資訊專欄INFORMATION COLUMN

摘要:神經網絡的注意機制已經引起了廣泛關注。什么是通俗地說,神經網絡注意機制是具備能專注于其輸入或特征的神經網絡,它能選擇特定的輸入。在實踐中,它們可以被一維高斯函數向量實現。
神經網絡的注意機制(Attention Mechanisms)已經引起了廣泛關注。在這篇文章中,我將嘗試找到不同機制的共同點和用例,講解兩種soft visual attention的原理和實現。
什么是attention?
通俗地說,神經網絡注意機制是具備能專注于其輸入(或特征)的神經網絡,它能選擇特定的輸入。我們將輸入設為x∈Rd,特征向量為z∈Rk,a∈[0,1]k為注意向量,fφ(x)為注意網絡。一般來說,attention的實現方式為:
a=fφ(x)
或za=a⊙z
在上面的等式[1]中,⊙代表對應按元素(element-wise)相乘的運算。在這里我們引入soft attention和hard attention的概念,前者是指相乘時(soft)mask of values在0到1,而后者表示mask of values被強制分為0或1兩種,也就是a∈{0,1}k。對于后者來說,我們能用hard attention掩飾指數特征向量:za=z[a]。這就增加了它的維度。
為了理解attention的重要性,我們需要考慮神經網絡的本質——它是一個函數逼近器。依賴它的架構,它可以近似不同類型函數。神經網絡一般被應用在鏈矩陣乘法和對應元素的架構中,在這些地方輸入或特征向量僅在加法時相互作用。
注意機制可以用來計算可被用于特征相乘的mask,這種操作讓神經網絡逼近的函數空間大大擴展,使全新的用例成為可能。
Visual Attention
注意力可被應用在各種類型的輸入,而無需考慮它們的形狀。在像圖像這種矩陣值輸入的情況下,我們引入了視覺注意力這個概念。定義圖像為I∈RH*W,g∈Rh*w為glimpse,也就是將注意機制應用于圖像。
Hard Attention
圖像中的Hard Attentention 已經被應用很長時間了,比如圖像裁剪。它的概念很簡單,只需要編入索引(indexing)。Hard attention可在Python和TensorFlow中實現為:

上面這個形式的問題是它是不可微分的,如果想了解模型的參數,則必須使用score-function estimator之類的幫助。
Soft Attention
在Attention最簡單的變體中,soft attention對圖像來說和公式[1]中實現的向量值特征沒什么不同。論文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》記錄了它的早期應用。
論文地址:
https://arxiv.org/abs/1502.03044

這個模型學習圖像特定的部分,同時生成描述該部分的語言。
然而,soft atttention用于計算有些不經濟。輸入中被遮蔽的部分對結果沒有影響,但仍然需要進行運算。同時它也過參數化了,實現attention的Sigmoid激活函數是對彼此獨立的。它可以一次選擇多個目標,但在實踐中,我們通常想有選擇性地關注場景中一個或幾個元素。
下面,我將分別由DRAW和Spatial Transformer Networks切入,介紹兩種機制解決上述問題。它們還可以調整輸入的大小,從而進一步提高性能。
DRAW介紹論文地址:
https://arxiv.org/abs/1502.04623
Spatial Transformer Networks介紹論文地址:
https://arxiv.org/abs/1506.02025
Gaussian Attention
Gaussian attention是用參數化的一維高斯濾波器創建一張圖像大小的注意力地圖。定義ay=Rh,ax=Rw為注意力向量,attention mask可被寫成:


在上圖中,頂行表示ax,最右列表示ay,中間的矩形表示a。為了讓結果可視化,向量中只包含了0和1。在實踐中,它們可以被一維高斯函數向量實現。一般來說,高斯函數的數目等同于空間維度,每一個向量都被三個參數表示:第一個高斯μ的中心,連續分布高斯中心之間的距離,高斯分布的標準差σ。有了這些參數變量,注意力和glimps都變得可微了,學習的難度也降低了不少。
因為上面這個例子只能選擇一部分圖像,剩余圖像都需要被清理掉,因此用attention也顯得有些不劃算。如果我們不直接用向量,進而選擇將它們分別形成矩陣Ay∈Rh*H和Ax∈Rw*W,可能會好些。
現在,每個矩陣的每一行都有一個Gaussian,并且參數d指定了連續行中高斯分布中心的特定距離。glimpse可以被表示為:

我將這個機制用在最近一篇對象跟蹤的RNN attention的論文中,這篇是關于HART(Hierarchical Attentive Recurrent Tracking)的。
論文地址:
https://arxiv.org/abs/1706.09262
這里有一個例子,左邊是輸入圖像,右邊是attention,顯示了綠色的主圖像上的方框。

下面這串代碼可以讓你在TensorFlow中為小批量樣例創建上述矩陣值mask。如果你想創建Ay,你可以稱它為Ay = gaussian_mask(u, s, d, h, H),其中u,s,d分別表示μ,σ和d,在這個方式中以像素的方式指定。

我們也可以編寫一個函數來直接從圖像中提取一個圖像:
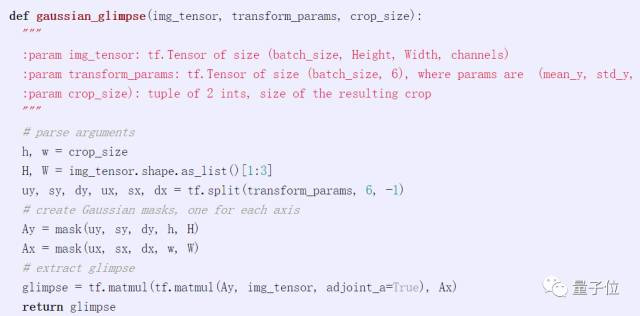
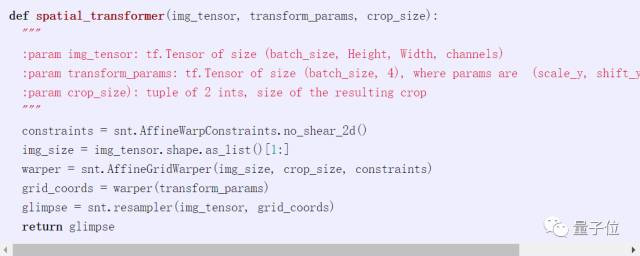
Spatial Transformer
Spatial Transformer(STN)允許更一般轉換,能區分圖像裁剪。圖像裁剪也是可能的用例之一,它由兩個組件組成,網格生成器和采樣器。網格生成器要指定從中取樣的點網格,而采樣器是樣本。在DeepMind最近的神經網絡庫Sonnet中,用TensorFlow實現非常簡單。
Gaunssian Attention vs. Spatial Transformer
Gaunssian Attention和Spatial Transformer實現的行為很相似,我們怎樣判斷選擇哪一種實現方式呢?這里列舉了一些細微差別:
Gaussian attention是一種超參數化的裁剪機制,它需要6個參數,但只有4個自由度(y,x,高度和寬度)。STN只需要四個參數。
目前我還沒有運行任何測試,但是STN應該更快一些。它依賴于抽樣點的線性插值,而Gaussian attention則需要執行兩個矩陣乘法。
Gaussian attention應該更容易訓練。這是因為,結果glimpse中每一個像素都可以是源圖像相對較大像素塊的凸組合,這使查找錯因變得更加容易。另一方面,STN依賴于線性插值,在每個采樣點處的梯度只在最接近的兩個像素點處不為零。
結論
注意機制擴展了神經網絡的功能,能近似更復雜的函數。或者用更直觀的術語來說,它能夠專注于輸入的特定部分,提高了自然語言基準測試的性能,也帶來了全新的功能,如圖像字幕、內存網絡中地址和神經程序。
我認為,attention最重要的應用案例尚未被發現。舉個例子,我們知道視頻中的對象是一致和連貫的,它們不會在幀與幀中突然消失。注意機制可以用來表示這種一致性。至于它的后續發展如何,我會持續關注。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4635.html
摘要:本文以機器翻譯為例,深入淺出地介紹了深度學習中注意力機制的原理及關鍵計算機制,同時也抽象出其本質思想,并介紹了注意力模型在圖像及語音等領域的典型應用場景。 最近兩年,注意力模型(Attention Model)被廣泛使用在自然語言處理、圖像識別及語音識別等各種不同類型的深度學習任務中,是深度學習技術中最值得關注與深入了解的核心技術之一。本文以機器翻譯為例,深入淺出地介紹了深度學習中注意力機制...
摘要:摘要在年率先發布上線了機器翻譯系統后,神經網絡表現出的優異性能讓人工智能專家趨之若鶩。目前在阿里翻譯平臺組擔任,主持上線了阿里神經網絡翻譯系統,為阿里巴巴國際化戰略提供豐富的語言支持。 摘要: 在2016年Google率先發布上線了機器翻譯系統后,神經網絡表現出的優異性能讓人工智能專家趨之若鶩。本文將借助多個案例,來帶領大家一同探究RNN和以LSTM為首的各類變種算法背后的工作原理。 ...
摘要:在這項工作中,我們提出了自注意力生成對抗網絡,它將自注意力機制引入到卷積中。越高,表示圖像質量越好。表將所提出的與較先進模型進行比較,任務是上的類別條件圖像生成。 圖像合成(Image synthesis)是計算機視覺中的一個重要問題。隨著生成對抗網絡(GAN)的出現,這個方向取得了顯著進展。基于深度卷積網絡的GAN尤其成功。但是,通過仔細檢查這些模型生成的樣本,可以觀察到,在ImageNe...

閱讀 1673·2021-11-15 11:38
閱讀 4514·2021-09-22 15:33
閱讀 2332·2021-08-30 09:46
閱讀 2176·2019-08-30 15:43
閱讀 827·2019-08-30 14:16
閱讀 2069·2019-08-30 13:09
閱讀 1255·2019-08-30 11:25
閱讀 701·2019-08-29 16:42




