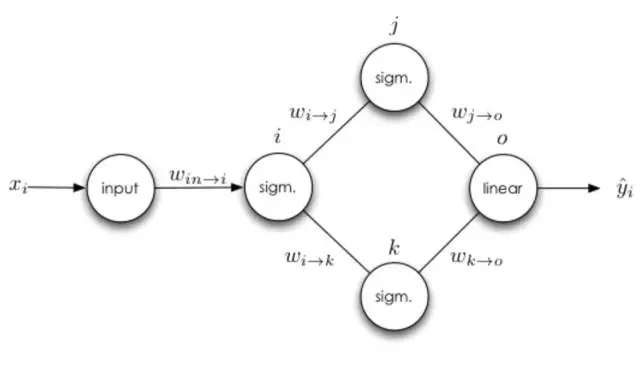
在前面的基礎(chǔ)上,和前面權(quán)重更新有差別的是輸入神經(jīng)元與 i 神經(jīng)元之間的求導法則。神經(jīng)元多輸出端的情況就是其有多個直接后繼神經(jīng)元,所以我們必須沿著以神經(jīng)元 i 為根結(jié)點的所有路徑來計算誤差的總和。接下來我們可以詳細地寫出損失函數(shù)對權(quán)重求導而更新的過程,并且我們定義σ(?) 就是神經(jīng)元 i 的激活函數(shù):

現(xiàn)在有兩點需要注意,首先就是第二條推導準則:具有多個輸出的神經(jīng)元權(quán)重更新依賴于所有可能路徑上的導數(shù)。
但是更重要地是我們需要看到反向傳播算法和正向傳播算法之間的聯(lián)系。在反向傳播的過程中,我們會計算神經(jīng)網(wǎng)絡(luò)輸出端的誤差,我們會把這些誤差反向傳播并且沿著每條路徑加權(quán)。當我們傳播到了一個神經(jīng)元,可以將經(jīng)權(quán)重反向傳播過來的誤差乘以神經(jīng)元的導數(shù),然后就可以同樣的方式反向傳播誤差,一直追溯到輸入端。反向傳播非常類似于正向傳播,是一種遞歸算法。接下來會介紹誤差信號,然后再改寫我們的表達式。
誤差信號


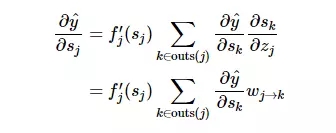

現(xiàn)在我們能用緊湊的方程式表征反向傳播誤差。
反向傳播算法的普遍形式
先回憶下第一部分的簡單神經(jīng)網(wǎng)絡(luò):
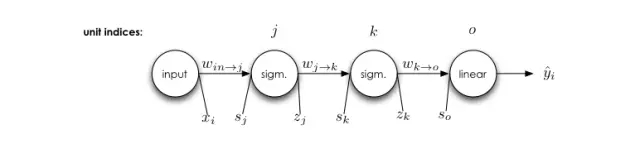
我們能使用 δ_i 的定義導出整個神經(jīng)網(wǎng)絡(luò)的所有誤差信號:

在這一個神經(jīng)網(wǎng)絡(luò)中,準確的權(quán)重更新模式是以下方程式:

還有另外一個復雜一點的神經(jīng)網(wǎng)絡(luò),即有多個輸出神經(jīng)元:
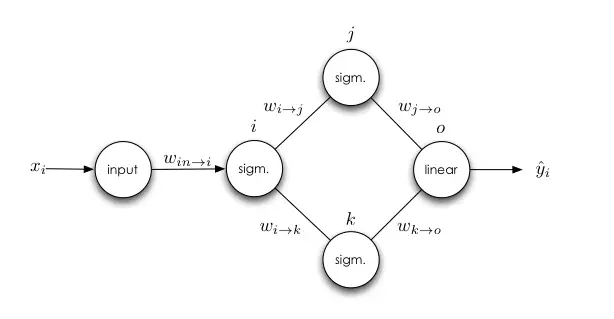
同樣我們能得出所有的誤差信號:
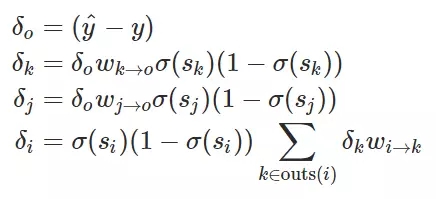
然后我們再一次將誤差代入到權(quán)重更新方程式中:
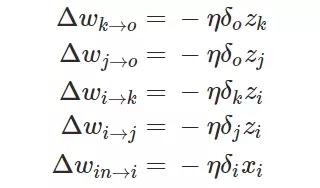
現(xiàn)在也許我們就可以推導出權(quán)重更新的簡單通用形式:

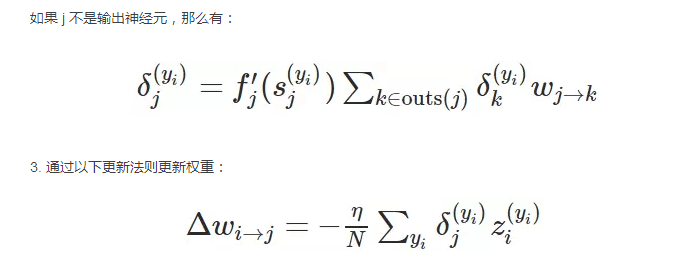
上面是一般反向傳播算法的推導和建立過程,我們從最簡單與直覺的概念一步步完善并推導出最后的更新規(guī)則。雖然反向傳播算法有著很多的局限性與不足,并且也有學者提出如解耦方法等理論解決反向傳播算法的不足,但反向傳播算法仍然是目前神經(jīng)網(wǎng)絡(luò)中最主流與強大的最優(yōu)化方法。最后我們同樣期待 Hinton 等人所提出的capsule能對反向傳播算法有本質(zhì)上的提升!
原文鏈接:
https://medium.com/intuitionmachine/the-deeply-suspicious-nature-of-backpropagation-9bed5e2b085e
http://briandolhansky.com/blog/2013/9/27/artificial-neural-networks-backpropagation-part-4
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4649.html
摘要:論文鏈接會上其他科學家認為反向傳播在人工智能的未來仍然起到關(guān)鍵作用。既然要從頭再來,的下一步是什么值得一提的是,與他的谷歌同事和共同完成的論文已被大會接收。 三十多年前,深度學習著名學者 Geoffrey Hinton 參與完成了論文《Experiments on Learning by Back Propagation》,提出了反向傳播這一深刻影響人工智能領(lǐng)域的方法。今天的他又一次呼吁研究...
摘要:然而反向傳播自誕生起,也受到了無數(shù)質(zhì)疑。主要是因為,反向傳播機制實在是不像大腦。他集結(jié)了來自和多倫多大學的強大力量,對這些替代品進行了一次評估。號選手,目標差傳播,。其中來自多倫多大學和,一作和來自,來自多倫多大學。 32年前,人工智能、機器學習界的泰斗Hinton提出反向傳播理念,如今反向傳播已經(jīng)成為推動深度學習爆發(fā)的核心技術(shù)。然而反向傳播自誕生起,也受到了無數(shù)質(zhì)疑。這些質(zhì)疑來自各路科學家...
摘要:在最近的一次大會上,表示,他對反向傳播深表懷疑,并認為我的觀點是將它完全摒棄,然后重新開始。相對于對象函數(shù)計算反向傳播。通常,目標函數(shù)是預測分布與實際分布之間差異的量度。所以也許無監(jiān)督的學習不需要目標函數(shù),但是它仍然可能需要反向傳播。 Geoffrey Hinton終于公開闡述了他對那些早已令許多人惶恐不安的事物的看法。在最近的一次AI大會上,Hinton表示,他對反向傳播深表懷疑,并認為:...
摘要:主流機器學習社區(qū)對神經(jīng)網(wǎng)絡(luò)興趣寡然。對于深度學習的社區(qū)形成有著巨大的影響。然而,至少有兩個不同的方法對此都很有效應用于卷積神經(jīng)網(wǎng)絡(luò)的簡單梯度下降適用于信號和圖像,以及近期的逐層非監(jiān)督式學習之后的梯度下降。 我們終于來到簡史的最后一部分。這一部分,我們會來到故事的尾聲并一睹神經(jīng)網(wǎng)絡(luò)如何在上世紀九十年代末擺脫頹勢并找回自己,也會看到自此以后它獲得的驚人先進成果。「試問機器學習領(lǐng)域的任何一人,是什...
摘要:的研究興趣涵蓋大多數(shù)深度學習主題,特別是生成模型以及機器學習的安全和隱私。與以及教授一起造就了年始的深度學習復興。目前他是僅存的幾個仍然全身心投入在學術(shù)界的深度學習教授之一。 Andrej Karpathy特斯拉 AI 主管Andrej Karpathy 擁有斯坦福大學計算機視覺博士學位,讀博期間師從現(xiàn)任 Google AI 首席科學家李飛飛,研究卷積神經(jīng)網(wǎng)絡(luò)在計算機視覺、自然語言處理上的應...

閱讀 3126·2021-09-28 09:42
閱讀 3459·2021-09-22 15:21
閱讀 1132·2021-07-29 13:50
閱讀 3585·2019-08-30 15:56
閱讀 3376·2019-08-30 15:54
閱讀 1203·2019-08-30 13:12
閱讀 1184·2019-08-29 17:03
閱讀 1207·2019-08-29 10:59






