資訊專欄INFORMATION COLUMN

摘要:本教程中用到了基于注意力的模型,它使我們很直觀地看到當文字生成時模型會關注哪些部分。運行的時候,它會自動下載數據集,使用模型訓練一個編碼解碼器,然后用模型對新圖像進行文字描述。
圖像描述類任務就是給圖像生成一個標題。 給定一個圖像:

圖片出處, 許可證:公共領域
我們的目標是用一句話來描述圖片, 比如「一個沖浪者正在沖浪」。 本教程中用到了基于注意力的模型,它使我們很直觀地看到當文字生成時模型會關注哪些部分。?
這個模型的結構類似于論文: Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.(https://arxiv.org/abs/1502.03044)
本教程中的代碼使用到了 ?tf.keras (https://www.tensorflow.org/guide/keras) 和 ?eager execution (https://www.tensorflow.org/programmers_guide/eager)這兩個工具,鏈接里有詳細的內容可以學習。
這個 notebook 展示了一個端到端模型。 運行的時候,它會自動下載 MS-COCO (http://cocodataset.org/#home)數據集,使用 Inception V3 模型訓練一個編碼 - 解碼器,然后用模型對新圖像進行文字描述。
這篇代碼可以在 Colab (https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb) 中運行,但是需要 TensorFlow 的版本 >=1.9 ??
本實驗對數據進行打亂以后取前 30000 篇描述作為訓練集,對應 20000 篇圖片(一張圖片可能會包含多個描述)。 訓練模型的數據量相對較小,因此只用了一個 P100 GPU,訓練模型大約需要兩個小時。
# Import TensorFlow and enable eager execution
# This code requires TensorFlow version >=1.9
import tensorflow as tf
tf.enable_eager_execution()
# We"ll generate plots of attention in order to see which parts of an image
# our model focuses on during captioning
import matplotlib.pyplot as plt
# Scikit-learn includes many helpful utilities
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import re
import numpy as np
import os
import time
import json
from glob import glob
from PIL import Image
import pickle
下載 MS-COCO 數據集
MS-COCO (http://cocodataset.org/#home)數據集包含 82,000 多張圖片,每張圖片都是用至少 5 句不同的文字描述的。 下面的代碼在運行時會自動下載并且解壓數據。
注意: 提前下載好數據,數據文件大小 13GB 。
annotation_zip = tf.keras.utils.get_file("captions.zip",?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?cache_subdir=os.path.abspath("."),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?origin = "http://images.cocodataset.org/annotations/annotations_trainval2014.zip",
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?extract = True)
annotation_file = os.path.dirname(annotation_zip)+"/annotations/captions_train2014.json"
name_of_zip = "train2014.zip"
if not os.path.exists(os.path.abspath(".") + "/" + name_of_zip):
?image_zip = tf.keras.utils.get_file(name_of_zip,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?cache_subdir=os.path.abspath("."),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?origin = "http://images.cocodataset.org/zips/train2014.zip",
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?extract = True)
?PATH = os.path.dirname(image_zip)+"/train2014/"
else:
?PATH = os.path.abspath(".")+"/train2014/"
選擇是否壓縮訓練集大小來減少訓練時間
本教程中選擇用 30000 篇描述和它們對應的圖片來訓練模型,但是當使用更多數據時,實驗結果的質量通常會得到提高。
# read the json file
with open(annotation_file, "r") as f:
? ?annotations = json.load(f)
# storing the captions and the image name in vectors
all_captions = []
all_img_name_vector = []
for annot in annotations["annotations"]:
? ?caption = "
? ?image_id = annot["image_id"]
? ?full_coco_image_path = PATH + "COCO_train2014_" + "%012d.jpg" % (image_id)
? ?
? ?all_img_name_vector.append(full_coco_image_path)
? ?all_captions.append(caption)
# shuffling the captions and image_names together
# setting a random state
train_captions, img_name_vector = shuffle(all_captions,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?all_img_name_vector,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?random_state=1)
# selecting the first 30000 captions from the shuffled set
num_examples = 30000
train_captions = train_captions[:num_examples]
img_name_vector = img_name_vector[:num_examples]
len(train_captions), len(all_captions)
Inceptions v3 圖像預處理
這個步驟中需要使用 InceptionV3 (在 Imagenet 上訓練好的模型) 對每一張圖片進行分類,并且從最后一個卷積層中提取特征。
首先,我們需要將圖像轉換為 inceptionV3 需要的格式:
把圖像的大小固定到 (299, 299)
使用 preprocess_input (https://www.tensorflow.org/api_docs/python/tf/keras/applications/inception_v3/preprocess_input)函數將像素調整到 -1 到 1 的范圍內(為了匹配 inceptionV3 的輸入格式)。
def load_image(image_path):
? ?img = tf.read_file(image_path)
? ?img = tf.image.decode_jpeg(img, channels=3)
? ?img = tf.image.resize_images(img, (299, 299))
? ?img = tf.keras.applications.inception_v3.preprocess_input(img)
? ?return img, image_path
初始化 InceptionV3 & 下載 Imagenet 的預訓練權重
將 InceptionV3 的最后一個卷積層作為輸出層時,需要創建一個 keras 模型。
將處理好的圖片輸入神經網絡,然后提取最后一層中獲得的向量作為圖像特征保存成字典格式(圖名 --> 特征向量);
選擇卷積層的目的是為了更好地利用注意力機制,并且輸出層的數據大小是8x8x2048;
為了提高模型質量的瓶頸,不要在預訓練的時候添加注意力機制;
在網絡中訓練完成以后,將緩存的字典文件輸出為 pickle 文件并且保存到本地磁盤。
image_model = tf.keras.applications.InceptionV3(include_top=False,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?weights="imagenet")
new_input = image_model.input
hidden_layer = image_model.layers[-1].output
image_features_extract_model = tf.keras.Model(new_input, hidden_layer)
保存從 InceptionV3中提取的特征
利用 InceptionV3 對圖像進行預處理以后將輸出保存到本地磁盤,將輸出緩存到 RAM 中會更快,但是內存更密集,每張圖片都需要 8 * 8 * 2048 浮點數大小。 在寫入時,這個大小可能會超過 Colab 的限制(也許會有浮動,但是當前這個實例顯示大約需要 12GB)。
采用更復雜的緩存策略可以提高性能,但前提是代碼會更的更復雜。例如,通過對數據進行分區來減少磁盤的隨機訪問 I/O 。
通過 GPU 在 Colab 上運行這個模型大約需要花費 10 分鐘。假如需要直觀地看程序進度,可以安裝 tqdm (!pip install tqdm), 并且修改這一行代碼:
for img, path in image_dataset: 為:for img, path in tqdm(image_dataset):
# getting the unique images
encode_train = sorted(set(img_name_vector))
# feel free to change the batch_size according to your system configuration
image_dataset = tf.data.Dataset.from_tensor_slices(
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?encode_train).map(load_image).batch(16)
for img, path in image_dataset:
?batch_features = image_features_extract_model(img)
?batch_features = tf.reshape(batch_features,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(batch_features.shape[0], -1, batch_features.shape[3]))
?for bf, p in zip(batch_features, path):
? ?path_of_feature = p.numpy().decode("utf-8")
? ?np.save(path_of_feature, bf.numpy())
對描述文字的預處理
首先,我們需要對描述進行分詞,英文等西語可以按空格分詞。分詞以后得到一個包括所有詞的詞表(不重復);
然后,只保存詞表中的前 5000 個詞, 其他的詞標記為 "UNK" (不認識的詞);
最后,創建「詞-編號」和「編號-詞」的索引表;
最后將最長的一個句子作為所有句子的向量長度。
# This will find the maximum length of any caption in our dataset
def calc_max_length(tensor):
? ?return max(len(t) for t in tensor)
# The steps above is a general process of dealing with text processing
# choosing the top 5000 words from the vocabulary
top_k = 5000
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?oov_token="
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?filters="!"#$%&()*+.,-/:;=?@[]^_`{|}~ ")
tokenizer.fit_on_texts(train_captions)
train_seqs = tokenizer.texts_to_sequences(train_captions)
tokenizer.word_index = {key:value for key, value in tokenizer.word_index.items() if value <= top_k}
# putting
tokenizer.word_index[tokenizer.oov_token] = top_k + 1
tokenizer.word_index["
# creating the tokenized vectors
train_seqs = tokenizer.texts_to_sequences(train_captions)
# creating a reverse mapping (index -> word)
index_word = {value:key for key, value in tokenizer.word_index.items()}
# padding each vector to the max_length of the captions
# if the max_length parameter is not provided, pad_sequences calculates that automatically
cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding="post")
# calculating the max_length?
# used to store the attention weights
max_length = calc_max_length(train_seqs)
將數據分為訓練集和測試集
# Create training and validation sets using 80-20 split
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?cap_vector,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?test_size=0.2,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?random_state=0)
len(img_name_train), len(cap_train), len(img_name_val), len(cap_val)
準備好圖形和描述數據后,就可以用 tf.data 訓練集來訓練模型了!
# feel free to change these parameters according to your system"s configuration
BATCH_SIZE = 64
BUFFER_SIZE = 1000
embedding_dim = 256
units = 512
vocab_size = len(tokenizer.word_index)
# shape of the vector extracted from InceptionV3 is (64, 2048)
# these two variables represent that
features_shape = 2048
attention_features_shape = 64
# loading the numpy files?
def map_func(img_name, cap):
? ?img_tensor = np.load(img_name.decode("utf-8")+".npy")
? ?return img_tensor, cap
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))
# using map to load the numpy files in parallel
# NOTE: Be sure to set num_parallel_calls to the number of CPU cores you have
# https://www.tensorflow.org/api_docs/python/tf/py_func
dataset = dataset.map(lambda item1, item2: tf.py_func(
? ? ? ? ?map_func, [item1, item2], [tf.float32, tf.int32]), num_parallel_calls=8)
# shuffling and batching
dataset = dataset.shuffle(BUFFER_SIZE)
# https://www.tensorflow.org/api_docs/python/tf/contrib/data/batch_and_drop_remainder
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(1)
模型結構
有趣的是,本實驗中的解碼器與 Neural Machine Translation with Attention (https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb)這篇論文中的結構完全相同。
這個模型的結構參考了 Show, Attend and Tell (https://arxiv.org/pdf/1502.03044.pdf)這篇文章。
在本教程的實驗中,我們從 InceptionV3 模型的下卷積層中提取特征,特征向量的大小為 (8, 8, 2048);
需要把這個形狀拉伸到 (64, 2048);
把這個向量輸入到 CNN 編碼器(還包括了一個全連接層);
用 RNN (這里用的是 RNN 的改進算法 GRU) 來預測詞序列。
def gru(units):
?# If you have a GPU, we recommend using the CuDNNGRU layer (it provides a?
?# significant speedup).
?if tf.test.is_gpu_available():
? ?return tf.keras.layers.CuDNNGRU(units,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?return_sequences=True,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?return_state=True,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?recurrent_initializer="glorot_uniform")
?else:
? ?return tf.keras.layers.GRU(units,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? return_sequences=True,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? return_state=True,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? recurrent_activation="sigmoid",?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? recurrent_initializer="glorot_uniform")
class BahdanauAttention(tf.keras.Model):
?def __init__(self, units):
? ?super(BahdanauAttention, self).__init__()
? ?self.W1 = tf.keras.layers.Dense(units)
? ?self.W2 = tf.keras.layers.Dense(units)
? ?self.V = tf.keras.layers.Dense(1)
?
?def call(self, features, hidden):
? ?# features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)
? ?
? ?# hidden shape == (batch_size, hidden_size)
? ?# hidden_with_time_axis shape == (batch_size, 1, hidden_size)
? ?hidden_with_time_axis = tf.expand_dims(hidden, 1)
? ?
? ?# score shape == (batch_size, 64, hidden_size)
? ?score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))
? ?
? ?# attention_weights shape == (batch_size, 64, 1)
? ?# we get 1 at the last axis because we are applying score to self.V
? ?attention_weights = tf.nn.softmax(self.V(score), axis=1)
? ?
? ?# context_vector shape after sum == (batch_size, hidden_size)
? ?context_vector = attention_weights * features
? ?context_vector = tf.reduce_sum(context_vector, axis=1)
? ?
? ?return context_vector, attention_weights
class BahdanauAttention(tf.keras.Model):
?def __init__(self, units):
? ?super(BahdanauAttention, self).__init__()
? ?self.W1 = tf.keras.layers.Dense(units)
? ?self.W2 = tf.keras.layers.Dense(units)
? ?self.V = tf.keras.layers.Dense(1)
?
?def call(self, features, hidden):
? ?# features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)
? ?
? ?# hidden shape == (batch_size, hidden_size)
? ?# hidden_with_time_axis shape == (batch_size, 1, hidden_size)
? ?hidden_with_time_axis = tf.expand_dims(hidden, 1)
? ?
? ?# score shape == (batch_size, 64, hidden_size)
? ?score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))
? ?
? ?# attention_weights shape == (batch_size, 64, 1)
? ?# we get 1 at the last axis because we are applying score to self.V
? ?attention_weights = tf.nn.softmax(self.V(score), axis=1)
? ?
? ?# context_vector shape after sum == (batch_size, hidden_size)
? ?context_vector = attention_weights * features
? ?context_vector = tf.reduce_sum(context_vector, axis=1)
? ?
? ?return context_vector, attention_weights
class CNN_Encoder(tf.keras.Model):
? ?# Since we have already extracted the features and dumped it using pickle
? ?# This encoder passes those features through a Fully connected layer
? ?def __init__(self, embedding_dim):
? ? ? ?super(CNN_Encoder, self).__init__()
? ? ? ?# shape after fc == (batch_size, 64, embedding_dim)
? ? ? ?self.fc = tf.keras.layers.Dense(embedding_dim)
? ? ? ?
? ?def call(self, x):
? ? ? ?x = self.fc(x)
? ? ? ?x = tf.nn.relu(x)
? ? ? ?return x
class RNN_Decoder(tf.keras.Model):
?def __init__(self, embedding_dim, units, vocab_size):
? ?super(RNN_Decoder, self).__init__()
? ?self.units = units
? ?self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
? ?self.gru = gru(self.units)
? ?self.fc1 = tf.keras.layers.Dense(self.units)
? ?self.fc2 = tf.keras.layers.Dense(vocab_size)
? ?
? ?self.attention = BahdanauAttention(self.units)
? ? ? ?
?def call(self, x, features, hidden):
? ?# defining attention as a separate model
? ?context_vector, attention_weights = self.attention(features, hidden)
? ?
? ?# x shape after passing through embedding == (batch_size, 1, embedding_dim)
? ?x = self.embedding(x)
? ?
? ?# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
? ?x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
? ?
? ?# passing the concatenated vector to the GRU
? ?output, state = self.gru(x)
? ?
? ?# shape == (batch_size, max_length, hidden_size)
? ?x = self.fc1(output)
? ?
? ?# x shape == (batch_size * max_length, hidden_size)
? ?x = tf.reshape(x, (-1, x.shape[2]))
? ?
? ?# output shape == (batch_size * max_length, vocab)
? ?x = self.fc2(x)
? ?return x, state, attention_weights
?def reset_state(self, batch_size):
? ?return tf.zeros((batch_size, self.units))
encoder = CNN_Encoder(embedding_dim)
decoder = RNN_Decoder(embedding_dim, units, vocab_size)
optimizer = tf.train.AdamOptimizer()
# We are masking the loss calculated for padding
def loss_function(real, pred):
? ?mask = 1 - np.equal(real, 0)
? ?loss_ = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=real, logits=pred) * mask
? ?return tf.reduce_mean(loss_)
訓練
提取 ?.npy 相關的文件中存儲的特征并輸入到編碼器中去;
將編碼器的輸出、隱狀態(初始化為 0) 和解碼器的輸入(句子分詞結果的索引集合) 一起輸入到解碼器中去;
解碼器返回預測結果和隱向量;
然后把解碼器輸出的隱向量傳回模型,預測結果需用于計算損失函數;
使用 teacher forcing 來決定解碼器的下一個輸入;
Teacher forcing 是用于篩選編碼器下一個輸入詞的技術;
最后一步是計算梯度,用于進行反向傳遞以最小化損失函數值。
# adding this in a separate cell because if you run the training cell?
# many times, the loss_plot array will be reset
loss_plot = []
EPOCHS = 20
for epoch in range(EPOCHS):
? ?start = time.time()
? ?total_loss = 0
? ?
? ?for (batch, (img_tensor, target)) in enumerate(dataset):
? ? ? ?loss = 0
? ? ? ?
? ? ? ?# initializing the hidden state for each batch
? ? ? ?# because the captions are not related from image to image
? ? ? ?hidden = decoder.reset_state(batch_size=target.shape[0])
? ? ? ?dec_input = tf.expand_dims([tokenizer.word_index["
? ? ? ?
? ? ? ?with tf.GradientTape() as tape:
? ? ? ? ? ?features = encoder(img_tensor)
? ? ? ? ? ?
? ? ? ? ? ?for i in range(1, target.shape[1]):
? ? ? ? ? ? ? ?# passing the features through the decoder
? ? ? ? ? ? ? ?predictions, hidden, _ = decoder(dec_input, features, hidden)
? ? ? ? ? ? ? ?loss += loss_function(target[:, i], predictions)
? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ?# using teacher forcing
? ? ? ? ? ? ? ?dec_input = tf.expand_dims(target[:, i], 1)
? ? ? ?
? ? ? ?total_loss += (loss / int(target.shape[1]))
? ? ? ?
? ? ? ?variables = encoder.variables + decoder.variables
? ? ? ?
? ? ? ?gradients = tape.gradient(loss, variables)?
? ? ? ?
? ? ? ?optimizer.apply_gradients(zip(gradients, variables), tf.train.get_or_create_global_step())
? ? ? ?
? ? ? ?if batch % 100 == 0:
? ? ? ? ? ?print ("Epoch {} Batch {} Loss {:.4f}".format(epoch + 1,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?batch,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?loss.numpy() / int(target.shape[1])))
? ?# storing the epoch end loss value to plot later
? ?loss_plot.append(total_loss / len(cap_vector))
? ?
? ?print ("Epoch {} Loss {:.6f}".format(epoch + 1,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? total_loss/len(cap_vector)))
? ?print ("Time taken for 1 epoch {} sec ".format(time.time() - start))
plt.plot(loss_plot)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Plot")
plt.show()
注意事項
評價函數與迭代訓練的過程類似,除了不使用 teacher forcing 機制,解碼器的每一步輸入都是前一步的預測結果、編碼器輸入和隱狀態;
當模型預測到最后一個詞時停止;
在每一步存儲注意力層的權重的權重。
def evaluate(image):
? ?attention_plot = np.zeros((max_length, attention_features_shape))
? ?hidden = decoder.reset_state(batch_size=1)
? ?temp_input = tf.expand_dims(load_image(image)[0], 0)
? ?img_tensor_val = image_features_extract_model(temp_input)
? ?img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))
? ?features = encoder(img_tensor_val)
? ?dec_input = tf.expand_dims([tokenizer.word_index["
? ?result = []
? ?for i in range(max_length):
? ? ? ?predictions, hidden, attention_weights = decoder(dec_input, features, hidden)
? ? ? ?attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()
? ? ? ?predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()
? ? ? ?result.append(index_word[predicted_id])
? ? ? ?if index_word[predicted_id] == "
? ? ? ? ? ?return result, attention_plot
? ? ? ?dec_input = tf.expand_dims([predicted_id], 0)
? ?attention_plot = attention_plot[:len(result), :]
? ?return result, attention_plot
def plot_attention(image, result, attention_plot):
? ?temp_image = np.array(Image.open(image))
? ?fig = plt.figure(figsize=(10, 10))
? ?
? ?len_result = len(result)
? ?for l in range(len_result):
? ? ? ?temp_att = np.resize(attention_plot[l], (8, 8))
? ? ? ?ax = fig.add_subplot(len_result//2, len_result//2, l+1)
? ? ? ?ax.set_title(result[l])
? ? ? ?img = ax.imshow(temp_image)
? ? ? ?ax.imshow(temp_att, cmap="gray", alpha=0.6, extent=img.get_extent())
? ?plt.tight_layout()
? ?plt.show()
# captions on the validation set
rid = np.random.randint(0, len(img_name_val))
image = img_name_val[rid]
real_caption = " ".join([index_word[i] for i in cap_val[rid] if i not in [0]])
result, attention_plot = evaluate(image)
print ("Real Caption:", real_caption)
print ("Prediction Caption:", " ".join(result))
plot_attention(image, result, attention_plot)
# opening the image
Image.open(img_name_val[rid])
使用自己的數據集進行訓練
為了讓這個實驗更有趣,下面提供了方法可以讓你用自己的圖片測試剛剛訓練好的模型進行圖片描述。但是需要注意,這個模型用的數據相對較少,假設你的圖片和訓練集區別太大,可能會出現比較奇怪的結果。
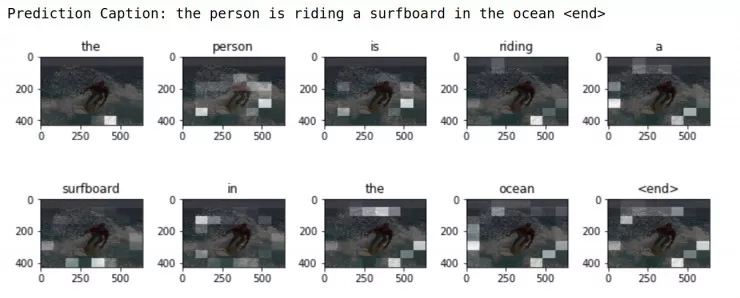
image_url = "https://tensorflow.org/images/surf.jpg"
image_extension = image_url[-4:]
image_path = tf.keras.utils.get_file("image"+image_extension,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? origin=image_url)
result, attention_plot = evaluate(image_path)
print ("Prediction Caption:", " ".join(result))
plot_attention(image_path, result, attention_plot)
# opening the image
Image.open(image_path)
下一步計劃
恭喜你!已經可以訓練一個基于注意力機制的圖片描述模型,而且你也可以嘗試對不同的圖像數據集進行實驗。有興趣的話,可以看一下這個示例 : Neural Machine Translation with Attention(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb)。 這個機器翻譯模型與本實驗使用的結構相似,可以翻譯西班牙語和英語句子。
原文鏈接:
https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb#scrollTo=io7ws3ReRPGv
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4805.html
摘要:從到,計算機視覺領域和卷積神經網絡每一次發展,都伴隨著代表性架構取得歷史性的成績。在這篇文章中,我們將總結計算機視覺和卷積神經網絡領域的重要進展,重點介紹過去年發表的重要論文并討論它們為什么重要。這個表現不用說震驚了整個計算機視覺界。 從AlexNet到ResNet,計算機視覺領域和卷積神經網絡(CNN)每一次發展,都伴隨著代表性架構取得歷史性的成績。作者回顧計算機視覺和CNN過去5年,總結...
摘要:意味著完全保持,意味著完全丟棄。卡比獸寫這篇博文的時間我本可以抓一百只,請看下面的漫畫。神經網絡神經網絡會以的概率判定輸入圖片中的卡比獸正在淋浴,以的概率判定卡比獸正在喝水,以的概率判定卡比獸正在遭遇襲擊。最終結果是卡比獸正在遭遇襲擊 我第一次學習 LSTM 的時候,它就吸引了我的眼球。事實證明 LSTM 是對神經網絡的一個相當簡單的擴展,而且在最近幾年里深度學習所實現的驚人成就背后都有它們...
摘要:本文以機器翻譯為例,深入淺出地介紹了深度學習中注意力機制的原理及關鍵計算機制,同時也抽象出其本質思想,并介紹了注意力模型在圖像及語音等領域的典型應用場景。 最近兩年,注意力模型(Attention Model)被廣泛使用在自然語言處理、圖像識別及語音識別等各種不同類型的深度學習任務中,是深度學習技術中最值得關注與深入了解的核心技術之一。本文以機器翻譯為例,深入淺出地介紹了深度學習中注意力機制...

閱讀 1411·2021-10-11 11:12
閱讀 3244·2021-09-30 09:46
閱讀 1633·2021-07-28 00:14
閱讀 3132·2019-08-30 13:49
閱讀 2581·2019-08-29 11:27
閱讀 3211·2019-08-26 11:52
閱讀 598·2019-08-23 18:14
閱讀 3435·2019-08-23 16:27




