資訊專欄INFORMATION COLUMN

摘要:主流機器學習社區對神經網絡興趣寡然。對于深度學習的社區形成有著巨大的影響。然而,至少有兩個不同的方法對此都很有效應用于卷積神經網絡的簡單梯度下降適用于信號和圖像,以及近期的逐層非監督式學習之后的梯度下降。
我們終于來到簡史的最后一部分。這一部分,我們會來到故事的尾聲并一睹神經網絡如何在上世紀九十年代末擺脫頹勢并找回自己,也會看到自此以后它獲得的驚人先進成果。
「試問機器學習領域的任何一人,是什么讓神經網絡研究進行下來,對方很可能提及這幾個名字中的一個或全部: Geoffrey Hinton,加拿大同事Yoshua Bengio 以及臉書和紐約大學的Yann LeCun。」
深度學習的密謀
當你希望有一場革命的時候,那么,從密謀開始吧。隨著支持向量機的上升和反向傳播的失敗,對于神經網絡研究來說,上世紀早期是一段黑暗的時間。Lecun與Hinton各自提到過,那時他們以及他們學生的論文被拒成了家常便飯,因為論文主題是神經網絡。上面的引文可能夸張了——當然機器學習與AI的研究仍然十分活躍,其他人,例如Juergen Schmidhuber也正在研究神經網絡——但這段時間的引用次數也清楚表明興奮期已經平緩下來,盡管還沒有完全消失。在研究領域之外,他們找到了一個強有力的同盟:加拿大政府。CIFAR的資助鼓勵還沒有直接應用的基礎研究,這項資助首先鼓勵Hinton于1987年搬到加拿大,然后一直資助他的研究直到九十年代中期。…Hinton 沒有放棄并改變他的方向,而是繼續研究神經網絡,并努力從CIFAR那里獲得更多資助,正如這篇例文(http://www.thestar.com/news/world/2015/04/17/how-a-toronto-professors-research-revolutionized-artificial-intelligence.html)清楚道明的:
「但是,在2004年,Hinton要求領導一項新的有關神經計算的項目。主流機器學習社區對神經網絡興趣寡然。」
「那是最不可能的時候」Bengio是蒙特利爾大學的教授,也是去年重新上馬的CIFAR項目聯合主管,「其他每個人都在做著不同的事。莫名其妙地,Geoff說服了他們。」
「我們應該為了他們的那場豪賭大力贊許CIFAR。」
CIFAR「對于深度學習的社區形成有著巨大的影響。」LeCun補充道,他是CIFAR項目的另一個聯合主管。「我們像是廣大機器學習社區的棄兒:無法發表任何文章。這個項目給了我們交流思想的天地。」
資助不算豐厚,但足夠讓研究員小組繼續下去。Hinton和這個小組孕育了一場密謀:用「深度學習」來「重新命名」讓人聞之色變的神經網絡領域。接下來,每位研究人員肯定都夢想過的事情真的發生了:2006年,Hinton、Simon Osindero與Yee-Whye Teh發表了一篇論文,這被視為一次重要突破,足以重燃人們對神經網絡的興趣:A fast learning algorithm for deep belief nets(論文參見:https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf)。
正如我們將要看到的,盡管這個想法所包含的東西都已經很古老了,「深度學習」的運動完全可以說是由這篇文章所開始。但是比起名稱,更重要的是如果權重能夠以一種更靈活而非隨機的方式進行初始化,有著多層的神經網絡就可以得以更好地訓練。
「歷史上的第一次,神經網絡沒有好處且不可訓練的信念被克服了,并且這是個非常強烈的信念。我的一個朋友在ICML(機器學習國際會議)發表了一篇文章,而就在這不久之前,選稿編輯還說過ICML不應該接受這種文章,因為它是關于神經網絡,并不適合ICML。實際上如果你看一下去年的ICML,沒有一篇文章的標題有『神經網絡』四個字,因此ICML不應該接受神經網絡的文章。那還僅僅只是幾年前。IEEE期刊真的有『不接收你的文章』的官方準則。所以,這種信念其實非常強烈。」

受限的玻爾茲曼機器
那么什么叫做初始化權重的靈活方法呢?實際上,這個主意基本就是利用非監督式訓練方式去一個一個訓練神經層,比起一開始隨機分配值的方法要更好些,之后以監督式學習作為結束。每一層都以受限波爾茲曼機器(RBM)開始,就像上圖所顯示的隱藏單元和可見單元之間并沒有連接的玻爾茲曼機器(如同亥姆霍茲機器),并以非監督模式進行數據生成模式的訓練。事實證明這種形式的玻爾茲曼機器能夠有效采用2002年Hinton引進的方式「最小化對比發散專家訓練產品(Training Products of Experts by Minimizing Contrastive Divergence)」進行訓練。
基本上,除去單元生成訓練數據的可能,這個算法較大化了某些東西,保證更優擬合,事實證明它做的很好。因此,利用這個方法,這個算法如以下:
利用對比發散訓練數據訓練RBM。這是信念網絡(belief net)的第一層。
生成訓練后RBM數據的隱藏值,模擬這些隱藏值訓練另一個RBM,這是第二層——將之「堆棧」在第一層之上,僅在一個方向上保持權重直至形成一個信念網絡。
根據信念網絡需求在多層基礎上重復步驟2。
如果需要進行分類,就添加一套隱藏單元,對應分類標志,并改變喚醒-休眠算法「微調」權重。這樣非監督式與監督式的組合也經常叫做半監督式學習。
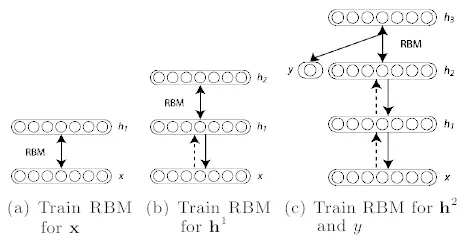
Hinton引入的層式預訓練
這篇論文展示了深度信念網絡(DBNs)對于標準化MNIST字符識別數據庫有著完美的表現,超越了僅有幾層的普通神經網絡。Yoshua Bengio等在這項工作后于2007年提出了「深層網絡冗余式逐層訓練( “Greedy Layer-Wise Training of Deep Networks)」,其中他們表達了一個強有力的論點,深度機器學習方法(也就是有著多重處理步驟的方法,或者有著數據等級排列特征顯示)在復雜問題上比淺顯方法更加有效(雙層ANNs或向量支持機器)。
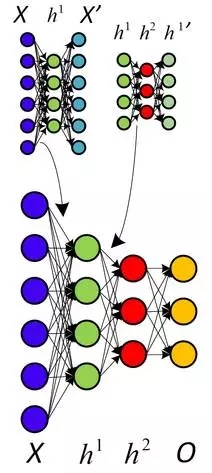
關于非監督式預訓練的另一種看法,利用自動代碼取代RBM。
他們還提出了為什么附加非監督式預訓練,并總結這不僅僅以更優化的方式初始權重,而且更加重要的是導致了更有用的可學習數據顯示,讓算法可以有更加普遍化的模型。實際上,利用RBM并不是那么重要——普通神經網絡層的非監督式預訓練利用簡單的自動代碼層反向傳播證明了其有效性。同樣的,與此同時,另一種叫做分散編碼的方法也表明,非監督式特征學習對于改進監督式學習的性能非常有力。
因此,關鍵在于有著足夠多的顯示層,這樣優良的高層數據顯示能夠被學習——與傳統的手動設計一些特征提取步驟并以提取到的特征進行機器學習方式完全不同。Hinton與Bengio的工作有著實踐上的證明,但是更重要的是,展示了深層神經網絡并不能被訓練好的假設是錯誤的。LeCun已經在整個九十年代證明了CNN,但是大部分研究團體卻拒絕接受。Bengio與Yann LeCun一起,在「實現AI的算法(Scaling Algorithms Towards AI)」研究之上證明了他們自己:
「直至最近,許多人相信訓練深層架構是一個太過困難的優化問題。然而,至少有兩個不同的方法對此都很有效:應用于卷積神經網絡的簡單梯度下降[LeCun et al., 1989, LeCun et al., 1998](適用于信號和圖像),以及近期的逐層非監督式學習之后的梯度下降[Hinton et al., 2006, Bengio et al., 2007, Ranzato et al., 2006]。深層架構的研究仍然處于雛形之中,更好的學習算法還有待發現。從更廣泛的觀點來看待以發現能夠引出AI的學習準則為目標這事已經成為指導性觀念。我們希望能夠激發他人去尋找實現AI的機器學習方法。」
他們的確做到了。或者至少,他們開始了。盡管深度學習還沒有達到今天山呼海應的效果,它已經如冰面下的潛流,不容忽視地開始了涌動。那個時候的成果還不那么引人注意——大部分論文中證明的表現都限于MNIST數據庫,一個經典的機器學習任務,成為了十年間算法的標準化基準。Hinton在2006年發布的論文展現出驚人的錯誤率,在測試集上僅有1.25%的錯誤率,但SVMs已經達到了僅1.4%的錯誤率,甚至簡單的算法在個位數上也能達到較低的錯誤率,正如在論文中所提到的,LeCun已經在1998年利用CNNs表現出0.95%的錯誤率。
因此,在MNIST上做得很好并不是什么大事。意識到這一點,并自信這就是深度學習踏上舞臺的時刻的Hinton與他的兩個研究生,Abdel-rahman Mohamed和George Dahl,展現了他們在一個更具有挑戰性的任務上的努力:語音識別( Speech Recognition)。
利用DBN,這兩個學生與Hinton做到了一件事,那就是改善了十年間都沒有進步的標準語音識別數據集。這是一個了不起的成就,但是現在回首來看,那只是暗示著即將到來的未來——簡而言之,就是打破更多的記錄。
蠻力的重要性
上面所描述的算法對于深度學習的出現有著不容置疑的重要性,但是自上世紀九十年代開始,也有著其他重要組成部分陸續出現:純粹的計算速度。隨著摩爾定律,計算機比起九十年代快了數十倍,讓大型數據集和多層的學習更加易于處理。但是甚至這也不夠——CPU開始抵達速度增長的上限,計算機能力開始主要通過數個CPU并行計算增長。為了學習深度模型中常有的數百萬個權重值,脆弱的CPU并行限制需要被拋棄,并被具有大型并行計算能力的GPUs所代替。意識到這一點也是Abdel-rahman Mohamed,George Dahl與Geoff Hinton做到打破語音識別性能記錄的部分原因:
「由Hinton的深度神經網絡課堂之一所激發,Mohamed開始將它們應用于語音——但是深度神經網絡需要巨大的計算能力,傳統計算機顯然達不到——因此Hinton與Mohamed招募了Dahl。Dahl是Hinton實驗室的學生,他發現了如何利用相同的高端顯卡(讓栩栩如生的計算機游戲能夠顯示在私人計算機上)有效訓練并模擬神經網絡。」
「他們用相同的方法去解決時長過短的語音中片段的音素識別問題,」Hinton說道,「對比于之前標準化三小時基準的方法,他們有了更好的成果。」
在這個案例中利用GPU而不是CPU到底能變得有多快很難說清楚,但是同年《Large-scale Deep Unsupervised Learning using Graphics Processors》這篇論文給出了一個數字:70倍。是的,70倍,這使得數以周記的工作可以被壓縮到幾天就完成,甚至是一天。之前研發了分散式代碼的作者中包括高產的機器學習研究者吳恩達,他逐漸意識到利用大量訓練數據與快速計算的能力在之前被贊同學習算法演變愈烈的研究員們低估了。這個想法在2010年的《Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition》(作者之一J. Schimidhuber正是遞歸LTSM網絡(recurrent LTSM networks)的投資者)中也得到了大力支持,展示了MNIST數據庫能夠達到令人驚嘆的0.35%錯誤率,并且除去大型神經網絡、輸入的多個變量、以及有效的反向傳播GPU實現以外沒有任何特殊的地方。這些想法已經存在了數十年,因此盡管可以說算法的改進并不那么重要,但是結果確實強烈表明大型訓練數據集與快速腭化計算的蠻力方法是一個關鍵。
Dahl與Mohamed利用GPU打破記錄是一個早期且相對有限的成功,但是它足以激勵人們,并且對這兩人來說也為他們帶來了在微軟研究室實習的機會。在這里,他們可以享受到那時已經出現的計算領域內另一個趨勢所帶來的益處:大數據。這個詞語定義寬松,在機器學習的環境下則很容易理解——大量訓練數據。大量的訓練數據非常重要,因為沒有它神經網絡仍然不能做到很好——它們有些過擬合了(完美適用于訓練數據,但無法推廣到新的測試數據)。這說得通——大型神經網絡能夠計算的復雜度需要許多數據來使它們避免學習訓練集中那些不重要的方面——這也是過去研究者面對的主要難題。因此現在,大型公司的計算與數據集合能力證明了其不可替代性。這兩個學生在三個月的實習期中輕易地證明了深度學習的能力,微軟研究室也自此成為了深度學習語音識別研究的前沿地帶。
微軟不是一個意識到深度學習力量的大公司(盡管起初它很靈巧)。Navdeep Jaitly是Hinton的另一個學生,2011年曾在谷歌當過暑假實習生。他致力于谷歌的語音識別項目,通過結合深度學習能夠讓他們現存的設備大大提高。修正后的方法不久就加強了安卓的語音識別技術,替代了許多之前的解決方案。
除了博士實習生給大公司的產品帶來的深刻影響之外,這里最著名的是兩家公司都在用相同的方法——這方法對所有使用它的人都是開放的。實際上,微軟和谷歌的工作成果,以及IBM和Hinton實驗室的工作成果,在2012 年發布了令人印象深刻的名為「深層神經網絡語音識別的聲學建模:分享四個研究小組的觀點」的文章。
這四個研究小組——有三個是來自企業,確定能從傷腦筋的深度學習這一新興技術專利中獲益,而大學研究小組推廣了技術——共同努力并將他們的成果發布給更廣泛的研究社區。如果有什么理想的場景讓行業接受研究中的觀念,似乎就是這一刻了。
這并不是說公司這么做是為了慈善。這是他們所有人探索如何把技術商業化的開始,其中更為突出的是谷歌。但是也許并非Hinton,而是吳恩達造成了這一切,他促使公司成為世界較大的商業化采用者和技術用戶者。在2011年,吳恩達在巡視公司時偶遇到了傳說中的谷歌人Jeff Dean,聊了一些他用谷歌的計算資源來訓練神經網絡所做的努力。
這使Dean著迷,于是與吳恩達一起創建了谷歌大腦(Google Brain)——努力構建真正巨大的神經網絡并且探索它們能做什么。這項工作引發了一個規模前所未有的無監督式神經網絡學習——16000個CPU核,驅動高達10億權重的學習(作為比較,Hinton在2006年突破性的DBN大約有100萬權重)。神經網絡在YouTube視頻上被訓練,完全無標記,并且學著在這些視頻中去辨認最平常的物體——而神經網絡對于貓的發現,引起了互聯網的集體歡樂。

谷歌最著名的神經網絡學習貓。這是輸入到一個神經元中較佳的一張。
它很可愛,也很有用。正如他們常規發表的一篇論文中所報道的,由模型學習的特征能用來記錄標準的計算機視覺基準的設置性能。
這樣一來,谷歌訓練大規模的神經網絡的內部工具誕生了,自此他們僅需繼續發展它。深度學習研究的浪潮始于2006年,現在已經確定進入行業使用。
深度學習的上升
當深度學習進入行業使用時,研究社區很難保持平靜。有效的利用GPU和計算能力的發現是如此重要,它讓人們檢查長久存疑的假設并且問一些也許很久之前被提及過的問題——也就是,反向傳播到底為何沒什么用呢?為什么舊的方法不起作用,而不是新的方法能奏效,這樣的問題觀點讓Xavier Glort 和 Yoshua Bengio在2010年寫了「理解訓練深度前饋神經網絡的難點」(Understanding the difficulty of training deep feedforward neural networks)一文。
在文中,他們討論了兩個有重大意義的發現:
為神經網絡中神經元選取的特定非線性激活函數,對性能有巨大影響,而默認使用的函數不是較好的選擇。
相對于隨機選取權重,不考慮神經層的權重就隨機選取權重的問題要大得多。以往消失的梯度問題重現,根本上,由于反向傳播引入一系列乘法,不可避免地導致給前面的神經層帶來細微的偏差。就是這樣,除非依據所在的神經層不同分別選取不同的權重 ——否則很小的變化會引起結果巨大變化。

不同的激活函數。ReLU是**修正線性單元**
第二點的結論已經很清楚了,但是第一點提出了這樣的問題:『然而,什么是較好的激活函數?』有三個不同的團隊研究了這個問題:LeCun所在的團隊,他們研究的是「針對對象識別較好的多級結構是什么?」;另一組是Hinton所在的團隊,研究「修正的線性單元改善受限玻爾茲曼機器」;第三組是Bengio所在的團隊——「深度稀缺的修正神經網絡」。他們都發現驚人的相似結論:近乎不可微的、十分簡單的函數f(x)=max(0,x)似乎是較好的。令人吃驚的是,這個函數有點古怪——它不是嚴格可微的,確切地說,在零點不可微,因此 就 數學而言論文看起來很糟糕。但是,清楚的是零點是很小的數學問題——更嚴重的問題是為什么這樣一個零點兩側導數都是常數的簡單函數,這么好用。答案還未揭曉,但一些想法看起來已經成型:
修正的激活導致了表征稀疏,這意味著在給定輸入時,很多神經元實際上最終需要輸出非零值。這些年的結論是,稀疏對深度學習十分有利,一方面是由于它用更具魯棒性的方式表征信息,另一方面由于它帶來極高的計算效率(如果大多數的神經元在輸出零,實際上就可以忽略它們,計算也就更快)。順便提一句,計算神經科學的研究者首次在大腦視覺系統中引入稀疏計算,比機器學習的研究早了10年。
相比指數函數或者三角函數,簡單的函數及其導數,使它能非常快地工作。當使用GPU時,這就不僅僅是一個很小的改善,而是十分重要,因為這能規模化神經網絡以很好地完成極具挑戰的問題。
后來吳恩達聯合發表的「修正的非線性改善神經網絡的語音模型 」(Rectifier Nonlinearities Improve Neural Network Acoustic Models)一文,也證明了ReLU導數為常數0或1對學習并無害處。實際上,它有助于避免梯度消失的問題,而這正是反向傳播的禍根。此外,除了生成更稀疏的表征,它還能生成更發散的表征——這樣就可以結合多個神經元的多重值,而不局限于從單個神經元中獲取有意義的結論。
目前,結合2006年以來的這些發現,很清楚的是非監督預訓練對深度學習來說不是必要的。雖然,它的確有幫助,但是在某些情況下也表明,純粹的監督學習(有正確的初始權重規模和激活函數)能超越含非監督訓練的學習方式。那么,到底為什么基于反向傳播的純監督學習在過去表現不佳?Geoffrey Hinton總結了目前發現的四個方面問題:
帶標簽的數據集很小,只有現在的千分之一.
計算性能很慢,只有現在的百萬分之一.
權重的初始化方式笨拙.
使用了錯誤的非線性模型。
好了,就到這里了。深度學習。數十年研究的積累,總結成一個公式就是:
深度學習=許多訓練數據+并行計算+規模化、靈巧的的算法

我希望我是第一個提出這個賞心悅目的方程的,但是看起來有人走在我前面了。
更不要說這里就是希望弄清楚這點。差遠了!被想通的東西剛好是相反的:人們的直覺經常出錯,尤其是一些看似沒有問題的決定及假設通常都是沒有根據的。問簡單的問題,嘗試簡單的東西——這些對于改善的技術有很大的幫助。其實這一直都在發生,我們看到更多的想法及方法在深度學習領域中被發掘、被分享。例如 G. E. Hinton等的「透過預防特征檢測器的互相適應改善神經網絡」( Improving neural networks by preventing co-adaptation of feature detectors)。
其構思很簡單:為了避免過度擬合,我們可以隨機假裝在訓練當中有些神經元并不在那兒。想法雖然非常簡單——被稱為丟棄法(dropout)——但對于實施非常強大的集成學習方法又非常有效,這意味著我們可以在訓練數據中實行多種不同的學習方法。隨機森林——一種在當今機器學習領域中占主導地位的方法——主要就是得益于集成學習而非常有效。訓練多個不同的神經網絡是可能的,但它在計算上過于昂貴,而這個簡單的想法在本質上也可取得相同的結果,而且性能也可有顯著提高。
然而,自2006年以來的所有這些研究發現都不是促使計算機視覺及其他研究機構再次尊重神經網絡的原因。這個原因遠沒有看來的高尚:在現代競爭的基準上完全摧毀其他非深度學習的方法。Geoffrey Hinton召集與他共同寫丟棄法的兩位作家,Alex Krizhevsky 與 Ilya Sutskever,將他們所發現的想法在ILSVRC-2012計算機視覺比賽中創建了一個條目。
對于我來說,了解他們的工作是非常驚人的,他們的「使用深度卷積神經網絡在ImageNet上分類」(ImageNet Classification with deep convolutional neural networks)一文其實就是將一些很舊的概念(例如卷積神經網絡的池化及卷積層,輸入數據的變化)與一些新的關鍵觀點(例如十分高性能的GPU、ReLU神經元、丟棄法等)重新組合,而這點,正是這一點,就是現代深度網絡的所有深意了。但他們如何做到的呢?
遠比下一個最近的條目好:它們的誤差率是15.3%,第二個最近的是26.2%。在這點上——第一個及一個在比賽中的CNN條目——對于CNNs及深度學習整體來說是一個無可爭議的標志,對于計算機視覺,它應該被認真對待。如今,幾乎所有的比賽條目都是CNNs——這就是Yann LeCun自1989年以來在上面花費大量心血的神經網絡模型。還記得上世紀90年代由Sepp Hochreiter 及 Jürgen Schmidhuber為了解決反向傳播問題而開發的LSTM循環神經網絡嗎?這些在現在也是的連續任務比如語音處理的處理方法。
這就是轉折點。一波對于其可能發展的狂歡在其無可否認的成績中達到了高潮,這遠遠超過了其他已知方法所能處理的。這就是我們在第一部分開頭所描寫的山呼海應比喻的起點,而且它到如今還一直在增長,強化。深度學習就在這兒,我們看不到寒冬。
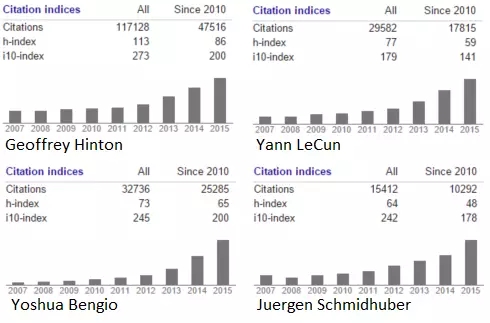
我們列舉了對深度學習的發展做出重要貢獻的人物。我相信我不需要再指出自從2012年以來其飛漲的趨勢了。
后記:現狀
如果這是一部電影,2012年ImageNet比賽將是其高潮,而現在在電影結束的時候,我們將會出現這幾個字:「他們如今在哪里」。Yann Lecun:Facebook; Geoffrey Hinton: 谷歌; 吳恩達: Coursera、谷歌、百度; Bengi、Schmidhuber 及 Hochreiter 依然還留在學術界——但我們可以很容易推測,這個領域將會有更多的引用及畢業生。
雖然深度學習的理念及成績令人振奮,但當我在寫這幾篇文章的時候,我也不由自主地被他們所感動,他們在一個幾乎被人遺棄的領域里深耕數十年,他們現在富裕、成功,但重要的是他們如今更確信自己的研究。這些人的思想依然保持開放,而這些大公司也一直在開源他們的深度學習模型,猶如一個由工業界領導研究界的理想國。多美好的故事啊啊。
我愚蠢的以為我可以在這一部分寫一個過去幾年讓人印象深刻的成果總結,但在此,我清楚知道我已經沒有足夠的空間來寫這些。可能有一天我會繼續寫第五部分,那就可以完成這個故事了。但現在,讓我提供以下一個簡短的清單:
1.LTSM RNNs的死灰復燃以及分布式表征的代表
去年的結果。看看吧!
2.利用深度學習來加強學習
3.附加外部可讀寫存儲
參考文獻:
Kate Allen. How a Toronto professor’s research revolutionized artificial intelligence Science and Technology reporter, Apr 17 2015 http://www.thestar.com/news/world/2015/04/17/how-a-toronto-professors-research-revolutionized-artificial-intelligence.html
Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural computation, 18(7), 1527-1554.
Hinton, G. E. (2002). Training products of experts by minimizing contrastive divergence. Neural computation, 14(8), 1771-1800.
Bengio, Y., Lamblin, P., Popovici, D., & Larochelle, H. (2007). Greedy layer-wise training of deep networks. Advances in neural information processing systems, 19, 153.
Bengio, Y., & LeCun, Y. (2007). Scaling learning algorithms towards AI. Large-scale kernel machines, 34(5).
Mohamed, A. R., Sainath, T. N., Dahl, G., Ramabhadran, B., Hinton, G. E., & Picheny, M. (2011, May). Deep belief networks using discriminative features for phone recognition. In Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on (pp. 5060-5063). IEEE.
November 26, 2012. Leading breakthroughs in speech recognition software at Microsoft, Google, IBM Source: http://news.utoronto.ca/leading-breakthroughs-speech-recognition-software-microsoft-google-ibm
Raina, R., Madhavan, A., & Ng, A. Y. (2009, June). Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th annual international conference on machine learning (pp. 873-880). ACM.
Claudiu Ciresan, D., Meier, U., Gambardella, L. M., & Schmidhuber, J. (2010). Deep big simple neural nets excel on handwritten digit recognition. arXiv preprint arXiv:1003.0358.
Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A. R., Jaitly, N., … & Kingsbury, B. (2012). Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Processing Magazine, IEEE, 29(6), 82-97.
Le, Q. V. (2013, May). Building high-level features using large scale unsupervised learning. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on (pp. 8595-8598). IEEE. ?
Glorot, X., & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. In International conference on artificial intelligence and statistics (pp. 249-256).
Jarrett, K., Kavukcuoglu, K., Ranzato, M. A., & LeCun, Y. (2009, September). What is the best multi-stage architecture for object recognition?. In Computer Vision, 2009 IEEE 12th International Conference on (pp. 2146-2153). IEEE.
Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10) (pp. 807-814).
Glorot, X., Bordes, A., & Bengio, Y. (2011). Deep sparse rectifier neural networks. In International Conference on Artificial Intelligence and Statistics (pp. 315-323).
Maas, A. L., Hannun, A. Y., & Ng, A. Y. (2013, June). Rectifier nonlinearities improve neural network acoustic models. In Proc. ICML (Vol. 30).
Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. R. (2012). Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).?
http://www.technologyreview.com/news/524026/is-google-cornering-the-market-on-deep-learning/
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4344.html
摘要:如何看待人工智能的本質人工智能的飛速發展又經歷了哪些歷程本文就從技術角度為大家介紹人工智能領域經常提到的幾大概念與發展簡史。一人工智能相關概念人工智能就是讓機器像人一樣的智能會思考是機器學習深度學習在實踐中的應用。 作為近幾年的一大熱詞,人工智能一直是科技圈不可忽視的一大風口。隨著智能硬件的迭代,智能家居產品逐步走進千家萬戶,語音識別、圖像識別等AI相關技術也經歷了階梯式發展。如何看待...
摘要:如何看待人工智能的本質人工智能的飛速發展又經歷了哪些歷程本文就從技術角度為大家介紹人工智能領域經常提到的幾大概念與發展簡史。一人工智能相關概念人工智能就是讓機器像人一樣的智能會思考是機器學習深度學習在實踐中的應用。 作為近幾年的一大熱詞,人工智能一直是科技圈不可忽視的一大風口。隨著智能硬件的迭代,智能家居產品逐步走進千家萬戶,語音識別、圖像識別等AI相關技術也經歷了階梯式發展。如何看待...

閱讀 2511·2021-11-18 10:02
閱讀 1976·2021-11-09 09:45
閱讀 2399·2021-09-26 09:47
閱讀 1010·2021-07-23 10:26
閱讀 1063·2019-08-30 15:47
閱讀 3356·2019-08-30 15:44
閱讀 957·2019-08-30 15:43
閱讀 881·2019-08-29 13:50



