資訊專欄INFORMATION COLUMN

摘要:是由華盛頓大學在讀博士陳天奇等人提出的深度學習自動代碼生成方法,去年月機器之心曾對其進行過簡要介紹。目前的堆棧支持多種深度學習框架以及主流以及專用深度學習加速器。
TVM 是由華盛頓大學在讀博士陳天奇等人提出的深度學習自動代碼生成方法,去年 8 月機器之心曾對其進行過簡要介紹。該技術能自動為大多數計算硬件生成可部署優化代碼,其性能可與當前最優的供應商提供的優化計算庫相比,且可以適應新型專用加速器后端。近日,這項研究的論文《TVM: End-to-End Optimization Stack for Deep Learning》終于完成,內容包含新方法的介紹與討論,以及 TVM 在英偉達、AMD 的 GPU、樹莓派及一些 FPGA 上的性能評估。
項目鏈接:https://github.com/dmlc/tvm
深度學習模型可以識別圖像、處理自然語言,以及在部分具有挑戰性的策略游戲中擊敗人類。在其技術發展的過程中,現代硬件穩步推進的計算能力扮演了不可或缺的作用。很多目前更為流行的深度學習框架,如 TensorFlow、MXNet、Caffe 和 PyTorch,支持在有限類型的服務器級 GPU 設備上獲得加速,這種支持依賴于高度特化、供應商特定的 GPU 庫。然而,專用深度學習加速器的種類越來越多,這意味著現代編譯器與框架越來越難以覆蓋所有的硬件。
顯而易見,以現有的點到點方式實現不同深度學習框架對所有種類的硬件進行后端支持是不現實的。我們的最終目標是讓深度學習負載可以輕松部署到所有硬件種類中,其中不僅包括 GPU、FPGA 和 ASIC(如谷歌 TPU),也包括嵌入式設備,這些硬件的內存組織與計算能力存在著顯著的差異(如圖 1 所示)。考慮到這種需求的復雜性,開發一種能夠將深度學習高級程序降低為適應任何硬件后端的低級優化代碼的優化框架是較好的方法。
目前的深度學習框架依賴于計算圖的中間表示來實現優化,如自動微分和動態內存管理 [3,7,4]。然而,圖級別的優化通常過于高級,無法有效處理硬件后端算子級別的轉換。另一方面,目前深度學習框架的算子級別庫通常過于僵化,難以輕松移植到不同硬件設備上。為了解決這些問題,我們需要一個可實現從計算圖到算子級別的優化,為各種硬件后端帶來強大性能的編譯器框架。

圖 1:CPU、GPU 與類 TPU 加速器需要不同的片上存儲架構和計算基元。在生成優化代碼時我們必須考慮這一問題。
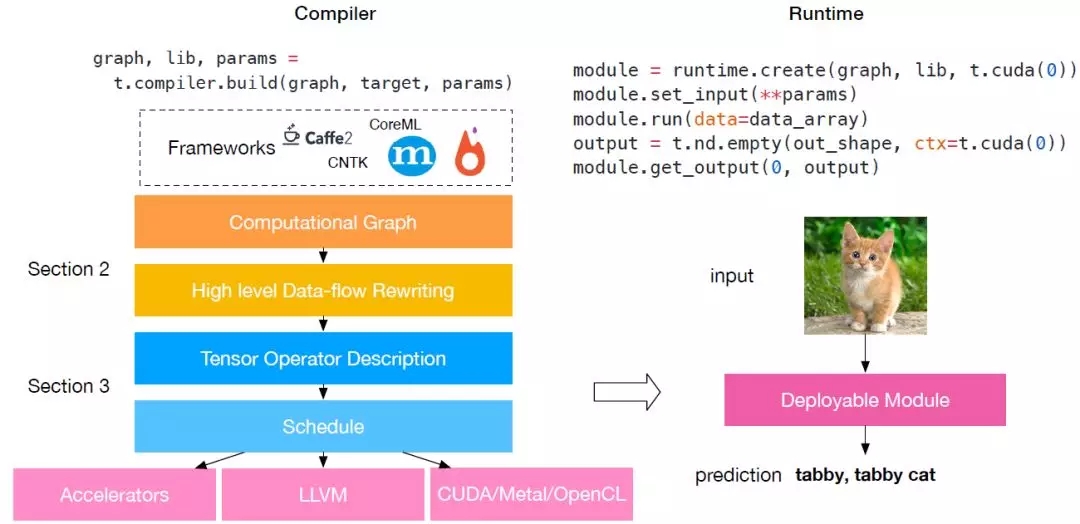
圖 2:TVM 堆棧圖。目前的堆棧支持多種深度學習框架以及主流 CPU、GPU 以及專用深度學習加速器。
優化的四大基本挑戰
深度學習的優化編譯器需要同時展示高級別與低級別的優化,在論文中,研究人員總結了在計算圖級別與張量算子級別上的四大基本挑戰:
高級數據流復寫:不同的硬件設備可能具有截然不同的內存層次結構,因此,融合算子與優化數據布局的策略對于優化內存訪問至關重要。
跨線程內存復用:現代 GPU 與專用加速器的內存可被多個計算核心共享,傳統的無共享嵌套并行模式已不再是最優方法。為優化內核,在共享內存負載上的線程合作很有必要。
張量計算內部函數:的硬件帶來了超越向量運算的新指令集,如 TPU 中的 GEMM 算子和英偉達 Volta 架構中的 Tensor Core。因此在調度過程中,我們必須將計算分解為張量算術內部函數,而非標量或向量代碼。
延遲隱藏(Latency Hiding):盡管在現代 CPU 與 GPU 上,同時擁有多線程和自動緩存管理的傳統架構隱藏了延遲問題,但專用的加速器設計通常使用精簡控制與分流,這為編譯器堆棧的調度帶來了復雜性。所以,調度仍需仔細,以隱藏內存訪問延遲。
TVM:一個端到端優化堆棧(見圖 2),該端到端優化編譯器堆棧可降低和調整深度學習工作負載,以適應多種硬件后端。TVM 的設計目的是分離算法描述、調度和硬件接口。該原則受到 Halide [22] 的計算/調度分離思想的啟發,而且通過將調度與目標硬件內部函數分開而進行了擴展。這一額外分離使支持新型專用加速器及其對應新型內部函數成為可能。TVM 具備兩個優化層:計算圖優化層,用于解決第一個調度挑戰;具備新型調度基元的張量優化層,以解決剩余的三個挑戰。通過結合這兩種優化層,TVM 從大部分深度學習框架中獲取模型描述,執行高級和低級優化,生成特定硬件的后端優化代碼,如樹莓派、GPU 和基于 FPGA 的專用加速器。該論文做出了以下貢獻:
我們構建了一個端到端的編譯優化堆棧,允許將高級框架(如 Caffe、MXNet、PyTorch、Caffe2、CNTK)專用的深度學習工作負載部署到多種硬件后端上(包括 CPU、GPU 和基于 FPGA 的加速器)。
我們發現了提供深度學習工作負載在不同硬件后端中的性能可移植性的主要優化挑戰,并引入新型調度基元(schedule primitive)以利用跨線程內存重用、新型硬件內部函數和延遲隱藏。
我們在基于 FPGA 的通用加速器上對 TVM 進行評估,以提供關于如何最優適應專用加速器的具體案例。
我們的編譯器可生成可部署代碼,其性能可與當前最優的特定供應商庫相比,且可適應新型專用加速器后端。

圖 3:兩層卷積神經網絡的計算圖示例。圖中每個節點表示一次運算,它消耗一或多個張量,并生成一或多個張量。張量運算可以通過屬性進行參數化,以配置其行為(如 padding 或 stride)。
論文:TVM: End-to-End Optimization Stack for Deep Learning

論文鏈接:https://arxiv.org/abs/1802.04799
摘要:可擴展框架,如 TensorFlow、MXNet、Caffe 和 PyTorch 是目前深度學習領域中最流行和易用的框架。但是,這些框架只對窄范圍的服務器級 GPU 進行優化,要把工作負載部署到其他平臺,如手機、嵌入式設備和專用加速器(如 FPGA、ASIC),則需要大量手動工作。我們提出了 TVM,一個端到端的優化堆棧,具備圖形級和算子級的優化,以為多種硬件后端提供深度學習工作負載的性能可移植性。我們討論了 TVM 所解決的深度學習優化挑戰:高級算子融合(operator fusion)、多線程低級內存重用、任意硬件基元的映射,以及內存延遲隱藏。實驗結果證明 TVM 在多個硬件后端中的性能可與適應低功耗 CPU 和服務器級 GPU 的當前最優庫相比。我們還通過針對基于 FPGA 的通用深度學習加速器的實驗,展示了 TVM 對新型硬件加速器的適應能力。該編譯器基礎架構已開源。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4732.html
摘要:亞馬遜和華盛頓大學今天合作發布了開源的端到端深度學習編譯器。項目作者之一陳天奇在微博上這樣介紹這個編譯器我們今天發布了基于工具鏈的深度學習編譯器。陳天奇團隊對的性能進行了基準測試,并與進行了比較。 亞馬遜和華盛頓大學今天合作發布了開源的端到端深度學習編譯器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是華盛頓大學博士陳天奇等人2016年發布的模塊化...
摘要:系列安裝報錯結果一樣的錯解決方法成功了過擬合當你觀察訓練精度高但檢測精度低很可能你遇到過度擬合問題。正如其名,它是的一個實現,作者為正在華盛頓大學研究機器學習的大牛陳天奇。為了方便大家使用,陳天奇將封裝成了庫。 xgboost系列 ubuntu14.04 安裝 pip install xgboost 報錯 sudo apt-get update 結果一樣的錯 解決方法: sudo -...
摘要:兩者取長補短,所以深度學習框架在年,迎來了前后端開發的黃金時代。陳天奇在今年的中,總結了計算圖優化的三個點依賴性剪枝分為前向傳播剪枝,例已知,,求反向傳播剪枝例,,求,根據用戶的求解需求,可以剪掉沒有求解的圖分支。 虛擬框架殺入從發現問題到解決問題半年前的這時候,暑假,我在SIAT MMLAB實習。看著同事一會兒跑Torch,一會兒跑MXNet,一會兒跑Theano。SIAT的服務器一般是不...

閱讀 1598·2021-11-22 09:34
閱讀 1689·2019-08-29 16:36
閱讀 2667·2019-08-29 15:43
閱讀 3113·2019-08-29 13:57
閱讀 1296·2019-08-28 18:05
閱讀 1874·2019-08-26 18:26
閱讀 3241·2019-08-26 10:39
閱讀 3453·2019-08-23 18:40




