資訊專欄INFORMATION COLUMN

摘要:和的得分均未超過右遺傳算法在也表現得很好。深度遺傳算法成功演化了有著萬自由參數的網絡,這是通過一個傳統的進化算法演化的較大的神經網絡。
Uber 涉及領域廣泛,其中許多領域都可以利用機器學習改進其運作。開發包括神經進化在內的各種有力的學習方法將幫助 Uber 發展更安全、更可靠的運輸方案。
遺傳算法——訓練深度學習網絡的有力競爭者
我們驚訝地發現,通過使用我們發明的一種新技術來高效演化 DNN,一個極其簡單的遺傳算法(GA)可以訓練含有超過 400 萬參數的深度卷積網絡,從而可以在像素級別上玩 Atari 游戲;而且,它能在許多游戲中比現代深度強化學習(RL)算法(例如 DQN 和 A3C)或進化策略(ES)表現得更好,同時由于更好的并行化能達到更快的速度。這個結果非常出乎意料:遺傳算法并非基于梯度進行計算,沒人能預料遺傳算法能擴展到如此大的參數空間;而且,使用遺傳算法卻能與較先進的強化學習算法媲美、甚至超過強化學習,這在以前看來是根本不可能的。我們進一步表明,現代遺傳算法的增強功能提高了遺傳算法的能力,例如新穎性搜索(novelty research),它同樣在 DNN 規模上發揮作用,且能夠促進對于欺騙性問題(存在挑戰性局部最優的問題)的探索。要知道,這些欺騙性問題通常對獎勵最優化算法形成障礙,例如 Q 學習(DQN)、策略梯度算法(A3C)、進化策略(ES)以及遺傳算法。
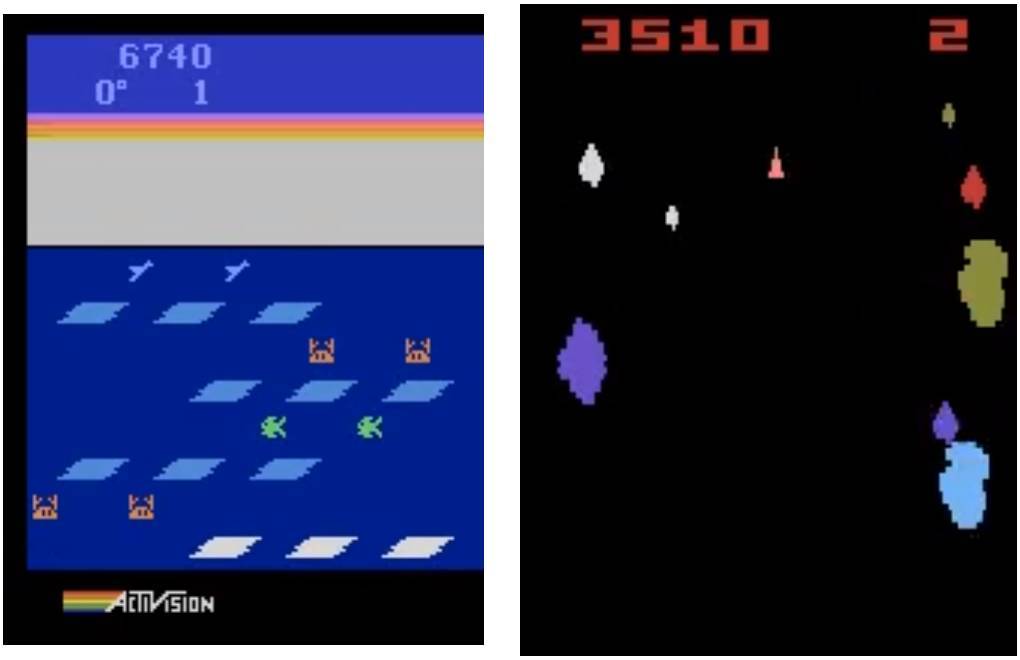
左:遺傳算法在 Frostbite 中得分 10500。DQN、AC3 和 ES 的得分均未超過 1000;右:遺傳算法在 Asteroids 也表現得很好。它的平均表現超越了 DQN 和 ES,但沒有超過 A3C。
通過梯度計算的安全突變
在論文「Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients」中,我們展示了如何將神經進化和梯度相結合,以提高循環神經網絡和深度神經網絡的進化能力。這種方法可以使上百層的深度神經網絡成功進化,遠遠超過了以前的神經進化方法所展示的可能性。我們通過計算網絡輸出關于權重的梯度(即,和在傳統深度學習中使用誤差梯度不同)來實現這一點,使得在隨機突變的校準過程中,對最敏感的變量(相比其他變量而言)進行更加精細的處理,從而解決大型網絡中隨機變量的一個主要問題。

這兩個動畫展示了用于解決迷宮問題的單個網絡的一批突變(左下角是起點,左上角是終點)。一般的突變大多不能解決這個問題,但是安全突變很大程度地在產生多樣性的同時保留了解決問題的能力,表明了安全突變的顯著優勢。
ES 如何與 SGD 聯系起來?
我們的論文對 A Visual Guide to Evolution Strategies(參見「從遺傳算法到 OpenAI 新方向:進化策略工作機制全解」)進行了補充和完善。這是由 OpenAI 團隊首先提出的想法(https://blog.openai.com/evolution-strategies/),即 ES 的變型——神經進化——可以在深度強化學習任務中競爭性地優化深度神經網絡。但是,迄今為止,這個結果有沒有更廣泛的應用仍然只是猜想。通過進一步創新 ES,我們通過一個綜合研究「On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent」深入了解 ES 和 SGD 的關聯,探索 ES 梯度近似實際上和在 MNIST 中通過 SGD 在每個 mini-batch 上計算的的最優梯度的聯系有多緊密,以及這種近似如何導致了優越的性能。我們發現,如果提供足夠的計算來改善梯度近似,ES 能在 MNIST 上實現 99% 的準確率,這暗示著 ES 何以愈發成為深度強化學習的有力競爭者——因為在并行計算增加時,還沒有方法能獲得完美的梯度信息。
ES 不只是傳統的有限差分
為了增加理解,一個伴隨性研究「ES Is More Than Just a Traditional Finite-Difference Approximator」經驗地證實,ES(具有足夠大的擾動尺寸參數)的行為與 SGD 表現得有差別。這是因為 ES 優化的是一代策略群體(由概率分布描述,即搜索空間中的「云」)的預期回報,但 SGD 僅為單一的策略(搜索空間中的「點」)優化回報。這種變化使得 ES 可以訪問搜索空間的不同區域,無論是好是壞(這兩種情況都被示出)。對每代的參數擾動進行優化的另一個結果是,ES 獲得了魯棒性,這是 SGD 不能做到的。強調 ES 優化每代的參數這一做法,同樣強調了 ES 和貝葉斯算法中的有趣聯系。
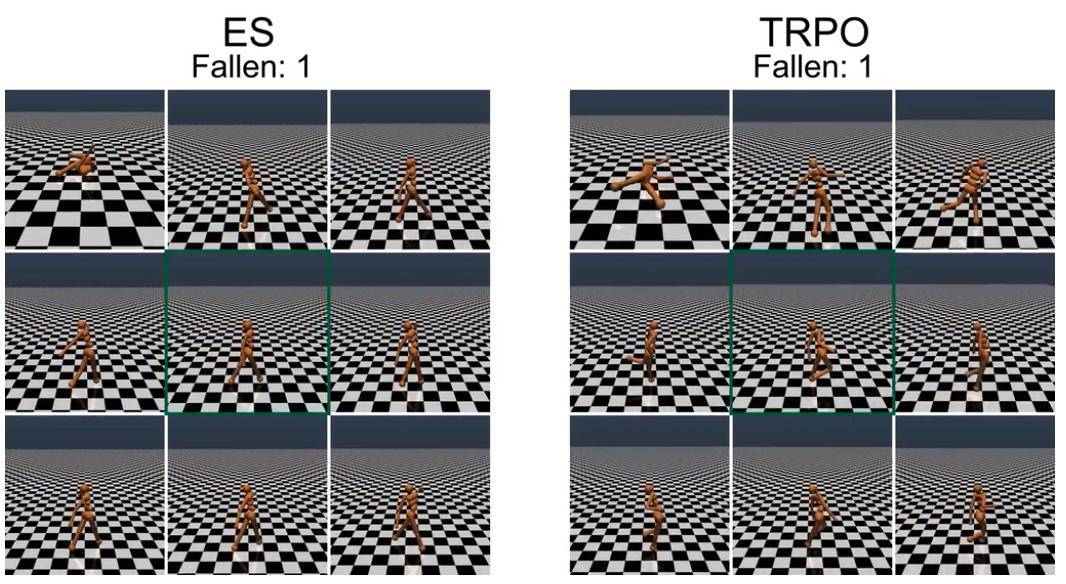
對步行者進行重量的隨機擾動,TRPO 訓練的步行者會產生明顯的不穩定步態,而 ES 進化的步行者步態顯得更加穩定。初始的訓練步行者位于每個 9 幀合成的中心(綠框)。

傳統的有限差分(梯度下降)不能跨越低適合度(fitness)的窄縫,但 ES 能容易地穿過并尋找另一側的更高適合度。

ES 會在高適合度的窄縫中慢慢停止,但傳統的有限差分(梯度下降)會毫無停頓地通過相同的路徑。這與前面的動畫一起說明了兩種不同方法的區別和權衡。
加強對 ES 的探索
深度神經進化有一個令人興奮的結果:之前為神經進化開發的工具集,現在成為了加強深度神經網絡訓練的候選者。我們通過引入新的算法「Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents」進行探索,這種算法將 ES 的優化能力和可擴展性與神經進化所獨有的、通過群體激勵將不同智能體區別開的促進強化學習領域的探索結合起來。這種基于群體的探索有別于強化學習中單一智能體傳統,包括最近在深度強化學習領域的探究工作。我們的實驗表明,通過增加這種新的探索方式,能夠提高 ES 在許多需要探索的領域(包括一些 Atari 游戲和 Mujoco 模擬器中的類人動作任務)的性能,從而避免欺騙性的局部最優。
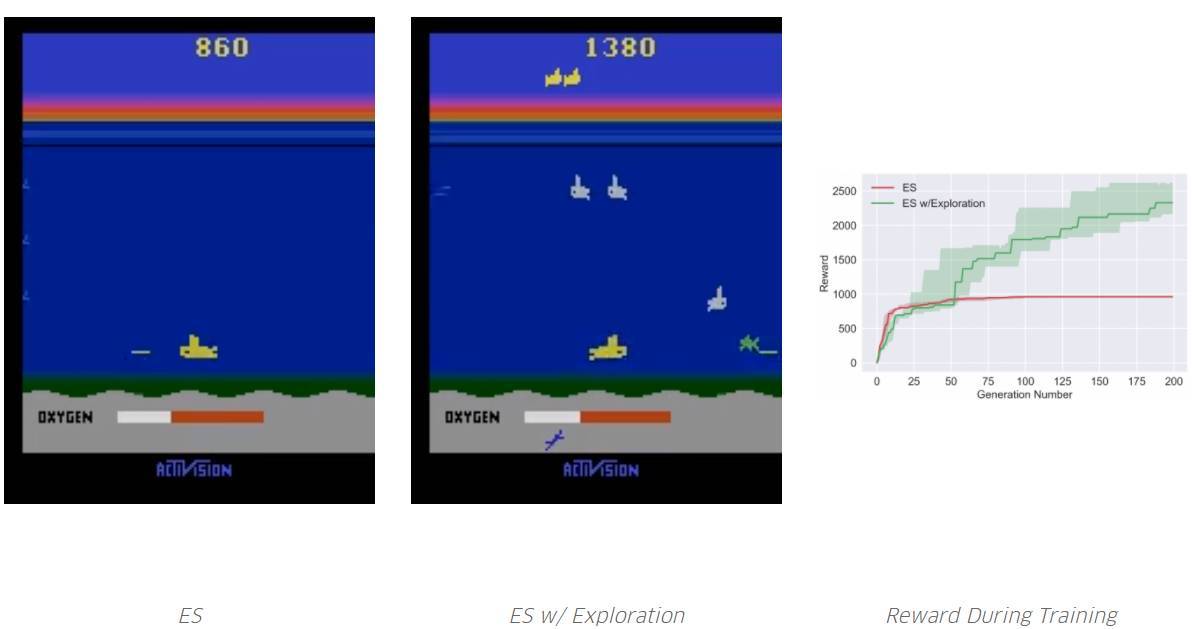
通過使用我們的超參數,ES 迅速收斂到局部最優,即不需要再次吸入氧氣,因為吸入氧氣暫時不能獲得獎勵。但是,通過探索,它學會了如何吸入氧氣,從而在未來獲得更高的獎勵。請注意,Salimans et al. 2017 并沒有報道 ES,根據他們的超參數,他們能夠實現特定的局部最優。但是,就像我們所展示的,沒有 ES,它很容易無限期地困在某些局部最優處(而那個探索能夠幫助它跳出局部最優)。
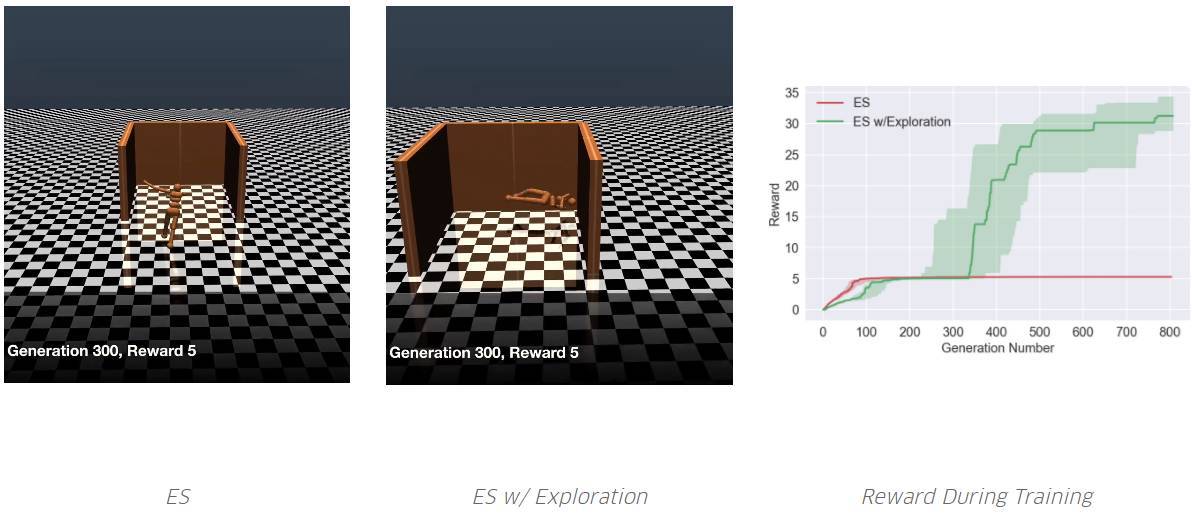
智能體需要學著跑得盡可能遠。ES 從未學過避免欺騙性的陷阱。但是,通過添加一個探索壓力,其中一個學會了繞過陷阱。
結論
對有志于轉向深度神經網絡的神經進化研究人員,有幾個重要因素值得考慮:首先,這種類型的實驗需要的計算量比以前更多;對于這些新論文中的實驗,我們經常需要運行成百上千個同步 CPU。但是,對 GPU 或 CPU 的需求不應該被視為一個負擔;從長遠來看,面對即將到來的世界,向大規模并行計算中心的規模變化也許意味著神經進化能利用未來的優勢。
新的結果與之前在低維神經進化中觀察到的結果有顯著差異。它們有效推翻了多年來的直覺,特別是對高維度探索的潛力的啟發。正如在深度學習中發現的那樣,在復雜性的某些閾值之上,在高維度的搜索似乎變得更加容易,因為它不易受到局部最優的影響。雖然深度學習已經對這種思維方式非常熟悉,但它的含義最近才在神經進化當中開始被理解。
神經進化的再度興起,是舊算法與當代計算量相結合產生驚人成果的另一個例子。神經進化的可行性非常有趣,因為在神經進化社區中開發的許多技術可以立即在 DNN 規模上變得可行,它們每個都提供了不同工具以解決具有挑戰性的問題。此外,正如我們的論文所展示的,神經進化搜索與 SGD 不同,因此為機器學習工具箱提供了有趣的替代方法。我們想知道,深度神經進化是否會像深度學習一樣經歷復興。如果是這樣,2017 年可能標志著這個時代的開始,我們也非常期待未來會發生什么!
下面是我們今天發布的 5 篇論文及關鍵發現的總結:
Deep Neuroevolution: Genetic Algorithms are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
用簡單、傳統、基于群體的遺傳算法演化 DNN,在困難的深度強化學習問題上表現良好。在 Atari 游戲中,遺傳算法表現良好,與 ES 以及基于 Q 學習(DQN)和政策梯度算法(A3C)的深度強化學習算法表現相當。
「深度遺傳算法(Deep GA)」成功演化了有著 400 萬自由參數的網絡,這是通過一個傳統的進化算法演化的較大的神經網絡。
表明了一個有趣的事實:在某些情況下,根據梯度更新不是優化性能的較佳選擇。
將 DNN 和新穎性搜索(Novelty Search)相結合,這種探索算法被設計用于欺騙性任務和稀疏獎勵函數,以解決欺騙性的高維問題。其中,獎勵較大化算法(例如 GA 和 ES)都在這類問題中失敗了。
表明 Deep GA 的并行度優于 DQN、A3C 和 ES,因此運行比它們都快。可實現當前較先進的緊湊編碼技術,只用幾千字節就可以表示百萬量級參數的 DNN。
包含在 Atari 中隨機搜索的結果。令人驚訝的是,在一些游戲中,隨機搜索大大優于 DQN、A3C 和 ES,不過它從沒有超過 GA。
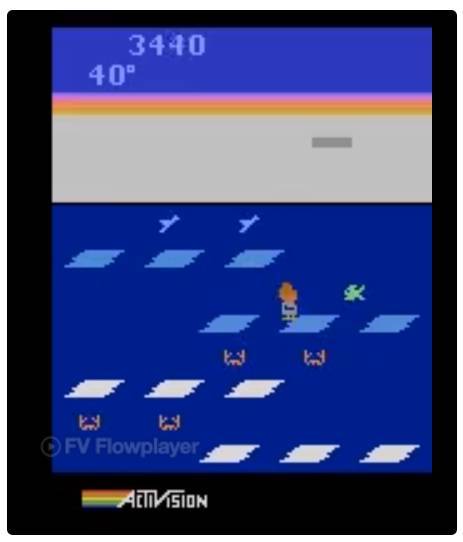
令人驚訝的是,在一個 DNN 中,隨機搜索能比 DQN、A3C 和 ES 在 Frostbite 游戲中表現得更好,但是還是不能超過 GA。
Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients
通過測量網絡敏感性改變特定連接權重,基于梯度的安全突變(SM-G)極大提高了大型深度循環網絡突變的效率。
計算關于權重的「輸出」梯度,而非如常規深度學習中誤差或損失函數的梯度,以允許隨機但安全的搜索步驟。
這兩種安全突變都不需要在領域當中的額外實驗或展示。
結果:深層神經網絡(超過 100 層)和大型循環網絡現在只能通過 SM-G 的各種變形有效演化。
On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
通過比較不同情況下由 ES 計算的近似梯度和由 SGD 在 MNIST 中計算的準確梯度探究 ES 和 SGD 的關系。
開發快速代理,預測不同群體規模的 ES 預期表現。
介紹并演示不同加速和改善 ES 性能的方法。
有限擾動 ES(Limited perturbation ES)顯著加快了在并行基礎設施上的執行速度。
「No-mini-batch ES」把針對 SGD 設計 mini-batch 傳統替換為適用于 ES 的不同方法,從而改進梯度估計:這是這樣一種算法,它在算法的每次迭代中,將整個訓練批的一個隨機子集分配給 ES 群體當中的每個成員。這種專用于 ES 的方法在等效計算的情況下提供了更好的準確度,且學習曲線甚至比 SGD 更加平滑。
「No-mini-batch ES」在測試運行中達到了 99% 的準確率,這是在本次監督學習任務中,進化方法的較佳報告性能。
總體上有助于說明為什么 ES 能在強化學習中成為有力競爭者。通過搜索域的實驗獲得的梯度信息與監督學習的性能目標相比,信息量更少。
ES Is More Than Just a Traditional Finite Difference Approximator
強調 ES 和傳統有限差分方法之間的重要區別,即 ES 優化的是較佳解決方案的分布函數(而非單個較佳的解決方案)。
一個有趣的結果:由 ES 發現的解決方案傾向于在參數擾動上保持魯棒性。例如,我們表明 ES 的仿人類行走解決方案比 GA 和 TRPO 實現的類似解決方案對參數擾動的魯棒性更強。
另一個重要結果:ES 可能可以解決傳統方法困擾的一些問題,反之亦然。通過簡單的例子說明 ES 和傳統梯度跟隨之間的不同動力學。
Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
增加在 ES 中鼓勵深度探索的能力。
表明通過探究不同代的智能體群體并用于促進小規模進化神經網絡中的探索性算法——特別是新穎性搜索(NS)和質量多樣性(QD)算法——能與 ES 結合,從而改善在稀疏或欺騙性深度強化學習任務當中的表現。
證實由此產生的新算法——NS-ES 和一個稱為 NSR-ES 的 QD-ES 版本——能夠避免 ES 所遭遇的局部最優問題,從而在某些任務中達到高性能。這些任務包括,模擬機器人學習繞過欺騙性陷阱達到高性能,以及 Atari 游戲當中的高維像素任務。
將這個基于群體的搜索算法系列添加到深度強化學習工具箱中。?
原文鏈接:https://eng.uber.com/deep-neuroevolution/
商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4700.html
摘要:通過在中結合進化算法執行架構搜索,谷歌開發出了當前較佳的圖像分類模型。本文是谷歌對該神經網絡架構搜索算法的技術解讀,其中涉及兩篇論文,分別是和。此外,谷歌還使用其新型芯片來擴大計算規模。 通過在 AutoML 中結合進化算法執行架構搜索,谷歌開發出了當前較佳的圖像分類模型 AmoebaNet。本文是谷歌對該神經網絡架構搜索算法的技術解讀,其中涉及兩篇論文,分別是《Large-Scale Ev...
摘要:近日,發表了一篇文章,詳細討論了為深度學習模型尋找較佳超參數集的有效策略。要知道,與機器學習模型不同,深度學習模型里面充滿了各種超參數。此外,在半自動全自動深度學習過程中,超參數搜索也是的一個非常重要的階段。 在文章開始之前,我想問你一個問題:你已經厭倦了小心翼翼地照看你的深度學習模型嗎?如果是的話,那你就來對地方了。近日,FloydHub Blog發表了一篇文章,詳細討論了為深度學習模型尋...
摘要:如今在機器學習中突出的人工神經網絡最初是受神經科學的啟發。雖然此后神經科學在機器學習繼續發揮作用,但許多主要的發展都是以有效優化的數學為基礎,而不是神經科學的發現。 開始之前看一張有趣的圖 - 大腦遺傳地圖:Figure 0. The Genetic Geography of the Brain - Allen Brain Atlas成年人大腦結構上的基因使用模式是高度定型和可再現的。 Fi...
摘要:世界杯小組賽將收官,你還依然信嗎冷門頻出,黑馬擊敗豪強。以本屆世界杯開幕戰俄羅斯對陣沙特阿拉伯的比賽為例,兩隊上次交手是在年的一場友誼賽,距今已經年。然后進入第二步,預測回報率導向。在足球領域,這個回報率已非常不俗。 世界杯小組賽將收官,你還依然信AI嗎?冷門頻出,黑馬擊敗豪強。不少AI模型始料未及。到底還能不能愉快找到科學規律?或者說足球比賽乃至其他競技體育賽事,數據科學家在AI加持下,究...

閱讀 2086·2021-11-24 10:34
閱讀 3060·2021-11-22 11:58
閱讀 3719·2021-09-28 09:35
閱讀 1730·2019-08-30 15:53
閱讀 2783·2019-08-30 14:11
閱讀 1558·2019-08-29 17:31
閱讀 547·2019-08-26 13:53
閱讀 2147·2019-08-26 13:45






