資訊專欄INFORMATION COLUMN

摘要:如今在機器學習中突出的人工神經網絡最初是受神經科學的啟發。雖然此后神經科學在機器學習繼續發揮作用,但許多主要的發展都是以有效優化的數學為基礎,而不是神經科學的發現。
開始之前看一張有趣的圖 - 大腦遺傳地圖:
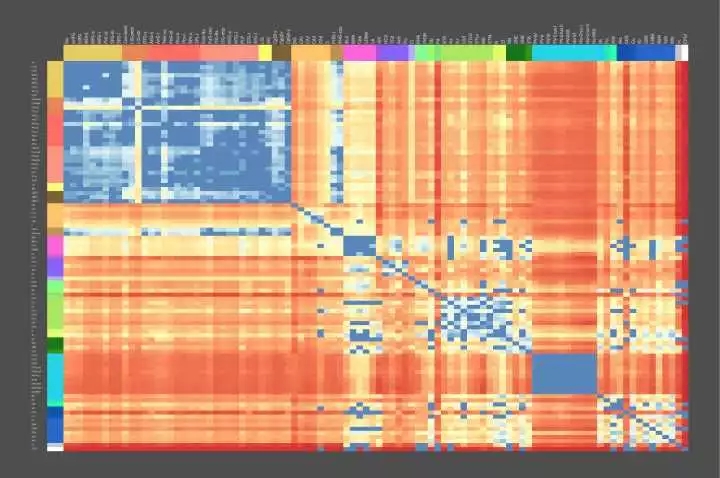
Figure 0. The Genetic Geography of the Brain - Allen Brain Atlas
成年人大腦結構上的基因使用模式是高度定型和可再現的。 Figure 0 中所示的動態熱圖表示跨個體的這種圖案化模式的共同結構,特別是一些介于解剖區域對(pairs of anatomic regions)之間差異表達的基因數目,在我們的實驗測量中,有5/6的大腦中發現了類似共同的模式。 熱紅色陰影代表在其轉錄調節中非常不同的腦區域,而較冷的藍色陰影代表高相似性的區域。
先看這張圖的用意是在于讓讀者了解目前大腦、神經科學的前沿,人類不僅具有了解全部大腦基本功能的能力,并且已經具備將各功能區域映射到自身遺傳物質編碼上的能力。不僅如此,更多先進的探測技術已經能讓人們記錄下更詳細的神經元內部的活動(dynamics),這使得對大腦內部計算結構的分析成為可能,上圖所示內容凝結了眾多科學家的努力,相信一定是21世紀最偉大的科學突破之一。
說明:
1. 翻譯這篇文章出于學習目的,有翻譯或者理解有誤的地方還望大家多多指教;
2. 本文可以任意轉載,支持知識分享,但請注明出處或附上原文地址;
3. 文章中所有的引用都在本文內嵌鏈接中可以找到,該論文有488篇引用!
4. 翻譯將進行連載,這是系列的第一部分,對應論文第一章;
Standing on the shoulders of giants, to touch the hands of "god".
引言
計算神經科學專注于計算的詳細實現,研究神經編碼、動力學和電路。然而,在機器學習中,人工神經網絡傾向于避開較精確設計的代碼,動力學或電路,有利于成本函數的強力優化(暴力搜索),通常使用簡單和相對均勻的初始架構。在機器學習中,近期的兩個發展方向創造了連接這些看似不同觀點的機會。首先,使用結構化體系架構,包括用于注意力機制,遞歸和各種形式的短期和長期存儲器存儲的專用系統(Specialized System)。第二,成本函數和訓練過程變得更加復雜,并且隨著時間的推移而變化。在這里我們根據這些想法思考大腦。我們假設(1)大腦優化成本函數,(2)成本函數是多樣的且在不同的發展階段大腦不同位置的成本函數是不同的,和(3)優化操作是在一個由行為預先架構好的、與對應計算問題相匹配的框架內執行。為了支持這些假設,我們認為通過多層神經元對可信度分配(Credit Assignment)的一系列實現是與我們當前的神經電路知識相兼容的,并且大腦的一些專門系統可以被解釋為對特定問題實現有效的優化。通過一系列相互作用的成本函數,這樣非均勻優化的系統使學習過程變得數據高效,并且較精確地針對機體的需求。我們建議一些神經科學的研究方向可以尋求改進和測試這些假設。
這里提到的相互作用的成本函數非常有趣,在目前的深度學習領域,使用多目標函數的學習任務包括multi-task learning,transfer learning,adversarial generative learning等,甚至一些帶約束條件的優化問題都可以一定程度上看做是多目標函數的。(“目標函數”是旨在最小化成本的函數,論文中使用成本函數,而所有的智能學習過程都是旨在降低各種成本函數值,比較普遍地人們會使用“信息熵”來作為量化標準,那么學習就可以看做是降低不確定性的行為)更有趣的是怎么相互作用?相互作用的目標函數對學習過程有怎樣的幫助?
1. 介紹
今天的機器學習和神經科學使用的并不是同一種“語言”。 腦科學發現了一系列令人眼花繚亂的大腦區域(Solari and Stoner, 2011)、細胞類型、分子、細胞狀態以及計算和信息存儲的機制。 相反,機器學習主要集中在單一原理的實例化:函數優化。 它發現簡單的優化目標,如最小化分類誤差,可以導致在在多層和復現(Recurrent)網絡形成豐富的內部表示和強大的算法能力(LeCun et al., 2015; Schmidhuber, 2015)。 這里我們試圖去連接這些觀點。
如今在機器學習中突出的人工神經網絡最初是受神經科學的啟發(McCulloch and Pitts, 1943)。雖然此后神經科學在機器學習繼續發揮作用(Cox and Dean, 2014),但許多主要的發展都是以有效優化的數學為基礎,而不是神經科學的發現(Sutskever and Martens,2013)。該領域從簡單線性系統(Minsky and Papert, 1972)到非線性網絡(Haykin,1994),再到深層和復現網絡(LeCun et al., 2015; Schmidhuber, 2015)。反向傳播誤差(Werbos, 1974, 1982; Rumelhart et al., 1986)通過提供一種有效的方法來計算相對于多層網絡的權重的梯度,使得神經網絡能夠被有效地訓練。訓練神經網絡的方法已經改進了很多,包括引入動量的學習率,更好的權重矩陣初始化,和共軛梯度等,發展到當前使用分批隨機梯度下降(SGD)優化的網絡。這些發展與神經科學并沒有明顯的聯系。
然而,我們將在此論證,神經科學和機器學習都已經發展成熟到了可以再次“收斂”(交織)的局面。 機器學習的三個方面在本文所討論的上下文中都顯得特別重要。 首先,機器學習側重于成本函數的優化(見Figure 1)。
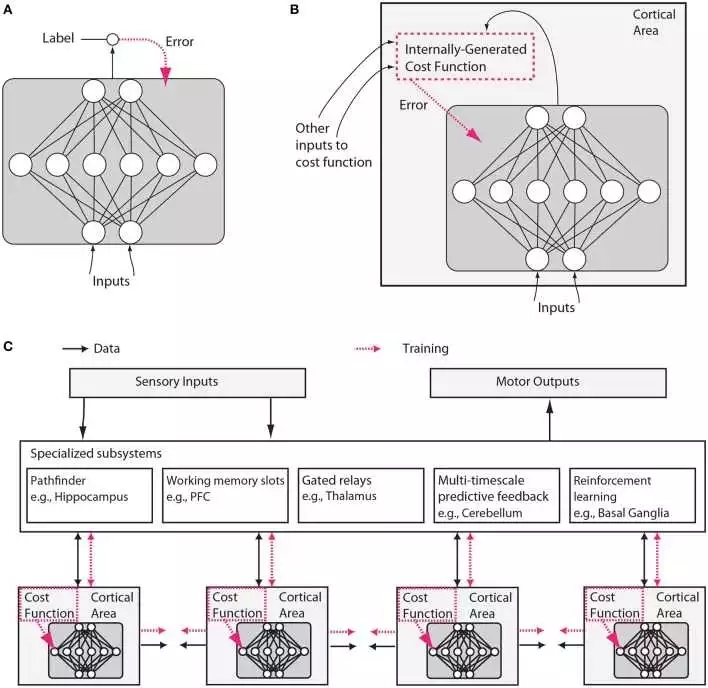
Figure 1. 傳統人工神經網絡和類腦神經網絡設計之間的假設差異。 (A)在常規深度學習中,監督訓練基于外部提供的標記數據。 (B)在大腦中,網絡的監督訓練仍然可以通過對誤差信號的梯度下降發生,但是該誤差信號必須來自內部生成的成本函數。這些成本函數本身是由遺傳基因和后天學習所指定的神經模塊計算而來。內部生成的成本函數創建heuristics(這個實在不好翻譯,“啟發”有些抽象,類似于元信息,大家意會吧),用于引導更復雜的學習。例如,識別面部的區域可以首先使用簡單的heuristic來訓練以來檢測面部,這種heuristic就比如是在直線之上存在兩個點,然后進一步訓練以使用來自無監督學習的表示結合來自其他與社交獎勵處理相關的大腦區域的錯誤信號來區分顯著的面部表情。 (C)內部生成的成本函數和錯誤驅動的神經皮質深層網絡經過訓練形成包含幾個專門系統的較大架構的一部分。雖然可訓練皮層區域在這里被示意為前饋神經網絡,但是LSTM或其他類型的recurrent網絡可能才是更較精確的比喻,并且許多神經元和網絡性質例如神經脈沖、樹突計算、神經調節、適應和穩態可塑性、定時依賴性可塑性、直接電連接、瞬時突觸動力、興奮/抑制平衡、自發振蕩活動、軸突傳導延遲(Izhikevich, 2006)等將影響這些網絡學習的內容和方式。
這里說到的“來自無監督學習的表示”可以用人工智能里的知識表示來理解,來自大腦其他區域的錯誤信號也是一種表示,所以他們可以結合。深度學習中我們用實值張量來表示知識,個人認為knowledge representation是智能形成最基礎的核心之一。C中描述的結構與《On Intelligence》中作者提到的”柱狀體“神經網絡非常類似。結尾的一大串神經動力學名詞真是又一次讓我深深感受到自己的無知...
第二,近來在機器學習中的工作開始引入復雜的成本函數:在層和時間上不一致的成本函數,以及由網絡的不同部分之間的交互產生的那些函數。 例如,引入低層的時間相干性(空間上非均勻成本函數)的目標改進了特征學習(Sermanet and Kavukcuoglu, 2013),成本函數計劃(時間上非均勻成本函數)改進了泛化能力(Saxe et al., 2013; Goodfellow et al., 2014b; Gül?ehre and Bengio, 2016)以及對抗網絡 - 內部交互作用產生的成本函數的一個例子 - 允許生成式模型基于梯度訓練(Goodfellow et al., 2014a)。 更容易訓練的網絡正被用于提供“提示”,以幫助引導更強大的網絡的訓練(Romero et al., 2014)。
第三,機器學習也開始多樣化進行優化的架構。 它引入了具有多重持久狀態的簡單記憶細胞(Hochreiter and Schmidhuber, 1997; Chung et al., 2014),更復雜的基本計算結構單元如“膠囊”和其他結構(Delalleau and Bengio, 2011; Hinton et al., 2011; Tang et al., 2012; Livni et al., 2013),內容可尋址性(Graves et al., 2014; Weston et al.,2014)和位置可尋址存儲器(Graves et al., 2014),另外還有指針 (Kurach et al., 2015)和硬編碼算術運算(Neelakantan et al., 2015)。
這三個想法到目前為止在神經科學中沒有受到很多關注。 因此,我們將這些想法形成為關于大腦的三個假設,檢查它們的證據,并且描繪可以如何測試它們的實驗。 但首先,我們需要更準確地陳述假設。
1.1 假設1 – 大腦進行成本函數優化
連接兩個領域的中心假設是,像許多機器學習系統一樣,生物系統能夠優化成本函數。成本函數的想法意味著大腦區域中的神經元可以以某種方式改變它們的屬性,例如它們的突觸的屬性,使得它們在做任何成本函數定義為它們的角色時更好。人類行為有時在一個領域中達到最優,例如在運動期間(K?rding, 2007),這表明大腦可能已經學習了較佳策略。受試者將他們的運動系統的能量消耗最小化(Taylor and Faisal, 2011),并且使他們的身體的風險和損害最小化,同時較大化財務和運動獲益。在計算上,我們現在知道軌跡的優化為非常復雜的運動任務提出了非常不錯的解決方案(Harris and Wolpert, 1998; Todorov and Jordan, 2002; Mordatch et al., 2012)。我們認為成本函數優化更廣泛地發在大腦使用的內部表示和其他處理過程之中。重要的是,我們還建議這需要大腦在多層和recurrent網絡中具備有效的信用分配(credit assignment,感覺翻譯成中文還是有些奇怪)機制。
1.2 假設2 – 不同的發展階段中不同大腦區域的成本函數不同
第二個假設的另一種表達是:成本函數不需要是全局的。 不同腦區域中的神經元可以優化不同的事物,例如,運動的均方誤差、視覺刺激中的驚喜或注意分配。 重要的是,這樣的成本函數可以在局部大腦區域生成。 例如,神經元可以局部評估其輸入的統計模型的質量(Figure1B)。 或者,一個區域的成本函數可以由另一個區域生成。 此外,成本函數可以隨時間改變,例如,神經網絡先指導小孩早期理解簡單的視覺對比度,稍后再進行面部識別。 這可以允許發展中的大腦根據更簡單的知識來引導更復雜的知識。 大腦中的成本函數是非常復雜的,并且被安排成在不同地區和不同發展之間變化。
1.3 假設3 – 專門系統提供關鍵計算問題上的高效解
第三個認識是:神經網絡的結構很重要。信息在不同大腦區域流動的模式似乎有根本性差異的,這表明它們解決不同的計算問題。一些腦區是高度recurrent的,可能使它們被預定為短期記憶存儲(Wang, 2012)。一些區域包含能夠在定性不同的激活狀態之間切換的細胞類型,例如響應于特定神經遞質的持續發射模式與瞬時發射模式(Hasselmo, 2006)。其他區域,如丘腦似乎有來自其他區域的信息流經它們,也許允許他們確定信息路由(Sherman, 2005)。像基底神經節的區域參與強化學習和分離決定的門控(Doya, 1999; Sejnowski and Poizner,2014)。正如每個程序員所知,專門的算法對于計算問題的有效解決方案很重要,并且大腦可能會很好地利用這種專業化(Figure1 C)。
這些想法受到機器學習領域的進展的啟發,但我們也認為大腦與今天的機器學習技術有很大的不同。特別是,世界給我們一個相對有限的信息量以讓我們可以用于監督學習(Fodor and Crowther, 2002)。有大量的信息可用于無人監督的學習,但沒有理由假設會存在一個通用的無監督算法,無論多么強大,將按人們需要知道的順序較精確學習人類需要知道的事情。因此,從進化的角度來看,使得無監督學習解決“正確”問題的挑戰是找到一系列成本函數,其將根據規定的發展階段確定性地建立電路和行為,使得最終相對少量的信息足以產生正確的行為。例如,一個成長中的鴨子跟隨(Tinbergen, 1965)其父母的行為印記模板,然后使用該模板來生成終級目標,幫助它開發其他技能,如覓食。
根據上述內容和其他研究(Minsky, 1977; Ullman et al., 2012),我們認為(suggest)許多大腦的成本函數產生于這樣的內部自舉過程。事實上,我們提出生物發展和強化學習實際上可以程序化實現生成一系列成本函數,較精確預測大腦內部子系統以及整個生物體面臨的未來需求。這種類型的發展程序化地引導生成多樣化和復雜的成本函數的內部基礎設施,同時簡化大腦的內部過程所面臨的學習問題。除了諸如家族印記的簡單任務之外,這種類型的引導可以擴展到更高的認知,例如,內部產生的成本函數可以訓練發育中的大腦正確地訪問其存儲器或者以隨后證明有用的方式組織其動作。這樣的潛在引導機制在無監督和強化學習的背景下運行,并且遠遠超出當今機器學習、人工智能課程學習的理念(Bengio et al.,2009)。
這段是至今我所看過的人工智能文獻里最精彩的部分。
本文的其余部分,我們將闡述這些假設。 首先,我們將認為局部和多層優化,出乎意料地與我們所知道的大腦兼容。 第二,我們將認為成本函數在大腦區域和不同時間的變化是不同的,并且描述了成本函數如何以協調方式交互以允許引導復雜函數。 第三,我們將列出一系列需要通過神經計算解決的專門問題,以及具有似乎與特定計算問題匹配的結構的腦區域。 然后,我們討論上述假設的神經科學和機器學習研究方法的一些影響,并草擬一組實驗來測試這些假設。 最后,我們從演化的角度討論這個架構。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4680.html
摘要:就像在權重擾動中,而不同于串擾的是,最小的全局協調是必須的每個神經元僅需要接收指示全局成本函數的反饋信號。在深度強化學習中比如可否使用不可微分的目標函數呢值得探索相反,反向傳播通過基于系統的分層結構計算成本函數對每個權重的靈敏度來工作。 2. 大腦能夠進行成本函數優化許多機器學習方法(如典型的監督式學習)是基于有效地函數優化,并且,使用誤差的反向傳播(Werbos, 1974; Rumelh...
摘要:例如,是一些神經元的特征,其中突觸權重變化的符號取決于突觸前后的較精確至毫秒量級相對定時。,是大腦自身調整其神經元之間的連接強度的生物過程。從他博士期間就開始研究至今,目前可以說深度學習占領著機器學習的半壁江山,而則是深度學習的核心。 上次說到誤差梯度的反向傳播(Backpropagation),這次咱們從這繼續。需要說明的是,原文太長,有的地方會有些冗長啰嗦,所以后面的我會選擇性地進行翻譯...
摘要:根據百度的說法,這是全球首次將深度學習領域技術應用在客戶端,獨創了深度神經網絡查殺技術。在過去,吳恩達說,百度用神經網絡來幫助偵測廣告。 吳恩達拿起他的手機,打開了臉優 app。他現在正位于硅谷公司的研究室。在辦公桌邊吃飯,談話內容很自然地也涉及到人工智能。他是百度的首席科學家,同時也是斯坦福大學計算機系的教授。在其他搜索引擎仍在發展時,他就曾幫助谷歌啟動了腦計劃,現在他在百度從事相似的人工...

閱讀 1701·2021-11-18 10:02
閱讀 2218·2021-11-15 11:38
閱讀 2666·2019-08-30 15:52
閱讀 2190·2019-08-29 14:04
閱讀 3230·2019-08-29 12:29
閱讀 2086·2019-08-26 11:44
閱讀 994·2019-08-26 10:28
閱讀 830·2019-08-23 18:37




