資訊專欄INFORMATION COLUMN

摘要:或許是有的這是一篇關于隨機加權平均的新論文所獲得的成果。隨機加權平均,隨機加權平均和快速幾何集成非常近似,除了計算損失的部分。
在這篇文章中,我將討論最近兩篇有趣的論文。它們提供了一種簡單的方式,通過使用一種巧妙的集成方法提升神經網絡的性能。
Garipov 等人提出的 “Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs” ?
https://arxiv.org/abs/1802.10026
Izmailov 等人提出的 “Averaging Weights Leads to Wider Optima and Better Generalization”?
https://arxiv.org/abs/1803.05407
若希望更容易理解這篇博客,可以先閱讀這一篇論文:
Vitaly Bushaev 提出的 “Improving the way we work with learning rate”?
https://techburst.io/improving-the-way-we-work-with-learning-rate-5e99554f163b
傳統的神經網絡集成方法
傳統的集成方法通常是結合幾種不同的模型,并使他們對相同的輸入進行預測,然后使用某種平均方法得到集合的最終預測。 它可以是簡單的投票法,平均法。或者甚至可以使用另一個模型,根據集成模型的輸入學習并預測正確的值或標簽。嶺回歸是一種特殊的集成方法,被許多在 Kaggle 競賽獲獎的機器學習從業人員所使用。

網絡快照集成法是在每次學習率周期結束時保存模型,然后在預測過程中同時使用保存下來的模型。
當集成方法應用在深度學習中時,可以通過組合多個神經網絡的預測,從而得到一個最終的預測結果。通常情況下,集成不同結構的神經網絡是一個很好的方法,因為不同的模型可能在不同的訓練樣本上犯錯,因此集成模型將會得到更大的好處。
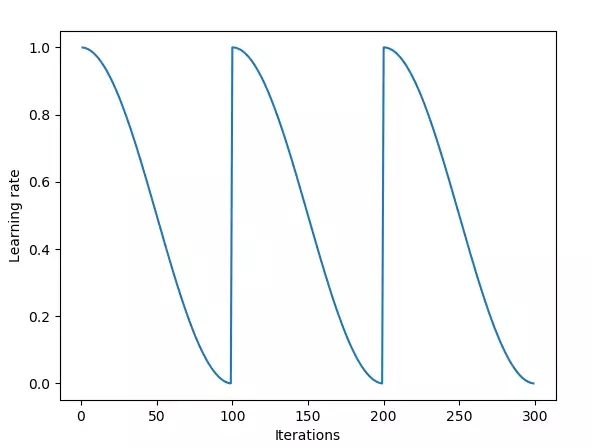
網絡快照集成法使用基于退火策略的循環學習率策略。
但是,你也可以集成相同結構的神經網絡模型,也會得到很棒的結果。在網絡快照集成法論文中,作者基于這種方法使用了一個非常酷的技巧。作者在訓練相同網絡時使用權重快照,在訓練結束后用這些結構相同但權重不同的模型創建一個集成模型。這種方法使測試集效果提升,而且這也是一種非常簡單的方法,因為你只需要訓練一次模型,將每一時刻的權重保存下來就可以了。
想要了解更多的細節,你可以參考這個博客。如果你還沒有使用循環學習率策略,那么你一定要了解它。因為這是當前較先進而且最簡單的訓練技巧了,計算量不大,也幾乎不需要額外成本就可以提供很大的收益。
上面的例子都是基于模型的集成方法,因為它們是通過結合多個模型的預測從而產生最終的預測結果。
但在這篇博客即將討論的論文中,作者提出了一種新的基于權重的集成方法。這種方法通過結合相同網絡結構不同訓練階段的權重獲得集成模型,然后進行預測。這種方法有兩個優點:
當結合權重時,我們最后仍然是得到一個模型,這提升了預測的速度
實驗結果表明,這種方法打敗了當前較先進的網絡快照集成法
來看看它是怎么實現的吧。但首先我們需要了解一些關于損失平面和泛化問題的重要結論。
權重空間中的解決方案
第一個重要的觀點是:一個訓練好的網絡是多維權重空間中的一個點。對于一個給定的網絡結構,每一種不同的權重組合將得到不同的模型。因為所有模型結構都有無限多種權重組合,所以將有無限多種組合方法。訓練神經網絡的目標是找到一個特別的解決方案(權重空間中的點),從而使訓練集和測試集上的損失函數的值達到很小。
訓練過程中,通過改變權重,訓練算法改變網絡的結構,并在權重空間中不斷搜索。隨機梯度下降法在損失平面上傳播,損失平面的高低由損失函數的值決定。
局部與全局最優解
可視化與理解多維權重空間的幾何特點是非常困難的。同時,這也是非常重要的,因為在訓練時,隨機梯度下降法的本質是在多維空間的損失平面上傳播,并努力找到一個好的解決方案--損失平面上的一個損失函數值很低的"點”。眾所周知,這些平面有許多局部最優解,但并不是所有局部最優解都是優秀的解決方案。
Hinton: “為了處理14維空間中的超平面, 可視化3維空間并大聲對自己說“14”。 每個人都這樣做。“
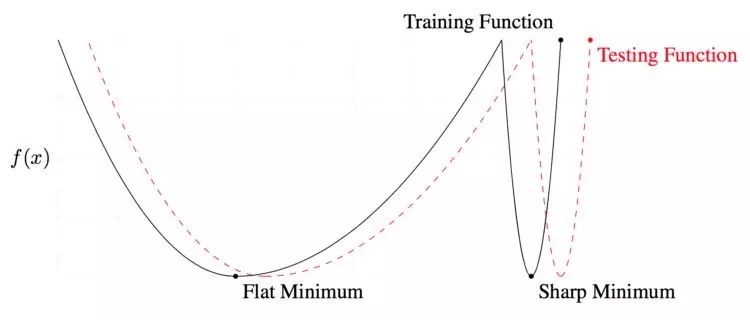
局部和全局最優解。在訓練和測試過程中,平滑的較低值會產生相似的損失。然而,訓練和測試過程中產生的局部損失,有非常大的差異。換句話說,全局最小值比局部最小值更通用。
判斷解決方案好壞的一個標準就是該方案解的平滑性。 這一思想在于訓練數據和測試數據會產生類似的但并不完全一樣的損失面。你可以想象一下,一個測試表面相對于訓練表面移動一點。對于一個局部解,在測試過程中,因為這一點移動,一個給出低損失值的點會給出一個高損失值。這意味著這個”局部“解決方案沒有產生最優值——訓練損失小,而測試損失大。另一方面,對于一個”全局“平滑解決方案,這一點移動會導致訓練和測試損失的差值很小。
我之所以解釋局部和全局解決方案的不同,是因為這篇博客聚焦的新方法提供非常好的全局解決方案。
快照集成
最初,隨機梯度下降(SGD,Stochastic Gradient Descent) 會在權重空間產生大的躍變。隨后,當學習率由于余弦退火算法越來越小時, SGD 會收斂到某個局部解,該算法會對模型拍個”快照“,即將這個局部解加入到集合中。接著,學習率再次被重置成高值,SGD在收斂到某個不同的局部解之前,再次產生一個大的躍變。
快照集成方法的循環長度是20到40個 epoch(使用訓練集的全部數據對模型進行一次完整的訓練,稱為一個epoch)。長學習率循環的思想在于能夠在權重空間找到足夠多不同的模型。如果模型相似度太高,集合中各網絡的預測就會太接近,而體現不出集成帶來的好處。
快照集成確實效果很好,提高了模型的性能,但是快速幾何集成更有效。
快速幾何集成 (FGE)
快速幾何集成與快照集成類似,但有一些與快照集成不同的特征。FGE使用線性分段循環學習率策略代替余弦。其次,FGE的循環長度更短——每個循環只有2到4個epoch。最初的直覺認為,短循環是錯誤的,因為每次循環結束時產生的模型都非常相似,差別不大,所以集成這些模型不能帶來益處。然而,正如作者發現的,由于在足夠多的不同模型間,存在低損失的連接通路,沿著那些通路,采用短循環是可行的,而且在這一過程中,會產生差異足夠大的模型,集成這些模型會產生很好的結果。因此,與快照集成相比,FGE提高了模型的性能,每次循環經過更少的epoch就能找到差異足夠大的模型(這使訓練速度更快)。
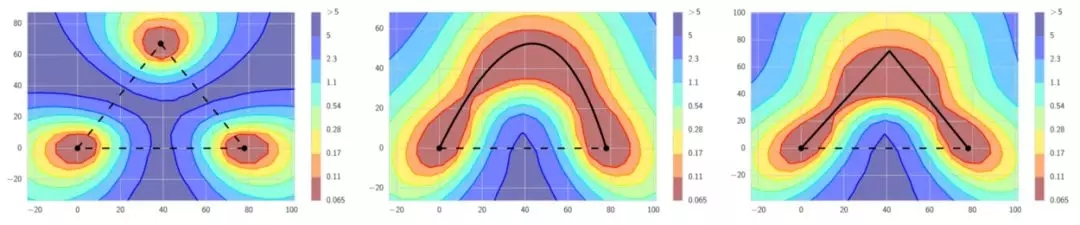
左邊:傳統觀點認為好的局部最小值被高損失區域分隔開。如果我們觀察連接局部最小值的直線,會發現這是正確的。中間和右邊:然而,在局部最小值之間存在通路,這些通路上的損失值始終很低。FGE沿著這些通路拍快照,并利用這些快照構建一個集合。
為了從快照集成或者FGE中獲益,需要存儲多種模型并得出這些模型的預測,然后對這些預測求平均,作為最終的預測。因此,集合的附加性能需要消耗更多的計算。所以沒有免費的午餐。或許是有的?這是一篇關于隨機加權平均的新論文所獲得的成果。
隨機加權平均(SWA,Stochastic Weight Averaging)
隨機加權平均和快速幾何集成非常近似,除了計算損失的部分。 SWA 可以應用于任何架構和數據集,而且都能產生較好的結果。這篇論文給出了參考建議,SWA可以得到更大范圍的最小值,上文已經討論過這一點的好處。SWA不是經典意義上的集成。在訓練結束的時候,會產生一個模型,這個模型的性能優于快照集成,接近FGE。?
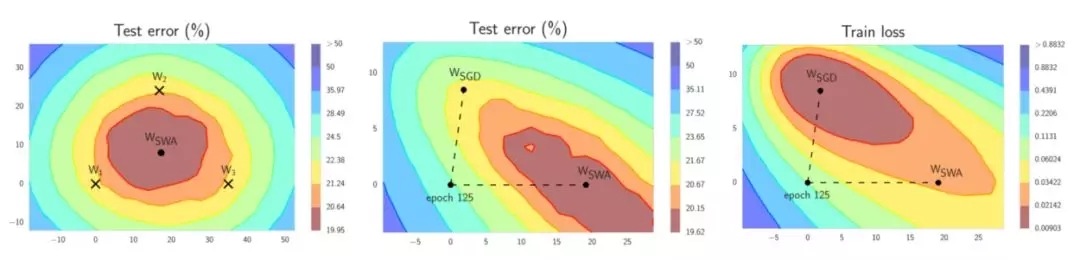
左邊:W1,W2和W3 代表了3個獨立的訓練網絡,Wswa是它們的平均。 中間:與SGD相比,Wswa 在測試集上產生了更優越的性能。右邊:注意即使Wswa在訓練集上的性能更差,它在測試集上的效果仍然更好。
SWA的靈感來自于實際觀察,每次學習率循環結束時產生的局部最小值趨向于在損失面的邊緣區域累積,這些邊緣區域上的損失值較小(上面左圖中,顯示低損失的紅色區域上的點W1,W2和W3)。通過對幾個這樣的點取平均,很有可能得到一個甚至更低損失的、全局化的通用解(上面左圖上的Wswa)。
這兒展示了 SWA 是如何工作的。不需要集成很多模型,只需要兩個模型。
第一個模型存儲模型權重的平均值(公式中的 w_swa )。這就是訓練結束后的最終模型,用于預測。
第二個模型(公式中的w)變換權重空間,利用循環學習率策略找到最優權重空間。

隨機加權平均權重更新公式
每次學習率循環結束的時候,第二個模型的當前權重會被用于更新正在運行的平均模型的權重,即對已有的平均權重和第二個模型產生的新權重進行加權平均(左圖中的公式)。采用這個方法,訓練時,只需要訓練一個模型,存儲兩個模型。而預測時,只需要一個當前的平均模型進行預測。用這個模型做預測,比前面提到的方法,速度快得多。之前的方法是用集合中的多個模型做預測,然后對多個預測結果求平均。
實現
該論文的作者提供了他們自己的實現,這個實現是用PyTorch完成的。
當然,著名的fast.ai庫也實現了SWA。每個人應該都在使用這個庫。如果你還沒有看到這個課程,請點擊此鏈接。
感謝您的閱讀!
原文鏈接:
https://towardsdatascience.com/stochastic-weight-averaging-a-new-way-to-get-state-of-the-art-results-in-deep-learning-c639ccf36a
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4771.html
摘要:機器學習系統被用來識別圖像中的物體將語音轉為文本,根據用戶興趣自動匹配新聞消息或產品,挑選相關搜索結果。而深度學習的出現,讓這些問題的解決邁出了至關重要的步伐。這就是深度學習的重要優勢。 借助深度學習,多處理層組成的計算模型可通過多層抽象來學習數據表征( representations)。這些方法顯著推動了語音識別、視覺識別、目標檢測以及許多其他領域(比如,藥物發現以及基因組學)的技術發展。...
摘要:三大牛和在深度學習領域的地位無人不知。逐漸地,這些應用使用一種叫深度學習的技術。監督學習機器學習中,不論是否是深層,最常見的形式是監督學習。 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度學習領域的地位無人不知。為紀念人工智能提出60周年,的《Nature》雜志專門開辟了一個人工智能 + 機器人專題 ,發表多篇相關論文,其中包括了Yann LeC...
摘要:和的得分均未超過右遺傳算法在也表現得很好。深度遺傳算法成功演化了有著萬自由參數的網絡,這是通過一個傳統的進化算法演化的較大的神經網絡。 Uber 涉及領域廣泛,其中許多領域都可以利用機器學習改進其運作。開發包括神經進化在內的各種有力的學習方法將幫助 Uber 發展更安全、更可靠的運輸方案。遺傳算法——訓練深度學習網絡的有力競爭者我們驚訝地發現,通過使用我們發明的一種新技術來高效演化 DNN,...

閱讀 817·2021-10-13 09:39
閱讀 3697·2021-10-12 10:12
閱讀 1741·2021-08-13 15:07
閱讀 1005·2019-08-29 15:31
閱讀 2882·2019-08-26 13:25
閱讀 1776·2019-08-23 18:38
閱讀 1878·2019-08-23 18:25
閱讀 1857·2019-08-23 17:20




