資訊專欄INFORMATION COLUMN

摘要:在此,我們將借用和的算子,分析硬件加速的需求。池化層池化層主要用于尺度變換,提取高維特征。此種類型主要用于深度卷積神經(jīng)網(wǎng)絡(luò)中卷積部分與部分的連接。和可以認為是的特例。
NNVM是由陳天奇團隊提出的一套可復用的計算流圖中間表達層,它提供了一套精簡的API函數(shù),用以構(gòu)建、表達和傳輸計算流圖,從而便于高層級優(yōu)化。另外NNVM也可以作為多個深度學習框架的共享編譯器,可以優(yōu)化、編譯和部署在多種不同的硬件后端。其特點是部署的模型擁有最小依賴,可加入新的操作(operators),可將新的優(yōu)化通路加入到現(xiàn)有的圖結(jié)構(gòu)中。從NNVM的觀點看,它可用于將M個框架,N個機器之間構(gòu)建一個單一的紐帶,以實現(xiàn)各種框架向各種實現(xiàn)平臺的無差別部署。如圖所示。
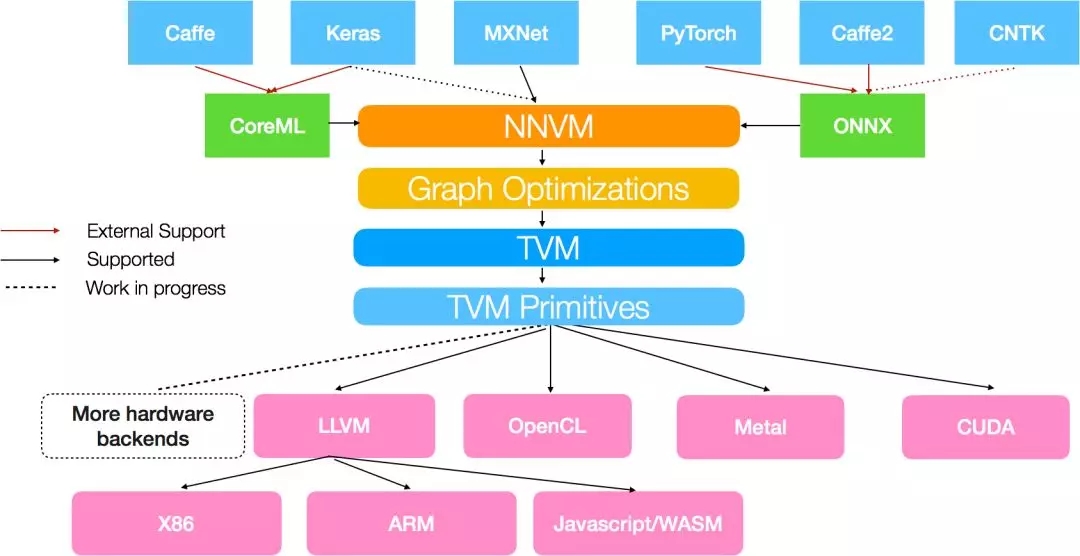
ONNX[1]是Facebook聯(lián)合微軟和AWS推出的開源的深度學習表示格式。通過ONNX,AI開發(fā)人員可以容易地在不同模型和工具間轉(zhuǎn)換,并將工具組合使用。目前可以支持Caffe2, CNTK, PyTorch等主流模型,也對Tensorflow提供了早期支持。一下是ONNX的一些基本信息(來自O(shè)NNX網(wǎng)站[1])。



嚴格而言,和NNVM相比,ONNX更像是一個協(xié)議轉(zhuǎn)換器,可以在各個框架之間進行轉(zhuǎn)換。
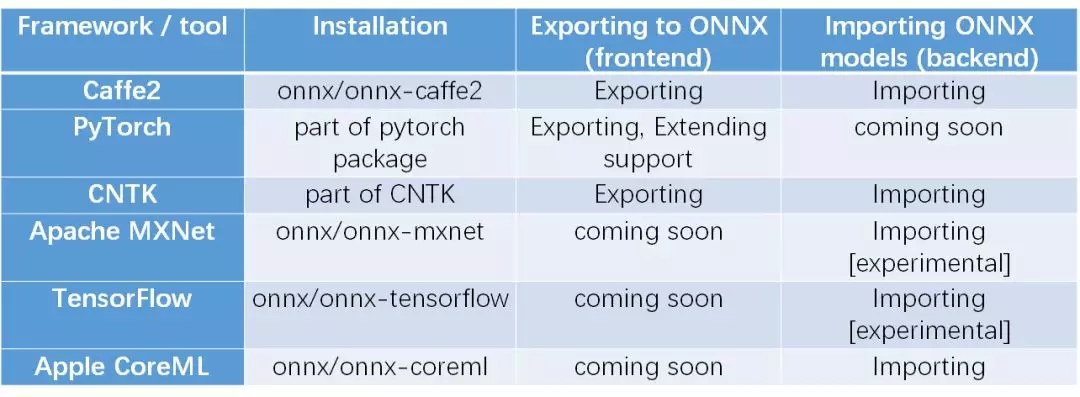
目前多種標準的轉(zhuǎn)換工具已經(jīng)開發(fā)了出來,如表格所示。
在此,我們將借用NNVM和ONNX的算子,分析AI硬件加速的需求。這些算子都包含了相關(guān)參數(shù),在此不細致表述。有關(guān)這些算子的完整解釋,可以查看ONNX的官方表述[2];NNVM目前的版本是0.8,因此本文參考版本0.8。算子的官方解釋參見[3]。
ONNX以張量(Tensor)作為輸入輸出數(shù)據(jù)格式,可以認為是多維數(shù)組。主要支持如下的數(shù)據(jù)格式:tensor(float16), tensor(float), tensor(double)。目前還不太支持定點,但提供了定點化的一些函數(shù),如floor, ceil, clip, cast等。NNVM也以Tensor作為數(shù)據(jù)格式。
ONNX不完整支持神經(jīng)網(wǎng)絡(luò)的訓練,但它提供了訓練所需要的完整的圖描述,其實就是對BN和dropout兩個功能上加了一個區(qū)別參數(shù),用來描述可訓練的圖和不可訓練的圖。由于ONNX實際上就是把各種框架的圖轉(zhuǎn)換成了它自己的Operator表示的圖,它只負責描述這個圖的結(jié)構(gòu),具體前后向的計算都需要一個執(zhí)行框架(稱為后端)。 因此,如果需要實現(xiàn)訓練,需要實現(xiàn)系統(tǒng)根據(jù)這個圖自動實現(xiàn)所有的反向過程的微分算子,并且實現(xiàn)loss函數(shù)。此外,還需要編譯器根據(jù)這個前向圖結(jié)構(gòu)推演出反向圖的各個步驟,這個過程可以是工具鏈自動的。而對于前向而言,基本不需要轉(zhuǎn)化就可以直接部署在支持這些算子的實現(xiàn)平臺上。
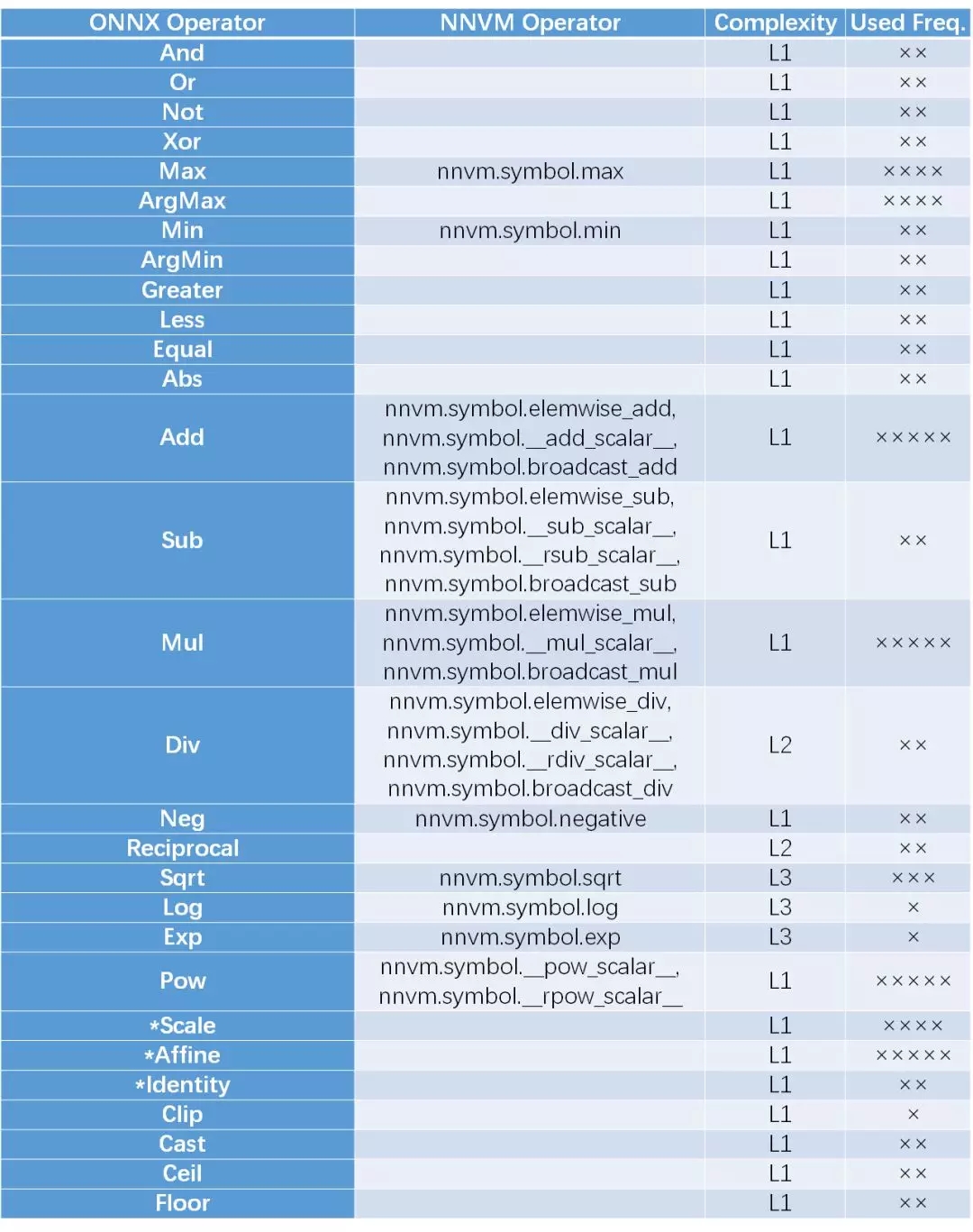
本人對這些算子進行了一個簡單的歸類,并將ONNX和NVM進行了比對。由于在硬件實現(xiàn)上,不同的算子的實現(xiàn)復雜度是不同的,因此加入了Complexity的度量。另外,根據(jù)當前神經(jīng)網(wǎng)絡(luò)在圖像/語音/文本三方面的應用情況,對這些算子的使用頻率進行了估計。由于應用領(lǐng)域和硬件平臺各不相同,因此復雜度和使用頻率僅作參考。
1. 深度神經(jīng)網(wǎng)絡(luò)計算
1.1. 計算層
這部分算子是深度網(wǎng)絡(luò)的核心,用于將輸入的神經(jīng)元激活值與突觸連接強度(權(quán)重)進行積分求和,得到新的神經(jīng)元的模電位。根據(jù)是否滑窗,是否具有時序結(jié)構(gòu),可分為如下幾種算子,其中FC(全連接)是多層感知機(MLP)的基礎(chǔ),Conv和FC是深度卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)。RNN, GRU, LSTM是帶有時序結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò)模型,主要用于非靜態(tài)圖像的場合,例如語音/文字/視頻等。可見,ONNX的關(guān)注面比較全面,包括了時序模型,而NNVM暫時還沒有包括時序模型。
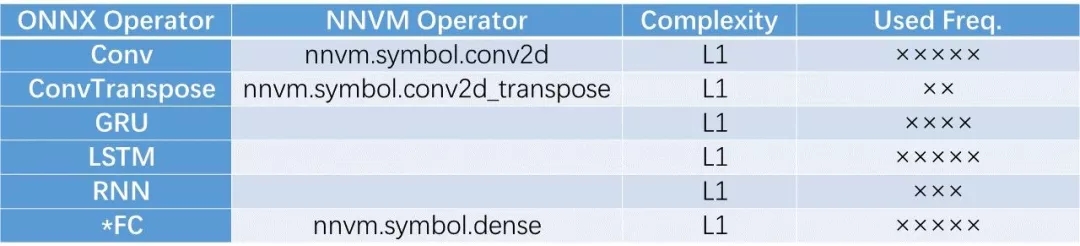
注: (*)代表ONNX庫中此函數(shù)帶有實驗階段(Experimental)標志。下同。
1.2 池化層
池化層主要用于尺度變換,提取高維特征。主要分三種池化,第一種是局部池化,在圖像維度上,幾個相鄰的點被縮減為一個輸出點,在Channel維度上不變。包括計算相鄰點的平均值(AveragePool),較大值(MaxPool),范數(shù)(LpPool)。主要用于圖像的尺寸變換。第二種是全局的池化,此時一個Channel的所有數(shù)據(jù)點縮為1個點,因此有幾個Channel就輸出幾個數(shù)據(jù)點。此種類型主要用于深度卷積神經(jīng)網(wǎng)絡(luò)中卷積部分與FC部分的連接。第三種是ROI-pooling,用于Faster-RCNN等檢測識別網(wǎng)絡(luò)中對感興趣區(qū)域進行尺度歸一化,從而輸入到識別網(wǎng)絡(luò)進行識別處理。可見,ONNX實現(xiàn)了比較全面的算子覆蓋,NNVM實現(xiàn)了比較常見的局部池化和全局池化,但是暫時還沒有實現(xiàn)ROI-pool。

1.3 批數(shù)據(jù)歸一化層
歸一化層作為一個特殊層,可用于數(shù)據(jù)的歸一化,提高神經(jīng)網(wǎng)絡(luò)的性能,降低訓練時間。對于帶有殘差的神經(jīng)網(wǎng)絡(luò)非常重要。目前高性能網(wǎng)絡(luò)大多帶有歸一化層,而絕大多數(shù)都會采用Batch Normalization(BN)。BN前向操作并不復雜,但反向比較復雜,因此用于訓練的BN需要加入更多的子層。ONNX構(gòu)建了兩套圖描述,用標志位進行區(qū)分,用戶可以選擇是用于訓練的還是僅用于前向的。另外,ONNX還提供了在這方面其他的選擇,例如Instance歸一化 (y = scale * (x - mean) / sqrt(variance + epsilon) + B)和基于范數(shù)的歸一化,LRN被用在AlexNet等早期設(shè)計,目前用的比較少。對比之下,NNVM只支持了BN,可以覆蓋約95%的應用情形。

1.4. 數(shù)據(jù)歸一化
將數(shù)據(jù)進行歸一化處理,通常用于輸出層的歸一化。

1.5. 其他計算層
在進行訓練時,DropOut隨機扔掉一些通路,可以用于防止過擬合。這方面兩個框架都實現(xiàn)了。Embedding用于將詞轉(zhuǎn)換為高維表達,是文本的預處理的主要步驟。GRUUnit是個試驗性函數(shù),功能類似于GRU的激活層。

2. 基礎(chǔ)Tensor運算
2.1 逐元素運算(element-wise)類
這個類別包括了Tensor的一些基礎(chǔ)運算,由于輸出的數(shù)據(jù)點只跟對應的那一個輸入的數(shù)據(jù)點有關(guān)系,因此可以稱為element-wise運算,這類運算與輸入的數(shù)據(jù)的維度和結(jié)構(gòu)無關(guān),可以等價的認為是一維向量運算的Tensor等效表示。由于輸入數(shù)據(jù)可能是各種維度,也可以是標量,因此此中的操作都是維度兼容的。一種特殊情況是輸入的參數(shù)中,一個是向量,另一個是標量,此時,NNVM區(qū)別對待,而ONNX將其統(tǒng)一處理。在此處,ONNX只支持了Tensor-Scalar,不支持scalar-tensor, 而NNVM兩者都支持。除法情況類似。對于加減乘除,ONNX自帶broadcast操作,而NNVM通過多帶帶函數(shù)實現(xiàn)。ONNX對邏輯運算和比較運算提供了支持,而NVVM沒有。另外ONNX提供了一些數(shù)據(jù)格式轉(zhuǎn)換(cast)和量化方面的函數(shù)(clip, floor, ceil),而NVVM暫時不支持。兩者都對指數(shù)運算和對數(shù)運算,開方運算提供了支持,可是這兩個函數(shù)其實是加速芯片比較難較精確實現(xiàn)的函數(shù)(可以通過查找表或近似函數(shù)實現(xiàn))。
2.2 Tensor/矩陣處理類
這部分操作是對整個Tensor的數(shù)據(jù)進行的,即輸出可能關(guān)系到Tensor中的不止一個數(shù)據(jù)。包括求和,求平均,通用矩陣運算(Gemm),矩陣乘法,圖像縮放等。其中Gemm是矩陣處理的通用表達形式,即Y = alpha * A * B + beta * C。其中A 為M X K維, B為K X N維,C和Y為M X N維。可以認為NNVM目前還缺乏對通用矩陣運算的支持。

2.3 激活和非線性函數(shù)
激活函數(shù)提供了神經(jīng)網(wǎng)絡(luò)的非線性擬合能力,不同的激活函數(shù)具有各自的性能特點。由于ReLU簡單且性能較好,因此一般圖像處理算法采用ReLU函數(shù)。而Sigmoid和Tanh在LSTM/GRU/RNN中較為常見。這些函數(shù)可以認為是2.1中所述的element-wise算子,但為了表達其在神經(jīng)網(wǎng)絡(luò)中的特殊功用,在此多帶帶提出。
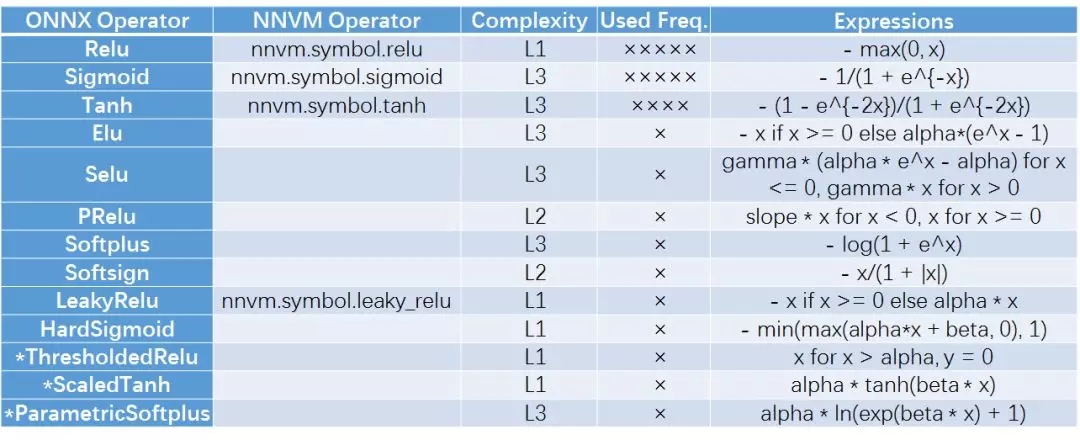
2.4. 隨機數(shù)和常數(shù)
這些操作用于產(chǎn)生數(shù)據(jù),包括正態(tài)隨機產(chǎn)生,均勻隨機產(chǎn)生,常數(shù)等。可以看出ONNX支持隨機數(shù)加入到圖中,而NNVM目前還不支持圖中包括隨機數(shù)。

2.5. 降維系列
降維系列是ONNX特有的。可以指定哪些維度根據(jù)某個計算度量去除。由于計算度量的方法比較多,本人認為功能類似于Global pooling。這些方法在神經(jīng)網(wǎng)絡(luò)應用中不是很多,NNVM目前還不支持這些方法。

3. Tensor變換
此部分算子不會改變Tensor的數(shù)據(jù),只會對數(shù)據(jù)的位置和維度進行調(diào)整。
3.1. 分割組合算子
此部分可以將多個Tensor合并成一個,或者將一個拆分為多個。可以用于分組卷積等。

3.2. 索引變換
索引變換包括Reshape, 矩陣轉(zhuǎn)置,空間維度與Feature Map互換等。可以認為是數(shù)據(jù)排布關(guān)系的變化。Flatten和Squeeze可以認為是Reshape的特例。

3.3. 數(shù)據(jù)選取
此部分操作可以根據(jù)維度參數(shù)、邊框或者腳標矩陣參數(shù)選取Tensor的部分數(shù)據(jù),或者對Tensor的數(shù)據(jù)進行復制拓展。

3.4. 數(shù)據(jù)填充
數(shù)據(jù)填充分為邊緣補0,常數(shù)填充和拷貝。其中NNVM沒有在官方文檔頁面中提供fill函數(shù)的解釋,但是確實存在這個函數(shù)。

綜上,我們總結(jié)了作為IR表示層的所有操作(Operator)。將這些操作連接起來就構(gòu)成了數(shù)據(jù)流圖,使得神經(jīng)網(wǎng)絡(luò)可以表達為一個基于Operator和Tensor的有向圖。采用Netron[4]可以查看ONNX的數(shù)據(jù)流圖,具有很好的可視化體驗。推薦大家可以嘗試。不過NNVM目前好像還沒有類似的工具。
另外,總體感覺是ONNX的靈活度高于NNVM,尤其是在RNN的支持上邊,但NNVM給大家提供了一個很好的范例,用以說明如何抓住重點,覆蓋典型的應用場景。另外,NNVM提供了一個很好的擴展機制,用戶可以將自己的原子操作加入到框架中去而不改變原有的框架結(jié)構(gòu)。上文中提及的可以認為是本征支持的操作(native operation)。
對于一個視頻/圖像類神經(jīng)網(wǎng)絡(luò)芯片,可以先考慮支持NNVM所支持的本征原語部分,如果有需要,再向著ONNX的更多操作擴展。而對于文本/語音處理而言,ONNX是比較好的考評量度。也許將來大家在進行加速器的功能比拼時,會以O(shè)NNX框架提供的兼容性為尺度。
另外,值得注意的是,要做到對一個操作的支持,并不只是有沒有的問題,還包括執(zhí)行效率的問題。后者可以從功耗效率的角度來衡量,也可以從有效計算能力和峰值計算能力的比值看出來。因此想設(shè)計一個高靈活的神經(jīng)網(wǎng)絡(luò)芯片還是一個各方面權(quán)衡,靈活度與性能聯(lián)合調(diào)優(yōu)的過程。
[ Reference ]
[1] Open Neural Network Exchange (ONNX), https://onnx.ai/
[2] ONNX Operator Schemas, https://github.com/onnx/onnx/blob/master/docs/Operators.md
[3] NNVM Core Tensor Operators, http://nnvm.tvmlang.org/top.html#detailed-definitions
[4] NETRON, https://github.com/lutzroeder/Netron
作者簡介:
吳臻志博士,清華大學類腦計算研究中心助理研究員。專長神經(jīng)網(wǎng)絡(luò)芯片設(shè)計,眾核芯片設(shè)計,神經(jīng)網(wǎng)絡(luò)高效實現(xiàn)等。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4724.html
摘要:亞馬遜和華盛頓大學今天合作發(fā)布了開源的端到端深度學習編譯器。項目作者之一陳天奇在微博上這樣介紹這個編譯器我們今天發(fā)布了基于工具鏈的深度學習編譯器。陳天奇團隊對的性能進行了基準測試,并與進行了比較。 亞馬遜和華盛頓大學今天合作發(fā)布了開源的端到端深度學習編譯器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是華盛頓大學博士陳天奇等人2016年發(fā)布的模塊化...
摘要:兩者取長補短,所以深度學習框架在年,迎來了前后端開發(fā)的黃金時代。陳天奇在今年的中,總結(jié)了計算圖優(yōu)化的三個點依賴性剪枝分為前向傳播剪枝,例已知,,求反向傳播剪枝例,,求,根據(jù)用戶的求解需求,可以剪掉沒有求解的圖分支。 虛擬框架殺入從發(fā)現(xiàn)問題到解決問題半年前的這時候,暑假,我在SIAT MMLAB實習。看著同事一會兒跑Torch,一會兒跑MXNet,一會兒跑Theano。SIAT的服務(wù)器一般是不...
摘要:如何進行操作本文將介紹在有道云筆記中用于文檔識別的實踐過程,以及都有些哪些特性,供大家參考。年月發(fā)布后,有道技術(shù)團隊第一時間跟進框架,并很快將其用在了有道云筆記產(chǎn)品中。微軟雅黑宋體以下是在有道云筆記中用于文檔識別的實踐過程。 這一兩年來,在移動端實現(xiàn)實時的人工智能已經(jīng)形成了一波潮流。去年,谷歌推出面向移動端和嵌入式的神經(jīng)網(wǎng)絡(luò)計算框架TensorFlowLite,將這股潮流繼續(xù)往前推。Tens...
摘要:據(jù)悉,在舊金山舉行的高通活動上,這家巨頭正式宣布進軍云計算市場,并發(fā)布了面向人工智能推理計算的專用加速器。沒有任何預告,繼谷歌亞馬遜和英偉達之后,高通成為第四家成功在云端推理上正式發(fā)布芯片的公司。提起高通,業(yè)內(nèi)對它的直接印象就是移動芯片領(lǐng)域的巨頭。一直以來,高通也確實只在移動通信領(lǐng)域深耕,并從芯片到底層平臺一攬子都包下。而現(xiàn)在,高通冷不丁扔出的一枚炸彈也將一改以往大家對它的認知。據(jù)悉,在舊金...
摘要:近日,與微軟聯(lián)合推出了開放式神經(jīng)網(wǎng)絡(luò)交換格式,它是一個表征深度學習模型的標準,可實現(xiàn)模型在不同框架之間的遷移。例如,在中,條件句通常是對輸入張量的大小或維度上的計算。 近日,F(xiàn)acebook 與微軟聯(lián)合推出了開放式神經(jīng)網(wǎng)絡(luò)交換(ONNX)格式,它是一個表征深度學習模型的標準,可實現(xiàn)模型在不同框架之間的遷移。ONNX 是構(gòu)建開源生態(tài)環(huán)境的第一步,供人工智能開發(fā)者輕松選擇并組合較先進的工具。開發(fā)...

閱讀 2227·2021-11-15 11:39
閱讀 982·2021-09-26 09:55
閱讀 925·2021-09-04 16:48
閱讀 2831·2021-08-12 13:23
閱讀 919·2021-07-30 15:30
閱讀 2455·2019-08-29 14:16
閱讀 886·2019-08-26 10:15
閱讀 525·2019-08-23 18:40






