資訊專欄INFORMATION COLUMN

摘要:最后,我們顯示了若干張圖像中所生成的趣味字幕。圖所提出的有趣字幕生成的體系結構。我們將所提出的方法稱為神經玩笑機器,它是與預訓練模型相結合的。用戶對已發布的字幕的趣味性進行評估,并為字幕指定一至三顆星。
可以毫不夸張地說,笑是一種特殊的高階功能,且只有人類才擁有。那么,是什么引起人類的笑聲表達呢?最近,日本東京電機大學(Tokyo Denki University)和日本國家先進工業科學和技術研究所(AIST)的科學家們提出了一種新方法,通過使用它就能夠生成引人發笑的字幕。
想問大家一個問題:什么是能夠引起人類笑聲的有效表達?在本文中,為了從學術角度思考這個問題,我們用計算機生成了一個能夠引人“大笑”的圖像字幕(image caption)。我們構建了一個基于計算機視覺領域中所提出的圖像字幕,能夠輸出趣味字幕的系統。此外,我們還提出了“趣味分數”(Funny Score),它能夠根據一個評估數據庫靈活地給出權重。滑稽分數能夠更有效地帶出“笑聲”從而對模型進行優化。另外,我們構建了一個自收集的BoketeDB,其中包含一個主題(圖像)和張貼在“Bokete”上的趣味字幕(文本),這是一個Image Ogiri網站。在實驗中,我們通過比較使用所提出的方法獲得的結果和使用MS COCO預先訓練的CNN + LSTM(這是由人類創建的基線)獲得的結果,從而驗證所提出的方法的有效性。我們將所提出的方法稱為神經玩笑機器(Neural Joking Machine,NJM),該方法使用BoketeDB預訓練模型。

圖1:NJM從圖像輸入中生成的有趣字幕樣本。
可以毫不夸張地說,笑是一種特殊的高階功能,且只有人類才擁有。在對笑聲的分析中,正如維基百科所言,“笑聲被認為是構圖(模式)的轉變”,并且當接受者的構圖發生變化時,笑聲就會經常發生。然而,笑聲的視角在很大的程度上取決于接受者的位置。因此,想要對笑聲進行定量測量是非常困難的。最近出現了諸如“Bokete”等網絡服務的Image Ogiri,其中,用戶在主題圖片上發布有趣的字幕,而字幕也會并在類似SNS的環境中進行評估。用戶進行競爭以獲得最多的“星星”。雖然對笑聲進行量化被認為是一項非常困難的任務,但Bokete評估和圖像之間的對應關系使得我們我們能夠定量地處理笑聲。圖像字幕是計算機視覺中的一個活躍話題,而且我們認為可以實現幽默的圖像字幕。本文的主要貢獻如下:
?我們基于最近在計算機視覺領域的圖像字幕研究,提出了一個用于趣味字幕生成器的框架。
?我們定義了趣味分數(Funny Score),這是一個基于數據庫中現有滑稽字幕評估的權重系統。而這個趣味分數常用于損失函數。
?我們收集了數據以從Web服務Bokete上創建BoketeDB。該數據庫包含999,571張圖像和字幕對。
BoketeDB
在實驗部分,我們將所提出的基于趣味分數和BoketeDB預訓練參數的方法與MS COCO 預訓練的 CNN + LSTM所提供的基線進行了比較。我們還將NJM的結果與人類所提供的趣味字幕進行比較。在人類的評估中,該方法所提供的結果排名要低于人類所提供的結果(22.59%VS 67.99%),但排名要高于基線(9.41%)。最后,我們顯示了若干張圖像中所生成的趣味字幕。
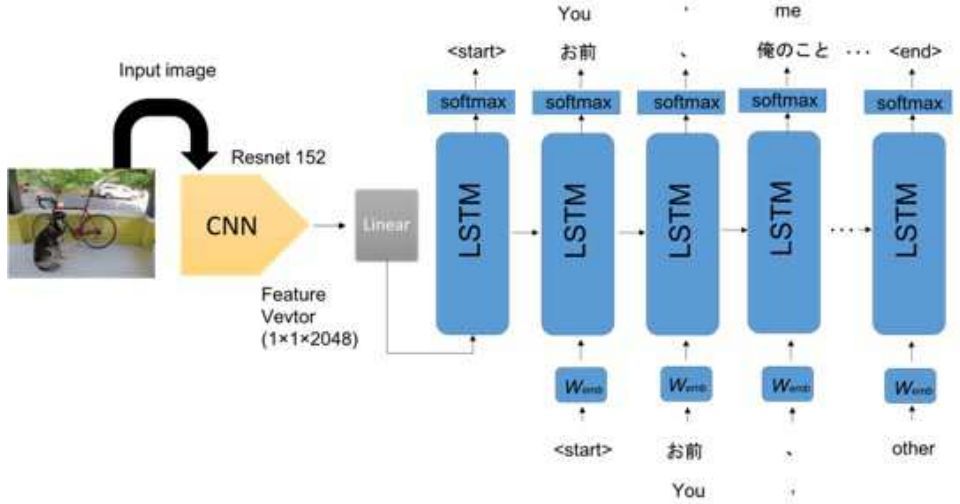
圖2:所提出的有趣字幕生成的CNN + LSTM體系結構。
相關研究
憑借在深度神經網絡(DNNs)所取得的重大研究進展,我們發現卷積神經網絡和循環神經網絡(CNN+RNN)的組合,是一種用于特征提取和序列處理的成功模型。盡管沒有明確的劃分,但CNN通常用于圖像處理,而RNN通常用于文本處理。此外,這兩個領域是相互統一的。一項成功的應用是使用CNN+LSTM(CNN+長短期記憶)生成圖像字幕。該技術可以從圖像輸入中自動生成文本。然而,我們認為圖像字幕需要人類的直覺和情感。在本文中,我們將幫助引導一個圖像字幕進行有趣的表達。接下來,我們將介紹幽默圖像字幕生成的相關研究。
Wang等人提出了一種自動“meme”生成技術。meme是一種有趣的圖像,通常包含幽默文字。Wang等人通過統計分析meme和評論之間的相關性,從而對概率依賴關系(例如圖像和文本的依賴關系)進行建模,并自動生成meme。
Chandrasekaran等人通過構造一個分析器來量化圖像輸入中的“視覺幽默”,從而對圖像進行幽默增強。他們還構建了包含有趣的(3200張)和無趣的(3200張)人類標記圖像在內的數據集來評估視覺幽默。可以通過定義5個階段來訓練一張圖像的“趣味性”。
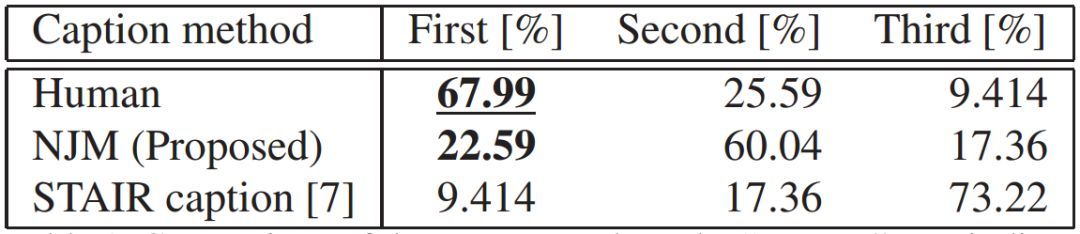
圖3:輸出結果的比較:“Human”行表示人類用戶所提供的字幕,且在Bokete網站上排名較高。“NJM”行表示應用所提出的基于Funny Score和BoketeDB的模型生成的結果。“STAIR字幕”欄表示MS COCO的日語翻譯結果。
所提出的方法
我們通過使用所提出的滑稽分數進行權重評估來對趣味字幕生成器進行有效的訓練。我們采用CNN + LSTM作為基準,但我們一直在探索有效的評分函數和數據庫構建。我們將所提出的方法稱為神經玩笑機器(NJM),它是與BoketeDB預訓練模型相結合的。
CNN + LSTM
所提出方法的流程如圖2所示。基本上,我們采用了Show和Tell中使用的CNN + LSTM模型,但CNN被ResNet-152替代為圖像特征提取方法。接下來,我們將詳細描述如何使用滑稽分數計算損失函數。該函數能夠適當地評估星星的數量和它的“趣味性”。
趣味分數(Funny Score)
Bokete Ogiri網站使用星星的數量來評估字幕的趣味程度。用戶對已發布的字幕的“趣味性”進行評估,并為字幕指定一至三顆星。因此,有趣的標題往往會被分配更多的星星。因此,我們關注的是星星的數量,以提出一種有效的訓練方法,其中,趣味分數使得我們能夠評估字幕的趣味性。根據我們先前實驗的結果,擁有100顆星星的趣味分數被視為閾值。換句話說,當星星的數量小于100時,趣味分數輸出損失值L;相反,當星星的數量超過100時,趣味分數返回L -1.0。損失值L是用LSTM進行計算的,作為每個小批量的平均值。

圖4.使用所提出的NJM獲得的可視化結果。
總而言之,在本文中,我們提出了一種方法,通過使用它能夠生成引人發笑的字幕。我們構建了Bokete DB,其中包含在Bokete Ogiri網站上發布的一個主題(圖像)和相應的有趣字幕。通過權重評估,我們有效地訓練了一個帶有趣味分數的趣味字幕生成器。雖然我們以CNN+LSTM為基準,但我們始終在探索一種有效的評分函數和數據庫結構。本次研究的實驗表明,NJM比基準STAIR字幕要有趣得多。
原文鏈接:https://arxiv.org/pdf/1805.11850.pdf
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4773.html
摘要:是你學習從入門到專家必備的學習路線和優質學習資源。的數學基礎最主要是高等數學線性代數概率論與數理統計三門課程,這三門課程是本科必修的。其作為機器學習的入門和進階資料非常適合。書籍介紹深度學習通常又被稱為花書,深度學習領域最經典的暢銷書。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【導讀】本文由知名開源平...
摘要:普通程序員,如何轉向人工智能方向,是知乎上的一個問題。領域簡介,也就是人工智能,并不僅僅包括機器學習。但是,人工智能并不等同于機器學習,這點在進入這個領域時一定要認識清楚。 人工智能已經成為越來越火的一個方向。普通程序員,如何轉向人工智能方向,是知乎上的一個問題。本文是對此問題的一個回答的歸檔版。相比原回答有所內容增加。 目的 本文的目的是給出一個簡單的,平滑的,易于實現的學習方法,幫...

閱讀 3762·2023-04-25 20:00
閱讀 3114·2021-09-22 15:09
閱讀 511·2021-08-25 09:40
閱讀 3418·2021-07-26 23:38
閱讀 2208·2019-08-30 15:53
閱讀 1100·2019-08-30 13:46
閱讀 2792·2019-08-29 16:44
閱讀 2047·2019-08-29 15:32



