資訊專欄INFORMATION COLUMN

摘要:然而,可用數據集的規模卻沒有成比例地擴大。這還說明無監督表征學習,以及半監督表征學習方法有良好的前景。例如,對于對象探測得分,單個模型目前可以實現,高于此前的。此外,構建包含圖片的數據集并不是最終目標。
都說深度學習的興起和大數據息息相關,那么是不是數據集越大,訓練出的圖像識別算法準確率就越高呢?
Google的研究人員用3億張圖的內部數據集做了實驗,然后寫了篇論文。他們指出,在深度模型中,視覺任務性能隨訓練數據量(取對數)的增加,線性上升。
以下是Google Research機器感知組指導教師,卡耐基梅隆大學助理教授Abhinav Gupta對這項工作的介紹,發布在Google Research官方博客上,量子位編譯:
過去10年,計算機視覺技術取得了很大的成功,其中大部分可以歸功于深度學習模型的應用。此外自2012年以來,這類系統的表現能力有了很大的進步,原因包括:
1)復雜度更高的深度模型;
2)計算性能的提升;
3)大規模標簽數據的出現。
每年,我們都能看到計算性能和模型復雜度的提升,從2012年7層的AlexNet,發展到2015年101層的ResNet。
然而,可用數據集的規模卻沒有成比例地擴大。101層的ResNet在訓練時仍然用著和AlexNet一樣的數據集:ImageNet中的10萬張圖。
作為研究者,我們一直在關注這樣的問題:如果能將訓練數據集擴大10倍,較精確度是否會有成倍的提升?如果數據集擴大100倍或300倍又會怎樣?較精確度會停滯不前,還是隨著數據量的增長不斷提升?
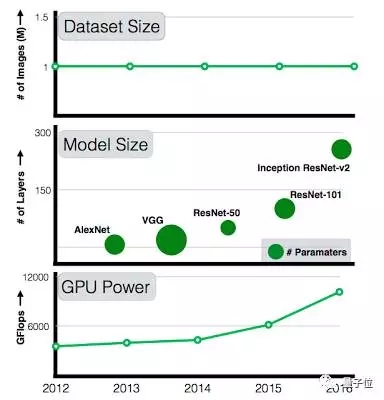
過去5年間,GPU計算力和模型復雜度都在持續增長,但訓練數據集的規模沒有任何變化
在論文Revisit the Unreasonable Effectiveness of Data中,我們邁出了第一步,探索“大量數據”與深度學習之間的關系。我們的目標是研究:
1)使用當前的算法,如果提供越來越多帶噪聲標簽的圖片,視覺表現是否仍然可以得到優化;
2)對于標準的視覺任務,例如分類、對象探測,以及圖像分割,數據和性能之間的關系是什么;
3)利用大規模學習技術,開發能勝任計算機視覺領域各類任務的較先進的模型。
當然,問題的關鍵在于,我們要從何處找到比ImageNet大300倍的數據集。
Google一直努力構建這樣的數據集,以優化計算機視覺算法。在Geoff Hinton、Francois Chollet等人的努力下,Google內部構建了一個包含3億張圖片的數據集,將其中的圖片標記為18291個類,并將其命名為JFT-300M。
圖片標記所用的算法混合了復雜的原始網絡信號,以及網頁和用戶反饋之間的關聯。
通過這種方法,這3億張圖片獲得了超過10億個標簽(一張圖片可以有多個標簽)。在這10億個標簽中,約3.75億個通過算法被選出,使所選擇圖片的標簽較精確度較大化。然而,這些標簽中依然存在噪聲:被選出圖片的標簽約有20%是噪聲。
我們的實驗驗證了一些假設,但也帶來了意料之外的結果:
更好的表征學習(Representation Learning)能帶來幫助。
我們觀察到的較早的現象是,大規模數據有助于表征學習,從而優化我們所研究的所有視覺任務的性能。
我們的發現表明,建立用于預訓練的大規模數據集很重要。這還說明無監督表征學習,以及半監督表征學習方法有良好的前景。看起來,數據規模繼續壓制了標簽中存在的噪聲。
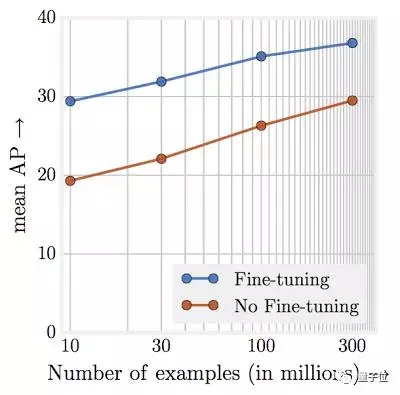
隨著訓練數據數量級的增加,任務性能呈線性上升。
或許最令人驚訝的發現在于,視覺任務性能和表現學習訓練數據量(取對數)之間的關系。我們發現,這樣的關系仍然是線性的。即使訓練圖片規模達到3億張,我們也沒有觀察到性能上升出現停滯。如下圖所示:
模型容量非常關鍵。
我們觀察到,如果希望完整利用3億張圖的數據集,我們需要更大容量(更深)的模型。
例如,對于ResNet-50,COCO對象探測得分的上升很有限,只有1.87%,而使用ResNet-152,這一得分上升達到3%。
新的較高水準結果。
我們的論文用JFT-300M去訓練模型,多項得分都達到了業界較高水準。例如,對于COCO對象探測得分,單個模型目前可以實現37.4 AP,高于此前的34.3 AP。
需要指出,我們使用的訓練體系、學習進度以及參數基于此前用ImageNet 1M圖片訓練ConvNets獲得的經驗。
由于我們并未在這項工作中探索最優的超參數(這將需要可觀的計算工作),因此很有可能,我們還沒有得到利用這一數據集進行訓練能取得的較佳結果。因此我們認為,量化的性能報告可能低估了這一數據集的實際影響。
這項工作并未關注針對特定任務的數據,例如研究更多邊界框是否會影響模型的性能。我們認為,盡管存在挑戰,但獲得針對特定任務的大規模數據集應當是未來研究的一個關注點。
此外,構建包含300M圖片的數據集并不是最終目標。我們應當探索,憑借更龐大的數據集(包含超過10億圖片),模型是否還能繼續優化。
Google Research Blog原文:https://research.googleblog.com/2017/07/revisiting-unreasonable-effectiveness.html
相關論文:Revisiting the Unreasonable Effectiveness of Data
https://arxiv.org/abs/1707.02968
你可能還關心那個3億張圖的數據集。它目前還是Google內部用品,這兩篇論文提到過它:
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, Jeff Dean
https://arxiv.org/abs/1503.02531
Xception: Deep Learning with Depthwise Separable Convolutions
Franc?ois Chollet
https://arxiv.org/abs/1610.02357
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4576.html
摘要:的這項研究,總共生成了篇深度學習論文的和代碼,還創建了一個網站,供同行們眾包編輯這些代碼。來自印度研究院。目前是印度研究院的實習生。 深度學習的論文越來越多了~多到什么程度?Google scholar的數據顯示,2016年以來,人工智能領域新增的論文已經超過3.5萬篇。arXiv上,AI相關的論文每天都不下百篇。剛剛結束不久的計算機視覺會議ICCV上,發表了621篇論文;2018年的ICL...
摘要:在年初之際,國內專業的云資源選型服務平臺旗下監測實驗室,針對業界家主流的云服務提供商,包括阿里云騰訊云與華為云進行了橫向評測。華為云和阿里云緊隨其后,位列第二第三位。阿里云和騰訊云相對優勢不明顯。 在2020年初之際,國內專業的云資源選型服務平臺CloudBest旗下監測實驗室,針對業界4家主流的云服務提供商,包括阿里云、騰訊云、UCloud與華為云進行了橫向評測。本次測試在盡量保證測試環...
摘要:年實驗室團隊采用了深度學習獲勝,失敗率僅。許多其他參賽選手也紛紛采用這一技術年,所有選手都使用了深度學習。和他的同事運用深度學習系統贏得了美元。深度學習,似乎是解決 三年前,在山景城(加利福尼亞州)秘密的谷歌X實驗室里,研究者從YouTube視頻中選取了大約一千萬張靜態圖片,并且導入到Google Brain —— 一個由1000臺電腦組成的像幼兒大腦一樣的神經網絡。花費了三天時間尋找模式之...
摘要:判別器勝利的條件則是很好地將真實圖像自編碼,以及很差地辨識生成的圖像。 先看一張圖:下圖左右兩端的兩欄是真實的圖像,其余的是計算機生成的。過渡自然,效果驚人。這是谷歌本周在 arXiv 發表的論文《BEGAN:邊界均衡生成對抗網絡》得到的結果。這項工作針對 GAN 訓練難、控制生成樣本多樣性難、平衡鑒別器和生成器收斂難等問題,提出了改善。尤其值得注意的,是作者使用了很簡單的結構,經過常規訓練...
摘要:接下來,介紹了使用深度學習的計算機視覺系統在農業零售業服裝量身定制廣告制造等產業中的應用和趨勢,以及在這些產業中值得關注的企業。 嵌入式視覺聯盟主編Brian Dipert今天發布博文,介紹了2016年嵌入式視覺峰會(Embedded Vision Summit)中有關深度學習的內容:谷歌工程師Pete Warden介紹如何利用TensorFlow框架,開發為Google Translate...

閱讀 4149·2021-09-22 15:34
閱讀 2765·2021-09-22 15:29
閱讀 490·2019-08-29 13:52
閱讀 3351·2019-08-29 11:30
閱讀 2259·2019-08-26 10:40
閱讀 832·2019-08-26 10:19
閱讀 2256·2019-08-23 18:16
閱讀 2311·2019-08-23 17:50






