資訊專(zhuān)欄INFORMATION COLUMN

摘要:亞馬遜和華盛頓大學(xué)今天合作發(fā)布了開(kāi)源的端到端深度學(xué)習(xí)編譯器。項(xiàng)目作者之一陳天奇在微博上這樣介紹這個(gè)編譯器我們今天發(fā)布了基于工具鏈的深度學(xué)習(xí)編譯器。陳天奇團(tuán)隊(duì)對(duì)的性能進(jìn)行了基準(zhǔn)測(cè)試,并與進(jìn)行了比較。
亞馬遜和華盛頓大學(xué)今天合作發(fā)布了開(kāi)源的端到端深度學(xué)習(xí)編譯器NNVM compiler。
先提醒一句,NNVM compiler ≠ NNVM。
NNVM是華盛頓大學(xué)博士陳天奇等人2016年發(fā)布的模塊化深度學(xué)習(xí)系統(tǒng),今年8月中旬,他們又推出了將深度學(xué)習(xí)工作負(fù)載部署到硬件的端到端IR堆棧TVM,也就是把深度學(xué)習(xí)模型更簡(jiǎn)單地放到各種硬件上。
當(dāng)時(shí),陳天奇把TVM+NNVM描述為“深度學(xué)習(xí)到各種硬件的完整優(yōu)化工具鏈”,而這次推出的NNVM compiler,是一個(gè)基于TVM工具鏈的編譯器。
項(xiàng)目作者之一陳天奇在微博上這樣介紹這個(gè)編譯器:
我們今天發(fā)布了基于TVM工具鏈的深度學(xué)習(xí)編譯器NNVM compiler。支持將包括mxnet,pytorch,caffe2, coreml等在內(nèi)的深度學(xué)習(xí)模型編譯部署到硬件上并提供多級(jí)別聯(lián)合優(yōu)化。速度更快,部署更加輕量級(jí)。 支持包括樹(shù)莓派,服務(wù)器和各種移動(dòng)式設(shè)備和cuda, opencl, metal, Javascript以及其它各種后端。 歡迎對(duì)于深度學(xué)習(xí), 編譯原理,高性能計(jì)算,硬件加速有興趣的同學(xué)一起加入dmlc推動(dòng)領(lǐng)導(dǎo)開(kāi)源項(xiàng)目社區(qū)。
NNVM compiler對(duì)CoreML的支持,讓開(kāi)發(fā)者可以在非iOS設(shè)備上部署CoreML模型。
AI開(kāi)發(fā)界的挑戰(zhàn)
AWS AI首席科學(xué)家李沐(MXNet作者)在亞馬遜博客撰文介紹稱,推出這個(gè)編譯器,是為了應(yīng)對(duì)深度學(xué)習(xí)框架多樣化為AI開(kāi)發(fā)界帶來(lái)的三個(gè)挑戰(zhàn):
一、對(duì)于算法的開(kāi)發(fā)者來(lái)說(shuō),由于各AI框架的前端交互和后端實(shí)現(xiàn)之間都存在很多區(qū)別,換框架很麻煩,而開(kāi)發(fā)和交付過(guò)程中可能會(huì)用到的框架不止一個(gè)。
比如說(shuō)有的亞馬遜AWS云服務(wù)用戶,為了獲得EC2上的加速性能,會(huì)想要把Caffe模型部署到MXNet上。
為了應(yīng)對(duì)這個(gè)問(wèn)題,之前Facebook和微軟也聯(lián)合發(fā)布了模型間轉(zhuǎn)換工具ONNX。
二、框架的開(kāi)發(fā)者需要維護(hù)多個(gè)后端,來(lái)保證自己的框架能適用于從手機(jī)芯片到數(shù)據(jù)中心GPU的各種硬件。
比如說(shuō)MXNet,要支持英偉達(dá)GPU的cuDNN,還要支持英特爾CPU的MKLML。
三、從芯片供應(yīng)商的角度來(lái)看,他們每新開(kāi)發(fā)一款芯片都需要支持多個(gè)AI框架,每個(gè)框架表示和執(zhí)行工作負(fù)載的方式都不一樣,所以,就連卷積這樣一個(gè)運(yùn)算,都需要用不同的方式來(lái)定義。
支持多個(gè)框架,就代表要完成巨大的工作量。
通過(guò)將框架中的深度學(xué)習(xí)模型直接部署到硬件,NNVM compiler自然也就解決了這些問(wèn)題。
結(jié)構(gòu)
NNVM compiler可以將前端框架中的工作負(fù)載直接編譯到硬件后端,能在高層圖中間表示(IR)中表示和優(yōu)化普通的深度學(xué)習(xí)工作負(fù)載,也能為不同的硬件后端轉(zhuǎn)換計(jì)算圖、最小化內(nèi)存占用、優(yōu)化數(shù)據(jù)分布、融合計(jì)算模式。
編譯器的典型工作流如下圖所示:

這個(gè)編譯器基于此前發(fā)布的TVM堆棧中的兩個(gè)組件:NNVM用于計(jì)算圖,TVM用于張量運(yùn)算。
其中,NNVM的目標(biāo)是將不同框架的工作負(fù)載表示為標(biāo)準(zhǔn)化計(jì)算圖,然后將這些高級(jí)圖轉(zhuǎn)換為執(zhí)行圖。
TVM提供了一種獨(dú)立于硬件的特定域語(yǔ)言,以簡(jiǎn)化張量索引層次中的運(yùn)算符實(shí)現(xiàn)。另外,TVM還支持多線程、平鋪、緩存等。
對(duì)框架和硬件的支持
編譯器中的NNVM模塊,支持下圖所示的深度學(xué)習(xí)框架:
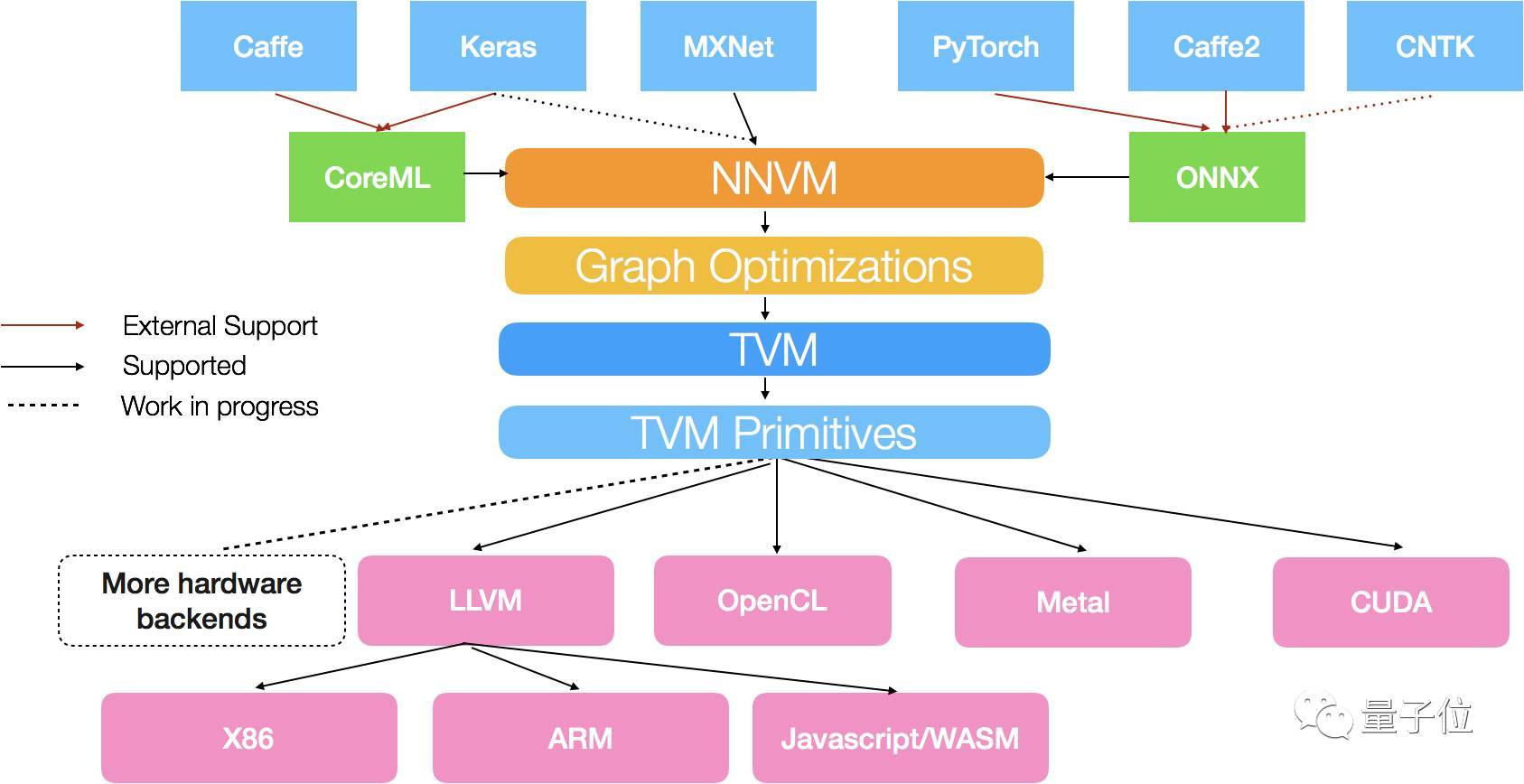
具體來(lái)說(shuō),MXNet的計(jì)算圖能直接轉(zhuǎn)換成NNVM圖,對(duì)Keras計(jì)算圖的直接支持也正在開(kāi)發(fā)中。
同時(shí),NNVM compiler還支持其他模型格式,比如說(shuō)微軟和Facebook前不久推出的ONNX,以及蘋(píng)果CoreML。
通過(guò)支持ONNX,NNVM compiler支持Caffe2、PyTorch和CNTK框架;通過(guò)支持CoreML,這個(gè)編譯器支持Caffe和Keras。
而編譯器中的TVM模塊,目前附帶多個(gè)編碼生成器,支持多種后端硬件,其中包括為X86和ARM架構(gòu)的CPU生成LLVM IR,為各種GPU輸出CUDA、OpenCL和Metal kernel。
性能

NNVM compiler聯(lián)合使用圖級(jí)和張量級(jí)優(yōu)化以獲得較佳性能。常規(guī)的深度學(xué)習(xí)框架會(huì)將圖優(yōu)化與部署runtime進(jìn)行打包,而NNVM編譯器將優(yōu)化與實(shí)際部署運(yùn)行時(shí)分離。
采用這種方法,編譯的模塊只需要依賴于最小的TVM runtime,當(dāng)部署在Raspberry Pi或移動(dòng)設(shè)備上時(shí),只占用大約300KB。
陳天奇團(tuán)隊(duì)對(duì)NNVM compiler的性能進(jìn)行了基準(zhǔn)測(cè)試,并與MXNet進(jìn)行了比較。這個(gè)測(cè)試基于兩種典型的硬件配置:樹(shù)莓派上的ARM CPU和AWS上的Nvidia GPU。
Nvidia GPU
GPU的基準(zhǔn)和時(shí)間表由Leyuan Wang(AWS/UCDavis)和Yuwei Hu(圖森)提供。他們?cè)贜vidia K80上對(duì)NNVM編譯器和MXNet進(jìn)行了比較,以CUDA8和CuDNN7作為后端。這是一個(gè)非常強(qiáng)的基線,因?yàn)镸XNet開(kāi)啟了從CuDNN中選擇較佳內(nèi)核的自動(dòng)調(diào)整功能。另外,他們還使用了MXNet中優(yōu)化深度內(nèi)核來(lái)優(yōu)化MobileNet工作負(fù)載。
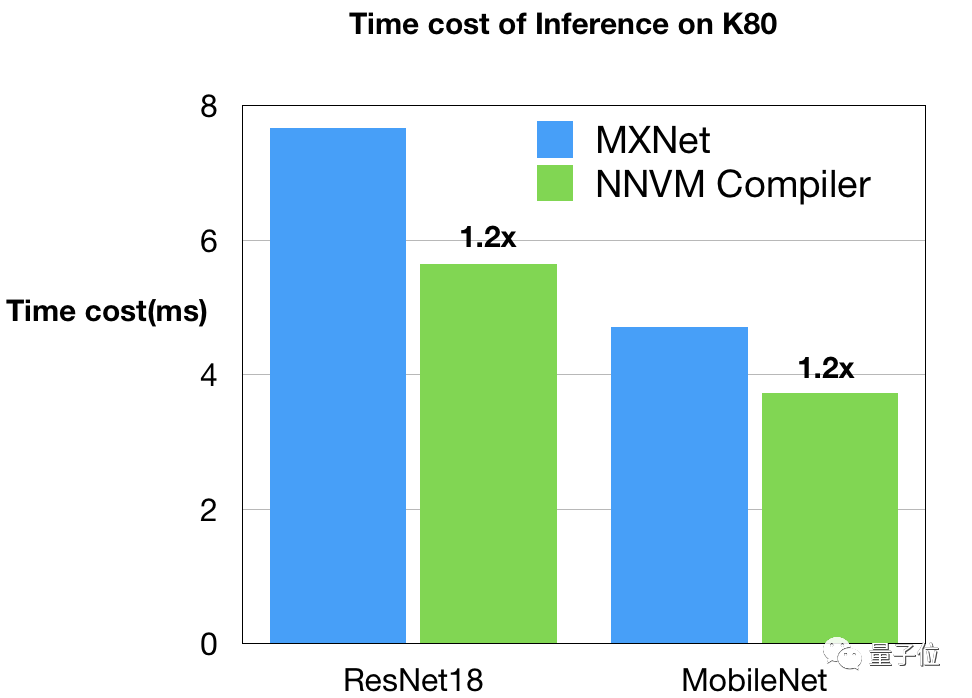
如圖所見(jiàn),NNVM編譯器生成的代碼在K80上優(yōu)于MXNet。這些改進(jìn)源于圖和內(nèi)核級(jí)別的優(yōu)化。值得注意的是,NNVM編譯器自己升恒所有的優(yōu)化GPU內(nèi)核,而不需要依賴諸如CuDNN這樣的外部庫(kù)。
樹(shù)莓派3b
樹(shù)莓派編譯堆棧由Ziheng Jiang(AWS/FDU)提供。他們使用OpenBLAS和NNPack對(duì)NNVM和MXNet進(jìn)行了比較,嘗試不同的設(shè)置來(lái)獲得MXNet的較佳表現(xiàn),例如為3×3卷積在NNPack中開(kāi)啟Winograd卷積,啟動(dòng)多線程,并禁用了額外的調(diào)度程序(所有的線程都被NNPack使用)。
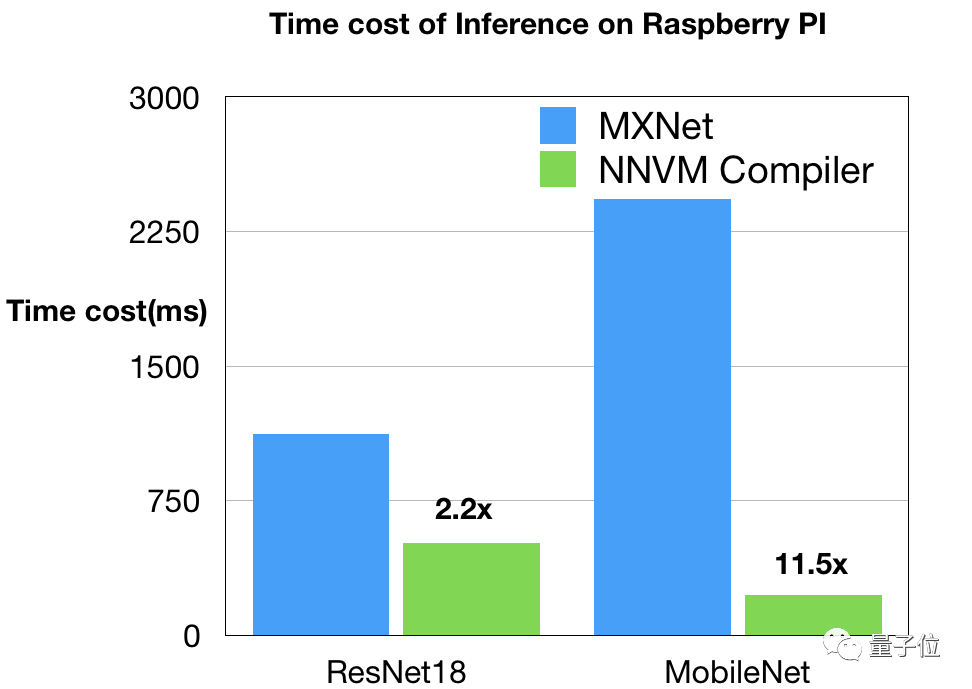
結(jié)果如上圖所示,由NNVM編譯器生成的代碼在ResNet18上速度快兩倍。MobileNet上的差距,主要是因?yàn)楝F(xiàn)有CPU DNN庫(kù)中缺乏深度卷積。NNVM編譯器受益于直接生成高效的ARM代碼。
開(kāi)發(fā)團(tuán)隊(duì)
NNVM編譯器的GitHub地址:
https://github.com/dmlc/nnvm
開(kāi)發(fā)這個(gè)項(xiàng)目的依然是TVM堆棧團(tuán)隊(duì),包括華盛頓大學(xué)艾倫計(jì)算機(jī)學(xué)院的陳天奇、Thierry Moreau、Haichen Shen、Luis Ceze、Carlos Guestrin和Arvind Krishnamurthy,以及亞馬遜AWS AI團(tuán)隊(duì)的Ziheng Jiang。
另外,在TVM博客最后還鳴謝了一群社區(qū)貢獻(xiàn)者:
在這里特別感謝Yuwen Hu(圖森)、Leyuan Wang(AWS/UCDavis)、Joshua Z. Zhang(AWS)以及Xingjian Shi(HKUST)的早期貢獻(xiàn)。我們也要感謝所有的TVM堆棧貢獻(xiàn)者。
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4641.html
摘要:兩者取長(zhǎng)補(bǔ)短,所以深度學(xué)習(xí)框架在年,迎來(lái)了前后端開(kāi)發(fā)的黃金時(shí)代。陳天奇在今年的中,總結(jié)了計(jì)算圖優(yōu)化的三個(gè)點(diǎn)依賴性剪枝分為前向傳播剪枝,例已知,,求反向傳播剪枝例,,求,根據(jù)用戶的求解需求,可以剪掉沒(méi)有求解的圖分支。 虛擬框架殺入從發(fā)現(xiàn)問(wèn)題到解決問(wèn)題半年前的這時(shí)候,暑假,我在SIAT MMLAB實(shí)習(xí)。看著同事一會(huì)兒跑Torch,一會(huì)兒跑MXNet,一會(huì)兒跑Theano。SIAT的服務(wù)器一般是不...
摘要:是由華盛頓大學(xué)在讀博士陳天奇等人提出的深度學(xué)習(xí)自動(dòng)代碼生成方法,去年月機(jī)器之心曾對(duì)其進(jìn)行過(guò)簡(jiǎn)要介紹。目前的堆棧支持多種深度學(xué)習(xí)框架以及主流以及專(zhuān)用深度學(xué)習(xí)加速器。 TVM 是由華盛頓大學(xué)在讀博士陳天奇等人提出的深度學(xué)習(xí)自動(dòng)代碼生成方法,去年 8 月機(jī)器之心曾對(duì)其進(jìn)行過(guò)簡(jiǎn)要介紹。該技術(shù)能自動(dòng)為大多數(shù)計(jì)算硬件生成可部署優(yōu)化代碼,其性能可與當(dāng)前最優(yōu)的供應(yīng)商提供的優(yōu)化計(jì)算庫(kù)相比,且可以適應(yīng)新型專(zhuān)用加...
摘要:在此,我們將借用和的算子,分析硬件加速的需求。池化層池化層主要用于尺度變換,提取高維特征。此種類(lèi)型主要用于深度卷積神經(jīng)網(wǎng)絡(luò)中卷積部分與部分的連接。和可以認(rèn)為是的特例。 NNVM是由陳天奇團(tuán)隊(duì)提出的一套可復(fù)用的計(jì)算流圖中間表達(dá)層,它提供了一套精簡(jiǎn)的API函數(shù),用以構(gòu)建、表達(dá)和傳輸計(jì)算流圖,從而便于高層級(jí)優(yōu)化。另外NNVM也可以作為多個(gè)深度學(xué)習(xí)框架的共享編譯器,可以優(yōu)化、編譯和部署在多種不同的硬...
摘要:所有需要跑任務(wù)的通過(guò)模版動(dòng)態(tài)創(chuàng)建,當(dāng)任務(wù)執(zhí)行結(jié)束自動(dòng)刪除。同時(shí)也可以用配置完畢,可以點(diǎn)擊按鈕測(cè)試是否能夠連接的到,如果顯示則表示連接成功,配置沒(méi)有問(wèn)題。 介紹 基于Kubernetes和Jenkins來(lái)實(shí)現(xiàn)CI/CD。 所有需要跑任務(wù)的jenkins slave(pod)通過(guò)模版動(dòng)態(tài)創(chuàng)建,當(dāng)任務(wù)執(zhí)行結(jié)束自動(dòng)刪除。 showImg(https://segmentfault.com/img...
摘要:系列安裝報(bào)錯(cuò)結(jié)果一樣的錯(cuò)解決方法成功了過(guò)擬合當(dāng)你觀察訓(xùn)練精度高但檢測(cè)精度低很可能你遇到過(guò)度擬合問(wèn)題。正如其名,它是的一個(gè)實(shí)現(xiàn),作者為正在華盛頓大學(xué)研究機(jī)器學(xué)習(xí)的大牛陳天奇。為了方便大家使用,陳天奇將封裝成了庫(kù)。 xgboost系列 ubuntu14.04 安裝 pip install xgboost 報(bào)錯(cuò) sudo apt-get update 結(jié)果一樣的錯(cuò) 解決方法: sudo -...

閱讀 3345·2021-11-25 09:43
閱讀 3133·2021-10-11 10:58
閱讀 2734·2021-09-27 13:59
閱讀 3073·2021-09-24 09:55
閱讀 2165·2019-08-30 15:52
閱讀 1826·2019-08-30 14:03
閱讀 2256·2019-08-30 11:11
閱讀 2020·2019-08-28 18:12






