資訊專欄INFORMATION COLUMN

摘要:目前,生成對抗網絡的大部分應用都是在計算機視覺領域。生成對抗網絡生成對抗網絡框架是由等人于年設計的生成模型。在設置中,兩個由神經網絡進行表示的可微函數被鎖定在一個游戲中。我們提出了深度卷積生成對抗網絡的實現。
讓我們假設這樣一種情景:你的鄰居正在舉辦一場非常酷的聚會,你非常想去參加。但有要參加聚會的話,你需要一張特價票,而這個票早就已經賣完了。
而對于這次聚會的組織者來說,為了讓聚會能夠成功舉辦,他們雇傭了一個合格的安全機構。主要目標就是不允許任何人破壞這次的聚會。為了做到這一點,他們在會場入口處安置了很多警衛,檢查每個人所持門票的真實性。
考慮到你沒有任何武術上的天賦,而你又特別想去參加聚會,那么的辦法就是用一張非常有說服力的假票來騙他們。
但是這個計劃存在一個很大的bug——你從來沒有真正看到過這張門票到底是什么樣的。所以,在這種情況下,如果你僅是根據自己的創造力設計了一張門票,那么在第一次嘗試期間就想要騙過警衛幾乎是不可能的。除此之外,除非你有一個很好的關于此次聚會的門票的復印件,否則你較好不要把你的臉展露出來。
為了幫助解決問題,你決定打電話給你的朋友Bob為你做這個工作。
Bob的任務非常簡單。他會試圖用你的假通行證進入聚會。如果他被拒絕了,他將返回,然后告訴你一些有關真正的門票應該是什么樣的建議。
基于這個反饋,你可以制作一張全新版本的門票,然后將其交給Bob,再去檢票處嘗試一下。這個過程不斷重復,直到你能夠設計一個完美的門票“復制品”。
?
這是一個必須去的派對。而下面這張照片,其實是我其實從一個假票據生成器器網站上拿到的。
?

對于上面這個小故事,拋開里面的假想成分,這幾乎就是生成對抗網絡(GAN)的工作方式。
目前,生成對抗網絡的大部分應用都是在計算機視覺領域。其中一些應用包括訓練半監督分類器,以及從低分辨率圖像中生成高分辨率圖像。
本篇文章對GAN進行了一些介紹,并對圖像生成問題進行了實際實踐。你可以在你的筆記本電腦上進行演示。
生成對抗網絡(Generative Adversarial Networks)
?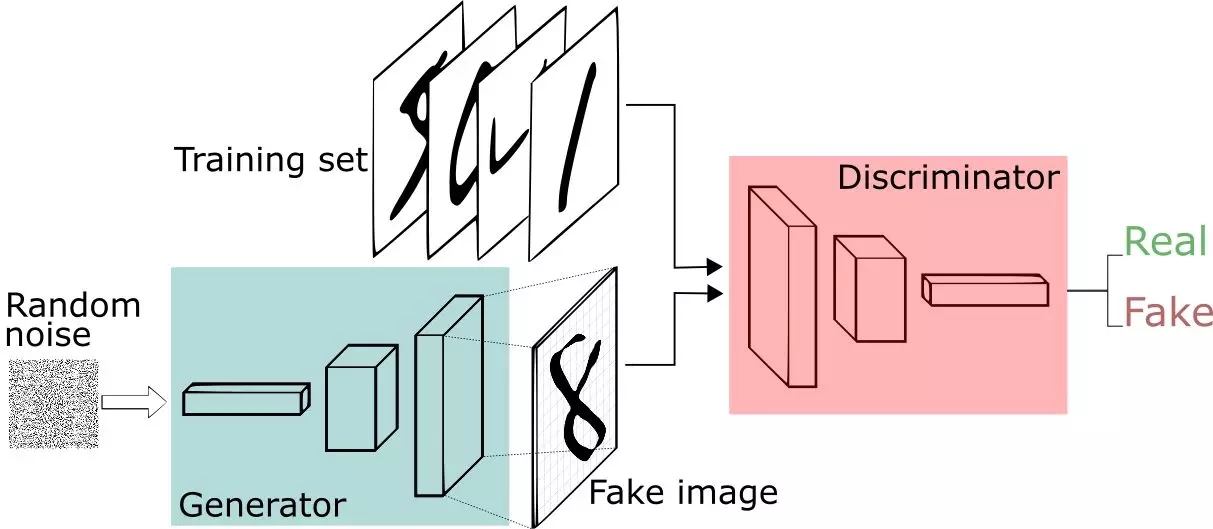
生成對抗網絡框架
GAN是由Goodfellow等人于2014年設計的生成模型。在GAN設置中,兩個由神經網絡進行表示的可微函數被鎖定在一個游戲中。這兩個參與者(生成器和鑒別器)在這個框架中要扮演不同的角色。
生成器試圖生成來自某種概率分布的數據。即你想重新生成一張聚會的門票。
鑒別器就像一個法官。它可以決定輸入是來自生成器還是來自真正的訓練集。這就像是聚會中的安保設置,比將你的假票和這正的門票進行比較,以找到你的設計中存在的缺陷。
?


?我們將一個4層卷積網絡用于生成器和鑒別器,進行批量正則化。對該模型進行訓練以生成SVHN和MNIST圖像。以上是訓練期間SVHN(上)和MNIST(下)生成器樣本
總而言之,游戲如下:
?生成器試圖較大化鑒別器將其輸入錯認為正確的的概率。
?鑒別器引導生成器生成更逼真的圖像。
在完美的平衡狀態中,生成器將捕獲通用的訓練數據分布。結果,鑒別器總是不確定其輸入是否是真實的。
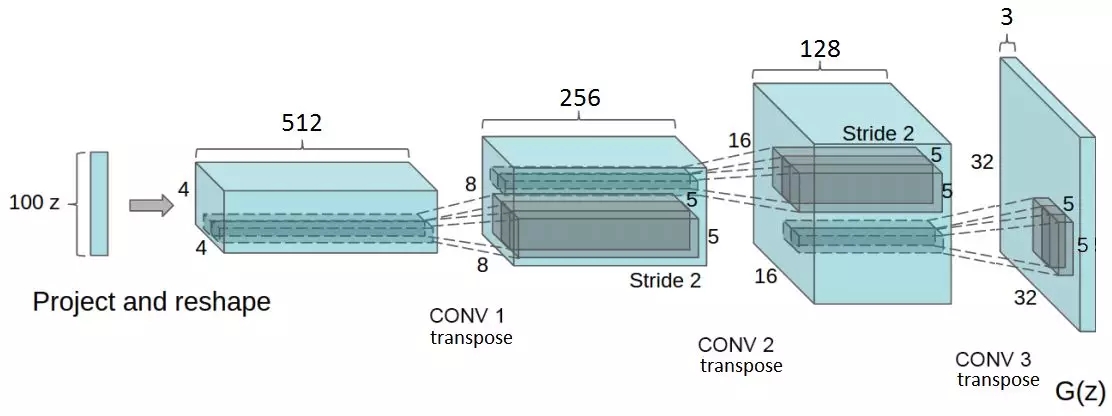
?摘自DCGAN論文。生成器網絡在這里實現。注意:完全連接層和池化層的不存在
在DCGAN論文中,作者描述了一些深度學習技術的組合,它們是訓練GAN的關鍵。這些技術包括:(i)所有的卷積網絡;(ii)批量正則化(BN)。
第一個強調的重點是帶步幅的卷積(strided convolutions),而不是池化層:增加和減少特征的空間維度;第二個是,對特征向量進行正則化以使其在所有層中具有零均值和單位方差。這有助于穩定學習和處理權重不佳的初始化問題。
言歸正傳,在這里闡述一下實施細節,以及GAN的相關知識。我們提出了深度卷積生成對抗網絡(DCGAN)的實現。我們的實現使用的是Tensorflow并遵循DCGAN論文中描述的一些實踐方法。
生成器
該網絡有4個卷積層,所有的位于BN(輸出層除外)和校正線性單元(ReLU)激活之后。
它將隨機向量z(從正態分布中抽取)作為輸入。將z重塑為4D形狀之后,將其饋送到啟動一系列上采樣層的生成器中。
每個上采樣層都代表一個步幅為2的轉置卷積(Transpose convolution)運算。轉置卷積與常規卷積類似。
一般來說,常規卷積從寬且淺的層延展為更窄、更深的層。轉移卷積走另一條路。他們從深而窄的層次走向更寬更淺。
轉置卷積運算的步幅定義了輸出層的大小。在“相同”的填充和步幅為2時,輸出特征的大小將是輸入層的兩倍。
發生這種情況的原因是,每次我們移動輸入層中的一個像素時,我們都會將輸出層上的卷積內核移動兩個像素。換句話說,輸入圖像中的每個像素都用于在輸出圖像中繪制一個正方形。
?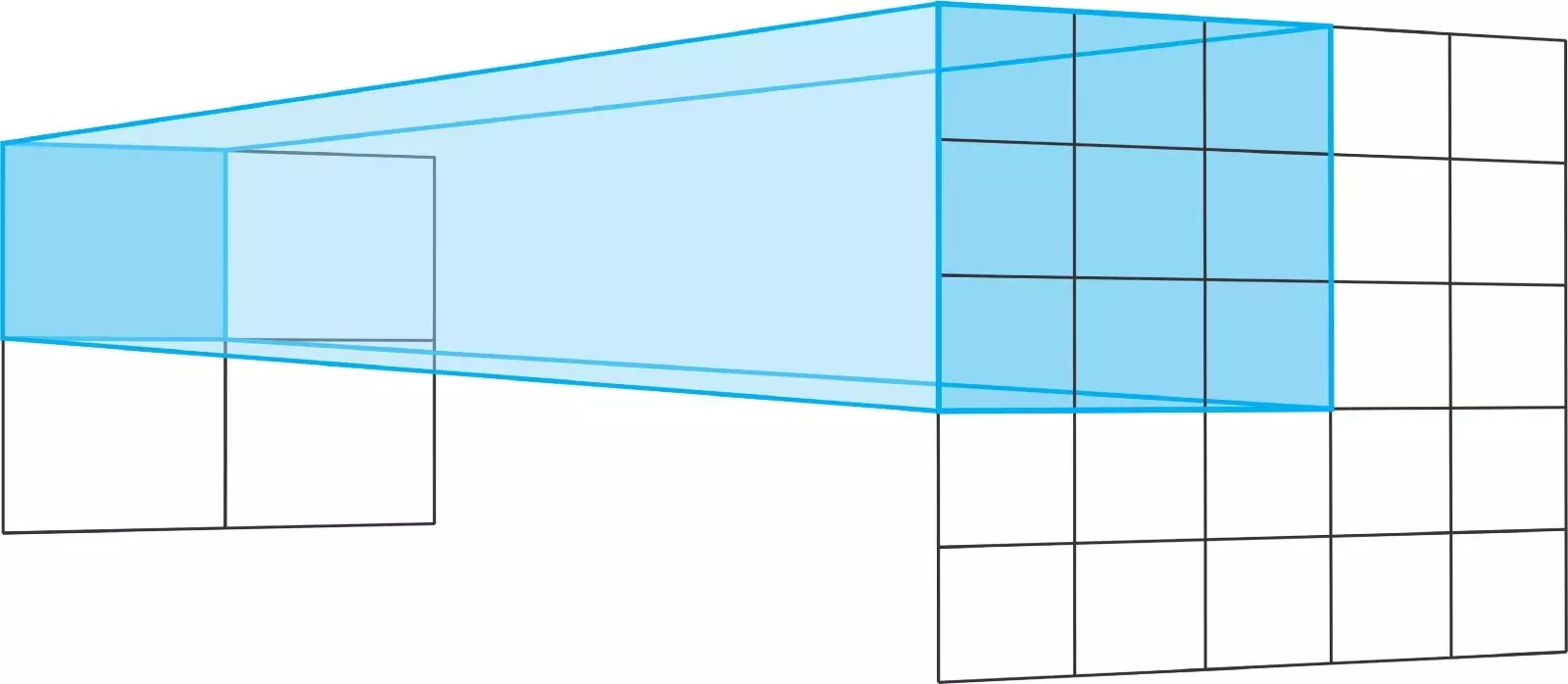
將一個3x3的內核在一個步幅為2的2x2輸入上進行轉置,就相當于將一個3x3的內核在一個步幅為2的5x5輸入上進行卷積運算。對于二者,均不使用填充“有效”
簡而言之,生成器開始于這個非常深但很窄的輸入向量開始。在每次轉置卷積之后,z變得更寬、更淺。所有的轉置卷積都使用5x5內核的大小,且深度從512減少到3——代表RGB彩色圖像。
def transpose_conv2d(x, output_space):
? ? return tf.layers.conv2d_transpose(x, output_space,?
? ? ? kernel_size=5, strides=2, padding="same",
? ? ? kernel_initializer=tf.random_normal_initializer(mean=0.0,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? stddev=0.02))
最后一層通過雙曲正切(tanh)函數輸出一個32x32x3的張量——值在-1和1之間進行壓縮。
這個最終的輸出形狀是由訓練圖像的大小來定義的。在這種情況下,如果是用于SVHN的訓練,生成器生成32x32x3的圖像。但是,如果是用于MNIST的訓練,則會生成28x28的灰度圖像。
最后,請注意,在將輸入向量z饋送到生成器之前,我們需要將其縮放到-1到1的區間。這是遵循使用tanh函數的選擇。
def generator(z, output_dim, reuse=False, alpha=0.2, training=True):
? ? """
? ? Defines the generator network
? ? :param z: input random vector z
? ? :param output_dim: output dimension of the network
? ? :param reuse: Indicates whether or not the existing model variables should be used or recreated
? ? :param alpha: Scalar for lrelu activation function
? ? :param training: Boolean for controlling the batch normalization statistics
? ? :return: model"s output
? ? """
? ? with tf.variable_scope("generator", reuse=reuse):
? ? ? ? fc1 = dense(z, 4*4*512)
? ? ? ? # Reshape it to start the convolutional stack
? ? ? ? fc1 = tf.reshape(fc1, (-1, 4, 4, 512))
? ? ? ? fc1 = batch_norm(fc1, training=training)
? ? ? ? fc1 = tf.nn.relu(fc1)
? ? ? ? t_conv1 = transpose_conv2d(fc1, 256)
? ? ? ? t_conv1 = batch_norm(t_conv1, training=training)
? ? ? ? t_conv1 = tf.nn.relu(t_conv1)
? ? ? ? t_conv2 = transpose_conv2d(t_conv1, 128)
? ? ? ? t_conv2 = batch_norm(t_conv2, training=training)
? ? ? ? t_conv2 = tf.nn.relu(t_conv2)
? ? ? ? logits = transpose_conv2d(t_conv2, output_dim)
? ? ? ? out = tf.tanh(logits)
? ? ? ? return out
鑒別器
鑒別器也是一個包含BN(除了其輸入層之外)和leaky ReLU激活的4層CNN。許多激活函數都可以在這種基礎GAN體系結構中進行良好的運算。但是leaky ReLUs有著非常廣泛的應用,因為它們可以幫助梯度在結構中更輕易地流動。
常規的RELU函數通過將負值截斷為0來工作。這樣做的效果是阻止梯度流通過網絡。leaky ReLU允許一個小負值通過,而非要求函數為0。也就是說,函數用來計算特征與小因素之間的較大值。
def lrelu(x, alpha=0.2):
? ? ?# non-linear activation function
? ? return tf.maximum(alpha * x, x)
leaky ReLU表示了一種解決崩潰邊緣ReLU問題的嘗試。這種情況發生在神經元陷于某一特定情況下,此時ReLU單元對于任何輸入都輸出0。對于這些情況,梯度完全關閉以通過網絡回流。
這對于GAN來說尤為重要,因為生成器必須學習的方法是接受來自鑒別器的梯度。
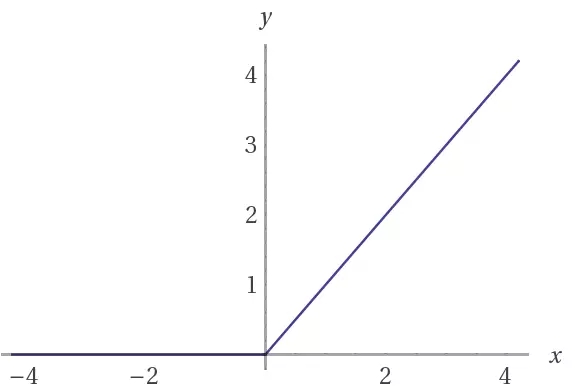
?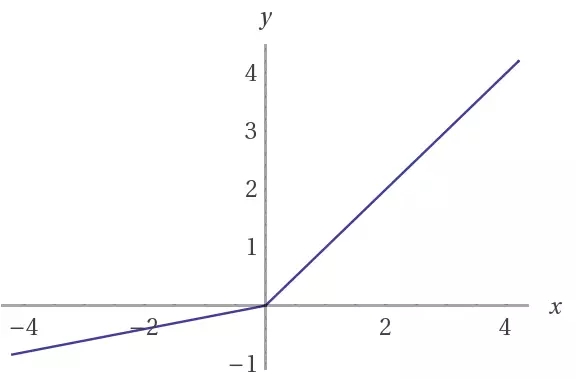
(上)ReLU,(下)leaky ReLU激活函數。 請注意,當x為負值時, leaky ReLU允許有一個小的斜率
這個鑒別器首先接收一個32x32x3的圖像張量。與生成器相反的是,鑒別器執行一系列步幅為2的卷積。每一種方法都是通過將特征向量的空間維度縮小一半,從而使學習過濾器的數量加倍。
最后,鑒別器需要輸出概率。為此,我們在最后的邏輯(logits)上使用Logistic Sigmoid激活函數。
def discriminator(x, reuse=False, alpha=0.2, training=True):
? ? """
? ? Defines the discriminator network
? ? :param x: input for network
? ? :param reuse: Indicates whether or not the existing model variables should be used or recreated
? ? :param alpha: scalar for lrelu activation function
? ? :param training: Boolean for controlling the batch normalization statistics
? ? :return: A tuple of (sigmoid probabilities, logits)
? ? """
? ? with tf.variable_scope("discriminator", reuse=reuse):
? ? ? ? # Input layer is 32x32x?
? ? ? ? conv1 = conv2d(x, 64)
? ? ? ? conv1 = lrelu(conv1, alpha)
? ? ? ? conv2 = conv2d(conv1, 128)
? ? ? ? conv2 = batch_norm(conv2, training=training)
? ? ? ? conv2 = lrelu(conv2, alpha)
? ? ? ? conv3 = conv2d(conv2, 256)
? ? ? ? conv3 = batch_norm(conv3, training=training)
? ? ? ? conv3 = lrelu(conv3, alpha)
? ? ? ? # Flatten it
? ? ? ? flat = tf.reshape(conv3, (-1, 4*4*256))
? ? ? ? logits = dense(flat, 1)
? ? ? ? out = tf.sigmoid(logits)
? ? ? ? return out, logits
需要注意的是,在這個框架中,鑒別器充當一個常規的二進制分類器。一半的時間從訓練集接收圖像,另一半時間從生成器接收圖像。
回到我們的故事中,為了復制聚會的票,你的信息來源是朋友Bob的反饋。換言之,Bob在每次嘗試期間向你提供的反饋的質量對于完成工作至關重要。
同樣的,每次鑒別器注意到真實圖像和虛假圖像之間的差異時,都會向生成器發送一個信號。該信號是從鑒別器向生成器反向流動的梯度。通過接收它,生成器能夠調整其參數以接近真實的數據分布。
這就是鑒別器的重要性所在。實際上,生成器將要盡可能好地產生數據,因為鑒別器正在不斷地縮小真實和虛假數據的差距。
損失
現在,讓我們來描述這一結構中最棘手的部分——損失。首先,我們知道鑒別器收集來自訓練集和生成器的圖像。
我們希望鑒別器能夠區分真實和虛假的圖像。我們每次通過鑒別器運行一個小批量(mini-batch)的時候,都會得到邏輯(logits)。這些是來自模型的未縮放值(unscaled values)。
然而,我們可以將鑒別器接收的小批量(mini-batches)分成兩種類型。第一種類型只由來自訓練集的真實圖像組成,第二種類型只包含由生成器生成的假圖像。
def model_loss(input_real, input_z, output_dim, alpha=0.2, smooth=0.1):
? ? """
? ? Get the loss for the discriminator and generator
? ? :param input_real: Images from the real dataset
? ? :param input_z: random vector z
? ? :param out_channel_dim: The number of channels in the output image
? ? :param smooth: label smothing scalar
? ? :return: A tuple of (discriminator loss, generator loss)
? ? """
? ? g_model = generator(input_z, output_dim, alpha=alpha)
? ? d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
? ? d_model_fake, d_logits_fake = discriminator(g_model, reuse=True, alpha=alpha)
? ? # for the real images, we want them to be classified as positives, ?
? ? # so we want their labels to be all ones.
? ? # notice here we use label smoothing for helping the discriminator to generalize better.
? ? # Label smoothing works by avoiding the classifier to make extreme predictions when extrapolating.
? ? d_loss_real = tf.reduce_mean(
? ? ? ? tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 - smooth)))
? ? # for the fake images produced by the generator, we want the discriminator to clissify them as false images,
? ? # so we set their labels to be all zeros.
? ? d_loss_fake = tf.reduce_mean(
? ? ? ? tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_model_fake)))
? ? # since the generator wants the discriminator to output 1s for its images, it uses the discriminator logits for the
? ? # fake images and assign labels of 1s to them.
? ? g_loss = tf.reduce_mean(
? ? ? ? tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_model_fake)))
? ? d_loss = d_loss_real + d_loss_fake
? ? return d_loss, g_loss
由于兩個網絡同時進行訓練,因此GAN需要兩個優化器。它們分別用于最小化鑒別器和發生器的損失函數。
我們希望鑒別器輸出真實圖像的概率接近于1,輸出假圖像的概率接近于0。要做到這一點,鑒別器需要兩部分損失。因此,鑒別器的總損失是這兩部分損失之和。其中一部分損失用于將真實圖像的概率較大化,另一部分損失用于將假圖像的概率最小化。
?
比較真實(左)和生成的(右)SVHN樣本圖像。雖然有些圖像看起來很模糊,且有些圖像很難識別,但值得注意的是,數據分布是由模型捕獲的
在訓練開始的時候,會出現兩個有趣的情況。首先,生成器不清楚如何創建與訓練集中圖像相似的圖像。其次,鑒別器不清楚如何將接收到的圖像分為真、假兩類。
結果,鑒別器接收兩種類型截然不同的批量(batches)。一個由訓練集的真實圖像組成,另一個包含含有噪聲的信號。隨著訓練的不斷進行,生成器輸出的圖像更加接近于訓練集中的圖像。這種情況是由生成器學習組成訓練集圖像的數據分布而造成的。
與此同時,鑒別器開始真正善于將樣本分類為真或假。結果,這兩種小批量(mini-batch)在結構上開始相互類似。因此,鑒別器無法識別出真實或虛假的圖像。
對于損失,我們認為,使用具有Adam算法的vanilla交叉熵(vanilla cross-entropy)作為優化器是一個不錯的選擇。
?

比較real(左)和Generate(右)MNIST示例圖像。由于MNIST圖像具有更簡單的數據結構,因此與SVHN相比,該模型能夠生成更真實的樣本
目前,GANs是機器學習中最熱門的學科之一。這些模型具有解開無監督學習方法(unsupervised learning methods)的潛力,并且可以將ML拓展到新領域。
自從GANs誕生以來,研究人員開發了許多用于訓練GANs的技術。在改進過后的GANs訓練技術中,作者描述了圖像生成(image generation)和半監督學習(semi-supervised learning)的技術。
原文鏈接:https://medium.freecodecamp.org/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4722.html
摘要:引用格式王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍生成對抗網絡的研究與展望自動化學報,論文作者王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍摘要生成式對抗網絡目前已經成為人工智能學界一個熱門的研究方向。本文概括了的研究進展并進行展望。 3月27日的新智元 2017 年技術峰會上,王飛躍教授作為特邀嘉賓將參加本次峰會的 Panel 環節,就如何看待中國 AI學術界論文數量多,但大師級人物少的現...
摘要:很多人可能會問這個故事和生成式對抗網絡有什么關系其實,只要你能理解這段故事,就可以了解生成式對抗網絡的工作原理。 男:哎,你看我給你拍的好不好?女:這是什么鬼,你不能學學XXX的構圖嗎?男:哦……男:這次你看我拍的行不行?女:你看看你的后期,再看看YYY的后期吧,呵呵男:哦……男:這次好點了吧?女:呵呵,我看你這輩子是學不會攝影了……男:這次呢?女:嗯,我拿去當頭像了上面這段對話講述了一位男...
摘要:但年在機器學習的較高級大會上,蘋果團隊的負責人宣布,公司已經允許自己的研發人員對外公布論文成果。蘋果第一篇論文一經投放,便在年月日,斬獲較佳論文。這項技術由的和開發,使用了生成對抗網絡的機器學習方法。 GANs「對抗生成網絡之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演講是聊他的代表作生成對抗網絡(GAN/Generative Adversarial ...
摘要:我仍然用了一些時間才從神經科學轉向機器學習。當我到了該讀博的時候,我很難在的神經科學和的機器學習之間做出選擇。 1.你學習機器學習的歷程是什么?在學習機器學習時你最喜歡的書是什么?你遇到過什么死胡同嗎?我學習機器學習的道路是漫長而曲折的。讀高中時,我興趣廣泛,大部分和數學或科學沒有太多關系。我用語音字母表編造了我自己的語言,我參加了很多創意寫作和文學課程。高中畢業后,我進了大學,盡管我不想去...
摘要:是世界上最重要的研究者之一,他在谷歌大腦的競爭對手,由和創立工作過不長的一段時間,今年月重返,建立了一個探索生成模型的新研究團隊。機器學習系統可以在這些假的而非真實的醫療記錄進行訓練。今年月在推特上表示是的,我在月底離開,并回到谷歌大腦。 理查德·費曼去世后,他教室的黑板上留下這樣一句話:我不能創造的東西,我就不理解。(What I cannot create, I do not under...

閱讀 3011·2021-10-27 14:15
閱讀 2999·2021-09-07 10:18
閱讀 1320·2019-08-30 15:53
閱讀 1570·2019-08-26 18:18
閱讀 3373·2019-08-26 12:15
閱讀 3460·2019-08-26 10:43
閱讀 654·2019-08-23 16:43
閱讀 2207·2019-08-23 15:27






