資訊專欄INFORMATION COLUMN

摘要:以攻擊模型為例,介紹生成攻擊樣本的基本原理。總結(jié)本章介紹了對抗樣本的基本原理,并以最簡單的梯度下降算法演示了生成對抗樣本的基本過程,大家可能會因為它的效率如此低而印象深刻。
對抗樣本是機器學習模型的一個有趣現(xiàn)象,攻擊者通過在源數(shù)據(jù)上增加人類難以通過感官辨識到的細微改變,但是卻可以讓機器學習模型接受并做出錯誤的分類決定。一個典型的場景。
概述
對抗樣本是機器學習模型的一個有趣現(xiàn)象,攻擊者通過在源數(shù)據(jù)上增加人類難以通過感官辨識到的細微改變,但是卻可以讓機器學習模型接受并做出錯誤的分類決定。一個典型的場景就是圖像分類模型的對抗樣本,通過在圖片上疊加精心構(gòu)造的變化量,在肉眼難以察覺的情況下,讓分類模型產(chǎn)生誤判。

在原理上介紹對抗樣本,以經(jīng)典的二分類問題為例,機器學習模型通過在樣本上訓(xùn)練,學習出一個分割平面,在分割平面的一側(cè)的點都被識別為類別一,在分割平面的另外一側(cè)的點都被識別為類別二。

生成攻擊樣本時,我們通過某種算法,針對指定的樣本計算出一個變化量,該樣本經(jīng)過修改后,從人類的感覺無法辨識,但是卻可以讓該樣本跨越分割平面,導(dǎo)致機器學習模型的判定結(jié)果改變。
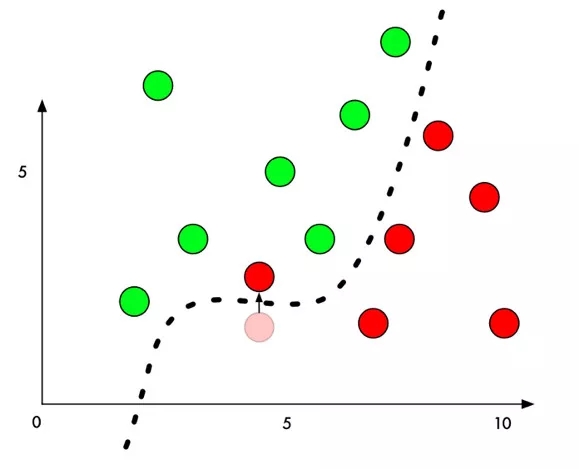
如何高效的生成對抗樣本,且讓人類感官難以察覺,正是對抗樣本生成算法研究領(lǐng)域的熱點。
梯度算法和損失函數(shù)
對抗樣本其實對機器學習模型都有效,不過研究的重點還是在神經(jīng)網(wǎng)絡(luò)尤其是深度學習網(wǎng)絡(luò)領(lǐng)域。理解對抗樣本算法,需要一定的神經(jīng)網(wǎng)絡(luò)的知識。在深度學習模型里面,經(jīng)常需要使用梯度算法,針對損失函數(shù)的反饋不斷調(diào)整各層的參數(shù),使得損失函數(shù)最小化。損失函數(shù)可以理解為理想和現(xiàn)實之間的差距,通常定義一個函數(shù)來描述真實值和預(yù)測值之間的差異,在訓(xùn)練階段,真實值就是樣本對應(yīng)的真實標簽和預(yù)測值就是機器學習模型預(yù)測的標簽值,這些都是明確的,所以損失函數(shù)是可以定義和計算的。在分類問題中,常見的損失函數(shù)包括 ? ? ? ?binary_crossentropy和categorical_crossentropy。
binary_crossentropy
binary_crossentropy亦稱作對數(shù)損失,
categorical_crossentropy
categorical_crossentropy亦稱作多類的對數(shù)損失
機器學習模型訓(xùn)練的過程就是不斷調(diào)整參數(shù)追求損失函數(shù)最小的過程。梯度可以理解為多元函數(shù)的指定點上升的坡度。梯度可以用偏導(dǎo)數(shù)來定義,通常損失函數(shù)就是這個多元函數(shù),特征向量就可以看成這個多元函數(shù)的某個點。在訓(xùn)練過程中,針對參數(shù)的調(diào)整可以使用梯度和學習率來定義,其中學習率也叫做學習步長,物理含義就是變量在梯度方向上移動的長度,學習率是一個非常重要的參數(shù),過大會導(dǎo)致?lián)p失函數(shù)的震蕩難以收斂,過小會導(dǎo)致計算緩慢,目前還沒有很成熟的理論來推導(dǎo)最合適的學習率,經(jīng)驗值是0.001-0.1之間,迭代更新參數(shù)x的方法為:
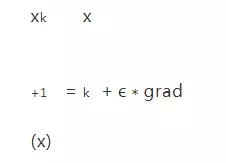
當我們求函數(shù)的較大值時,我們會向梯度向上的方向移動,所以使用加號,也成為梯度向上算法。如果我們想求函數(shù)的最小值時,則需要向梯度向下的方向移動,也成為梯度下降算法。所以使用減號,比如求損失函數(shù)最小值是,對應(yīng)迭代求解的方法為:
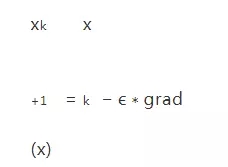
我們通過一個非常簡單的例子演示這個過程,假設(shè)我們只有一個變量x,對應(yīng)的損失函數(shù)定義為:
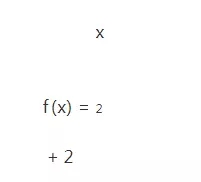
根據(jù)梯度的定義,可以獲得對應(yīng)的梯度為:
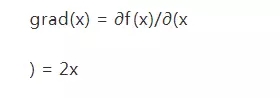
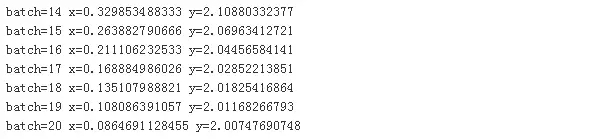
我們隨機初始化x,學習率設(shè)置為0.1,整個過程如下:

整個迭代過程最多100步,由于我們預(yù)先知道函數(shù)的最小值為2,所以如果當計算獲得的函數(shù)值非常接近2,我們也可以提前退出迭代過程,比如值相差不超過0.01。最后果然沒讓我們失望,在迭代20次后就找到了接近理論上的最小點。
Keras里面提供相應(yīng)的工具返回loss函數(shù)關(guān)于variables的梯度,variables為張量變量的列表,這里的loss函數(shù)即損失函數(shù)。

Keras也提供了function用于實例化一個Keras函數(shù),inputs是輸入列表列表,其元素為占位符或張量變量,outputs為輸出張量的列表
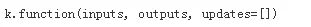
在進行神經(jīng)網(wǎng)絡(luò)訓(xùn)練時,追求的是損失函數(shù)最小,因此每輪訓(xùn)練時,通過訓(xùn)練集數(shù)據(jù)與模型的參數(shù)進行矩陣計算,獲得預(yù)測值,這一過程成為正向傳遞。然后通過計算預(yù)測值與目標值的損失函數(shù),通過鏈式法則,計算出梯度值,然后根據(jù)梯度下降算法調(diào)整模型的參數(shù)值,這一過程成為反向傳遞。經(jīng)過若干輪訓(xùn)練后,損失函數(shù)下降到可以接受的程度,模型的參數(shù)也完成了調(diào)整,整個訓(xùn)練過程結(jié)束。

攻擊InceptionV3模型
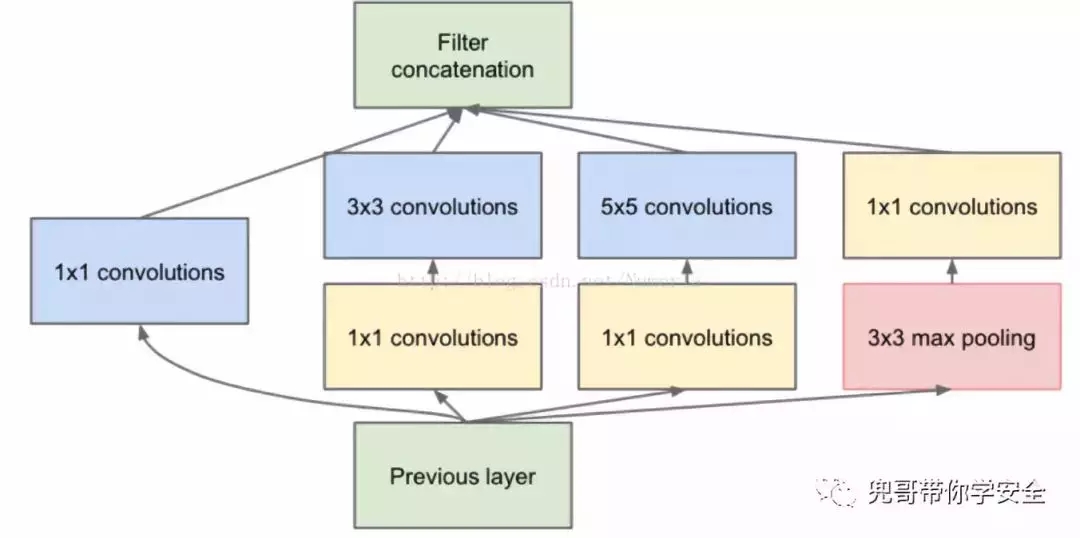
一般的卷積層只是一味增加卷積層的深度,但是在單層上卷積核卻只有一種,這樣特征提取的功能可能就比較弱。Google增加單層卷積層的寬度,即在單層卷積層上使用不同尺度的卷積核,他們構(gòu)建了Inception這個基本單元,基本的Inception中有1x1卷積核,3x3卷積核,5x5卷積核還有一個3x3下采樣,從而產(chǎn)生了InceptionV1模型。InceptionV3的改進是使用了2層3x3的小卷積核替代了5x5卷積核。
以攻擊InceptionV3模型為例,介紹生成攻擊樣本的基本原理。Keras內(nèi)置了這個模型,我們直接使用就可以了。從模型中直接獲取第一層的輸入作為輸入層,最后一層的輸出為輸出層。

然后加載我們攻擊的圖片,比如我們的小豬。這里需要特別強調(diào)的是,NumPy出于性能考慮,默認的變量賦值會引用同樣一份內(nèi)存,所以我們需要使用np.copy手工強制復(fù)制一份圖像數(shù)據(jù)。

為了避免圖像變化過大,超過肉眼可以接受的程度,我們需要定義閾值。

下面我們要定義最關(guān)鍵的三個函數(shù)了,我們定義損失函數(shù)為識別為烤面包機的概率,因此我們需要使用梯度上升算法,不斷追求損失函數(shù)的較大化,變量object_type_to_fake定義的就是烤面包機對應(yīng)的標簽,在InceptionV3中面包機的標簽為859。
object_type_to_fake = 859
有了損失函數(shù)以后,我們就可以通過Keras的接口獲取到對應(yīng)的梯度函數(shù)。最后通過K.function獲取一個Keras函數(shù)實例,該函數(shù)的輸入列表分別為輸入層和當前是訓(xùn)練模式還是測試模式的標記learning_phase(),輸出列表是損失函數(shù)和梯度。關(guān)于K.function的使用建議閱讀Keras的在線文檔。

下面我們就可以開始通過訓(xùn)練迭代最終獲得我們需要的圖片了,我們認為烤面包機的概率超過60%即可,所以我們定義損失函數(shù)的值超過0.6即可以完成訓(xùn)練。我們設(shè)置使用訓(xùn)練模式,learning_phase()標記為0,使用梯度上升的算法迭代獲取新的圖片內(nèi)容。為了不影響肉眼識別,超過閾值的部分會截斷,這部分功能使用NumPy的np.clip即可完成。

我們輸出梯度的內(nèi)容,便于我們理解。

訓(xùn)練完成后,保存圖片即可。這里需要說明的是,圖像保存到NumPy變量后,每個維度都是0-255之間的整數(shù),需要轉(zhuǎn)換成-1到1之間的小數(shù)便于模型處理。保存成圖像的時候需要再轉(zhuǎn)換回以前的范圍。

在我的Mac本經(jīng)過接近2個小時3070次迭代訓(xùn)練,獲得了新的家豬圖像,但是機器學習模型識別它為烤面包機的概率卻達到了95.61%,我們攻擊成功。在GPU服務(wù)器上大致運行5分鐘可以得到一樣的結(jié)果。

總結(jié)
本章介紹了對抗樣本的基本原理,并以最簡單的梯度下降算法演示了生成對抗樣本的基本過程,大家可能會因為它的效率如此低而印象深刻。后面我們將進一步介紹常見的幾種生成對抗樣本的算法。
參考文獻
https://medium.com/@ageitgey/machine-learning-is-fun-part-8-how-to-intentionally-trick-neural-networks-b55da32b7196
https://blog.csdn.net/u012223913/article/details/68942581
Ian J. Goodfellow, Jonathon Shlens & Christian Szegedy,EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES,arXiv:1412.6572
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4772.html
摘要:引用格式王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍生成對抗網(wǎng)絡(luò)的研究與展望自動化學報,論文作者王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍摘要生成式對抗網(wǎng)絡(luò)目前已經(jīng)成為人工智能學界一個熱門的研究方向。本文概括了的研究進展并進行展望。 3月27日的新智元 2017 年技術(shù)峰會上,王飛躍教授作為特邀嘉賓將參加本次峰會的 Panel 環(huán)節(jié),就如何看待中國 AI學術(shù)界論文數(shù)量多,但大師級人物少的現(xiàn)...
摘要:很多人可能會問這個故事和生成式對抗網(wǎng)絡(luò)有什么關(guān)系其實,只要你能理解這段故事,就可以了解生成式對抗網(wǎng)絡(luò)的工作原理。 男:哎,你看我給你拍的好不好?女:這是什么鬼,你不能學學XXX的構(gòu)圖嗎?男:哦……男:這次你看我拍的行不行?女:你看看你的后期,再看看YYY的后期吧,呵呵男:哦……男:這次好點了吧?女:呵呵,我看你這輩子是學不會攝影了……男:這次呢?女:嗯,我拿去當頭像了上面這段對話講述了一位男...
摘要:但年在機器學習的較高級大會上,蘋果團隊的負責人宣布,公司已經(jīng)允許自己的研發(fā)人員對外公布論文成果。蘋果第一篇論文一經(jīng)投放,便在年月日,斬獲較佳論文。這項技術(shù)由的和開發(fā),使用了生成對抗網(wǎng)絡(luò)的機器學習方法。 GANs「對抗生成網(wǎng)絡(luò)之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演講是聊他的代表作生成對抗網(wǎng)絡(luò)(GAN/Generative Adversarial ...

閱讀 1583·2021-10-18 13:35
閱讀 2362·2021-10-09 09:44
閱讀 816·2021-10-08 10:05
閱讀 2718·2021-09-26 09:47
閱讀 3564·2021-09-22 15:22
閱讀 432·2019-08-29 12:24
閱讀 1999·2019-08-29 11:06
閱讀 2857·2019-08-26 12:23




